Sztuczna inteligencja oferuje potencjał transformacji handlu detalicznego, ponieważ wiemy o tym dzisiaj. Rozsądnie jest sądzić, że sprzedawcy detaliczni opracują architekturę środowiska klienta obsługiwaną przez sztuczną inteligencję. Niektóre oczekiwania są następujące, że platforma rozszerzona o sztuczną inteligencję zapewni wzrost przychodów ze względu na hiper personalizację. Handel cyfrowy nadal zwiększa oczekiwania klientów, preferencje i zachowanie. Wymagania, takie jak zaangażowanie w czasie rzeczywistym, odpowiednie rekomendacje i hiper-personalizacja są szybkie i wygodne po kliknięciu przycisku. Włączamy analizę w aplikacjach za pomocą naturalnej mowy, wizji itd. Ta analiza umożliwia ulepszenia w handlu detalicznym, które zwiększą wartość podczas zakłócania sposobu, w jaki klienci kupują.
Ten dokument koncentruje się na koncepcji sztucznej inteligencji wyszukiwania wizualnego i oferuje kilka kluczowych zagadnień dotyczących jego implementacji. Udostępnia przykład przepływu pracy i mapuje swoje etapy na odpowiednie technologie platformy Azure. Koncepcja opiera się na tym, że klienci mogą korzystać z obrazu, który jest wykonywany z urządzeniem przenośnym lub znajduje się w Internecie. Przeprowadziliby poszukiwania odpowiednich elementów i podobnych, w zależności od intencji doświadczenia. W związku z tym wyszukiwanie wizualne zwiększa szybkość wprowadzania tekstu do obrazu z wieloma punktami metadanych, aby szybko wyświetlić wszystkie dostępne elementy.
Wyszukiwarki wizualne
Wyszukiwarki wizualne pobierają informacje z obrazów jako dane wejściowe i często — ale nie wyłącznie — jako dane wyjściowe.
Silniki stają się coraz bardziej powszechne w branży detalicznej i z bardzo dobrych powodów:
- Około 75% użytkowników Internetu szuka zdjęć lub filmów wideo produktu przed dokonaniem zakupu, zgodnie z raportem Emarketer opublikowanym w 2017 roku.
- 74% konsumentów znajduje również nieefektywne wyszukiwanie tekstu, zgodnie z raportem Slyce (firmy wyszukiwania wizualnego) 2015.
W związku z tym rynek rozpoznawania obrazów będzie wart ponad 25 miliardów dolarów do 2019 r., zgodnie z badaniami rynków i rynków.
Technologia ta miała już duże marki handlu elektronicznego, które również przyczyniły się znacząco do rozwoju. Najwybitniejszymi wczesnymi adopterami są prawdopodobnie:
- Serwis eBay ze swoimi narzędziami wyszukiwania obrazów i "Znajdź go w serwisie eBay" w swojej aplikacji (jest to obecnie tylko środowisko mobilne).
- Pinterea z narzędziem do odnajdywania wizualnego Lens.
- Firma Microsoft z wyszukiwaniem wizualnym Bing.
Wdrażanie i dostosowywanie
Na szczęście nie potrzebujesz ogromnych ilości mocy obliczeniowej, aby czerpać korzyści z wyszukiwania wizualnego. Każda firma z wykazem obrazów może korzystać z wiedzy firmy Microsoft dotyczącej sztucznej inteligencji wbudowanej w jej usługi platformy Azure.
Interfejs API wyszukiwania wizualnego Bing umożliwia wyodrębnianie informacji kontekstowych z obrazów, identyfikowanie — na przykład — mebli domowych, mody, różnych rodzajów produktów itd.
Zwróci również wizualnie podobne obrazy z własnego katalogu, produkty ze względnymi źródłami zakupów, powiązane wyszukiwania. Chociaż jest to interesujące, będzie to ograniczone użycie, jeśli firma nie jest jednym z tych źródeł.
Usługa Bing zapewni również:
- Tagi, które umożliwiają eksplorowanie obiektów lub pojęć znalezionych na obrazie.
- Pola ograniczenia dla regionów zainteresowania obrazem (na przykład dla przedmiotów odzieżowych lub mebli).
