Konfigurowanie grupy trybu failover — interfejs wiersza polecenia
W tym artykule wyjaśniono, jak skonfigurować odzyskiwanie po awarii dla wystąpienia zarządzanego SQL włączonego przez usługę Azure Arc przy użyciu interfejsu wiersza polecenia. Przed kontynuowaniem przejrzyj informacje i wymagania wstępne w usłudze SQL Managed Instance włączone przez usługę Azure Arc — odzyskiwanie po awarii.
Wymagania wstępne
Przed skonfigurowaniem grup trybu failover między dwoma wystąpieniami usługi SQL Managed Instance włączonymi przez usługę Azure Arc należy spełnić następujące wymagania wstępne:
- Kontroler danych usługi Azure Arc i wystąpienie zarządzane SQL z obsługą usługi Arc aprowizowane w lokacji głównej jako jedno z
--license-typeBasePricelubLicenseIncluded. - Kontroler danych usługi Azure Arc i wystąpienie zarządzane SQL z obsługą usługi Arc aprowizowane w lokacji dodatkowej z identyczną konfiguracją jako podstawową w zakresie:
- Procesor CPU
- Memory (Pamięć)
- Storage
- Warstwa usług
- Sortowanie
- Inne ustawienia wystąpienia
- Wystąpienie w lokacji dodatkowej wymaga
--license-typeelementu jakoDisasterRecovery. To wystąpienie musi być nowe, bez żadnych obiektów użytkownika.
Uwaga
- Ważne jest, aby określić element
--license-typepodczas tworzenia wystąpienia zarządzanego. Umożliwi to inicjowanie wystąpienia odzyskiwania po awarii z wystąpienia podstawowego w podstawowym centrum danych. Aktualizowanie tej właściwości po wdrożeniu nie będzie miało takiego samego efektu.
Proces wdrażania
Aby skonfigurować grupę trybu failover platformy Azure między dwoma wystąpieniami, wykonaj następujące kroki:
- Tworzenie zasobu niestandardowego dla rozproszonej grupy dostępności w lokacji głównej
- Tworzenie zasobu niestandardowego dla rozproszonej grupy dostępności w lokacji dodatkowej
- Kopiowanie danych binarnych z certyfikatów dublowania
- Konfigurowanie rozproszonej grupy dostępności między lokacjami podstawowymi i dodatkowymi w
synctrybie lubasynctrybie
Na poniższej ilustracji przedstawiono prawidłowo skonfigurowaną rozproszoną grupę dostępności:
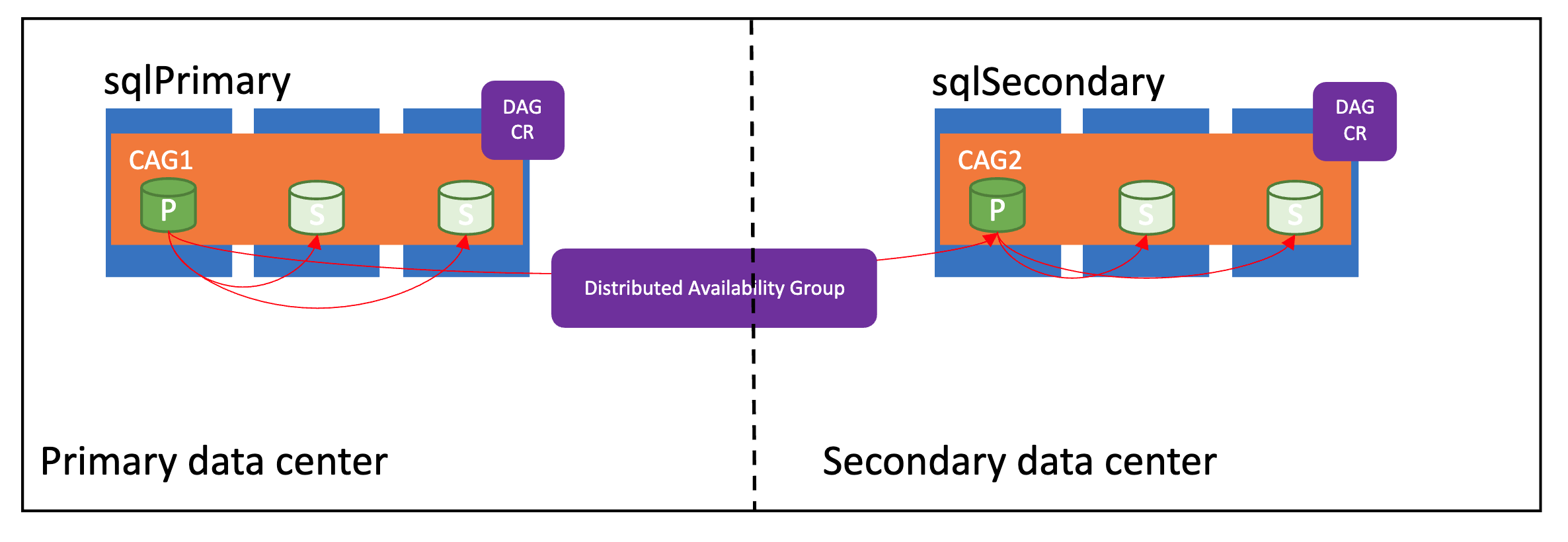
Tryby synchronizacji
Grupy trybu failover w usługach danych usługi Azure Arc obsługują dwa tryby synchronizacji — sync i async. Tryb synchronizacji ma bezpośredni wpływ na sposób synchronizacji danych między wystąpieniami i potencjalnie wydajność w podstawowym wystąpieniu zarządzanym.
