Wzorzec potoków i filtrów
Podziel zadanie wykonujące złożone przetwarzanie na serię oddzielnych elementów, które mogą być używane ponownie. Może to poprawić wydajność, skalowalność i możliwość ponownego zastosowania początkowych kroków, umożliwiając elementy zadań, które wykonują przetwarzanie, które mają być wdrażane i skalowane niezależnie. Wzorzec potoków i filtrów obsługuje wysoki poziom modułowości.
Kontekst i problem
Masz potok sekwencyjnych zadań, które należy przetworzyć. Proste, ale nieelastyczne podejście do implementowania tej aplikacji polega na wykonaniu tego przetwarzania w module monolitycznym. Jednak takie podejście może zmniejszyć możliwości refaktoryzacji kodu, optymalizacji go lub ponownego korzystania z niego, jeśli części tego samego przetwarzania są wymagane w innym miejscu w aplikacji.
Na poniższym diagramie przedstawiono jeden z problemów z przetwarzaniem danych przy użyciu podejścia monolitycznego, brak możliwości ponownego użycia kodu w wielu potokach. W tym przykładzie aplikacja odbiera i przetwarza dane z dwóch źródeł. Oddzielny moduł przetwarza dane z każdego źródła, wykonując szereg zadań w celu przekształcenia danych przed przekazaniem wyniku do logiki biznesowej aplikacji.
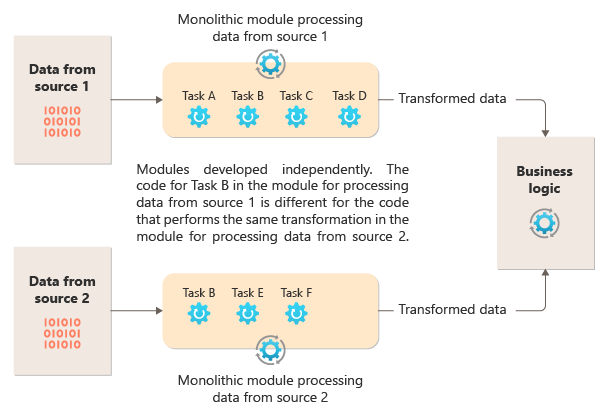
Niektóre zadania wykonywane przez moduły monolityczne są funkcjonalnie podobne, ale kod musi być powtarzany w obu modułach i prawdopodobnie ściśle powiązany w ramach modułu. Oprócz braku możliwości ponownego użycia logiki to podejście wprowadza ryzyko, gdy wymagania się zmienią. Pamiętaj, aby zaktualizować kod w obu miejscach.
Istnieją inne wyzwania związane z implementacją monolityczną niepowiązaną z wieloma potokami lub ponownym użyciem. W przypadku monolitu nie masz możliwości uruchamiania określonych zadań w różnych środowiskach ani skalowania ich niezależnie. Niektóre zadania mogą być intensywnie obciążane obliczeniami i mogą korzystać z pracy na zaawansowanym sprzęcie lub równolegle z wieloma wystąpieniami. Inne zadania mogą nie mieć tych samych wymagań. Ponadto w przypadku monolitów trudno jest zmienić kolejność zadań lub wstrzyknąć nowe zadania w potoku. Te zmiany wymagają ponownego testowania całego potoku.
Rozwiązanie
Podziel przetwarzanie wymagane dla każdego strumienia na zestaw oddzielnych składników (filtrów), z których każdy wykonuje jedno zadanie. Zadania złożone powinny używać wielu filtrów, a nie jednego. Filtry składają się z potoków przez połączenie filtrów z potokami. Filtry są niezależne, samodzielne i zwykle bezstanowe. Filtry odbierają komunikaty z potoku przychodzącego i publikują komunikaty do innego potoku wychodzącego. Filtry mogą przekształcać komunikat lub testować go pod kątem co najmniej jednego kryterium, aby uwzględnić logikę warunkową. Potoki nie wykonują routingu ani żadnej innej logiki. Łączą tylko filtry, przekazując komunikat wyjściowy z jednego filtru jako dane wejściowe do następnego.
Filtry działają niezależnie i nie znają innych filtrów. Są oni świadomi tylko ich schematów wejściowych i wyjściowych. W związku z tym filtry można rozmieścić w dowolnej kolejności, o ile schemat wejściowy dla dowolnego filtru jest zgodny ze schematem wyjściowym poprzedniego filtru. Użycie standardowego schematu dla wszystkich filtrów zwiększa możliwość zmiany kolejności filtrów. Architektura potoków i filtrów zachęca do ponownego używania kompozycji.
Luźne sprzężenie filtrów ułatwia:
- Tworzenie nowych potoków składających się z istniejących filtrów
- Aktualizowanie lub zastępowanie logiki w poszczególnych filtrach
- Zmień kolejność filtrów, w razie potrzeby
- Uruchamianie filtrów na różnym sprzęcie, jeśli jest to wymagane
- Równoległe uruchamianie filtrów
Ten diagram przedstawia rozwiązanie zaimplementowane za pomocą potoków i filtrów:
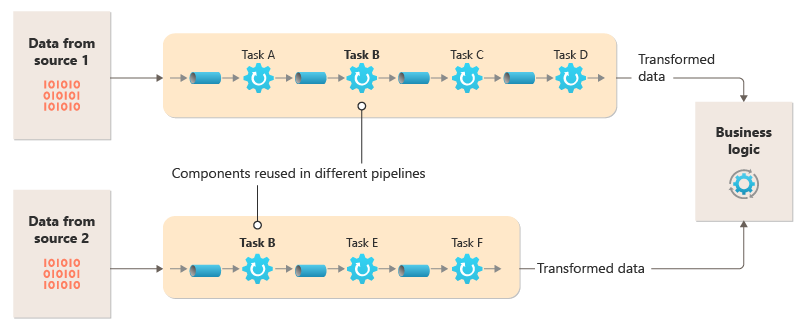
Czas przetwarzania pojedynczego żądania zależy od szybkości najwolniejszych filtrów w potoku. Jeden lub więcej filtrów może być wąskimi gardłami, zwłaszcza jeśli duża liczba żądań pojawia się w strumieniu z określonego źródła danych. Możliwość uruchamiania równoległych wystąpień wolnych filtrów umożliwia systemowi rozłożenie obciążenia i zwiększenie przepływności.
Możliwość uruchamiania filtrów na różnych wystąpieniach obliczeniowych umożliwia ich niezależne skalowanie i korzystanie z elastyczności zapewnianej przez wiele środowisk w chmurze. Filtr intensywnie korzystający z obliczeń może działać na sprzęcie o wysokiej wydajności, podczas gdy inne mniej wymagające filtry mogą być hostowane na mniej kosztownym sprzęcie. Filtry nie muszą nawet znajdować się w tym samym centrum danych lub lokalizacji geograficznej, co umożliwia uruchamianie każdego elementu w potoku w środowisku zbliżonym do potrzebnych zasobów. Te wysiłki wymagają określonych technik projektowych, takich jak obsługa komunikatów, wielowątkowa obsługa itp., aby zmaksymalizować elastyczność każdego potoku lub filtru. Na tym diagramie przedstawiono przykład zastosowany do potoku dla danych ze źródła 1:
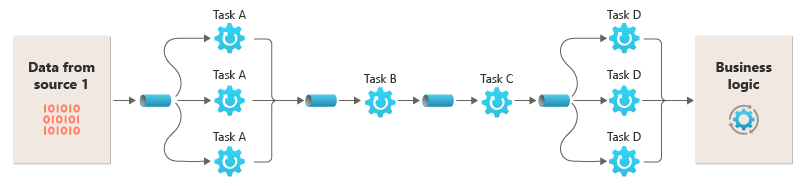
Jeśli dane wejściowe i wyjściowe filtru mają strukturę strumienia, można wykonać przetwarzanie dla każdego filtru równolegle. Pierwszy filtr w potoku może rozpocząć pracę i wyświetlić wyniki, które są przekazywane bezpośrednio do następnego filtru w sekwencji przed ukończeniem pracy pierwszego filtru.