Możesz podjąć te informacje, aby znacznie zmniejszyć obszar wyszukiwania (i czas) do wykazu produktów firmy, ograniczając je do obiektów takich jak te w regionie i kategorii zainteresowania.
Implementowanie własnych
Podczas implementowania wyszukiwania wizualnego należy wziąć pod uwagę kilka kluczowych składników:
- Pozyskiwanie i filtrowanie obrazów
- Techniki magazynowania i pobierania
- Cechowanie, kodowanie lub "skrótowanie"
- Miary podobieństwa lub odległości i klasyfikacja
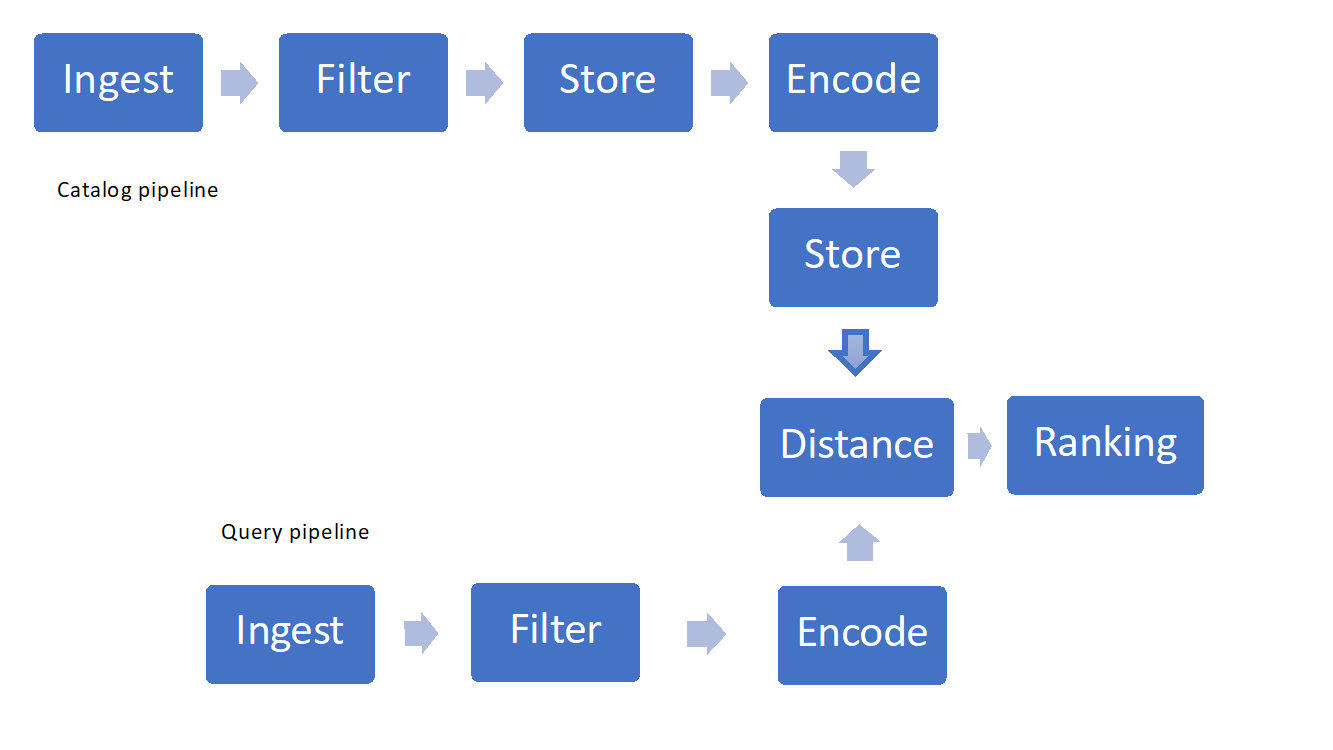
Rysunek 1. Przykład potoku wyszukiwania wizualnego
Określanie źródła obrazów
Jeśli nie jesteś właścicielem katalogu obrazów, może być konieczne trenowanie algorytmów na otwartych dostępnych zestawach danych, takich jak moda MNIST, głęboka moda itd. Zawierają one kilka kategorii produktów i są często używane do porównywania klasyfikacji obrazów i algorytmów wyszukiwania.

Rysunek 2. Przykład z zestawu danych DeepFashion
Filtrowanie obrazów
Większość zestawów danych testów porównawczych, takich jak wymienione wcześniej, została już wstępnie przetworzona.
Jeśli tworzysz własny test porównawczy, co najmniej chcesz, aby obrazy miały taki sam rozmiar, głównie podyktowane danymi wejściowymi, dla których został wytrenowany model.
W wielu przypadkach najlepiej jest również znormalizować jasność obrazów. W zależności od poziomu szczegółów wyszukiwania kolor może być również nadmiarowy, więc zmniejszenie liczby czarnych i białych pomoże w czasie przetwarzania.
Na koniec jednak zestaw danych obrazów powinien być zrównoważony w różnych klasach, które reprezentuje.
Baza danych obrazów
Warstwa danych jest szczególnie delikatnym składnikiem architektury. Będzie on zawierać:
- Obrazy
- Wszelkie metadane dotyczące obrazów (rozmiar, tagi, jednostki SKU produktu, opis)
- Dane generowane przez model uczenia maszynowego (na przykład wektor liczbowy 4096 na obraz)
Podczas pobierania obrazów z różnych źródeł lub używania kilku modeli uczenia maszynowego w celu uzyskania optymalnej wydajności struktura danych ulegnie zmianie. Dlatego ważne jest, aby wybrać technologię lub kombinację, która może obsługiwać dane częściowo ustrukturyzowane i nie ma ustalonego schematu.
Możesz również wymagać minimalnej liczby przydatnych punktów danych (takich jak identyfikator obrazu lub klucz, jednostka SKU produktu, opis lub pole tagu).
Usługa Azure Cosmos DB oferuje wymaganą elastyczność i różne mechanizmy dostępu dla aplikacji utworzonych na jego podstawie (co pomoże w wyszukiwaniu w katalogu). Należy jednak uważać, aby zapewnić najlepszą cenę/wydajność. Usługa Azure Cosmos DB umożliwia przechowywanie załączników dokumentów, ale istnieje całkowity limit na konto i może to być kosztowna propozycja. Typowym rozwiązaniem jest przechowywanie rzeczywistych plików obrazów w obiektach blob i wstawianie linku do nich w bazie danych. W przypadku usługi Azure Cosmos DB oznacza to utworzenie dokumentu zawierającego właściwości katalogu skojarzone z tym obrazem (takie jak jednostka SKU, tag itd.) oraz załącznik zawierający adres URL pliku obrazu (na przykład w usłudze Azure Blob Storage, OneDrive itd.).
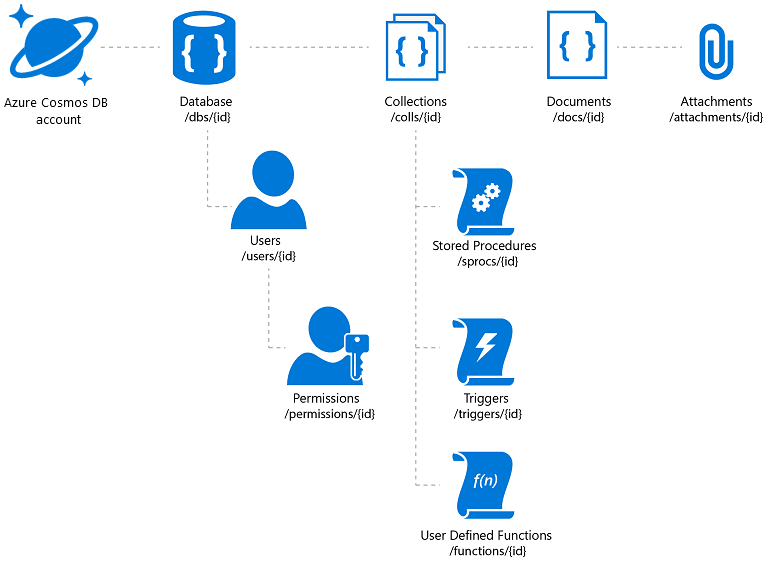
Rysunek 3. Model zasobów hierarchicznych usługi Azure Cosmos DB
Jeśli planujesz skorzystać z globalnej dystrybucji usługi Azure Cosmos DB, pamiętaj, że zreplikuje on dokumenty i załączniki, ale nie połączone pliki. Warto rozważyć sieć dystrybucji zawartości.