Jeśli lokacje główne i dodatkowe znajdują się w odległości kilku mil od siebie, użyj sync trybu . W przeciwnym razie użyj async trybu, aby uniknąć wpływu na wydajność w lokacji głównej.
Konfigurowanie grupy trybu failover platformy Azure — tryb bezpośredni
Wykonaj poniższe kroki, jeśli usługi danych usługi Azure Arc są wdrażane w directly trybie połączonym.
Po spełnieniu wymagań wstępnych uruchom poniższe polecenie, aby skonfigurować grupę trybu failover platformy Azure między dwoma wystąpieniami:
az sql instance-failover-group-arc create --name <name of failover group> --mi <primary SQL MI> --partner-mi <Partner MI> --resource-group <name of RG> --partner-resource-group <name of partner MI RG>
Przykład:
az sql instance-failover-group-arc create --name sql-fog --mi sql1 --partner-mi sql2 --resource-group rg-name --partner-resource-group rg-name
Powyższe polecenie:
- Tworzy wymagane zasoby niestandardowe w lokacjach głównych i dodatkowych
- Kopiuje certyfikaty dublowania i konfiguruje grupę trybu failover między wystąpieniami
Konfigurowanie grupy trybu failover platformy Azure — tryb pośredni
Wykonaj poniższe kroki, jeśli usługi danych Usługi Azure Arc są wdrażane w indirectly trybie połączonym.
Aprowizuj wystąpienie zarządzane w lokacji głównej.
az sql mi-arc create --name <primaryinstance> --tier bc --replicas 3 --k8s-namespace <namespace> --use-k8sPrzełącz kontekst do klastra pomocniczego, uruchamiając
kubectl config use-context <secondarycluster>i aprowizując wystąpienie zarządzane w lokacji dodatkowej, które będzie wystąpieniem odzyskiwania po awarii. W tym momencie systemowe bazy danych nie są częścią zawartej grupy dostępności.Uwaga
Ważne jest, aby określić
--license-type DisasterRecoverypodczas wystąpienia zarządzanego. Umożliwi to inicjowanie wystąpienia odzyskiwania po awarii z wystąpienia podstawowego w podstawowym centrum danych. Aktualizowanie tej właściwości po wdrożeniu nie będzie miało takiego samego efektu.az sql mi-arc create --name <secondaryinstance> --tier bc --replicas 3 --license-type DisasterRecovery --k8s-namespace <namespace> --use-k8sCertyfikaty dublowania — dane binarne wewnątrz właściwości Certyfikat dublowania wystąpienia zarządzanego są wymagane do utworzenia wystąpienia trybu failover grupy cr (zasobu niestandardowego).