Użycie wzorca Potoki i filtry wraz ze wzorcem transakcji wyrównywczej jest alternatywnym podejściem do implementowania transakcji rozproszonych. Transakcję rozproszoną można podzielić na oddzielne, możliwe do wykonania zadania, z których każdy można zaimplementować za pomocą filtru, który implementuje również wzorzec transakcji wyrównywalnej. Filtry można zaimplementować w potoku jako oddzielne hostowane zadania, które są uruchamiane blisko obsługiwanych danych.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o zaimplementowaniu tego wzorca należy wziąć pod uwagę następujące kwestie:
Monolityczny charakter. Ten wzorzec jest zwykle implementowany jako potok monolityczny, więc w przypadku każdej zmiany cały łańcuch filtrów powinien zostać przetestowany na końcu. Ponadto należy wziąć pod uwagę odporność na uszkodzenia całego procesu; Jeśli filtr lub potok ulegnie awarii, cały potok prawdopodobnie zakończy się niepowodzeniem.
Złożoność. Zwiększona elastyczność zapewniana przez ten wzorzec może także prowadzić do złożoności, szczególnie jeśli filtry w potoku są rozproszone na różnych serwerach.
Niezawodność. Użyj infrastruktury, która zapewnia, że dane przepływające między filtrami w potoku nie zostaną utracone.
Idempotentność. Jeśli filtr w potoku zakończy się niepowodzeniem po otrzymaniu komunikatu, a praca zostanie ponownie zaplanowana na inne wystąpienie filtru, część pracy może już zostać ukończona. Jeśli praca aktualizuje jakiś aspekt stanu globalnego (na przykład informacje przechowywane w bazie danych), można powtórzyć pojedynczą aktualizację. Podobny problem może wystąpić, jeśli filtr zakończy się niepowodzeniem po opublikowaniu wyników do następnego filtru, ale zanim wskaże, że zakończył pracę pomyślnie. W takich przypadkach inne wystąpienie filtru może powtórzyć tę pracę, powodując dwukrotne opublikowanie tych samych wyników. Ten scenariusz może spowodować dwukrotne przetworzenie tych samych danych przez kolejne filtry w potoku. W związku z tym filtry w potoku powinny być zaprojektowane tak, aby był idempotentny. Aby uzyskać więcej informacji, zobacz Idempotency Patterns (Wzorce idempotentności) na blogu Jonathana Olivera.
Powtórzone komunikaty. Jeśli filtr w potoku zakończy się niepowodzeniem po opublikowaniu komunikatu do następnego etapu potoku, może zostać uruchomione inne wystąpienie filtru i opublikuje kopię tego samego komunikatu do potoku. Ten scenariusz może spowodować przekazanie dwóch wystąpień tego samego komunikatu do następnego filtru. Aby uniknąć tego problemu, potok powinien wykrywać i usuwać zduplikowane komunikaty.
Uwaga
W przypadku implementowania potoku przy użyciu kolejek komunikatów (takich jak kolejki usługi Azure Service Bus) infrastruktura kolejkowania komunikatów może zapewnić automatyczne wykrywanie i usuwanie zduplikowanych komunikatów.
Kontekst i stan. Zasadniczo każdy filtr w potoku działa w izolacji i nie powinny być w nim przyjmowane żadne założenia co do sposobu jego wywołania. W związku z tym każdy filtr powinien być dostarczany z wystarczającą ilością kontekstu, aby wykonać swoją pracę. Ten kontekst może zawierać znaczną ilość informacji o stanie. Jeśli filtry używają stanu zewnętrznego, takiego jak dane w bazie danych lub magazynie zewnętrznym, należy wziąć pod uwagę wpływ na wydajność. Każdy filtr musi ładować, obsługiwać i utrwalać ten stan, co dodaje rozwiązania, które ładują stan zewnętrzny pojedynczo.
Tolerancja komunikatów. Filtry muszą być odporne na dane w komunikacie przychodzącym, względem których nie działają. Działają one na danych odpowiednich dla nich i ignorują inne dane i przekazują je bez zmian w komunikacie wyjściowym.
Obsługa błędów — każdy filtr musi określić, co zrobić w przypadku błędu powodującego niezgodność. Filtr musi określić, czy potok nie powiedzie się lub propaguje wyjątek.
Kiedy używać tego wzorca
Użyj tego wzorca, gdy:
Przetwarzanie wymagane przez aplikację można łatwo podzielić na zestaw niezależnych kroków.
Kroki przetwarzania wykonywane przez aplikację mają różne wymagania w zakresie skalowalności.
Uwaga
Można grupować filtry, które powinny być skalowane razem w tym samym procesie. Aby uzyskać więcej informacji, zobacz Compute Resource Consolidation Pattern (Wzorzec konsolidacji zasobów obliczeniowych).
Wymagana jest elastyczność umożliwiająca zmienianie kolejności kroków przetwarzania, które wykonuje aplikacja, lub umożliwienie możliwości dodawania i usuwania kroków.
System może zyskać na rozproszeniu przetwarzania dla kroków między różne serwery.
Potrzebujesz niezawodnego rozwiązania, które minimalizuje skutki awarii w kroku podczas przetwarzania danych.
Ten wzorzec może nie być przydatny w następujących sytuacjach:
Aplikacja jest zgodna ze wzorcem żądania-odpowiedzi.
Przetwarzanie zadania musi zostać ukończone w ramach początkowego żądania, takiego jak scenariusz żądania/odpowiedzi.
Kroki przetwarzania wykonywane przez aplikację nie są niezależne lub muszą być wykonywane razem w ramach jednej transakcji.
Ilość informacji o kontekście lub stanie, których wymaga krok, sprawia, że takie podejście jest nieefektywne. Może być możliwe utrwalanie informacji o stanie w bazie danych, ale nie należy używać tej strategii, jeśli dodatkowe obciążenie bazy danych powoduje nadmierne rywalizacje.
Projekt obciążenia
Architekt powinien ocenić, w jaki sposób wzorzec potoków i filtrów może być używany w projekcie obciążenia, aby sprostać celom i zasadom opisanym w filarach platformy Azure Well-Architected Framework. Na przykład:
| Filar | Jak ten wzorzec obsługuje cele filaru |
|---|---|
| Decyzje projektowe dotyczące niezawodności pomagają obciążeniu stać się odporne na awarię i zapewnić, że zostanie przywrócony do w pełni funkcjonalnego stanu po wystąpieniu awarii. | Pojedyncza odpowiedzialność każdego etapu umożliwia skoncentrowanie uwagi i pozwala uniknąć rozproszenia procesów przetwarzania danych. - RE:01 Prostota - RE:07 Zadania w tle |
Podobnie jak w przypadku każdej decyzji projektowej, należy rozważyć wszelkie kompromisy w stosunku do celów innych filarów, które mogą zostać wprowadzone przy użyciu tego wzorca.
Przykład
Możesz skorzystać z sekwencji kolejek komunikatów, aby udostępnić infrastrukturę wymaganą do zaimplementowania potoku. Początkowa kolejka komunikatów odbiera nieprzetworzone komunikaty, które stają się początkiem implementacji wzorca potoków i filtrów. Składnik zaimplementowany jako zadanie filtrowania nasłuchuje komunikatu w tej kolejce, wykonuje jego pracę, a następnie publikuje nowy lub przekształcony komunikat do następnej kolejki w sekwencji. Inne zadanie filtrowania może nasłuchiwać komunikatów w tej kolejce, przetwarzać je, publikować wyniki w innej kolejce itd., aż do ostatniego kroku kończącego proces potoków i filtrów. Na tym diagramie przedstawiono potok korzystający z kolejek komunikatów:

Potok przetwarzania obrazów można zaimplementować przy użyciu tego wzorca. Jeśli obciążenie pobiera obraz, obraz może przechodzić przez serię w dużej mierze niezależnych i zmienianych filtrów w celu wykonania akcji, takich jak:
- con tryb namiotu ration
- zmienianie rozmiaru
- Znak wodny
- Reorientacji
- Usuwanie metadanych exif
- Publikacja usługi Content Delivery Network (CDN)
W tym przykładzie filtry można zaimplementować jako pojedynczo wdrożoną usługę Azure Functions, a nawet pojedynczą aplikację funkcji platformy Azure zawierającą każdy filtr jako izolowane wdrożenie. Użycie wyzwalaczy funkcji platformy Azure, powiązań wejściowych i powiązań wyjściowych może uprościć kod filtru i pracować automatycznie z potokiem opartym na kolejce przy użyciu sprawdzania oświadczenia do obrazu w celu przetworzenia.

Oto przykład tego, co jeden filtr zaimplementowany jako funkcja platformy Azure został wyzwolony z potoku usługi Queue Storage z oświadczeniem Check do obrazu i zapis nowego sprawdzenia oświadczenia do innego potoku usługi Queue Storage może wyglądać następująco. Zastąpiliśmy implementację pseudokodem w komentarzach w celu zwięzłości. Więcej takich kodów można znaleźć w pokazie wzorca potoków i filtrów dostępnych w usłudze GitHub.
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
Uwaga
Struktura Spring Integration Framework zawiera implementację wzorca potoków i filtrów.
Następne kroki
Podczas implementowania tego wzorca mogą być przydatne następujące zasoby:
- Demonstracja wzorca potoków i filtrów przy użyciu scenariusza przetwarzania obrazów jest dostępna w usłudze GitHub.
- Wzorce idempotentności na blogu Jonathana Olivera.
Powiązane zasoby
Podczas implementowania tego wzorca mogą być również istotne następujące wzorce:
- Wzorzec sprawdzania oświadczeń. Potok zaimplementowany przy użyciu kolejki może nie zawierać rzeczywistego elementu wysyłanego przez filtry, ale zamiast tego wskaźnik do danych, które należy przetworzyć. W tym przykładzie użyto ewidencjonowania oświadczeń w usłudze Azure Queue Storage dla obrazów przechowywanych w usłudze Azure Blob Storage.
- Wzorzec konkurujących odbiorców. Potok może zawierać wiele wystąpień jednego lub większej liczby filtrów. Takie podejście jest przydatne w przypadku uruchamiania równoległych wystąpień wolnych filtrów. Umożliwia systemowi rozłożenie obciążenia i zwiększenie przepływności. Każde wystąpienie filtru konkuruje o dane wejściowe z innymi wystąpieniami, ale dwa wystąpienia filtru nie powinny być w stanie przetworzyć tych samych danych. W tym artykule wyjaśniono podejście.
- Wzorzec konsolidacji zasobów obliczeniowych. Może być możliwe grupowanie filtrów, które powinny być skalowane razem w jeden proces. Ten artykuł zawiera więcej informacji na temat korzyści i kompromisów tej strategii.
- Wzorzec transakcji wyrównującej. Filtr można zaimplementować jako operację, która może zostać odwrócona lub ma operację wyrównywczą, która przywraca stan do poprzedniej wersji, jeśli wystąpi awaria. W tym artykule wyjaśniono, jak można zaimplementować ten wzorzec, aby zachować lub osiągnąć spójność ostateczną.
- Potoki i filtry — wzorce integracji dla przedsiębiorstw.