Inne odpowiednie technologie to kombinacja usługi Azure SQL Database (jeśli stały schemat jest akceptowalny) i obiektów blob, a nawet tabel i obiektów blob platformy Azure w celu uzyskania niedrogiego i szybkiego przechowywania i pobierania.
Wyodrębnianie i kodowanie funkcji
Proces kodowania wyodrębnia istotne funkcje z obrazów w bazie danych i mapuje każdy z nich na rozrzedliwy wektor "cech" (wektor z wieloma zerami), który może zawierać tysiące składników. Ten wektor jest liczbową reprezentacją cech (takich jak krawędzie i kształty), które scharakteryzują obraz. Jest to związane z kodem.
Techniki wyodrębniania cech zwykle używają mechanizmów uczenia transferowego. Dzieje się tak, gdy wybierasz wstępnie wytrenowana sieć neuronowa, uruchamiaj każdy obraz za jego pośrednictwem i przechowujesz wektor funkcji utworzony z powrotem w bazie danych obrazów. W ten sposób "przenosisz" naukę od tego, kto wytrenuje sieć. Firma Microsoft opracowała i opublikowała kilka wstępnie wytrenowanych sieci, które były szeroko używane do zadań rozpoznawania obrazów, takich jak ResNet50.
W zależności od sieci neuronowej wektor funkcji będzie dłuższy lub mniej długi, dlatego wymagania dotyczące pamięci i magazynu będą się różnić.
Ponadto może się okazać, że różne sieci mają zastosowanie do różnych kategorii, dlatego implementacja wyszukiwania wizualnego może faktycznie generować wektory funkcji o różnym rozmiarze.
Wstępnie wytrenowane sieci neuronowe są stosunkowo łatwe w użyciu, ale mogą nie być tak wydajne, jak model niestandardowy wytrenowany w katalogu obrazów. Te wstępnie wytrenowane sieci są zwykle przeznaczone do klasyfikacji zestawów danych porównawczych, a nie wyszukiwania w określonej kolekcji obrazów.
Można je zmodyfikować i ponownie wytrenować, aby utworzyć zarówno przewidywanie kategorii, jak i gęsty (tj. mniejszy, a nie rozrzedniony) wektor, co będzie bardzo przydatne w celu ograniczenia przestrzeni wyszukiwania, zmniejszenia wymagań dotyczących pamięci i magazynu. Wektory binarne mogą być używane i są często określane jako " skrót semantyczny" — termin pochodzący z kodowania i pobierania dokumentów. Reprezentacja binarna upraszcza dalsze obliczenia.
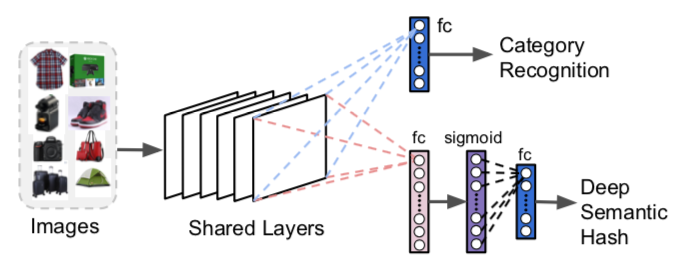
Rysunek 4. Modyfikacje usługi ResNet dla wyszukiwania wizualnego — F. Yang et al., 2017
Niezależnie od tego, czy wybierasz wstępnie wytrenowane modele, czy chcesz opracowywać własne, nadal musisz zdecydować, gdzie uruchomić cechowanie i/lub trenowanie samego modelu.
Platforma Azure oferuje kilka opcji: maszyny wirtualne, usługa Azure Batch, usługa Batch AI, klastry usługi Databricks. We wszystkich przypadkach jednak najlepszym ceną/wydajnością jest użycie procesorów GPU.
Firma Microsoft ogłosiła również niedawno dostępność układów FPGA na potrzeby szybkiego obliczania w ułamku kosztu procesora GPU (projekt Brainwave). Jednak w momencie pisania tego artykułu ta oferta jest ograniczona do niektórych architektur sieci, dlatego należy dokładnie ocenić ich wydajność.
Miara lub odległość podobieństwa
Gdy obrazy są reprezentowane w przestrzeni wektorów funkcji, znalezienie podobieństw staje się kwestią definiowania miary odległości między punktami w takiej przestrzeni. Po zdefiniowaniu odległości można obliczyć klastry podobnych obrazów i/lub zdefiniować macierze podobieństwa. W zależności od wybranej metryki odległości wyniki mogą się różnić. Najczęściej spotykana miara odległości euklidesowej w wektorach liczb rzeczywistych jest na przykład łatwa do zrozumienia: przechwytuje wielkość odległości. Jednak jest to raczej nieefektywne pod względem obliczeń.
Odległość cosinusu jest często używana do przechwytywania orientacji wektora, a nie jego wielkości.
Alternatywy, takie jak odległość Hamming na reprezentacje binarne handlują pewną dokładnością dla wydajności i prędkości.
Połączenie miary rozmiaru i odległości wektorów określi, w jaki sposób będzie intensywnie obciążane obliczenia i pamięć.
Wyszukiwanie i klasyfikowanie
Po zdefiniowaniu podobieństwa musimy opracować wydajną metodę pobierania najbliższych N elementów do elementu przekazanego jako dane wejściowe, a następnie zwrócić listę identyfikatorów. Jest to również nazywane "rankingiem obrazów". W przypadku dużego zestawu danych czas obliczania każdej odległości jest zbyt duży, dlatego używamy przybliżonych algorytmów najbliższych sąsiadów. Istnieje kilka bibliotek typu open source dla tych bibliotek, więc nie trzeba ich kodować od podstaw.
Na koniec wymagania dotyczące pamięci i obliczeń określą wybór technologii wdrażania dla wytrenowanego modelu, a także wysoką dostępność. Zazwyczaj miejsce wyszukiwania zostanie podzielone na partycje, a kilka wystąpień algorytmu klasyfikacji będzie uruchamianych równolegle. Jedną z opcji, która umożliwia skalowalność i dostępność, jest klastry usługi Azure Kubernetes . W takim przypadku zaleca się wdrożenie modelu klasyfikacji w kilku kontenerach (obsługa partycji przestrzeni wyszukiwania w każdym) i kilku węzłach (w celu zapewnienia wysokiej dostępności).
Współautorzy
Ten artykuł jest obsługiwany przez firmę Microsoft. Pierwotnie został napisany przez następujących współautorów.
Autorzy zabezpieczeń:
- Giovanni Marchetti | Menedżer, architekci rozwiązań platformy Azure
- Mariya Zorotovich | Dyrektor ds. obsługi klienta, HLS & Emerging Technology
Inni współautorzy:
- Scott Seely | Architekt oprogramowania
Następne kroki
Implementowanie wyszukiwania wizualnego nie musi być złożone. Możesz użyć usługi Bing lub utworzyć własne z usługami platformy Azure, korzystając z badań i narzędzi sztucznej inteligencji firmy Microsoft.
Programowanie
- Aby rozpocząć tworzenie dostosowanej usługi, zobacz Omówienie interfejsu API wyszukiwania wizualnego Bing
- Aby utworzyć pierwsze żądanie, zobacz przewodniki Szybki start: C# | Java | node.js Python |
- Zapoznaj się z dokumentacją interfejsu API wyszukiwania wizualnego.
Tło
- Głębokie Edukacja Segmentacja obrazów: artykuł firmy Microsoft opisuje proces oddzielania obrazów od tła
- Wyszukiwanie wizualne w Ebay: Badania na Uniwersytecie Cornell
- Visual Discovery w: Pine Cornell University research
- Semantyczne badania na Uniwersytecie Hashing w Toronto