W tym artykule opisano sposób, w jaki zespół programistyczny używał metryk do znajdowania wąskich gardeł i poprawiania wydajności systemu rozproszonego. Artykuł jest oparty na rzeczywistym testowaniu obciążenia, które wykonaliśmy dla przykładowej aplikacji. Aplikacja pochodzi z planu bazowego Azure Kubernetes Service (AKS) dla mikrousług.
Ten artykuł jest częścią serii. Przeczytaj pierwszą część tutaj.
Scenariusz: aplikacja kliencka inicjuje transakcję biznesową, która obejmuje wiele kroków.
Ten scenariusz obejmuje aplikację dostarczania dronów działającą w usłudze AKS. Klienci używają aplikacji internetowej do planowania dostaw przez drona. Każda transakcja wymaga wielu kroków wykonywanych przez oddzielne mikrousługi na zapleczu:
- Usługa dostarczania zarządza dostawami.
- Usługa Drone Scheduler planuje drony do odbioru.
- Usługa Pakiet zarządza pakietami.
Istnieją dwie inne usługi: usługa pozyskiwania, która akceptuje żądania klientów i umieszcza je w kolejce do przetwarzania, oraz usługę Przepływu pracy, która koordynuje kroki w przepływie pracy.
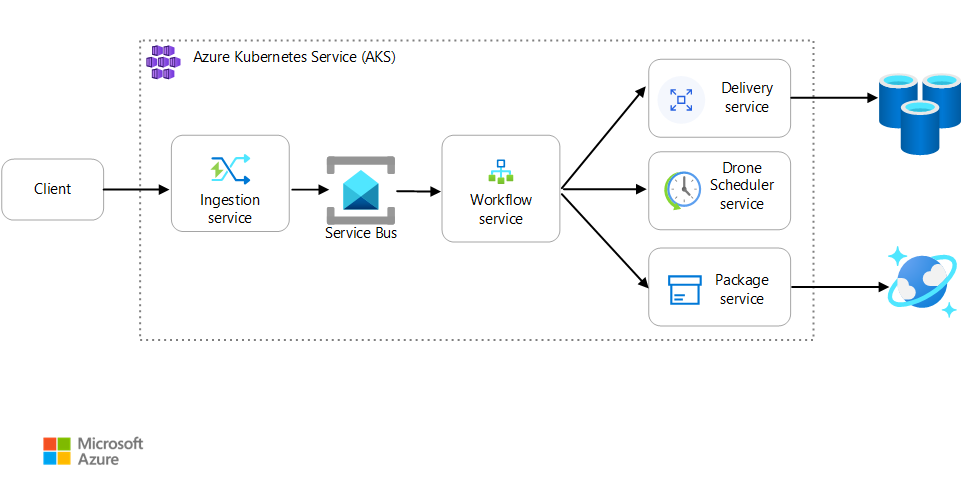
Aby uzyskać więcej informacji na temat tego scenariusza, zobacz Projektowanie architektury mikrousług.
Test 1. Punkt odniesienia
W pierwszym teście obciążeniowym zespół utworzył klaster AKS z sześciowęźle i wdrożył trzy repliki każdej mikrousługi. Test obciążeniowy był testem obciążeniowym, który rozpoczął się od dwóch symulowanych użytkowników i zwiększał do 40 symulowanych użytkowników.
| Ustawienie | Wartość |
|---|---|
| Węzły klastra | 6 |
| Strąków | 3 na usługę |
Poniższy wykres przedstawia wyniki testu obciążeniowego, jak pokazano w programie Visual Studio. Purpurowa linia generuje obciążenie użytkownika, a pomarańczowa linia kreśle łączną liczbę żądań.
