Ten projekt klienta pomógł firmie zajmującej się żywnością Fortune 500 poprawić prognozowanie zapotrzebowania. Firma dostarcza produkty bezpośrednio do wielu placówek detalicznych. Poprawa pomogła im zoptymalizować zapasy swoich produktów w różnych sklepach w kilku regionach Stany Zjednoczone. Aby to osiągnąć, zespół komercyjnej inżynierii oprogramowania (CSE) firmy Microsoft współpracował z analitykami danych klienta w ramach badania pilotażowego w celu opracowania dostosowanych modeli uczenia maszynowego dla wybranych regionów. Modele uwzględniają następujące uwzględnienia:
- Dane demograficzne kupujących
- Historyczna i prognozowana pogoda
- Wcześniejsze przesyłki
- Zwroty produktów
- Wydarzenia specjalne
Celem optymalizacji zapasów było główne składniki projektu, a klient zdał sobie sprawę ze znacznego wzrostu sprzedaży we wczesnych próbach terenowych. Ponadto zespół odnotował spadek o 40% prognozowania średniego bezwzględnego błędu procentowego (MAPE) w porównaniu z historycznym modelem średniej bazowej.
Kluczową częścią projektu było ustalenie, jak skalować w górę przepływ pracy nauki o danych z badania pilotażowego do poziomu produkcyjnego. Ten przepływ pracy na poziomie produkcyjnym wymagał od zespołu CSE:
- Opracowywanie modeli dla wielu regionów.
- Ciągłe aktualizowanie i monitorowanie wydajności modeli.
- Ułatwia współpracę między zespołami ds. danych i inżynierów.
Typowy przepływ pracy nauki o danych jest obecnie bliżej środowiska laboratoryjnego jednorazowego niż produkcyjny przepływ pracy. Środowisko dla analityków danych musi być odpowiednie dla nich:
- Przygotuj dane.
- Eksperymentuj z różnymi modelami.
- Dostrajanie hiperparametrów.
- Utwórz cykl uściślinia oceny kompilacji i oceny.
Większość narzędzi używanych do tych zadań ma określone cele i nie nadaje się do automatyzacji. W przypadku operacji uczenia maszynowego na poziomie produkcyjnym należy wziąć pod uwagę więcej zagadnień związanych z zarządzaniem cyklem życia aplikacji i metodyką DevOps.
Zespół CSE pomógł klientowi skalować operację w górę do poziomów produkcyjnych. Zaimplementowali różne aspekty możliwości ciągłej integracji i ciągłego dostarczania (CI/CD) oraz rozwiązali problemy, takie jak możliwość obserwacji i integracja z możliwościami platformy Azure. Podczas implementacji zespół odkrył luki w istniejących wskazówkach dotyczących metodyki MLOps. Te luki musiały zostać wypełnione, aby metodyka MLOps była lepiej zrozumiała i stosowana na dużą skalę.
Zrozumienie rozwiązań MLOps pomaga organizacjom zapewnić, że modele uczenia maszynowego tworzone przez system są modelami jakości produkcji, które zwiększają wydajność biznesową. Po zaimplementowaniu metodyki MLOps organizacja nie musi już poświęcać tyle czasu na szczegóły niskiego poziomu dotyczące infrastruktury i pracy inżynieryjnej wymaganej do opracowywania i uruchamiania modeli uczenia maszynowego na potrzeby operacji na poziomie produkcyjnym. Implementowanie metodyki MLOps pomaga również społecznościom nauki o danych i inżynierii oprogramowania nauczyć się współpracować w celu zapewnienia systemu gotowego do produkcji.
Zespół CSE wykorzystał ten projekt do zaspokojenia potrzeb społeczności uczenia maszynowego, zajmując się problemami, takimi jak opracowywanie modelu dojrzałości MLOps. Te wysiłki miały na celu poprawę wdrażania metodyki MLOps przez zrozumienie typowych wyzwań kluczowych graczy w procesie MLOps.
Scenariusze dotyczące zaangażowania i techniki
Scenariusz zaangażowania omawia rzeczywiste wyzwania, które zespół CSE musiał rozwiązać. Scenariusz techniczny definiuje wymagania dotyczące tworzenia cyklu życia metodyki MLOps, który jest tak niezawodny, jak dobrze ugruntowany cykl życia metodyki DevOps.
Scenariusz zaangażowania
Klient dostarcza produkty bezpośrednio do sklepów detalicznych zgodnie z harmonogramem. Każdy punkt sprzedaży detalicznej różni się w swoich wzorcach użycia produktów, dlatego zapasy produktów muszą się różnić w każdym cotygodniowym dostarczaniu. Maksymalizacja sprzedaży i minimalizacja zwrotów produktów i utraconych szans sprzedaży to cele metodologii prognozowania popytu używanych przez klienta. Ten projekt koncentruje się na ulepszaniu prognoz przy użyciu uczenia maszynowego.
Zespół CSE podzielił projekt na dwie fazy. Faza 1 koncentruje się na opracowywaniu modeli uczenia maszynowego w celu wspierania badań pilotażowych opartych na dziedzinie na temat skuteczności prognozowania uczenia maszynowego dla wybranego regionu sprzedaży. Sukces fazy 1 doprowadził do fazy 2, w której zespół przeskalował wstępne badanie pilotażowe z minimalnej grupy modeli, które obsługiwały pojedynczy region geograficzny do zestawu zrównoważonych modeli na poziomie produkcyjnym dla wszystkich regionów sprzedaży klienta. Główną kwestią dla rozwiązania skalowanego w górę była potrzeba uwzględnienia dużej liczby regionów geograficznych i lokalnych placówek detalicznych. Zespół poświęcił modele uczenia maszynowego zarówno dużym, jak i małym sklepom detalicznym w każdym regionie.
Badanie pilotażowe fazy 1 wykazało, że model przeznaczony dla placówek detalicznych w jednym regionie może korzystać z lokalnej historii sprzedaży, lokalnych danych demograficznych, pogody i wydarzeń specjalnych, aby zoptymalizować prognozę zapotrzebowania dla placówek w regionie. Cztery zespołowe modele prognozowania uczenia maszynowego obsługiwały rynki w jednym regionie. Modele przetwarzały dane w cotygodniowych partiach. Ponadto zespół opracował dwa modele bazowe przy użyciu danych historycznych do porównania.
W pierwszej wersji rozwiązania skalowanego w górę fazy 2 zespół CSE wybrał 14 regionów geograficznych do udziału, w tym małych i dużych placówek rynkowych. Użyli ponad 50 modeli prognozowania uczenia maszynowego. Zespół spodziewał się dalszego wzrostu systemu i dalszego uściślenia modeli uczenia maszynowego. Szybko stało się jasne, że to szersze rozwiązanie do uczenia maszynowego jest trwałe tylko wtedy, gdy jest oparte na zasadach najlepszych rozwiązań metodyki DevOps dla środowiska uczenia maszynowego.
| Środowisko | Region rynku | Formatuj | Modele | Podział modelu | Opis modelu |
|---|---|---|---|---|---|
| Środowisko deweloperskie | Każdy rynek geograficzny/region (na przykład North Texas) | Sklepy w dużych formatach (supermarkety, sklepy z dużymi skrzynkami itd.) | Dwa modele grupowe | Powolne przenoszenie produktów | Zarówno powolne, jak i szybkie mają zespół co najmniej bezwzględnego modelu regresji liniowej operatora zmniejszania i wyboru (LASSO) oraz sieci neuronowej z osadzaniem podzielonym na kategorie |
| Szybkie przenoszenie produktów | Zarówno powolne, jak i szybkie mają zespół modelu regresji liniowej LASSO i sieć neuronową z osadzaniem kategorii | ||||
| Jeden model zespołu | Nie dotyczy | Średnia historyczna | |||
| Małe sklepy w formacie (apteki, sklepy wygodne itd.) | Dwa modele grupowe | Powolne przenoszenie produktów | Zarówno powolne, jak i szybkie mają zespół modelu regresji liniowej LASSO i sieć neuronową z osadzaniem kategorii | ||
| Szybkie przenoszenie produktów | Powolne i oba mają zespół modelu regresji liniowej LASSO i sieci neuronowej z osadzaniem podzielonym na kategorie | ||||
| Jeden model zespołu | Nie dotyczy | Średnia historyczna | |||
| Tak samo jak powyżej w przypadku dodatkowych 13 regionów geograficznych | |||||
| Tak samo jak powyżej dla środowiska prod |
Proces MLOps zapewnia platformę dla skalowanego systemu w górę, który dotyczył pełnego cyklu życia modeli uczenia maszynowego. Platforma obejmuje programowanie, testowanie, wdrażanie, operacje i monitorowanie. Spełnia ona potrzeby klasycznego procesu ciągłej integracji/ciągłego wdrażania. Jednak ze względu na względną niedojrzałość w porównaniu z metodyką DevOps okazało się, że istniejące wskazówki dotyczące metodyki MLOps miały luki. Zespół projektu pracował nad wypełnieniem niektórych z tych luk. Chcieli zapewnić funkcjonalny model procesu, który zapewnia rentowność skalowanego w górę rozwiązania do uczenia maszynowego.
Proces MLOps opracowany w ramach tego projektu wykonał znaczący rzeczywisty krok w celu przeniesienia metodyki MLOps na wyższy poziom dojrzałości i rentowności. Nowy proces ma zastosowanie bezpośrednio do innych projektów uczenia maszynowego. Zespół CSE wykorzystał zdobytą wiedzę na temat tworzenia projektu modelu dojrzałości MLOps, który każdy może zastosować do innych projektów uczenia maszynowego.