Można to osiągnąć na kilka sposobów:
(a) W przypadku korzystania z
azinterfejsu wiersza polecenia najpierw wygeneruj plik certyfikatu dublowania, a następnie wskaż ten plik podczas konfigurowania grupy trybu failover wystąpienia, aby dane binarne są odczytywane z pliku i kopiowane do cr. Pliki certyfikatów nie są potrzebne po utworzeniu grupy trybu failover.(b) Jeśli używasz metody
kubectl, bezpośrednio skopiuj i wklej dane binarne z wystąpienia zarządzanego CR do pliku yaml, który zostanie użyty do utworzenia grupy trybu failover wystąpienia.Przy użyciu (a) powyżej:
Utwórz plik certyfikatu dublowania dla wystąpienia podstawowego:
az sql mi-arc get-mirroring-cert --name <primaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sPrzykład:
az sql mi-arc get-mirroring-cert --name sqlprimary --cert-file $HOME/sqlcerts/sqlprimary.pem --k8s-namespace my-namespace --use-k8sPołącz się z klastrem pomocniczym i utwórz plik certyfikatu dublowania dla wystąpienia pomocniczego:
az sql mi-arc get-mirroring-cert --name <secondaryinstance> --cert-file </path/name>.pem --k8s-namespace <namespace> --use-k8sPrzykład:
az sql mi-arc get-mirroring-cert --name sqlsecondary --cert-file $HOME/sqlcerts/sqlsecondary.pem --k8s-namespace my-namespace --use-k8sPo utworzeniu plików certyfikatów dublowania skopiuj certyfikat z wystąpienia pomocniczego do udostępnionej/lokalnej ścieżki w klastrze wystąpienia podstawowego i na odwrót.
Utwórz zasób grupy trybu failover w obu lokacjach.
Uwaga
Upewnij się, że wystąpienia SQL mają różne nazwy zarówno dla lokacji głównych, jak i dodatkowych, a wartość powinna być identyczna
shared-namew obu lokacjach.az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for primary failover group resource> --mi <local SQL managed instance name> --role primary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<secondary IP> --partner-mirroring-cert-file <secondary.pem> --k8s-namespace <namespace> --use-k8sPrzykład:
az sql instance-failover-group-arc create --shared-name myfog --name primarycr --mi sqlinstance1 --role primary --partner-mi sqlinstance2 --partner-mirroring-url tcp://10.20.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance2.pem --k8s-namespace my-namespace --use-k8sW wystąpieniu pomocniczym uruchom następujące polecenie, aby skonfigurować niestandardowy zasób grupy trybu failover. W
--partner-mirroring-cert-filetym przypadku należy wskazać ścieżkę, która zawiera plik certyfikatu dublowania wygenerowany z wystąpienia podstawowego zgodnie z opisem w powyższej 3(a).az sql instance-failover-group-arc create --shared-name <name of failover group> --name <name for secondary failover group resource> --mi <local SQL managed instance name> --role secondary --partner-mi <partner SQL managed instance name> --partner-mirroring-url tcp://<primary IP> --partner-mirroring-cert-file <primary.pem> --k8s-namespace <namespace> --use-k8sPrzykład:
az sql instance-failover-group-arc create --shared-name myfog --name secondarycr --mi sqlinstance2 --role secondary --partner-mi sqlinstance1 --partner-mirroring-url tcp://10.10.5.20:970 --partner-mirroring-cert-file $HOME/sqlcerts/sqlinstance1.pem --k8s-namespace my-namespace --use-k8s
Pobieranie stanu kondycji grupy trybu failover platformy Azure
Informacje o grupie trybu failover, takiej jak rola podstawowa, rola pomocnicza i bieżący stan kondycji, można wyświetlić w zasobie niestandardowym w lokacji głównej lub dodatkowej.
Uruchom poniższe polecenie w lokacji głównej i/lub lokacji dodatkowej, aby wyświetlić listę zasobów niestandardowych grup trybu failover:
kubectl get fog -n <namespace>
Opisz zasób niestandardowy, aby pobrać stan grupy trybu failover w następujący sposób:
kubectl describe fog <failover group cr name> -n <namespace>
Operacje dotyczące grupy trybu failover
Po skonfigurowaniu grupy trybu failover między wystąpieniami zarządzanymi można wykonywać różne operacje trybu failover w zależności od okoliczności.
Możliwe scenariusze trybu failover to:
Wystąpienia w obu lokacjach są w dobrej kondycji i należy wykonać tryb failover:
- wykonaj ręczne przejście w tryb failover z podstawowej do pomocniczej bez utraty danych przez ustawienie
role=secondarypodstawowego wystąpienia zarządzanego SQL.