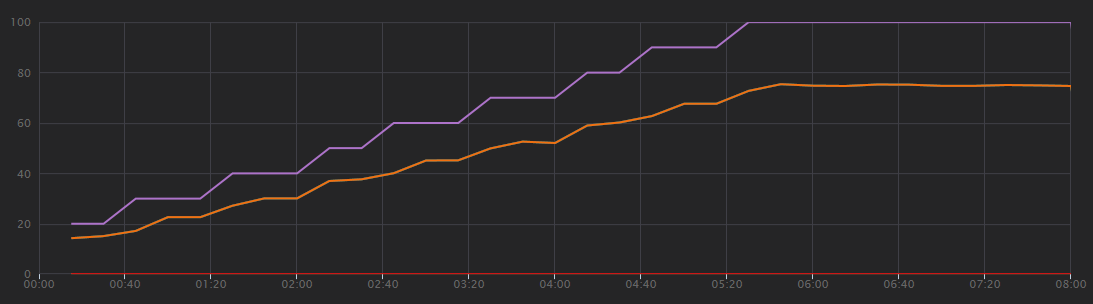
Pierwszą rzeczą do zrealizowania tego scenariusza jest to, że żądania klientów na sekundę nie są przydatną metryką wydajności. Dzieje się tak dlatego, że aplikacja przetwarza żądania asynchronicznie, więc klient od razu otrzymuje odpowiedź. Kod odpowiedzi jest zawsze HTTP 202 (zaakceptowany), co oznacza, że żądanie zostało zaakceptowane, ale przetwarzanie nie zostało ukończone.
Chcemy wiedzieć, czy zaplecze jest zgodne z szybkością żądań. Kolejka usługi Service Bus może absorbować skoki, ale jeśli zaplecze nie może obsłużyć trwałego obciążenia, przetwarzanie spadnie dalej i dalej.
Oto bardziej informacyjny wykres. Tworzy ona wykres liczby przychodzących i wychodzących komunikatów w kolejce usługi Service Bus. Komunikaty przychodzące są wyświetlane w jasnoniebieskim, a komunikaty wychodzące są wyświetlane w kolorze ciemnoniebieskim:
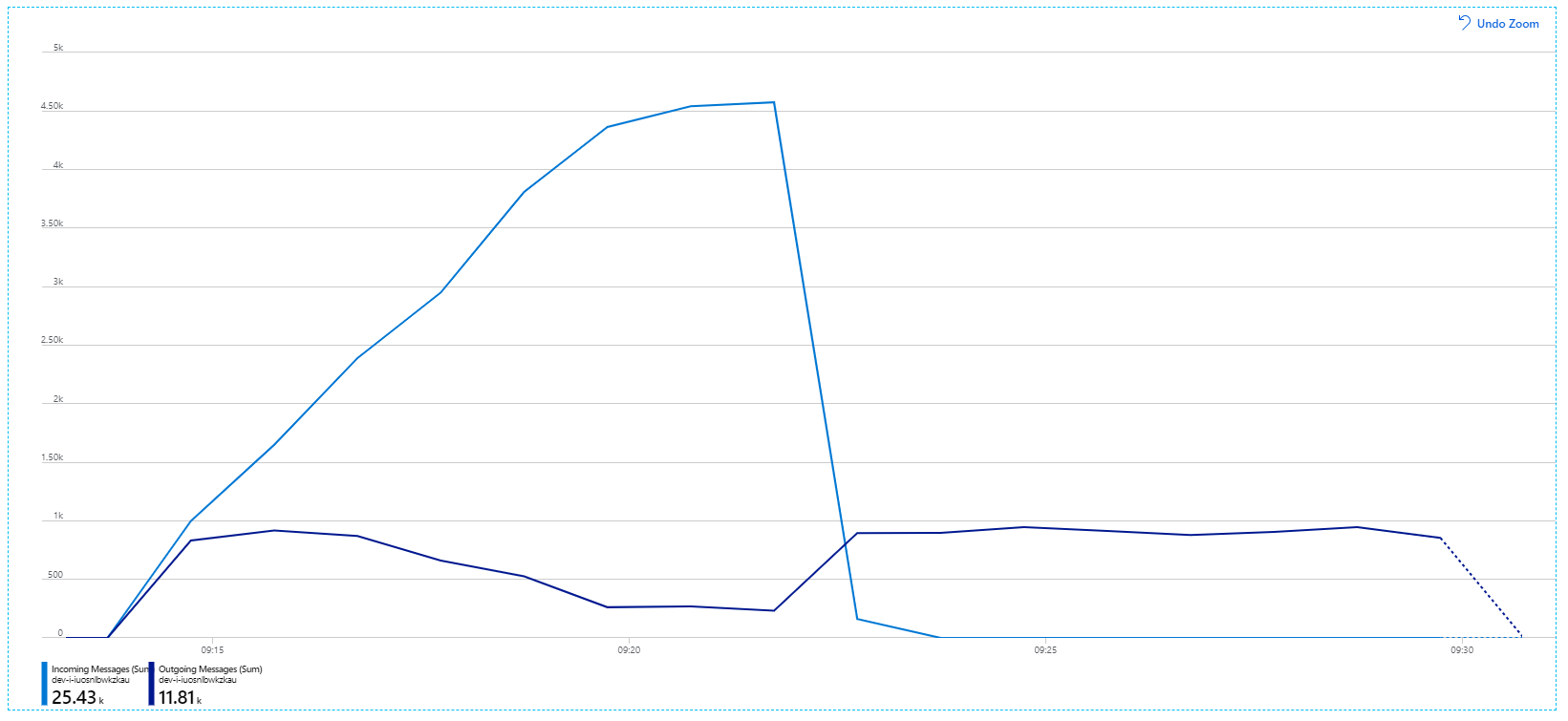
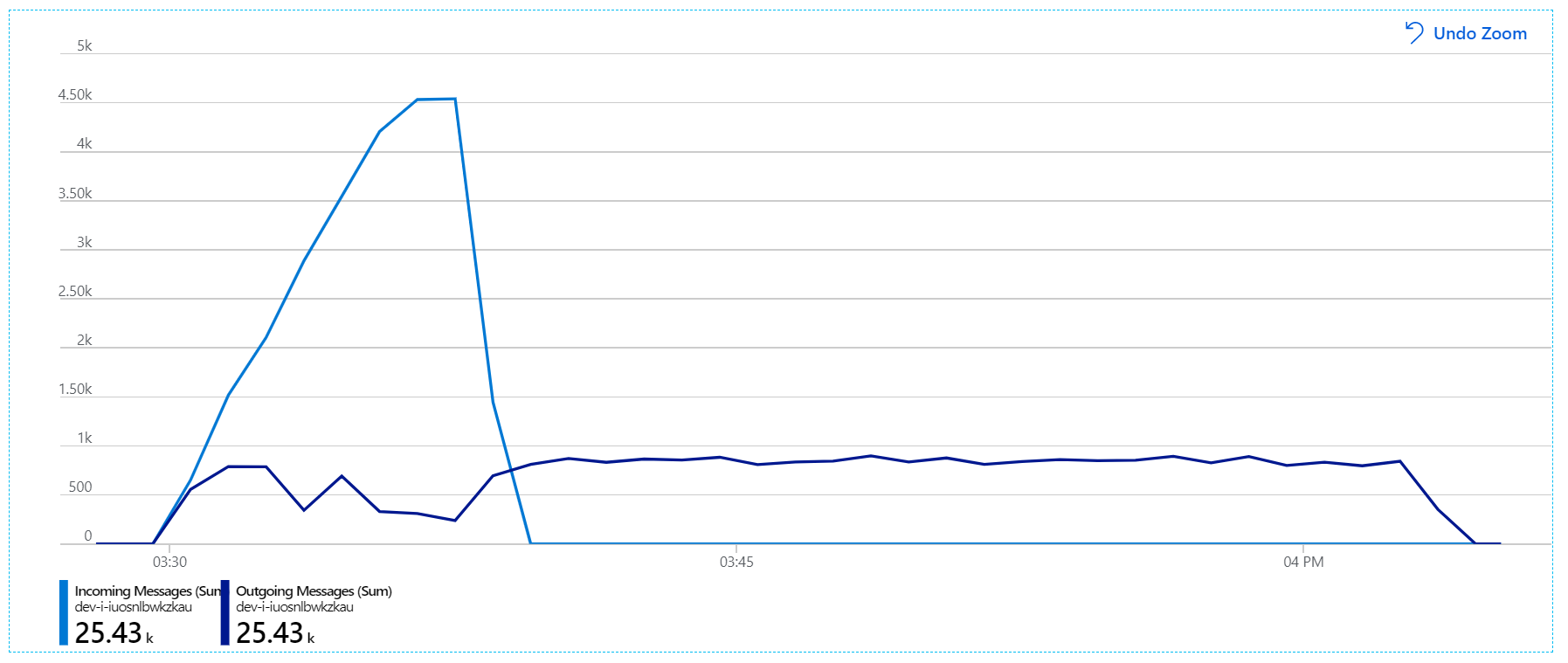
Ten wykres pokazuje, że szybkość przychodzących komunikatów wzrasta, osiągając szczyt, a następnie spadając z powrotem do zera na końcu testu obciążeniowego. Ale liczba wychodzących komunikatów szczytuje się na początku testu, a następnie rzeczywiście spada. Oznacza to, że usługa Przepływu pracy, która obsługuje żądania, nie utrzymuje się. Nawet po zakończeniu testu obciążeniowego (około 9:22 na grafie) komunikaty są nadal przetwarzane, ponieważ usługa Przepływu pracy nadal opróżnia kolejkę.
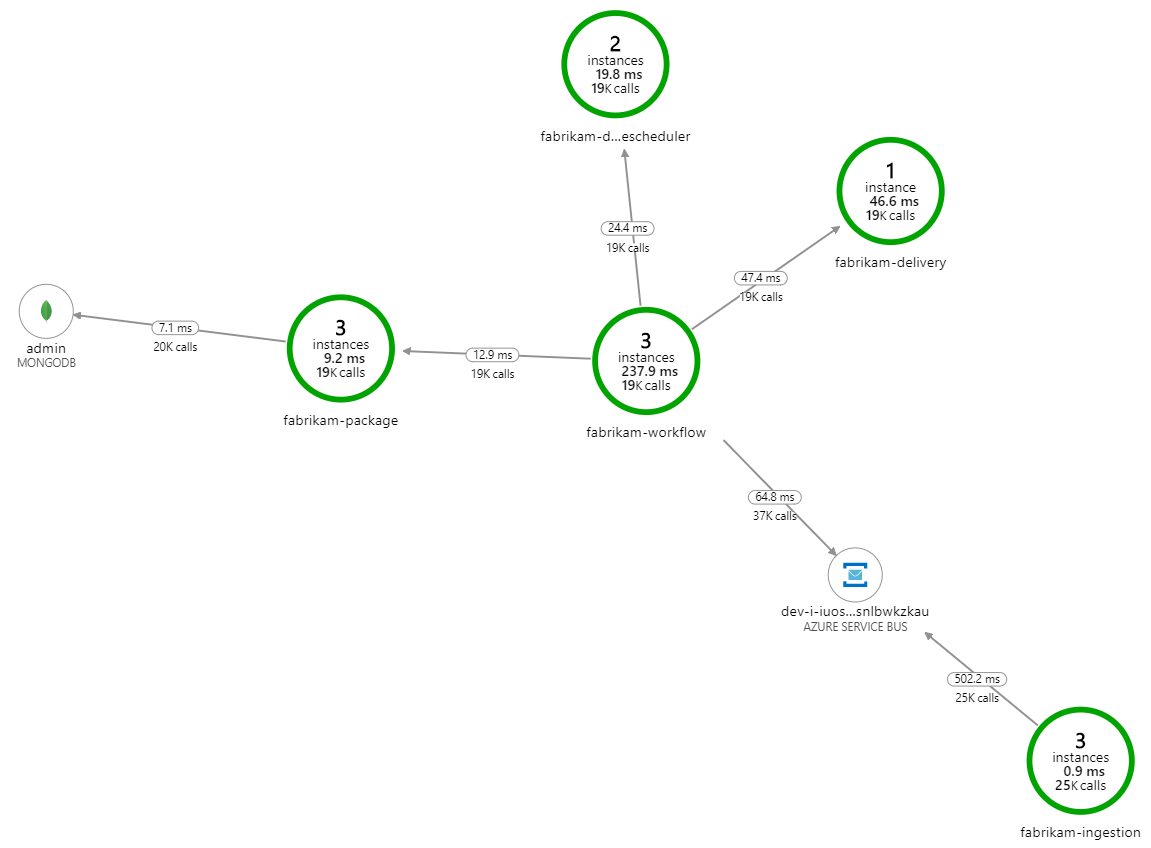
Co spowalnia przetwarzanie? Pierwszą rzeczą do wyszukania są błędy lub wyjątki, które mogą wskazywać na systematyczny problem. Mapa aplikacji w usłudze Azure Monitor przedstawia wykres wywołań między składnikami i jest szybkim sposobem wykrywania problemów, a następnie kliknij, aby uzyskać więcej szczegółów.
Na pewno mapa aplikacji pokazuje, że usługa Przepływu pracy otrzymuje błędy z usługi dostarczania:
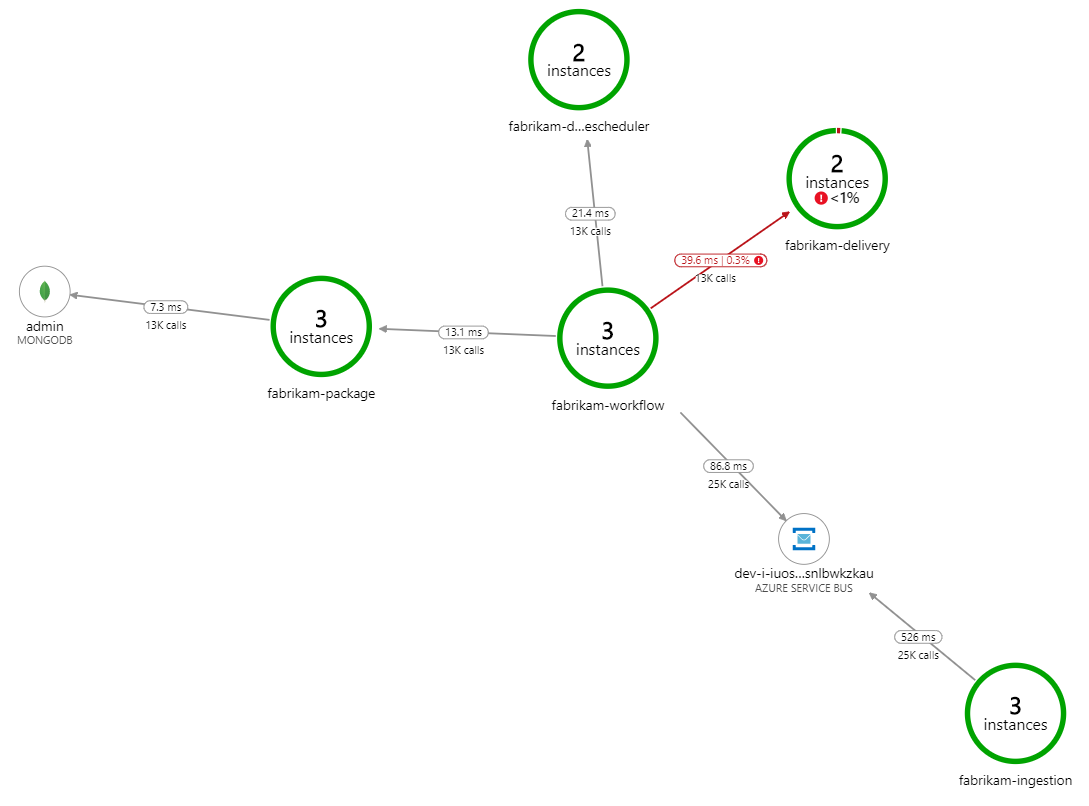
Aby wyświetlić więcej szczegółów, możesz wybrać węzeł na wykresie i kliknąć w widok transakcji kompleksowej. W takim przypadku widać, że usługa dostarczania zwraca błędy HTTP 500. Komunikaty o błędach wskazują, że wyjątek jest zgłaszany z powodu limitów pamięci w Azure Cache for Redis.
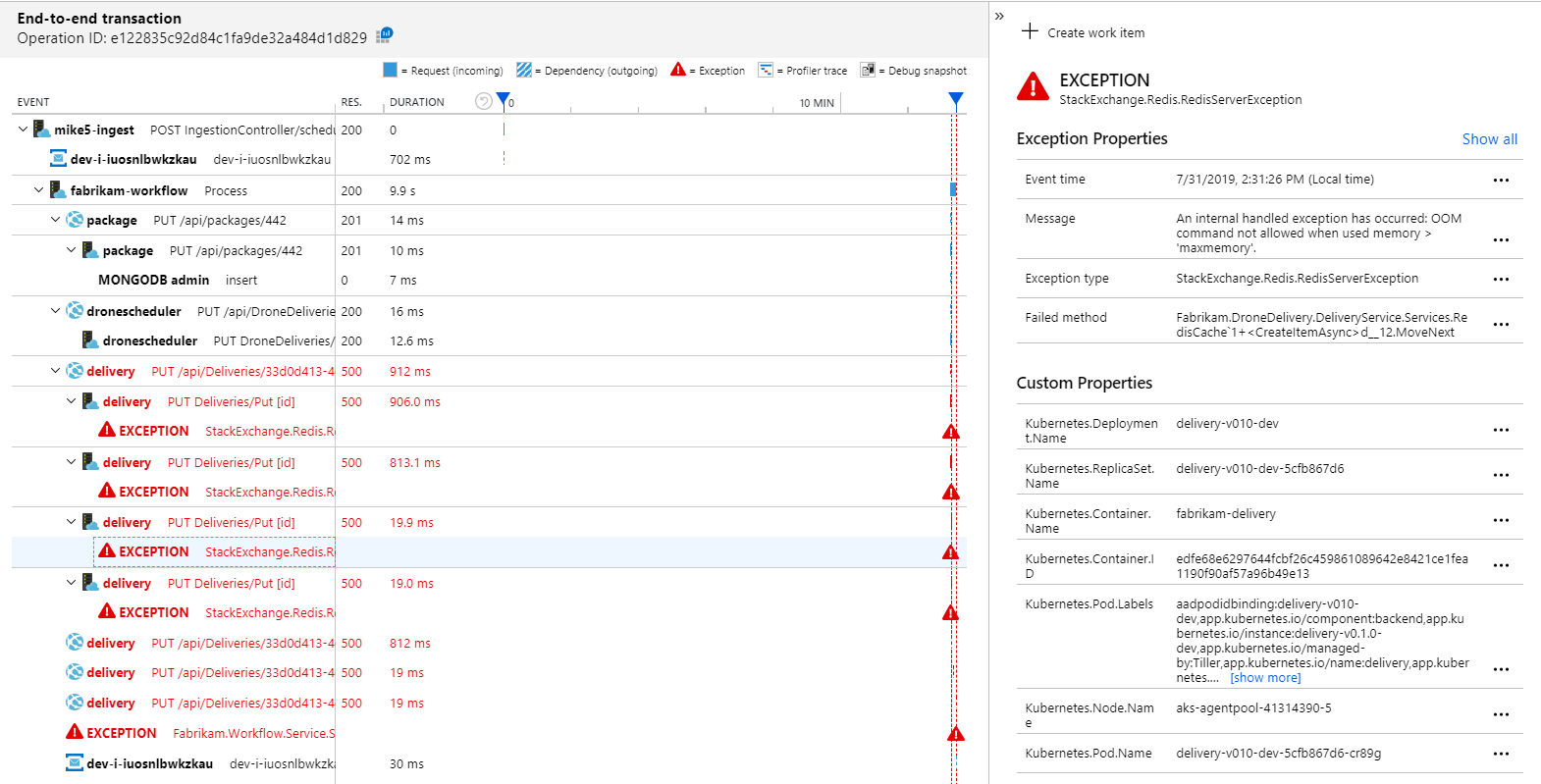
Możesz zauważyć, że te wywołania do usługi Redis nie są wyświetlane na mapie aplikacji. Dzieje się tak, ponieważ biblioteka .NET dla usługi Application Insights nie obsługuje wbudowanej obsługi śledzenia usługi Redis jako zależności. (Aby zapoznać się z listą obsługiwanych elementów, zobacz Automatyczne zbieranie zależności). Jako powrót możesz użyć interfejsu API TrackDependency do śledzenia dowolnej zależności. Testowanie obciążenia często ujawnia tego rodzaju luki w telemetrii, które można skorygować.
Test 2. Zwiększony rozmiar pamięci podręcznej
W drugim teście obciążeniowym zespół deweloperów zwiększył rozmiar pamięci podręcznej w Azure Cache for Redis. (Zobacz Jak skalować Azure Cache for Redis). Ta zmiana rozwiązała wyjątki poza pamięcią, a teraz mapa aplikacji pokazuje błędy zerowe:
Jednak nadal występuje dramatyczne opóźnienie w przetwarzaniu komunikatów. Podczas szczytu testu obciążeniowego szybkość komunikatów przychodzących przekracza 5× szybkość wychodząca:
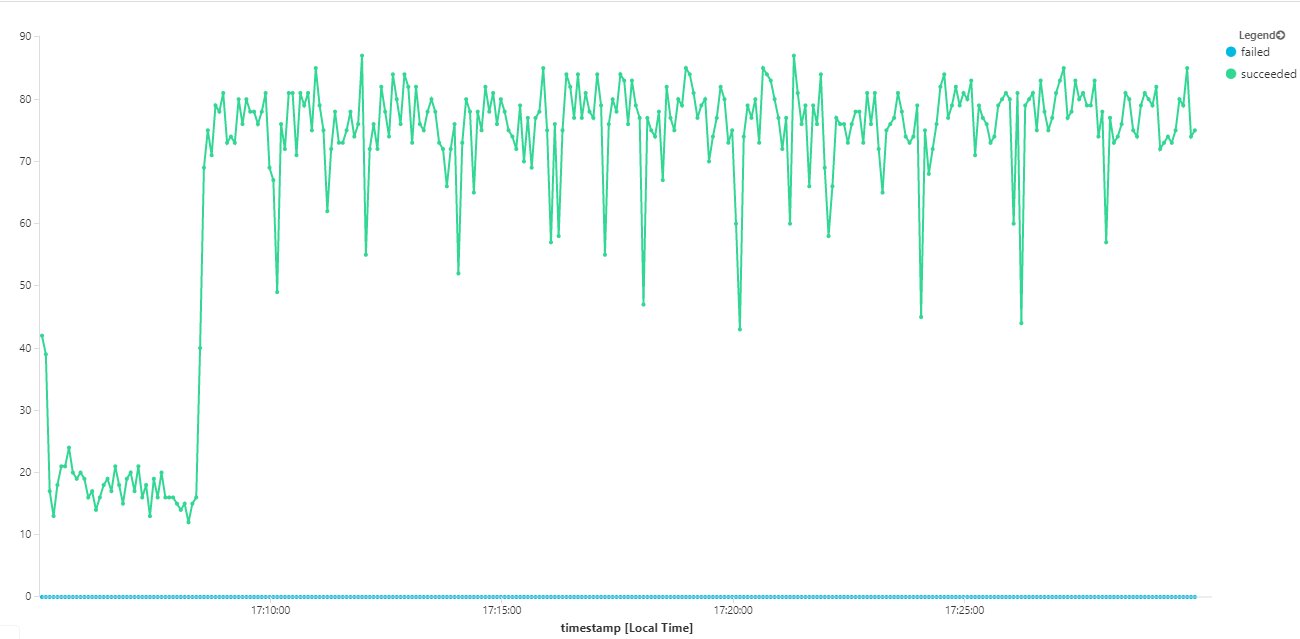
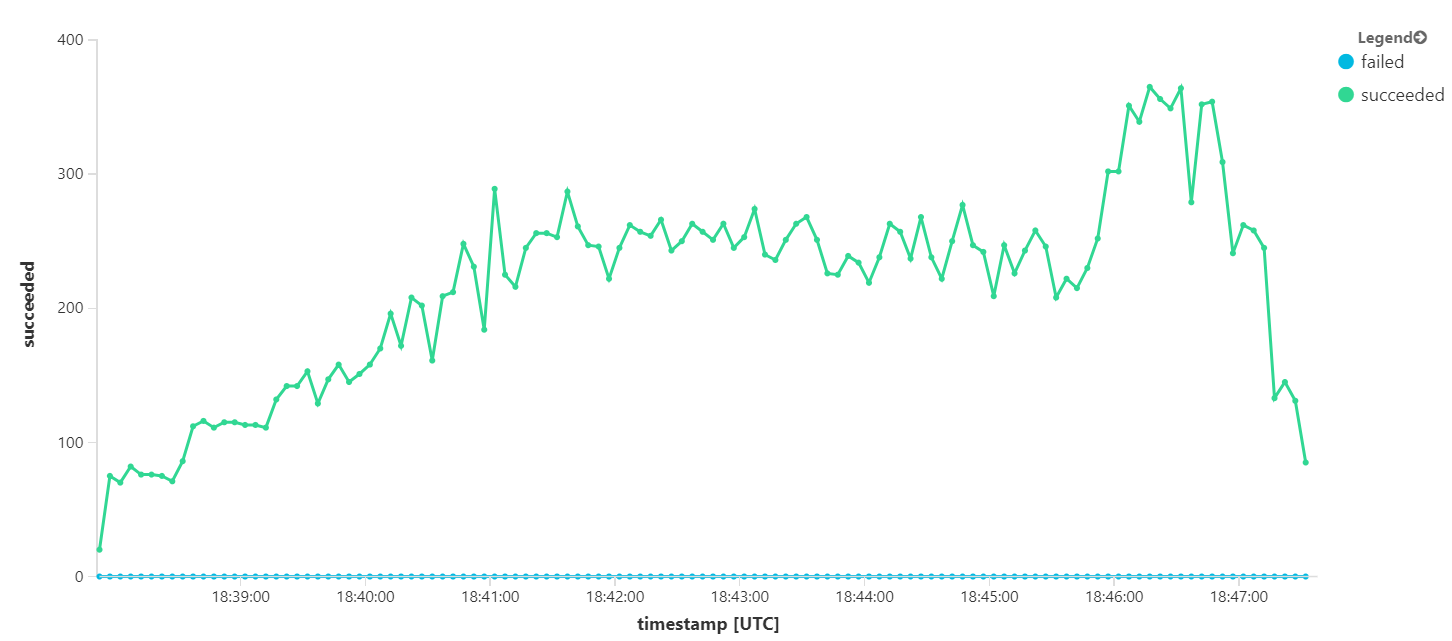
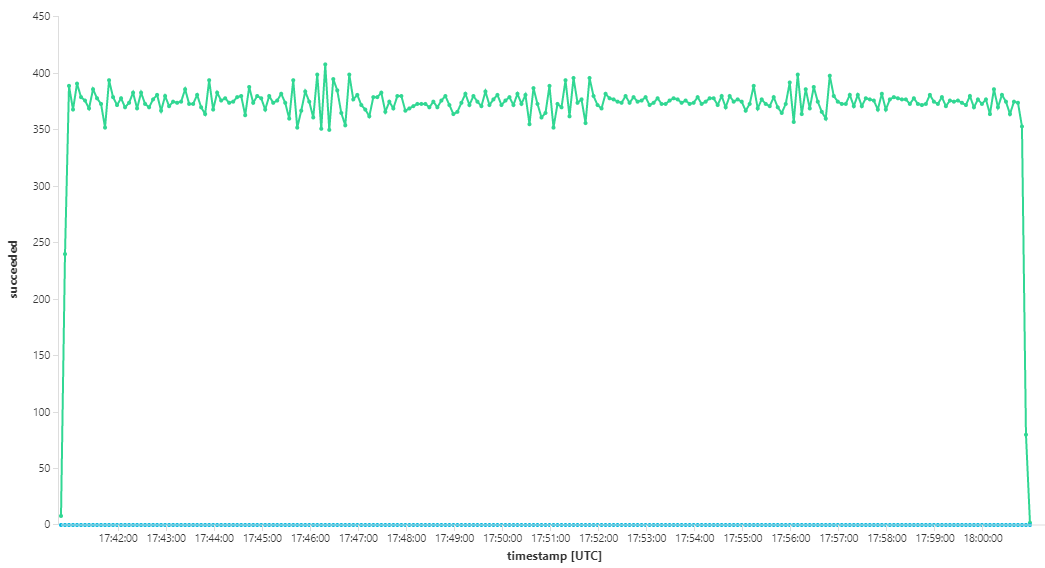
Poniższy wykres mierzy przepływność w zakresie uzupełniania komunikatów — czyli szybkość, z jaką usługa Workflow oznacza komunikaty usługi Service Bus zgodnie z ukończeniem. Każdy punkt na wykresie reprezentuje 5 sekund danych z maksymalną przepływnością ok. 16/s.
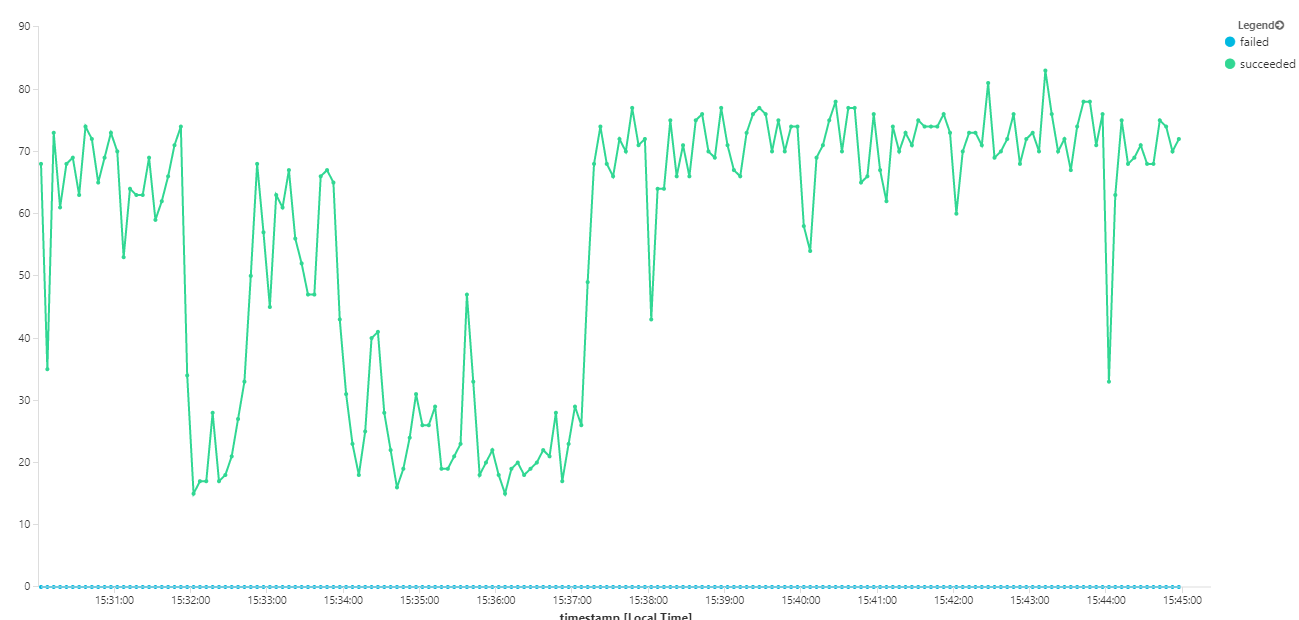
Ten graf został wygenerowany przez uruchomienie zapytania w obszarze roboczym usługi Log Analytics przy użyciu języka zapytań Kusto:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
Test 3. Skalowanie w poziomie usług zaplecza
Wygląda na to, że zaplecze jest wąskim gardłem. Następnym krokiem jest skalowanie usług biznesowych (Package, Delivery i Drone Scheduler) i sprawdzenie, czy przepływność się poprawia. W następnym teście obciążeniowym zespół przeskalował te usługi z trzech replik do sześciu replik.
| Ustawienie | Wartość |
|---|---|
| Węzły klastra | 6 |
| Usługa pozyskiwania | 3 repliki |
| Usługa przepływu pracy | 3 repliki |
| Pakiet, dostarczanie, usługi Drone Scheduler | Każda z 6 replik |
Niestety ten test obciążeniowy pokazuje tylko skromną poprawę. Komunikaty wychodzące nadal nie są zgodne z komunikatami przychodzącymi:
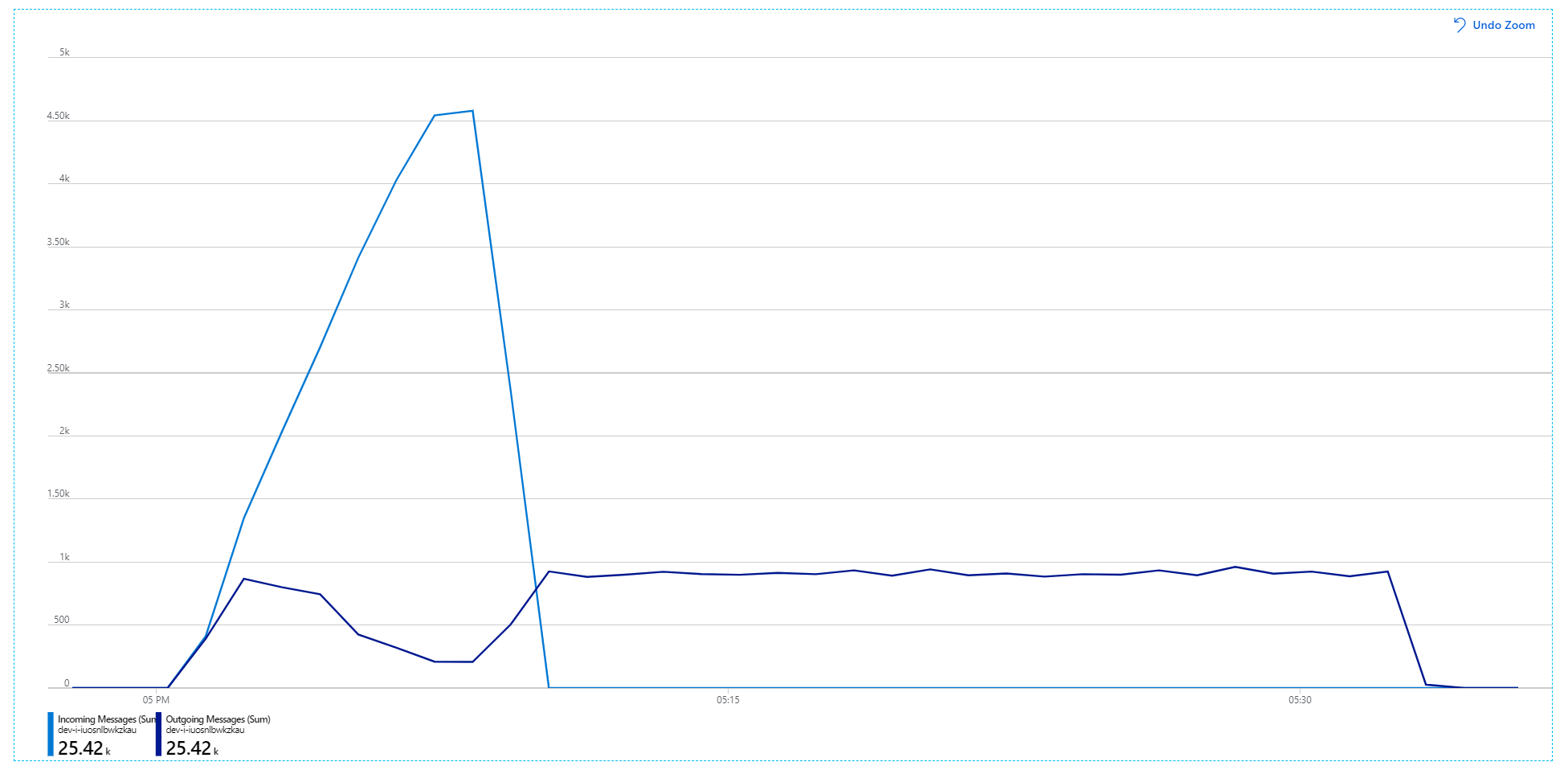
Przepływność jest bardziej spójna, ale wartość maksymalna osiągana jest mniej więcej taka sama jak poprzedni test:
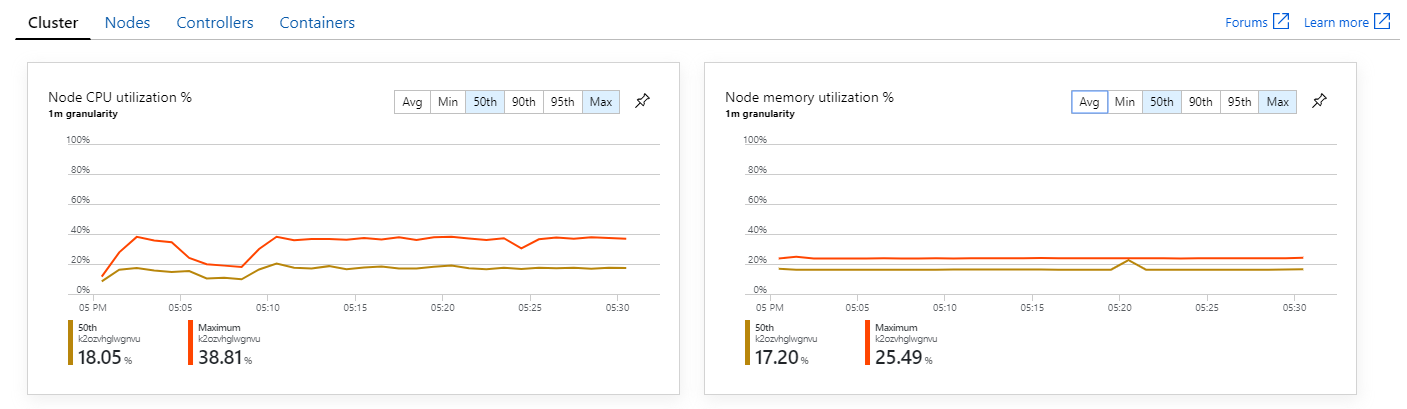
Ponadto, patrząc na szczegółowe informacje o kontenerze usługi Azure Monitor, wydaje się, że problem nie jest spowodowany wyczerpaniem zasobów w klastrze. Po pierwsze metryki na poziomie węzła pokazują, że użycie procesora CPU pozostaje poniżej 40% nawet w 95. percentylu, a wykorzystanie pamięci wynosi około 20%.
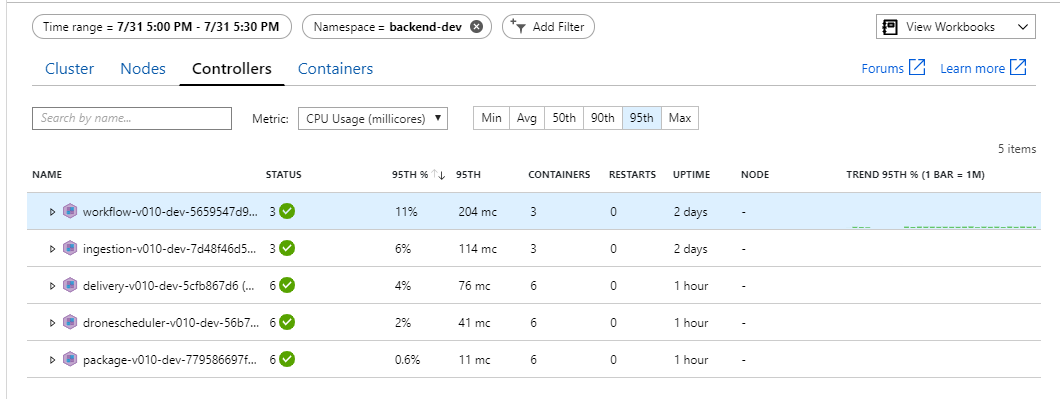
W środowisku Kubernetes można ograniczyć poszczególne zasobniki nawet wtedy, gdy węzły nie są. Ale widok na poziomie zasobnika pokazuje, że wszystkie zasobniki są w dobrej kondycji.
Z tego testu wydaje się, że dodanie kolejnych zasobników do zaplecza nie pomoże. Następnym krokiem jest przyjrzenie się bliżej usłudze Przepływu pracy, aby zrozumieć, co się dzieje podczas przetwarzania komunikatów. Usługa Application Insights pokazuje, że średni czas trwania operacji usługi Process Przepływ pracy wynosi 246 ms.
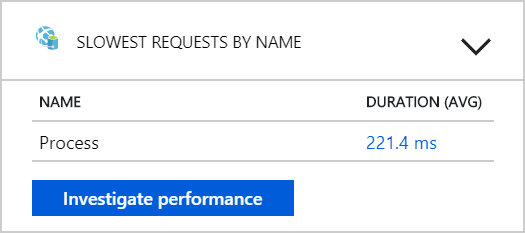
Możemy również uruchomić zapytanie, aby pobrać metryki dotyczące poszczególnych operacji w ramach każdej transakcji:
| Docelowego | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| Dostawy | 37 | 57 |
| package | 12 | 17 |
| dronescheduler | 21 | 41 |
Pierwszy wiersz w tej tabeli reprezentuje kolejkę usługi Service Bus. Pozostałe wiersze to wywołania usług zaplecza. Poniżej przedstawiono zapytanie usługi Log Analytics dla tej tabeli:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target
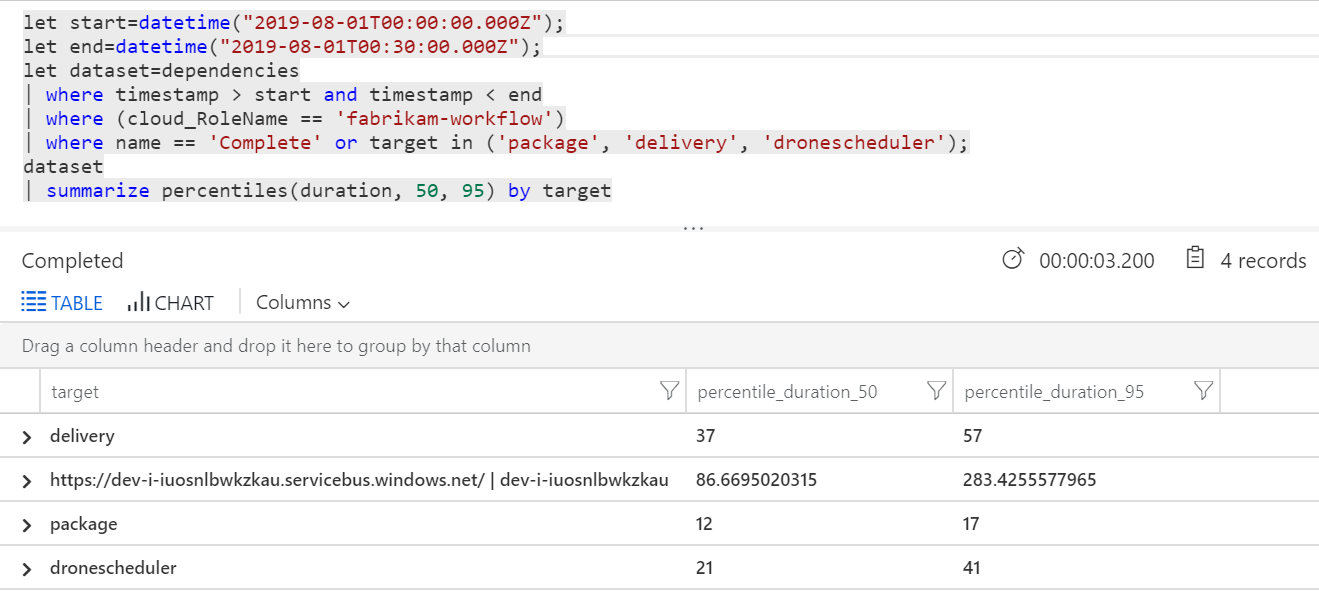
Opóźnienia te wyglądają rozsądnie. Ale oto kluczowy wgląd: Jeśli całkowity czas operacji wynosi ok. 250 ms, to stawia ściśle górną granicę sposobu przetwarzania szybkich komunikatów w serii. Kluczem do poprawy przepływności jest zatem większa równoległość.
Powinno to być możliwe w tym scenariuszu z dwóch powodów:
- Są to wywołania sieciowe, więc większość czasu jest poświęcana na oczekiwanie na ukończenie operacji we/wy
- Komunikaty są niezależne i nie muszą być przetwarzane w kolejności.
Test 4. Zwiększanie równoległości
Na potrzeby tego testu zespół skupił się na zwiększaniu równoległości. W tym celu dostosowali dwa ustawienia klienta usługi Service Bus używane przez usługę Workflow:
| Ustawienie | Opis | Domyślny | Nowa wartość |
|---|---|---|---|
MaxConcurrentCalls |
Maksymalna liczba komunikatów do przetwarzania współbieżnego. | 1 | 20 |
PrefetchCount |
Ile komunikatów klient pobierze z wyprzedzeniem do lokalnej pamięci podręcznej. | 0 | 3000 |
Aby uzyskać więcej informacji na temat tych ustawień, zobacz Best Practices for performance improvements using Service Bus Messaging (Najlepsze rozwiązania dotyczące poprawy wydajności przy użyciu komunikatów usługi Service Bus). Uruchomienie testu przy użyciu tych ustawień wywołało następujący graf:
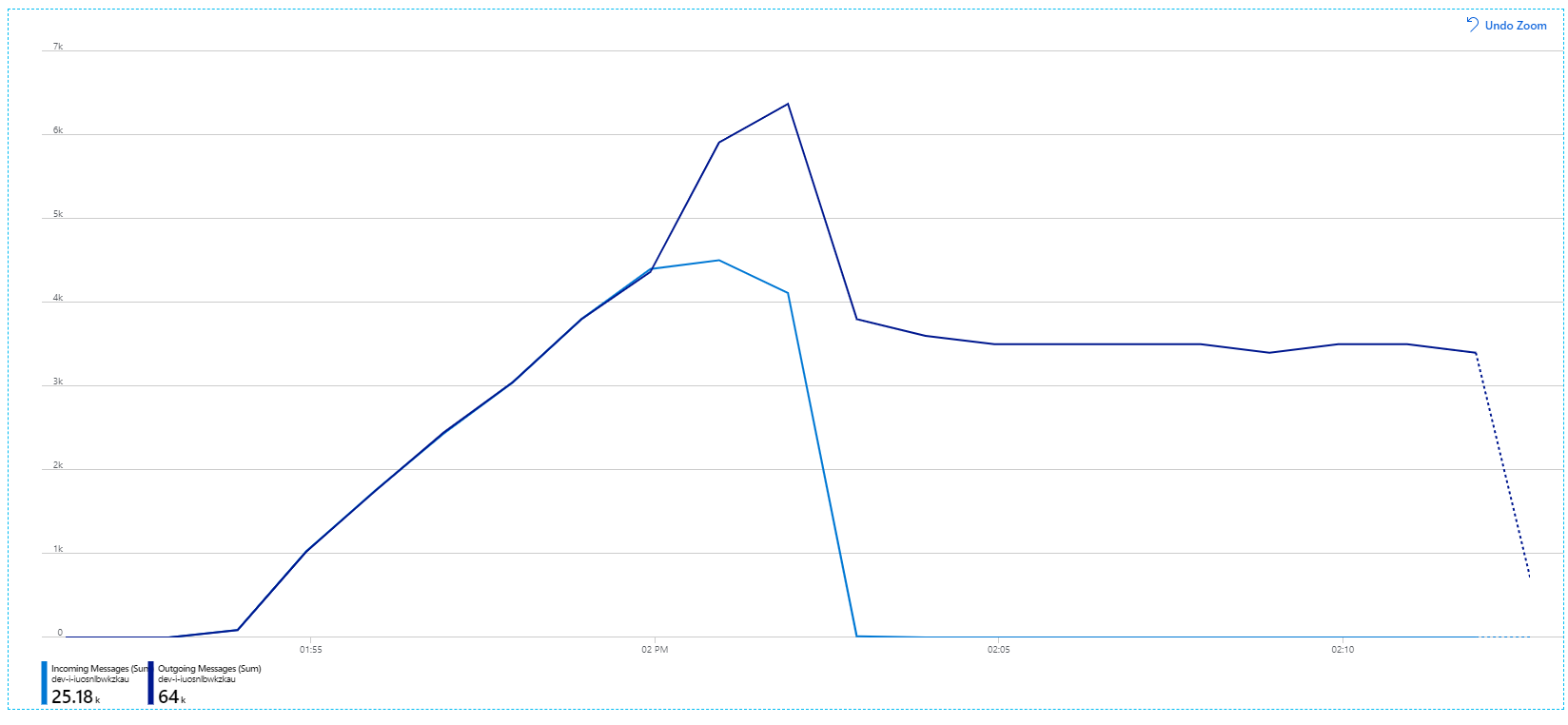
Przypomnij sobie, że komunikaty przychodzące są wyświetlane w kolorze jasnoniebieskim, a komunikaty wychodzące są wyświetlane w ciemnoniebieskim.
Na pierwszy rzut oka jest to bardzo dziwny wykres. Przez pewien czas szybkość komunikatów wychodzących dokładnie śledzi szybkość przychodzącą. Ale następnie, na około 2:03 znacznik, szybkość przychodzących komunikatów jest wyłączona, podczas gdy liczba wychodzących komunikatów nadal rośnie, faktycznie przekraczając całkowitą liczbę przychodzących komunikatów. To wydaje się niemożliwe.
Wskazówki dotyczące tej tajemnicy można znaleźć w widoku Zależności w usłudze Application Insights. Ten wykres zawiera podsumowanie wszystkich wywołań wykonanych przez usługę Workflow w usłudze Service Bus:
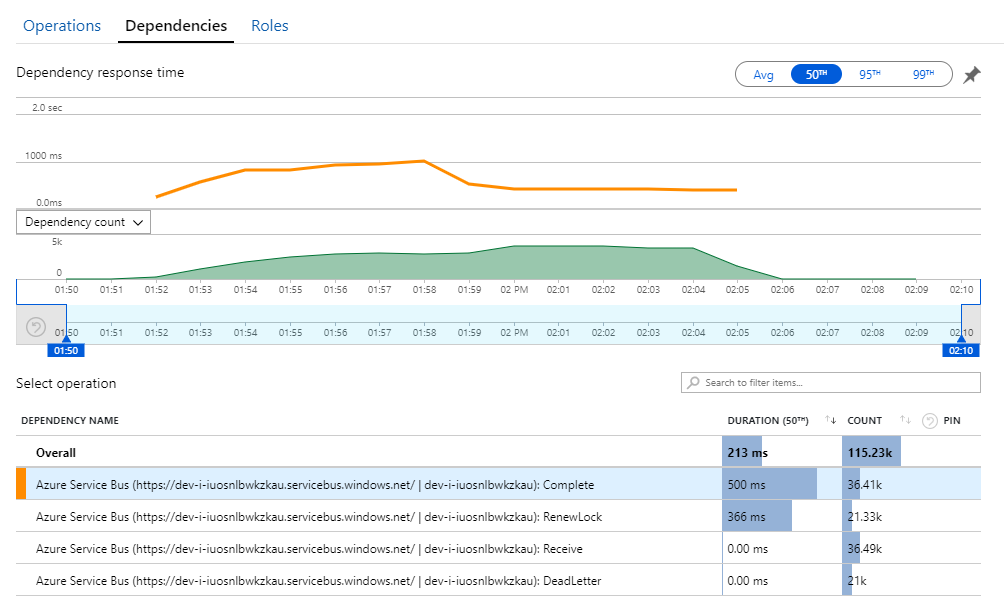
Zwróć uwagę, że wpis dla DeadLetter. To wywołania wskazuje, że komunikaty przechodzą do kolejki utraconych komunikatów usługi Service Bus.
Aby zrozumieć, co się dzieje, musisz zrozumieć semantykę Peek-Lock w usłudze Service Bus. Gdy klient używa funkcji Peek-Lock, usługa Service Bus niepodziealnie pobiera i blokuje komunikat. Gdy blokada jest utrzymywana, komunikat nie jest dostarczany do innych odbiorników. Jeśli blokada wygaśnie, komunikat stanie się dostępny dla innych odbiorców. Po maksymalnej liczbie prób dostarczenia (które można skonfigurować), usługa Service Bus umieści komunikaty w kolejce utraconych komunikatów, gdzie można je zbadać później.
Pamiętaj, że usługa Przepływu pracy pobiera wstępnie duże partie komunikatów — 3000 komunikatów jednocześnie). Oznacza to, że całkowity czas przetwarzania każdego komunikatu jest dłuższy, co powoduje przekroczenie limitu czasu komunikatów, powrót do kolejki i ostatecznie przejście do kolejki utraconych komunikatów.
To zachowanie można również zobaczyć w wyjątkach, w których rejestrowane są liczne MessageLostLockException wyjątki:
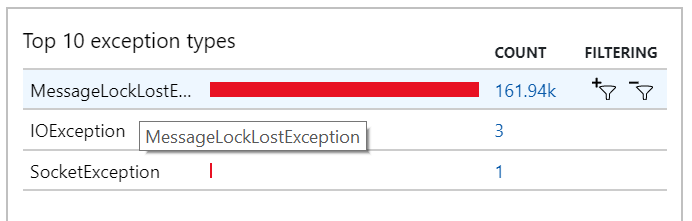
Test 5. Zwiększanie czasu trwania blokady
W przypadku tego testu obciążeniowego czas trwania blokady komunikatu został ustawiony na 5 minut, aby zapobiec przekroczeniom limitu czasu blokady. Wykres przychodzących i wychodzących komunikatów pokazuje teraz, że system nadąża za szybkością komunikatów przychodzących:
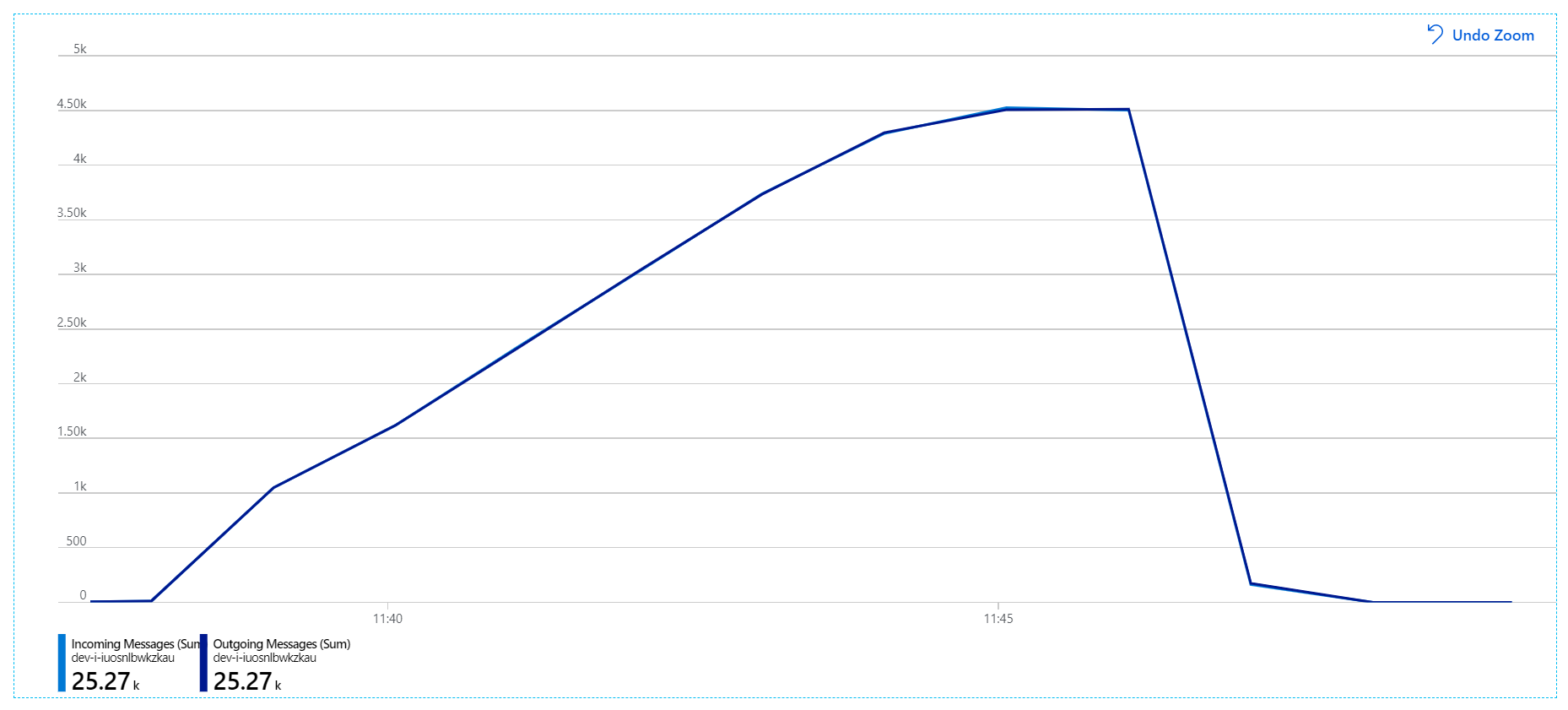
W ramach łącznego czasu trwania 8-minutowego testu obciążeniowego aplikacja wykonała 25 K operacji z maksymalną przepływnością wynoszącą 72 operacje na sekundę, co oznacza wzrost maksymalnej przepływności o 400%.
Jednak uruchomienie tego samego testu z dłuższym czasem trwania wykazało, że aplikacja nie może utrzymać tego współczynnika:
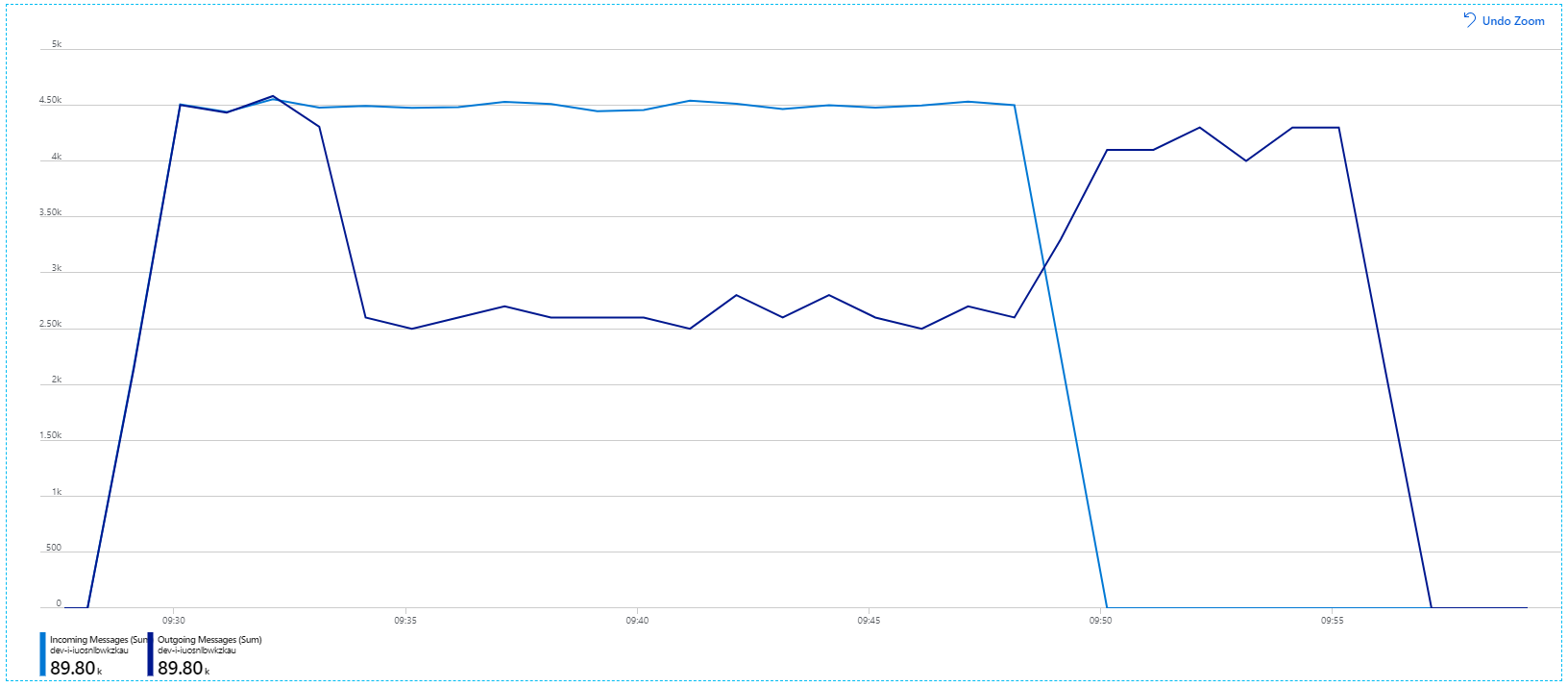
Metryki kontenera pokazują, że maksymalne wykorzystanie procesora CPU wynosiło blisko 100%. W tym momencie aplikacja wydaje się być powiązana z procesorem CPU. Skalowanie klastra może teraz poprawić wydajność, w przeciwieństwie do poprzedniej próby skalowania w poziomie.
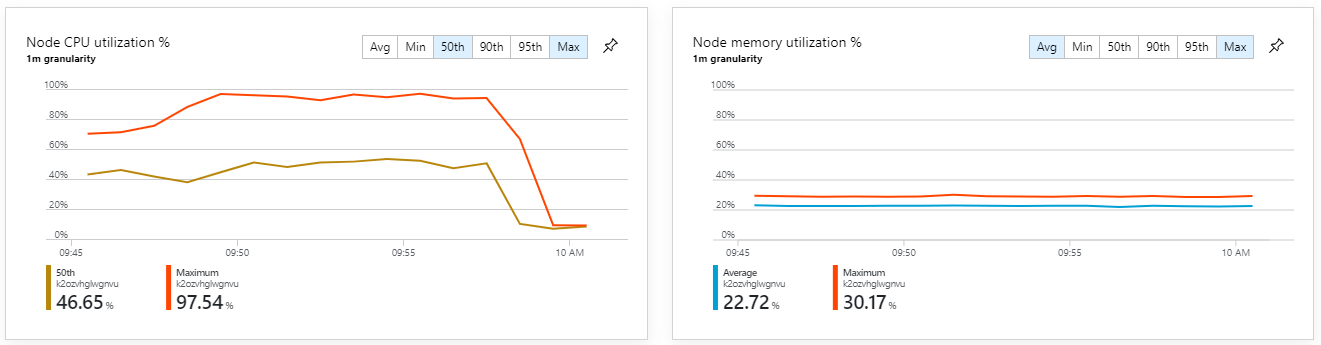
Test 6: skalowanie w poziomie usług zaplecza (ponownie)
W przypadku końcowego testu obciążeniowego w serii zespół skalował w poziomie klaster i zasobniki Kubernetes w następujący sposób:
| Ustawienie | Wartość |
|---|---|
| Węzły klastra | 12 |
| Usługa pozyskiwania | 3 repliki |
| Usługa przepływu pracy | 6 replik |
| Pakowanie, dostarczanie, usługi Drone Scheduler | Każda z 9 replik |
Ten test spowodował zwiększenie stałej przepływności bez znaczących opóźnień w przetwarzaniu komunikatów. Ponadto wykorzystanie procesora CPU węzłów pozostawało poniżej 80%.
Podsumowanie
W tym scenariuszu zidentyfikowano następujące wąskie gardła:
- Wyjątki braku pamięci w Azure Cache for Redis.
- Brak równoległości przetwarzania komunikatów.
- Niewystarczający czas trwania blokady komunikatu, co prowadzi do przekroczenia limitu czasu blokady i komunikatów umieszczanych w kolejce utraconych komunikatów.
- Wyczerpanie procesora CPU.
Aby zdiagnozować te problemy, zespół programistyczny oparł się na następujących metrykach:
- Szybkość przychodzących i wychodzących komunikatów usługi Service Bus.
- Mapa aplikacji w usłudze Application Insights.
- Błędy i wyjątki.
- Niestandardowe zapytania usługi Log Analytics.
- Użycie procesora CPU i pamięci w szczegółowych danych kontenera usługi Azure Monitor.
Następne kroki
Aby uzyskać więcej informacji na temat projektowania tego scenariusza, zobacz Projektowanie architektury mikrousług.