Scenariusz techniczny
Metodyka MLOps, znana również jako DevOps na potrzeby uczenia maszynowego, jest terminem parasolowym obejmującym założenia, praktyki i technologie związane z wdrażaniem cykli życia uczenia maszynowego w środowisku produkcyjnym. Jest to jeszcze stosunkowo nowa koncepcja. Istnieje wiele prób zdefiniowania metodyki MLOps, a wiele osób zakwestionowało, czy metodyka MLOps może podsumowyć wszystko, od tego, jak analitycy danych przygotowują dane do sposobu, w jaki ostatecznie dostarczają, monitorują i oceniają wyniki uczenia maszynowego. Chociaż metodyka DevOps miała lata na opracowanie zestawu podstawowych praktyk, metodyka MLOps jest nadal na wczesnym etapie opracowywania. W miarę rozwoju odkrywamy wyzwania związane z łączeniem dwóch dyscyplin, które często działają z różnymi zestawami umiejętności i priorytetami: inżynierią oprogramowania/ops i nauką o danych.
Implementowanie metodyki MLOps w rzeczywistych środowiskach produkcyjnych ma unikatowe wyzwania, które należy przezwyciężyć. Zespoły mogą używać platformy Azure do obsługi wzorców MLOps. Platforma Azure może również udostępniać klientom usługi zarządzania zasobami i orkiestracji na potrzeby efektywnego zarządzania cyklem życia uczenia maszynowego. Usługi platformy Azure są podstawą rozwiązania MLOps opisanego w tym artykule.
Wymagania dotyczące modelu uczenia maszynowego
Większość prac w badaniu pilotażowym fazy 1 polegała na tworzeniu modeli uczenia maszynowego, które zespół CSE zastosował do dużych i małych sklepów detalicznych w jednym regionie. Istotne wymagania dotyczące modeli:
Korzystanie z usługi Azure Machine Learning.
Początkowe modele eksperymentalne, które zostały opracowane w notesach Jupyter i zaimplementowane w języku Python.
Uwaga
Zespoły używały tego samego podejścia do uczenia maszynowego w dużych i małych magazynach, ale dane trenowania i oceniania zależą od rozmiaru sklepu.
Dane, które wymagają przygotowania do użycia modelu.
Dane przetwarzane na podstawie partii, a nie w czasie rzeczywistym.
Ponowne trenowanie modelu za każdym razem, gdy kod lub dane zmieniają się albo model jest nieaktualny.
Wyświetlanie wydajności modelu na pulpitach nawigacyjnych usługi Power BI.
Wydajność modelu w ocenianiu, która jest uznawana za znaczącą, gdy MAPE <= 45% w porównaniu z modelem bazowym średniej historycznej.
Wymagania dotyczące metodyki MLOps
Zespół musiał spełnić kilka kluczowych wymagań, aby skalować rozwiązanie w górę z badania pilotażowego fazy 1, w którym opracowano tylko kilka modeli dla jednego regionu sprzedaży. Faza 2 zaimplementowała niestandardowe modele uczenia maszynowego dla wielu regionów. Implementacja obejmowała:
Cotygodniowe przetwarzanie wsadowe dla dużych i małych magazynów w każdym regionie w celu ponownego trenowania modeli przy użyciu nowych zestawów danych.
Ciągłe uściślenie modeli uczenia maszynowego.
Integracja procesu programowania/testowania/pakietu/testowania/wdrażania wspólnego dla ciągłej integracji/ciągłego wdrażania w środowisku przetwarzania przypominającym metodykę DevOps dla metodyki MLOps.
Uwaga
Stanowi to zmianę sposobu, w jaki analitycy danych i inżynierowie danych często pracowali w przeszłości.
Unikatowy model, który reprezentował każdy region dla dużych i małych sklepów w oparciu o historię sklepu, dane demograficzne i inne kluczowe zmienne. Model musiał przetworzyć cały zestaw danych, aby zminimalizować ryzyko wystąpienia błędu przetwarzania.
Możliwość początkowego skalowania w górę w celu obsługi 14 regionów sprzedaży z planami dalszego skalowania w górę.
Plany dodatkowych modeli prognozowania długoterminowego dla regionów i innych klastrów sklepów.
Rozwiązanie modelu uczenia maszynowego
Cykl życia uczenia maszynowego, znany również jako cykl życia nauki o danych, mieści się w przybliżeniu w następującym przepływie procesów wysokiego poziomu:
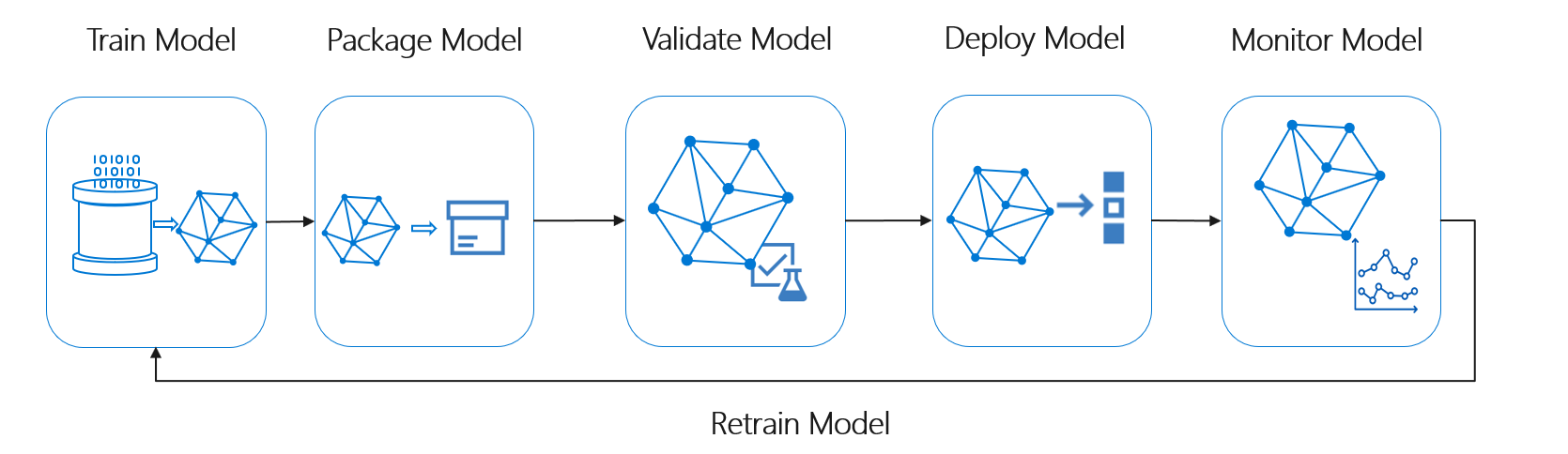
W tym miejscu wdróż model może reprezentować dowolne użycie operacyjne zweryfikowanego modelu uczenia maszynowego. W porównaniu z metodykami DevOps metodyka MLOps stanowi dodatkowe wyzwanie związane z integracją cyklu życia uczenia maszynowego z typowym procesem ciągłej integracji/ciągłego wdrażania.
Cykl życia nauki o danych nie jest zgodny z typowym cyklem życia tworzenia oprogramowania. Obejmuje ona korzystanie z usługi Azure Machine Learning do trenowania i oceniania modeli, więc te kroki musiały zostać uwzględnione w automatyzacji ciągłej integracji/ciągłego wdrażania.
Przetwarzanie wsadowe danych jest podstawą architektury. Dwa potoki usługi Azure Machine Learning są kluczowe dla procesu, jeden do trenowania, a drugi do oceniania. Na tym diagramie przedstawiono metodologię nauki o danych, która została użyta do początkowej fazy projektu klienta:
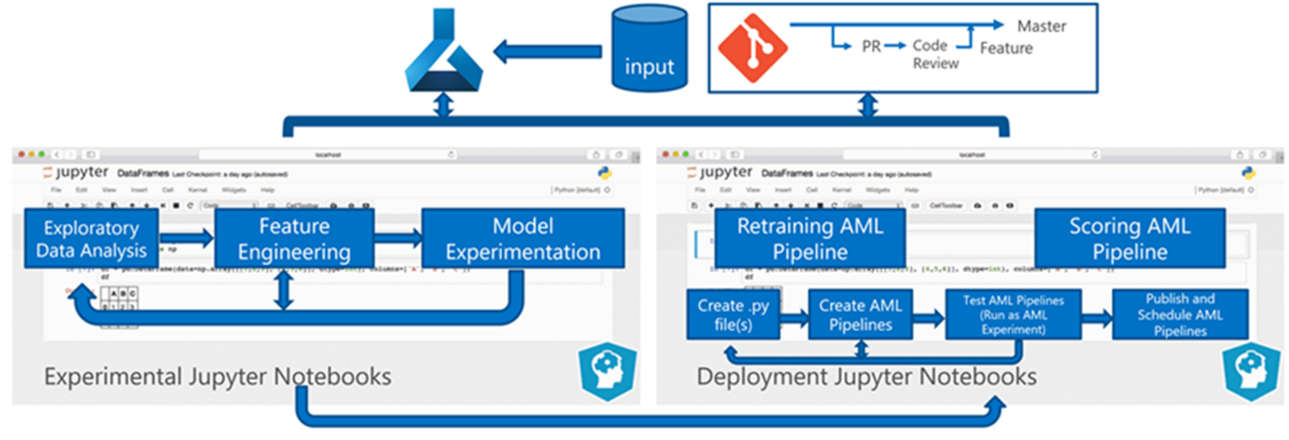
Zespół przetestował kilka algorytmów. Ostatecznie wybrali projekt zespołu modelu regresji liniowej LASSO i sieci neuronowej z osadzanymi kategoriami. Zespół użył tego samego modelu zdefiniowanego przez poziom produktu, który klient może przechowywać w lokacji zarówno w przypadku dużych, jak i małych sklepów. Zespół dodatkowo podzielił model na szybko poruszające się i wolno poruszające się produkty.
Analitycy danych szkolą modele uczenia maszynowego, gdy zespół wyda nowy kod i kiedy są dostępne nowe dane. Trenowanie zwykle odbywa się co tydzień. W związku z tym każde uruchomienie przetwarzania obejmuje dużą ilość danych. Ze względu na to, że zespół zbiera dane z wielu źródeł w różnych formatach, wymaga odłożonego umieszczenia danych w formacie eksploatacyjnym, zanim analitycy danych będą mogli je przetworzyć. Kondycja danych wymaga znacznego nakładu pracy ręcznej, a zespół CSE określił go jako podstawowego kandydata do automatyzacji.
Jak wspomniano, analitycy danych opracowali i zastosli eksperymentalne modele usługi Azure Machine Learning do pojedynczego regionu sprzedaży w badaniu pilotażowym fazy 1, aby ocenić użyteczność tego podejścia do prognozowania. Zespół CSE ocenił, że wzrost sprzedaży sklepów w badaniu pilotażowym był znaczący. Ten sukces uzasadnia zastosowanie rozwiązania do pełnych poziomów produkcji w fazie 2, począwszy od 14 regionów geograficznych i tysięcy sklepów. Następnie zespół może użyć tego samego wzorca, aby dodać dodatkowe regiony.
Model pilotażowy był podstawą skalowanego rozwiązania w górę, ale zespół CSE wiedział, że model wymaga dalszego uściślenia w celu poprawy wydajności.
Rozwiązanie MLOps
W miarę dojrzewania pojęć metodyki MLOps zespoły często odkrywają wyzwania związane z łączeniem dziedzin nauki o danych i metodyce DevOps. Powodem jest to, że głównymi graczami w dyscyplinach, inżynierami oprogramowania i analitykami danych działają z różnymi zestawami umiejętności i priorytetami.
Ale istnieją podobieństwa do budowania na. Metodyka MLOps, podobnie jak Metodyka DevOps, to proces programowania implementowany przez łańcuch narzędzi. Łańcuch narzędzi MLOps zawiera takie elementy jak:
- Kontrola wersji
- Analiza kodu
- Automatyzacja kompilacji
- Ciągła integracja
- Struktury testowania i automatyzacja
- Zasady zgodności zintegrowane z potokami ciągłej integracji/ciągłego wdrażania
- Automatyzacja wdrażania
- Monitorowanie
- Odzyskiwanie po awarii i wysoka dostępność
- Zarządzanie pakietami i kontenerami
Jak wspomniano powyżej, rozwiązanie korzysta z istniejących wskazówek metodyki DevOps, ale jest rozszerzone w celu utworzenia bardziej dojrzałej implementacji metodyki MLOps, która spełnia potrzeby klienta i społeczności nauki o danych. Metodyka MLOps opiera się na wskazówkach metodyki DevOps z następującymi dodatkowymi wymaganiami:
- Przechowywanie wersji danych i modelu nie jest takie samo jak przechowywanie wersji kodu: musi istnieć przechowywanie wersji zestawów danych, ponieważ zmieniają się dane schematu i źródła.
- Wymagania dotyczące cyfrowego dziennika inspekcji: śledzenie wszystkich zmian podczas pracy z kodem i danymi klienta.
- Uogólnianie: Modele różnią się od kodu do ponownego użycia, ponieważ analitycy danych muszą dostroić modele na podstawie danych wejściowych i scenariuszy. Aby ponownie użyć modelu w nowym scenariuszu, może być konieczne dostosowanie/przeniesienie/nauczenie się go. Potrzebujesz potoku trenowania.
- Nieaktualne modele: Modele mają tendencję do rozkładu w czasie i potrzebujesz możliwości ponownego trenowania ich na żądanie, aby upewnić się, że pozostają one istotne w środowisku produkcyjnym.
Wyzwania związane z metodykami MLOps
Niedojrzały standard MLOps
Standardowy wzorzec metodyki MLOps nadal ewoluuje. Rozwiązanie jest zwykle tworzone od podstaw i dostosowane do potrzeb określonego klienta lub użytkownika. Zespół CSE uznał tę lukę i starał się wykorzystać najlepsze rozwiązania devOps w tym projekcie. Rozszerzyli proces DevOps, aby spełnić dodatkowe wymagania metodyki MLOps. Proces opracowany przez zespół jest realnym przykładem tego, jak powinien wyglądać standardowy wzorzec metodyki MLOps.
Różnice w zestawach umiejętności
Inżynierowie oprogramowania i analitycy danych wprowadzają unikatowe zestawy umiejętności do zespołu. Te różne zestawy umiejętności mogą utrudniać znalezienie rozwiązania, które pasuje do potrzeb wszystkich. Ważne jest utworzenie dobrze zrozumiałego przepływu pracy na potrzeby dostarczania modelu od eksperymentowania do środowiska produkcyjnego. Członkowie zespołu muszą podzielić się wiedzą, w jaki sposób mogą integrować zmiany w systemie bez przerywania procesu MLOps.
Zarządzanie wieloma modelami
Często istnieje potrzeba rozwiązania wielu modeli w przypadku trudnych scenariuszy uczenia maszynowego. Jednym z wyzwań związanych z metodykami MLOps jest zarządzanie tymi modelami, w tym:
- Posiadanie spójnego schematu przechowywania wersji.
- Stale ocenianie i monitorowanie wszystkich modeli.
Do diagnozowania problemów z modelem i tworzenia powtarzalnych modeli potrzebne jest również śledzenie pochodzenia kodu i danych. Niestandardowe pulpity nawigacyjne mogą mieć sens działania wdrożonych modeli i wskazać, kiedy należy interweniować. Zespół utworzył takie pulpity nawigacyjne dla tego projektu.
Potrzeba klimatyzacji danych
Dane używane z tymi modelami pochodzą z wielu prywatnych i publicznych źródeł. Ponieważ oryginalne dane są dezorganizowane, nie można używać go w stanie pierwotnym przez model uczenia maszynowego. Analitycy danych muszą postawić dane w standardowym formacie na potrzeby użycia modelu uczenia maszynowego.
Większość testu pola pilotażowego koncentruje się na klimatyzacji danych pierwotnych, aby model uczenia maszynowego mógł go przetworzyć. W systemie MLOps zespół powinien zautomatyzować ten proces i śledzić dane wyjściowe.
Model dojrzałości metodyki MLOps
Celem modelu dojrzałości MLOps jest wyjaśnienie zasad i praktyk oraz zidentyfikowanie luk w implementacji metodyki MLOps. Jest to również sposób pokazania klientowi sposobu przyrostowego zwiększania możliwości metodyki MLOps zamiast próby wykonania tego wszystkiego jednocześnie. Klient powinien używać go jako przewodnika:
- Szacowanie zakresu pracy dla projektu.
- Ustal kryteria powodzenia.
- Identyfikowanie elementów dostarczanych.
Model dojrzałości MLOps definiuje pięć poziomów możliwości technicznych:
| Poziom | opis |
|---|---|
| 0 | Brak operacji |
| 1 | Metodyka DevOps, ale bez metodyki MLOps |
| 2 | Zautomatyzowane trenowanie |
| 3 | Wdrażanie modelu zautomatyzowanego |
| 100 | Operacje automatyczne (pełna liczba operacji MLOps) |
Aby zapoznać się z bieżącą wersją modelu dojrzałości MLOps, zobacz artykuł MLOps maturity model (Model dojrzałości MLOps).
Definicja procesu MLOps
Metodyka MLOps obejmuje wszystkie działania związane z uzyskiwaniem nieprzetworzonych danych po dostarczanie danych wyjściowych modelu, nazywanych również ocenianiem:
- Kondycja danych
- Trenowanie modelu
- Testowanie i ewaluacja modelu
- Definicja kompilacji i potok
- Potok wydania
- Wdrożenie
- Scoring (Ocenianie)
Podstawowy proces uczenia maszynowego
Podstawowy proces uczenia maszynowego przypomina tradycyjne programowanie oprogramowania, ale istnieją istotne różnice. Na tym diagramie przedstawiono główne kroki procesu uczenia maszynowego:
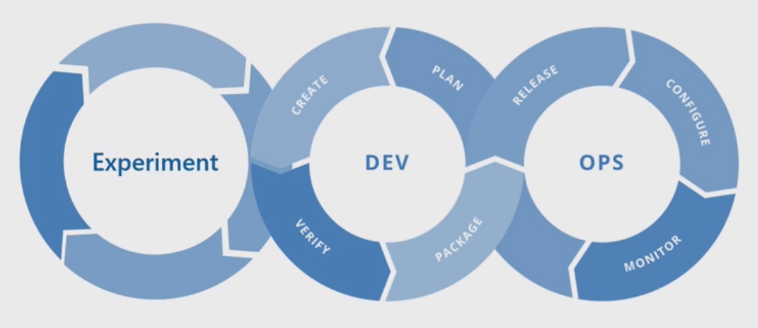
Faza eksperymentu jest unikatowa dla cyklu życia nauki o danych, która odzwierciedla sposób, w jaki analitycy danych tradycyjnie wykonują swoją pracę. Różni się to od tego, jak deweloperzy kodu wykonują swoją pracę. Na poniższym diagramie przedstawiono ten cykl życia bardziej szczegółowo.
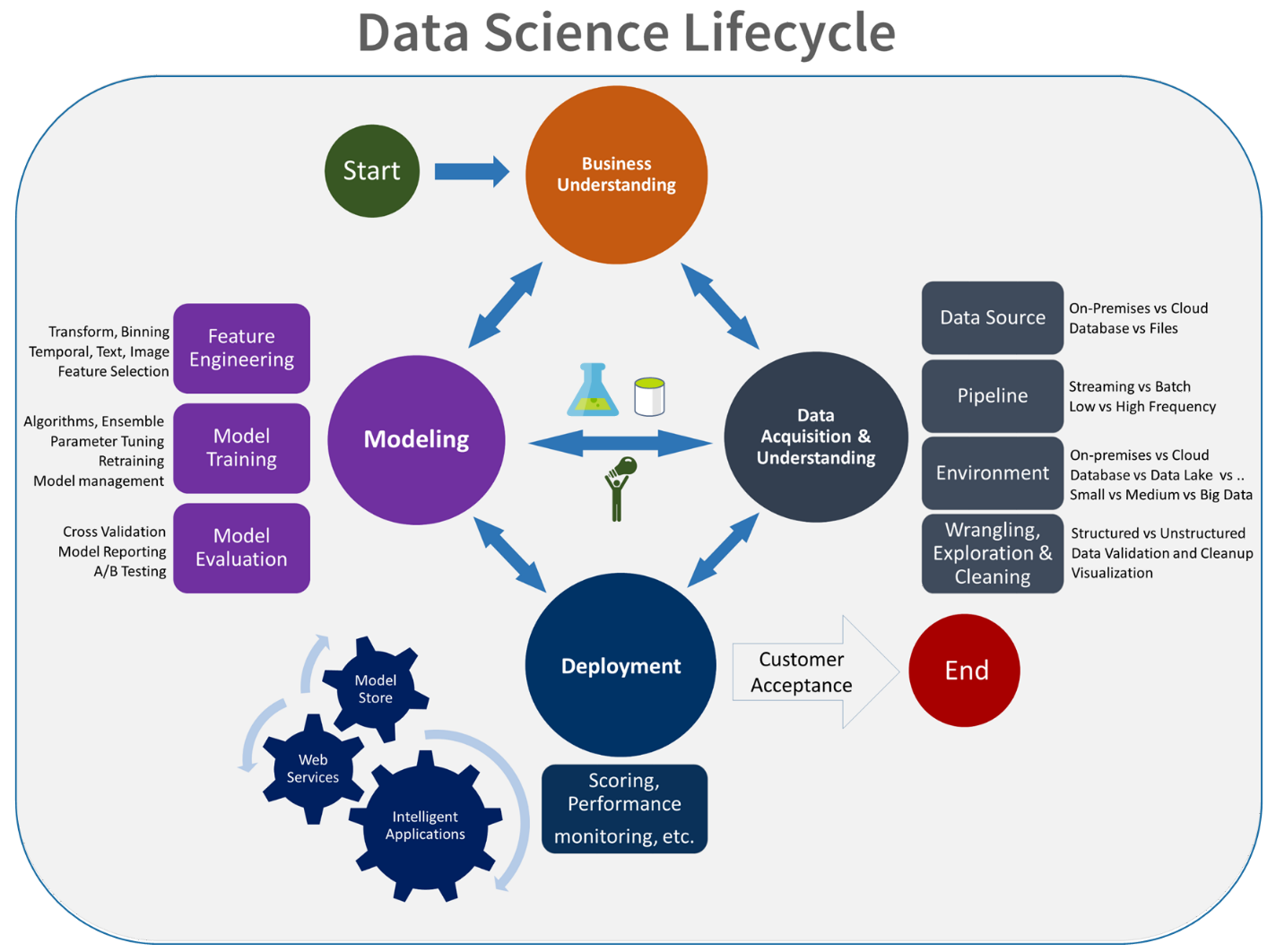
Integracja tego procesu programowania danych z metodyką MLOps stanowi wyzwanie. W tym miejscu zobaczysz wzorzec, który zespół użył do zintegrowania procesu z formularzem, który może obsługiwać metodyka MLOps:
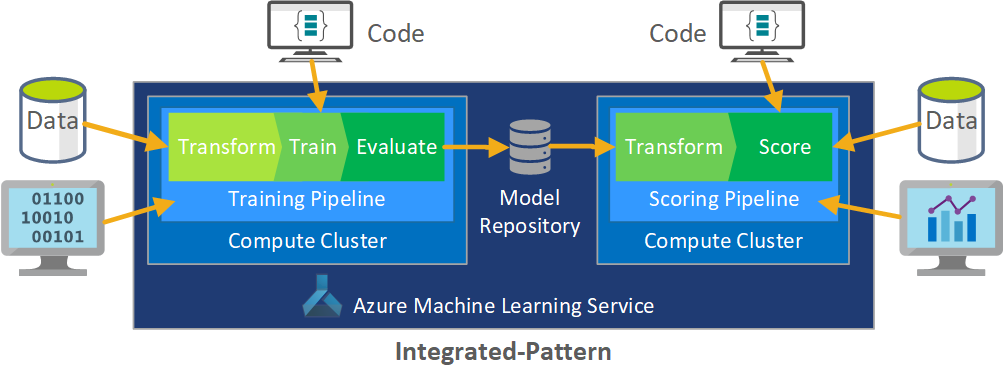
Rolą metodyki MLOps jest utworzenie skoordynowanego procesu, który może efektywnie obsługiwać środowiska ciągłej integracji/ciągłego wdrażania na dużą skalę, które są wspólne w systemach na poziomie produkcyjnym. Koncepcyjnie model MLOps musi zawierać wszystkie wymagania dotyczące procesu od eksperymentowania po ocenianie.
Zespół CSE udoskonalił proces MLOps, aby dopasować go do konkretnych potrzeb klienta. Najbardziej godną uwagi potrzebą było przetwarzanie wsadowe zamiast przetwarzania w czasie rzeczywistym. Gdy zespół opracował skalowany system w górę, zidentyfikowali i rozwiązali pewne braki. Najważniejsze z tych niedociągnięć doprowadziło do rozwoju mostu między usługą Azure Data Factory i usługą Azure Machine Learning, który zespół zaimplementował przy użyciu wbudowanego łącznika w usłudze Azure Data Factory. Utworzyli ten zestaw składników, aby ułatwić monitorowanie wyzwalania i stanu niezbędne do wykonania pracy automatyzacji procesu.
Inną fundamentalną zmianą było to, że analitycy danych potrzebowali możliwości eksportowania kodu eksperymentalnego z notesów Jupyter do procesu wdrażania metodyki MLOps, a nie wyzwalania trenowania i oceniania bezpośrednio.
Oto ostateczna koncepcja modelu procesów MLOps:
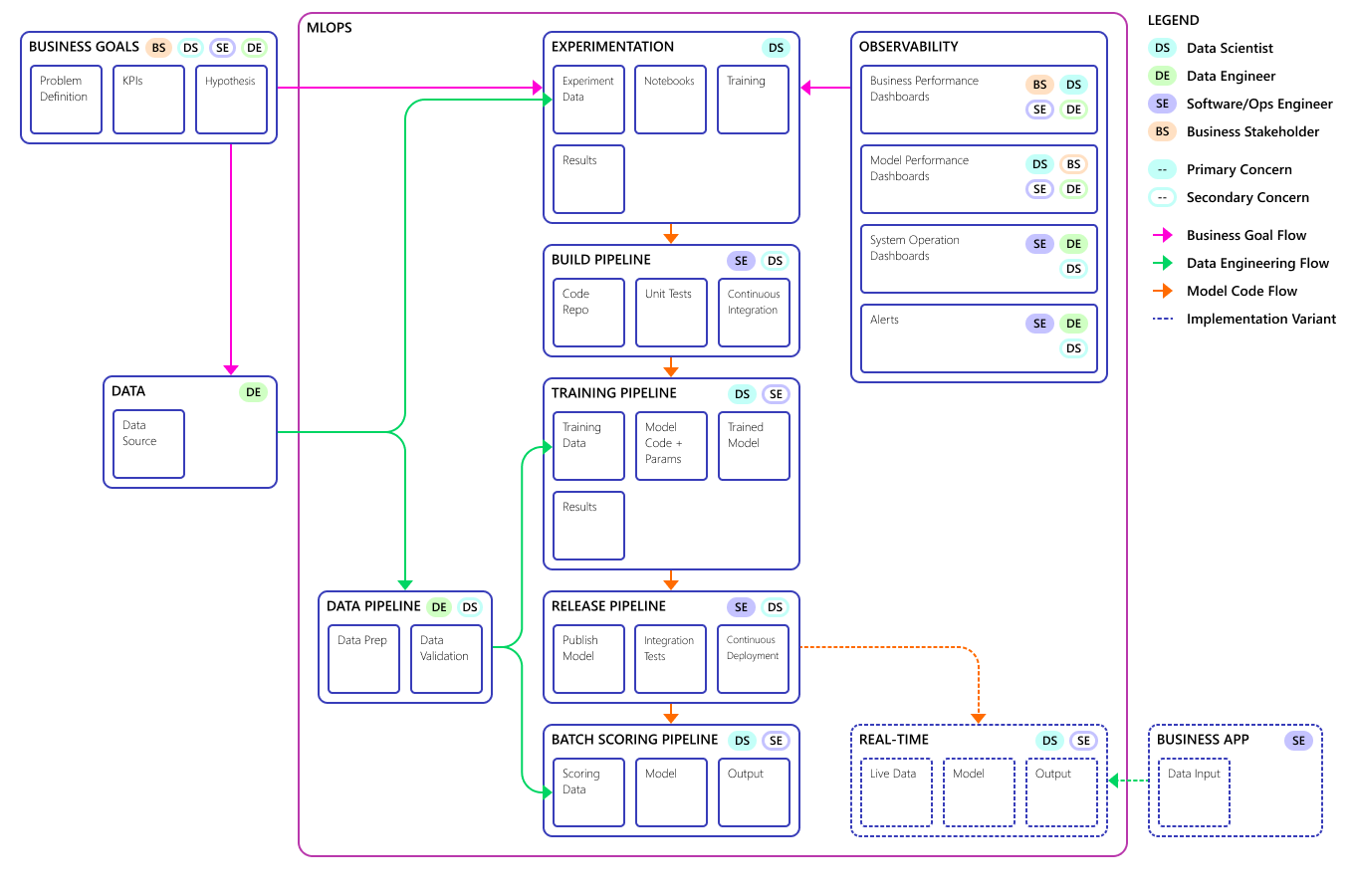
Ważne
Ocenianie jest ostatnim krokiem. Proces uruchamia model uczenia maszynowego w celu przewidywania. Dotyczy to podstawowego wymagania przypadku użycia biznesowego na potrzeby prognozowania zapotrzebowania. Zespół ocenia jakość przewidywań przy użyciu mapE, która jest miarą dokładności przewidywania metod prognozowania statystycznego i funkcji utraty dla problemów regresji w uczeniu maszynowym. W tym projekcie zespół uznał MAPE za <45% znaczący.
Przepływ procesów MLOps
Na poniższym diagramie opisano sposób stosowania przepływów pracy programowania ciągłej integracji/ciągłego wdrażania do cyklu życia uczenia maszynowego:
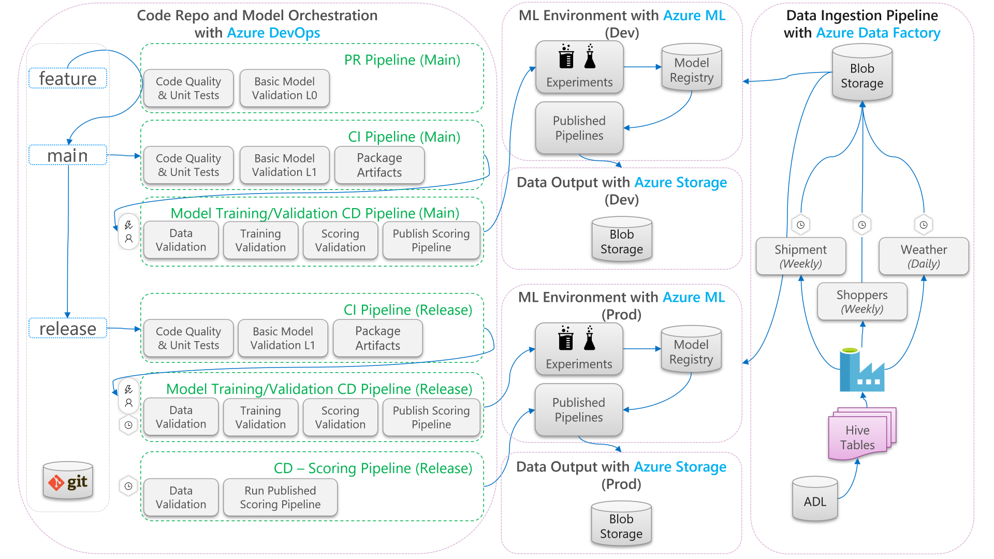
- Po utworzeniu żądania ściągnięcia na podstawie gałęzi funkcji potok uruchamia testy weryfikacyjne kodu w celu zweryfikowania jakości kodu za pomocą testów jednostkowych i testów jakości kodu. Aby zweryfikować jakość nadrzędną, potok uruchamia również podstawowe testy weryfikacji modelu w celu zweryfikowania kompleksowego trenowania i oceniania kroków z przykładowym zestawem pozorowanych danych.
- Po scaleniu żądania ściągnięcia z gałęzią główną potok ciągłej integracji uruchomi te same testy weryfikacji kodu i podstawowe testy weryfikacji modelu z większą epoką. Następnie potok spakuje artefakty, które obejmują kod i pliki binarne, które będą uruchamiane w środowisku uczenia maszynowego.
- Po udostępnieniu artefaktów zostanie wyzwolony potok ciągłej walidacji modelu. Jest ona uruchamiana kompleksowa walidacja w środowisku uczenia maszynowego programowania. Opublikowano mechanizm oceniania. W przypadku scenariusza oceniania wsadowego potok oceniania jest publikowany w środowisku uczenia maszynowego i wyzwalany w celu wygenerowania wyników. Jeśli chcesz użyć scenariusza oceniania w czasie rzeczywistym, możesz opublikować aplikację internetową lub wdrożyć kontener.
- Po utworzeniu i scaleniu punktu kontrolnego z gałęzią wydania zostanie wyzwolony ten sam potok ciągłej integracji i potok ciągłej weryfikacji modelu ciągłej integracji. Tym razem są uruchamiane względem kodu z gałęzi wydania.
Przepływ danych procesu MLOps pokazany powyżej można wziąć pod uwagę jako struktura archetypu dla projektów, które mają podobne wybory architektoniczne.
Testy sprawdzania poprawności kodu
Testy poprawności kodu na potrzeby uczenia maszynowego koncentrują się na weryfikowaniu jakości bazy kodu. Jest to taka sama koncepcja jak każdy projekt inżynieryjny, który ma testy jakości kodu (linting), testy jednostkowe i pomiary pokrycia kodu.
Podstawowe testy weryfikacji modelu
Walidacja modelu zwykle odnosi się do weryfikowania pełnych kroków procesu wymaganych do utworzenia prawidłowego modelu uczenia maszynowego. Zawiera on następujące kroki:
- Weryfikacja danych: zapewnia, że dane wejściowe są prawidłowe.
- Walidacja trenowania: gwarantuje, że model można pomyślnie wytrenować.
- Walidacja oceniania: gwarantuje, że zespół może pomyślnie użyć wytrenowanego modelu do oceniania danych wejściowych.
Uruchomienie tego pełnego zestawu kroków w środowisku uczenia maszynowego jest kosztowne i czasochłonne. W rezultacie zespół wykonał podstawowe testy weryfikacji modelu lokalnie na maszynie dewelopera. Uruchomiono powyższe kroki i użyto następujących czynności:
- Lokalny zestaw danych testowania: mały zestaw danych, często zaciemniony, który jest zaewidencjonowany w repozytorium i używany jako źródło danych wejściowych.
- Flaga lokalna: flaga lub argument w kodzie modelu, który wskazuje, że kod zamierza uruchomić zestaw danych lokalnie. Flaga nakazuje kodowi obejście dowolnego wywołania środowiska uczenia maszynowego.
Celem tych testów weryfikacyjnych nie jest ocena wydajności wytrenowanego modelu. Zamiast tego należy sprawdzić, czy kod kompleksowego procesu ma dobrą jakość. Zapewnia jakość kodu, który jest wypychany w górę, podobnie jak włączenie testów weryfikacji modelu w kompilacji żądania ściągnięcia i ciągłej integracji. Umożliwia również inżynierom i analitykom danych umieszczenie punktów przerwania w kodzie na potrzeby debugowania.
Potok ciągłego wdrażania weryfikacji modelu
Celem potoku weryfikacji modelu jest zweryfikowanie kompleksowego trenowania i oceniania modeli w środowisku uczenia maszynowego z rzeczywistymi danymi. Każdy wygenerowany wytrenowany model zostanie dodany do rejestru modeli i oznaczony tagiem w celu oczekiwania na podwyższenie poziomu po zakończeniu walidacji. W przypadku przewidywania wsadowego podwyższanie poziomu może być publikowaniem potoku oceniania, który używa tej wersji modelu. W przypadku oceniania w czasie rzeczywistym można oznaczyć model, aby wskazać, że został promowany.
Potok ciągłego oceniania
Potok oceniania ciągłego wdrażania ma zastosowanie do scenariusza wnioskowania wsadowego, w którym ten sam koordynator modelu używany do walidacji modelu wyzwala opublikowany potok oceniania.
Programowanie a środowiska produkcyjne
Dobrym rozwiązaniem jest oddzielenie środowiska programistycznego (deweloperskiego) od środowiska produkcyjnego (prod). Separacja umożliwia systemowi wyzwalanie potoku ciągłego wdrażania weryfikacji modelu i ocenianie potoku ciągłego wdrażania według różnych harmonogramów. W przypadku opisanego przepływu metodyki MLOps potoki przeznaczone dla głównej gałęzi są uruchamiane w środowisku deweloperskim, a potok przeznaczony dla gałęzi wydania działa w środowisku prod.
Zmiany kodu a zmiany danych
Poprzednie sekcje dotyczą głównie sposobu obsługi zmian kodu z programowania na wydanie. Jednak zmiany danych powinny być zgodne z tym samym rygorem co zmiany kodu, aby zapewnić taką samą jakość walidacji i spójność w środowisku produkcyjnym. Za pomocą wyzwalacza zmiany danych lub wyzwalacza czasomierza system może wyzwolić potok ciągłego wdrażania weryfikacji modelu i potok ciągłego wdrażania oceniania z orkiestratora modelu, aby uruchomić ten sam proces, który jest uruchamiany dla zmian kodu w środowisku prod gałęzi wydania.
Osoby i role metodyki MLOps
Kluczowym wymaganiem dla każdego procesu MLOps jest spełnienie wymagań wielu użytkowników procesu. W celach projektowych należy wziąć pod uwagę tych użytkowników jako osoby indywidualne. W przypadku tego projektu zespół zidentyfikował te osoby:
- Analityk danych: tworzy model uczenia maszynowego i jego algorytmy.
- Inżynier
- Inżynier danych: obsługuje klimatyzację danych.
- Inżynier oprogramowania: obsługuje integrację modelu z pakietem zasobów i przepływem pracy ciągłej integracji/ciągłego wdrażania.
- Operacje lub dział IT: nadzoruje operacje systemowe.
- Uczestnik projektu biznesowego: zaniepokojony przewidywaniami modelu uczenia maszynowego i sposobem, w jaki pomagają firmie.
- Użytkownik końcowy danych: w jakiś sposób korzysta z danych wyjściowych modelu, które ułatwiają podejmowanie decyzji biznesowych.
Zespół musiał rozwiązać trzy kluczowe ustalenia z badań persona i role:
- Analitycy danych i inżynierowie mają niezgodność podejścia i umiejętności w swojej pracy. Ułatwianie analitykowi danych i inżynierowi współpracy jest głównym czynnikiem do projektowania przepływu procesów MLOps. Wymaga to nowych umiejętności nabycia przez wszystkich członków zespołu.
- Istnieje potrzeba ujednolicenia wszystkich głównych osób bez alienacji nikogo. Aby to zrobić, należy wykonać następujące czynności:
- Upewnij się, że rozumieją model koncepcyjny metodyki MLOps.
- Uzgodnij członków zespołu, którzy będą współpracować.
- Ustanów wytyczne robocze w celu osiągnięcia wspólnych celów.
- Jeśli uczestnik projektu biznesowego i dane użytkownika końcowego potrzebują sposobu interakcji z danymi wyjściowymi z modeli, przyjazny dla użytkownika interfejs użytkownika jest standardowym rozwiązaniem.
Inne zespoły z pewnością napotkają podobne problemy w innych projektach uczenia maszynowego podczas skalowania w górę do użytku produkcyjnego.
Architektura rozwiązania MLOps
Architektura logiczna
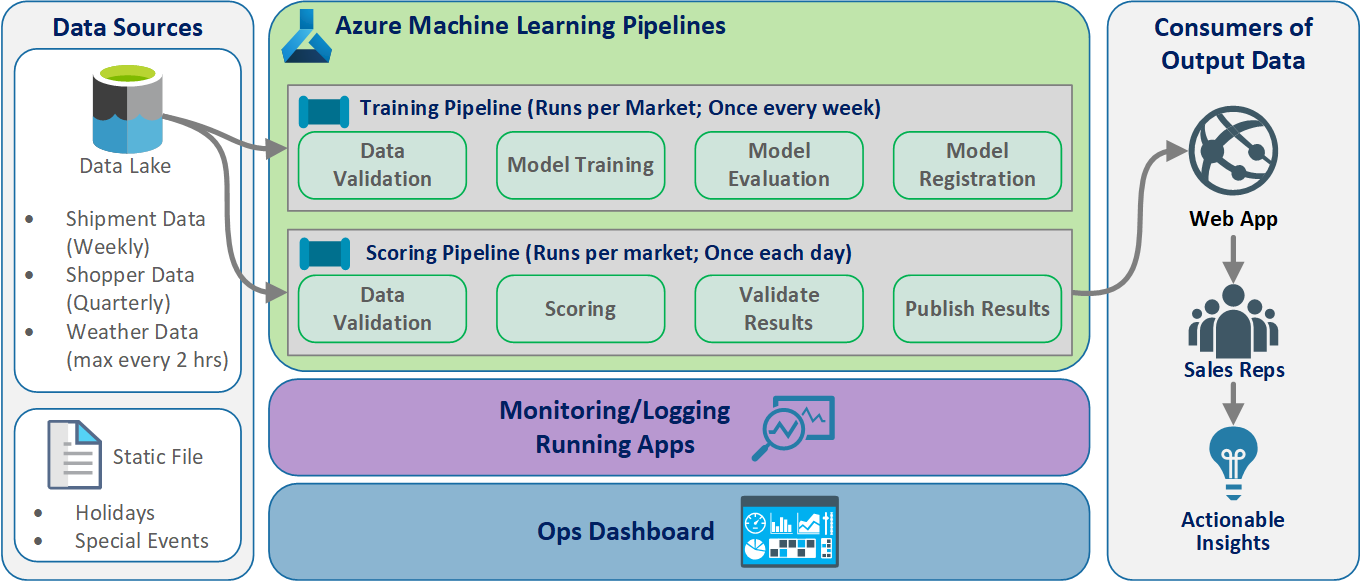
Dane pochodzą z wielu źródeł w wielu różnych formatach, więc są warunekowane przed wstawieniem ich do usługi Data Lake. Kondycja jest wykonywana przy użyciu mikrousług działających jako usługa Azure Functions. Klienci dostosowują mikrousługi do źródeł danych i przekształcają je w standardowy format csv używany przez potoki trenowania i oceniania.
Architektura systemu
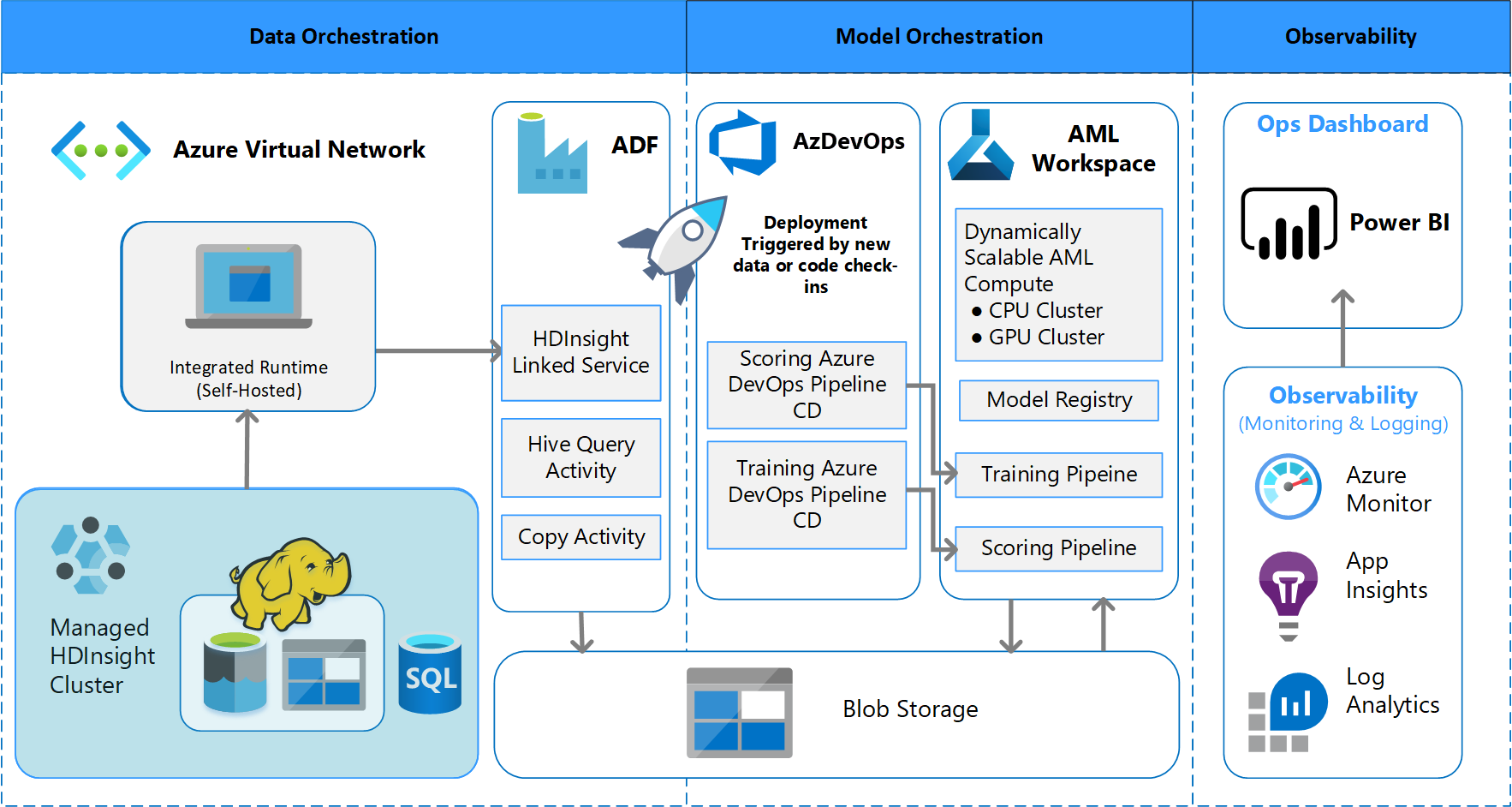
Architektura przetwarzania wsadowego
Zespół opracował projekt architektury w celu obsługi schematu przetwarzania danych wsadowych. Istnieją alternatywy, ale niezależnie od tego, co jest używane, musi obsługiwać procesy MLOps. Pełne korzystanie z dostępnych usług platformy Azure było wymaganiem projektowym. Na poniższym diagramie przedstawiono architekturę:
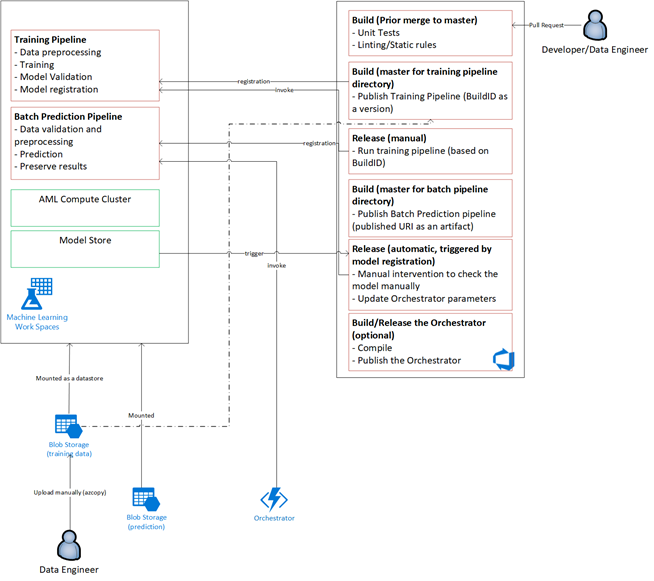
Omówienie rozwiązania
Usługa Azure Data Factory wykonuje następujące czynności:
- Wyzwala funkcję platformy Azure w celu rozpoczęcia pozyskiwania danych i uruchomienia potoku usługi Azure Machine Learning.
- Uruchamia trwałą funkcję sondowania potoku usługi Azure Machine Learning w celu ukończenia.
Niestandardowe pulpity nawigacyjne w usłudze Power BI wyświetlają wyniki. Inne pulpity nawigacyjne platformy Azure połączone z usługami Azure SQL, Azure Monitor i App Insights za pośrednictwem zestawu OpenCensus Python SDK śledzą zasoby platformy Azure. Te pulpity nawigacyjne zawierają informacje o kondycji systemu uczenia maszynowego. Dają one również dane używane przez klienta do prognozowania zamówień produktów.
Aranżacja modelu
Orkiestracja modelu jest zgodna z następującymi krokami:
- Po przesłaniu żądania ściągnięcia metodyka DevOps wyzwala potok weryfikacji kodu.
- Potok uruchamia testy jednostkowe, testy jakości kodu i testy weryfikacji modelu.
- Po scaleniu z gałęzią główną są uruchamiane te same testy sprawdzania poprawności kodu, a metodyka DevOps pakuje artefakty.
- Zbieranie artefaktów w usłudze DevOps wyzwala usługę Azure Machine Learning w celu wykonania:
- Weryfikacja danych.
- Walidacja trenowania.
- Sprawdzanie poprawności oceniania.
- Po zakończeniu walidacji końcowy potok oceniania zostanie uruchomiony.
- Zmiana danych i przesłanie nowego żądania ściągnięcia ponownie wyzwoli potok weryfikacji, a następnie końcowy potok oceniania.
Włączanie eksperymentowania
Jak wspomniano, tradycyjny cykl życia uczenia maszynowego do nauki o danych nie obsługuje procesu MLOps bez modyfikacji. Używa różnych rodzajów narzędzi ręcznych i eksperymentowania, walidacji, pakowania i przekazywania modelu, które nie mogą być łatwo skalowane w celu efektywnego procesu ciągłej integracji/ciągłego wdrażania. Metodyka MLOps wymaga wysokiego poziomu automatyzacji procesów. Niezależnie od tego, czy jest opracowywany nowy model uczenia maszynowego, czy stary jest modyfikowany, konieczne jest zautomatyzowanie cyklu życia modelu uczenia maszynowego. W projekcie fazy 2 zespół użył usługi Azure DevOps do organizowania i ponownego publikowania potoków usługi Azure Machine Learning na potrzeby zadań szkoleniowych. Długotrwała gałąź główna wykonuje podstawowe testy modeli i wypycha stabilne wersje za pośrednictwem długotrwałej gałęzi wydania.
Kontrola źródła staje się ważną częścią tego procesu. Git to system kontroli wersji używany do śledzenia notesu i kodu modelu. Obsługuje również automatyzację procesów. Podstawowy przepływ pracy implementowany na potrzeby kontroli źródła stosuje następujące zasady:
- Użyj formalnego przechowywania wersji dla kodu i zestawów danych.
- Użyj gałęzi do tworzenia nowego kodu, dopóki kod nie zostanie w pełni opracowany i zweryfikowany.
- Po zweryfikowaniu nowego kodu można go scalić z gałęzią główną.
- W przypadku wydania tworzona jest stała gałąź wersjonowana, która jest oddzielona od gałęzi głównej.
- Użyj wersji i kontroli źródła dla zestawów danych, które zostały warunekowane na potrzeby trenowania lub użycia, aby zachować integralność każdego zestawu danych.
- Użyj kontroli źródła, aby śledzić eksperymenty programu Jupyter Notebook.
Integracja ze źródłami danych
Analitycy danych używają wielu nieprzetworzonych źródeł danych i przetworzonych zestawów danych do eksperymentowania z różnymi modelami uczenia maszynowego. Ilość danych w środowisku produkcyjnym może być przytłaczająca. Aby analitycy danych eksperymentowali z różnymi modelami, muszą używać narzędzi do zarządzania, takich jak Usługa Azure Data Lake. Wymóg formalnej identyfikacji i kontroli wersji dotyczy wszystkich nieprzetworzonych danych, przygotowanych zestawów danych i modeli uczenia maszynowego.
W projekcie analitycy danych warunekowali następujące dane dotyczące danych wejściowych do modelu:
- Historyczne dane dotyczące wysyłki tygodniowej od stycznia 2017 r.
- Historyczne i prognozowane dzienne dane pogodowe dla każdego kodu pocztowego
- Dane kupujących dla każdego identyfikatora sklepu
Integracja z kontrolą źródła
Aby analitycy danych mogli zastosować najlepsze rozwiązania inżynieryjne, należy wygodnie zintegrować narzędzia używane z systemami kontroli źródła, takimi jak GitHub. Ta praktyka pozwala na przechowywanie wersji modelu uczenia maszynowego, współpracę między członkami zespołu i odzyskiwanie po awarii, jeśli zespoły doświadczają utraty danych lub awarii systemu.
Obsługa zespołu modeli
Projekt modelu w tym projekcie był modelem zespołowym. Oznacza to, że analitycy danych używali wielu algorytmów w końcowym projekcie modelu. W tym przypadku modele używały tego samego podstawowego projektu algorytmu. Jedyną różnicą było to, że używali różnych danych treningowych i danych oceniania. Modele używały kombinacji algorytmu regresji liniowej LASSO i sieci neuronowej.
Zespół zbadał, ale nie zaimplementował, opcję przeniesienia procesu do punktu, w którym będzie obsługiwać wiele modeli w czasie rzeczywistym uruchomionych w środowisku produkcyjnym w celu obsługi danego żądania. Ta opcja może pomieścić użycie modeli zespołowych w testach A/B i przeplatanych eksperymentach.
Interfejsy użytkownika końcowego
Zespół opracował interfejsy użytkownika końcowego w celu obserwowania, monitorowania i instrumentacji. Jak wspomniano, pulpity nawigacyjne wizualnie wyświetlają dane modelu uczenia maszynowego. Te pulpity nawigacyjne pokazują następujące dane w formacie przyjaznym dla użytkownika:
- Kroki potoku, w tym wstępne przetwarzanie danych wejściowych.
- Aby monitorować kondycję przetwarzania modelu uczenia maszynowego:
- Jakie metryki są zbierane z wdrożonego modelu?
- MAPE: Średni bezwzględny błąd procentowy, kluczowa metryka do śledzenia ogólnej wydajności. (Cel wartości <MAPE = 0,45 dla każdego modelu).
- RMSE 0: błąd średniokwadratowy (RMSE), gdy rzeczywista wartość docelowa = 0.
- Wszystkie usługi RMSE: RMSE w całym zestawie danych.
- Jak ocenić, czy model działa zgodnie z oczekiwaniami w środowisku produkcyjnym?
- Czy istnieje sposób na określenie, czy dane produkcyjne odbiegają zbytnio od oczekiwanych wartości?
- Czy model działa słabo w środowisku produkcyjnym?
- Czy masz stan trybu failover?
- Jakie metryki są zbierane z wdrożonego modelu?
- Śledzenie jakości przetworzonych danych.
- Wyświetl wyniki/przewidywania utworzone przez model uczenia maszynowego.
Aplikacja wypełnia pulpity nawigacyjne zgodnie z charakterem danych oraz sposobem przetwarzania i analizowania danych. W związku z tym zespół musi zaprojektować dokładny układ pulpitów nawigacyjnych dla każdego przypadku użycia. Oto dwa przykładowe pulpity nawigacyjne:
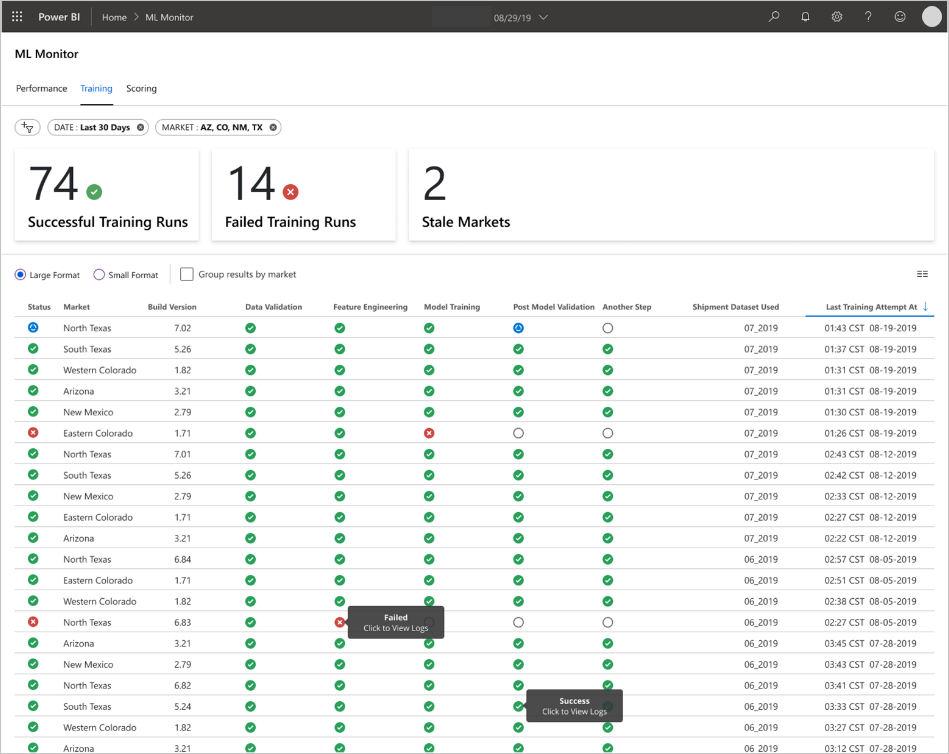
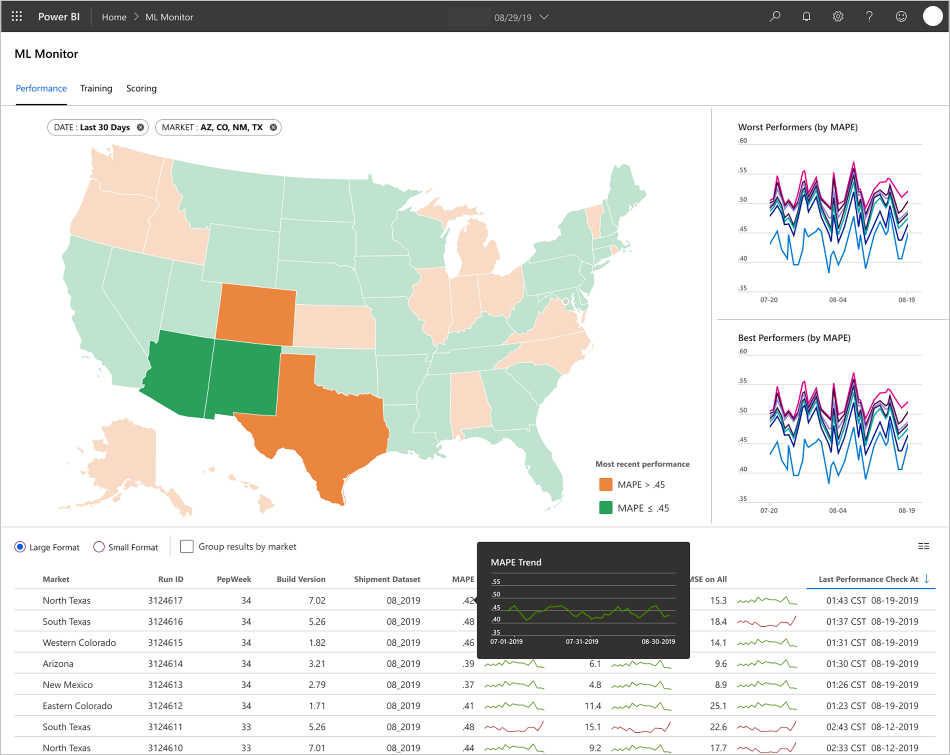
Pulpity nawigacyjne zostały zaprojektowane w celu zapewnienia łatwo używanych informacji do użycia przez użytkownika końcowego przewidywań modelu uczenia maszynowego.
Uwaga
Nieaktualne modele oceniają przebiegi, w których analitycy danych wytrenowali model używany do oceniania ponad 60 dni od momentu, gdy miało miejsce ocenianie. Na stronie Ocenianie pulpitu nawigacyjnego Monitor uczenia maszynowego jest wyświetlana ta metryka kondycji.
Składniki
- Azure Machine Learning
- Azure Blob Storage
- Azure Data Lake Storage
- Azure Pipelines
- Azure Data Factory
- Usługa Azure Functions dla języka Python
- Azure Monitor
- Azure SQL Database
- Pulpity nawigacyjne platformy Azure
- Power BI
Kwestie wymagające rozważenia
W tym miejscu znajdziesz listę zagadnień do zbadania. Są one oparte na lekcjach, które zespół CSE nauczył się podczas projektu.
Zagadnienia dotyczące środowiska
- Analitycy danych opracowują większość modeli uczenia maszynowego przy użyciu języka Python, często zaczynając od notesów Jupyter. Wdrożenie tych notesów jako kodu produkcyjnego może być wyzwaniem. Notesy Jupyter to bardziej eksperymentalne narzędzie, a skrypty języka Python są bardziej odpowiednie dla środowiska produkcyjnego. Zespoły często muszą poświęcić czas na refaktoryzację kodu tworzenia modelu do skryptów języka Python.
- Klienci, którzy są nowi w metodyce DevOps i uczeniu maszynowym, wiedzą, że eksperymentowanie i produkcja wymagają różnych rygorów, dlatego dobrym rozwiązaniem jest oddzielenie tych dwóch.
- Narzędzia takie jak Projektant visual Designer lub AutoML usługi Azure Machine Learning mogą być skuteczne w uzyskiwaniu podstawowych modeli poza ziemią, podczas gdy klient zwiększa możliwości standardowych rozwiązań DevOps, aby zastosować je do pozostałej części rozwiązania.
- Usługa Azure DevOps ma wtyczki, które można zintegrować z usługą Azure Machine Learning, aby ułatwić wyzwalanie kroków potoku. Repozytorium MLOpsPython zawiera kilka przykładów takich potoków.
- Uczenie maszynowe często wymaga zaawansowanych maszyn procesora graficznego (GPU) do trenowania. Jeśli klient nie ma jeszcze takiego sprzętu, klastry obliczeniowe usługi Azure Machine Learning mogą zapewnić efektywną ścieżkę do szybkiego aprowizowania ekonomicznego zaawansowanego sprzętu, który automatycznie skaluje. Jeśli klient ma zaawansowane potrzeby w zakresie zabezpieczeń lub monitorowania, istnieją inne opcje, takie jak standardowe maszyny wirtualne, usługa Databricks lub lokalne obliczenia.
- Aby klient zakończył się sukcesem, ich zespoły tworzące modele (analitycy danych) i zespoły wdrożeniowe (inżynierowie DevOps) muszą mieć silny kanał komunikacyjny. Mogą to osiągnąć za pomocą codziennych spotkań stand-up lub formalnej usługi czatu online. Oba podejścia pomagają w integrowaniu wysiłków programistycznych w strukturze MLOps.
Zagadnienia dotyczące przygotowywania danych
Najprostszym rozwiązaniem do korzystania z usługi Azure Machine Learning jest przechowywanie danych w obsługiwanym rozwiązaniu magazynu danych. Narzędzia, takie jak Azure Data Factory, są skuteczne w przypadku potokowania danych do i z tych lokalizacji zgodnie z harmonogramem.
Ważne jest, aby klienci często przechwytywali dodatkowe dane ponownego trenowania, aby zapewnić aktualność modeli. Jeśli nie mają jeszcze potoku danych, utworzenie tego potoku będzie ważną częścią ogólnego rozwiązania. Użycie rozwiązania, takiego jak Zestawy danych w usłudze Azure Machine Learning, może być przydatne w przypadku przechowywania wersji danych, aby ułatwić śledzenie modeli.
Zagadnienia dotyczące trenowania i oceny modelu
Jest to przytłaczające dla klienta, który dopiero zaczyna pracę w swojej podróży uczenia maszynowego, aby spróbować zaimplementować pełny potok MLOps. W razie potrzeby mogą ułatwić sobie korzystanie z usługi Azure Machine Learning w celu śledzenia przebiegów eksperymentów i używania obliczeń usługi Azure Machine Learning jako celu trenowania. Te opcje mogą stworzyć niższą barierę wejścia rozwiązania, aby rozpocząć integrowanie usług platformy Azure.
Przejście z eksperymentu notesu do powtarzalnych skryptów jest trudnym przejściem dla wielu analityków danych. Im szybciej będzie można napisać kod szkoleniowy w skryptach języka Python, tym łatwiej będzie im rozpocząć przechowywanie wersji kodu szkoleniowego i włączenie ponownego trenowania.
To nie jest jedyna możliwa metoda. Usługa Databricks obsługuje planowanie notesów jako zadań. Jednak w oparciu o bieżące środowisko klienta takie podejście jest trudne do instrumentacji z pełnymi praktykami DevOps z powodu ograniczeń testowania.
Ważne jest również, aby zrozumieć, jakie metryki są używane do rozważenia sukcesu modelu. Sama dokładność nie jest wystarczająco dobra, aby określić ogólną wydajność jednego modelu w porównaniu z drugim.
Zagadnienia dotyczące obliczeń
- Klienci powinni rozważyć użycie kontenerów do standaryzacji środowisk obliczeniowych. Prawie wszystkie cele obliczeniowe usługi Azure Machine Learning obsługują korzystanie z platformy Docker. Posiadanie kontenera dojścia do zależności może znacznie zmniejszyć tarcie, zwłaszcza jeśli zespół korzysta z wielu celów obliczeniowych.
Zagadnienia dotyczące obsługi modeli
- Zestaw SDK usługi Azure Machine Learning udostępnia opcję wdrażania bezpośrednio w usłudze Azure Kubernetes Service (AKS) z zarejestrowanego modelu, co pozwala ograniczyć bezpieczeństwo/metryki. Możesz spróbować znaleźć łatwiejsze rozwiązanie dla klientów, aby przetestować swój model, ale najlepiej jest opracować bardziej niezawodne wdrożenie w usłudze AKS dla obciążeń produkcyjnych.
Następne kroki
- Dowiedz się więcej o metodyce MLOps
- Metodyka MLOps na platformie Azure
- Wizualizacje usługi Azure Monitor
- Cykl życia uczenia maszynowego
- Rozszerzenie usługi Azure DevOps Machine Learning
- Interfejs wiersza polecenia usługi Azure Machine Learning
- Wyzwalanie aplikacji, procesów lub przepływów pracy ciągłej integracji/ciągłego wdrażania na podstawie zdarzeń usługi Azure Machine Learning
- Konfigurowanie trenowania i wdrażania modelu za pomocą usługi Azure DevOps
Powiązane zasoby
- Model dojrzałości MLOps
- Organizowanie metodyki MLOps w usłudze Azure Databricks przy użyciu notesu usługi Databricks
- Metodyka MLOps dla modeli języka Python korzystających z usługi Azure Machine Learning
- Nauka o danych i uczenie maszynowe za pomocą usługi Azure Databricks
- Citizen AI with the Power Platform
- Wdrażanie sztucznej inteligencji i obliczeń uczenia maszynowego w środowisku lokalnym i na brzegu sieci