- wykonaj ręczne przejście w tryb failover z podstawowej do pomocniczej bez utraty danych przez ustawienie
Lokacja główna jest w złej kondycji/niedostępna i należy wykonać tryb failover:
- podstawowa usługa SQL Managed Instance włączona przez usługę Azure Arc nie działa/jest w złej kondycji/nie jest osiągalna
- pomocnicze wystąpienie zarządzane SQL włączone przez usługę Azure Arc musi zostać wymusić podwyższenie poziomu do podstawowego z potencjalnymi utratą danych
- gdy oryginalne podstawowe wystąpienie zarządzane SQL włączone przez usługę Azure Arc powraca do trybu online, będzie raportować jako
Primaryrolę i stan złejsecondarykondycji i musi zostać wymuszone do roli, aby można było dołączyć do grupy trybu failover i zsynchronizować dane.
Ręczne przechodzenie w tryb failover (bez utraty danych)
Użyj az sql instance-failover-group-arc update ... grupy poleceń, aby zainicjować tryb failover z podstawowego do pomocniczego. Wszystkie oczekujące transakcje w wystąpieniu podstawowym geograficznym są replikowane do wystąpienia pomocniczego obszaru geograficznego przed przejściem w tryb failover.
Tryb połączony bezpośrednio
Uruchom następujące polecenie, aby zainicjować ręczne przejście w tryb failover w direct trybie połączonym przy użyciu interfejsów API usługi ARM:
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <primary instance> --role secondary --resource-group <resource group>
Przykład:
az sql instance-failover-group-arc update --name myfog --mi sqlmi1 --role secondary --resource-group myresourcegroup
Tryb pośrednio połączony
Uruchom następujące polecenie, aby zainicjować ręczne przejście w tryb failover w indirect trybie połączonym przy użyciu interfejsów API kubernetes:
az sql instance-failover-group-arc update --name <name of failover group resource> --role secondary --k8s-namespace <namespace> --use-k8s
Przykład:
az sql instance-failover-group-arc update --name myfog --role secondary --k8s-namespace my-namespace --use-k8s
Wymuszone przejście w tryb failover z utratą danych
W sytuacji, gdy wystąpienie geograficzne podstawowe stanie się niedostępne, następujące polecenia można uruchomić w pomocniczym wystąpieniu odzyskiwania po awarii geograficznej, aby podwyższyć poziom do podstawowego z wymuszonym przejściem w tryb failover, co spowoduje potencjalną utratę danych.
W pomocniczym wystąpieniu odzyskiwania po awarii geograficznej uruchom następujące polecenie, aby podwyższyć poziom go do roli podstawowej z utratą danych.
Uwaga
--partner-sync-mode Jeśli parametr został skonfigurowany jako sync, należy go zresetować, gdy async pomocniczy jest podwyższony do poziomu podstawowego.
Tryb połączony bezpośrednio
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <instance> --role force-primary-allow-data-loss --resource-group <resource group> --partner-sync-mode async
Przykład:
az sql instance-failover-group-arc update --name myfog --mi sqlmi2 --role force-primary-allow-data-loss --resource-group myresourcegroup --partner-sync-mode async
Tryb pośrednio połączony
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-primary-allow-data-loss --partner-sync-mode async
Gdy wystąpienie geograficzne podstawowe stanie się dostępne, uruchom poniższe polecenie, aby przenieść je do grupy trybu failover i zsynchronizować dane:
Tryb połączony bezpośrednio
az sql instance-failover-group-arc update --name <shared name of failover group> --mi <old primary instance> --role force-secondary --resource-group <resource group>
Tryb pośrednio połączony
az sql instance-failover-group-arc update --k8s-namespace my-namespace --name secondarycr --use-k8s --role force-secondary
Opcjonalnie można skonfigurować go z powrotem do sync trybu, --partner-sync-mode jeśli jest to konieczne.
Operacje po przejściu w tryb failover
Po przejściu w tryb failover z lokacji głównej do lokacji dodatkowej z utratą danych lub bez jej utraty może być konieczne wykonanie następujących czynności:
- Zaktualizuj parametry połączenia dla aplikacji, aby nawiązać połączenie z nowo promowanym podstawowym wystąpieniem zarządzanym usługi Arc SQL
- Jeśli planujesz kontynuować uruchamianie obciążenia produkcyjnego poza lokacją dodatkową, zaktualizuj
--license-typeelement doBasePricelubLicenseIncludedzainicjuj rozliczenia dla wykorzystanych rdzeni wirtualnych.
Powiązana zawartość
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla