Wysoka dostępność z usługą SQL Managed Instance włączoną przez usługę Azure Arc
Wystąpienie zarządzane SQL włączone przez usługę Azure Arc jest wdrażane na platformie Kubernetes jako konteneryzowanej aplikacji. Używa konstrukcji Kubernetes, takich jak zestawy stanowe i magazyn trwały, aby zapewnić wbudowane:
- Monitorowanie kondycji
- Wykrywanie błędów
- Automatyczne przełączanie w tryb failover w celu zachowania kondycji usługi.
W celu zwiększenia niezawodności można również skonfigurować usługę SQL Managed Instance włączoną przez usługę Azure Arc w celu wdrożenia z dodatkowymi replikami w konfiguracji wysokiej dostępności. Kontroler danych usług danych usługi Arc zarządza:
- Monitorowanie
- Wykrywanie błędów
- Automatyczne przełączanie w tryb failover
Usługa danych z obsługą usługi Arc zapewnia tę usługę bez interwencji użytkownika. Usługa:
- Konfigurowanie grupy dostępności
- Konfiguruje punkty końcowe dublowania bazy danych
- Dodaje bazy danych do grupy dostępności
- Koordynuje tryb failover i uaktualnianie.
W tym dokumencie omówiono oba typy wysokiej dostępności.
Wystąpienie zarządzane SQL włączone przez usługę Azure Arc zapewnia różne poziomy wysokiej dostępności w zależności od tego, czy wystąpienie zarządzane SQL zostało wdrożone jako warstwa usługi ogólnego przeznaczenia, czy Krytyczne dla działania firmy warstwę usługi.
Wysoka dostępność w warstwie usługi Ogólnego przeznaczenia
W warstwie usługi Ogólnego przeznaczenia dostępna jest tylko jedna replika, a wysoka dostępność jest osiągana za pośrednictwem orkiestracji platformy Kubernetes. Jeśli na przykład zasobnik lub węzeł zawierający obraz kontenera wystąpienia zarządzanego ulegnie awarii, platforma Kubernetes próbuje wstać inny zasobnik lub węzeł i dołączyć go do tego samego magazynu trwałego. W tym czasie wystąpienie zarządzane SQL jest niedostępne dla aplikacji. Aplikacje muszą ponownie nawiązać połączenie i ponowić próbę wykonania transakcji po uruchomieniu nowego zasobnika. Jeśli load balancer jest używany typ usługi, aplikacje mogą ponownie nawiązać połączenie z tym samym podstawowym punktem końcowym, a platforma Kubernetes przekieruje połączenie do nowego podstawowego. Jeśli typ usługi to nodeport wówczas aplikacje będą musiały ponownie nawiązać połączenie z nowym adresem IP.
Weryfikowanie wbudowanej wysokiej dostępności
Aby sprawdzić wysoką dostępność kompilacji zapewnianą przez platformę Kubernetes, możesz:
- Usuwanie zasobnika istniejącego wystąpienia zarządzanego
- Sprawdź, czy platforma Kubernetes odzyskuje dane z tej akcji
Podczas odzyskiwania platforma Kubernetes uruchamia kolejny zasobnik i dołącza magazyn trwały.
Wymagania wstępne
- Klaster Kubernetes wymaga udostępnionego magazynu zdalnego
- Wystąpienie zarządzane SQL włączone przez usługę Azure Arc wdrożone z jedną repliką (domyślnie)
Wyświetl zasobniki.
kubectl get pods -n <namespace of data controller>Usuń zasobnik wystąpienia zarządzanego.
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>Na przykład
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deletedWyświetl zasobniki, aby sprawdzić, czy wystąpienie zarządzane jest odzyskiwane.
kubectl get pods -n <namespace of data controller>Na przykład:
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
Po odzyskaniu wszystkich kontenerów w zasobniku można nawiązać połączenie z wystąpieniem zarządzanym.
Wysoka dostępność w warstwie usługi Krytyczne dla działania firmy
W warstwie usługi Krytyczne dla działania firmy oprócz tego, co jest natywnie udostępniane przez orkiestrację platformy Kubernetes, usługa SQL Managed Instance dla usługi Azure Arc udostępnia zawartą grupę dostępności. Zawarta grupa dostępności jest oparta na technologii Always On programu SQL Server. Zapewnia on wyższy poziom dostępności. Wystąpienie zarządzane SQL włączone przez usługę Azure Arc wdrożone przy użyciu warstwy usługi Krytyczne dla działania firmy można wdrożyć z replikami 2 lub 3. Te repliki są zawsze synchronizowane ze sobą.
W przypadku zawartych grup dostępności wszystkie awarie zasobnika lub awarie węzła są niewidoczne dla aplikacji. Zawarta grupa dostępności udostępnia co najmniej jeden inny zasobnik, który zawiera wszystkie dane z serwera podstawowego i jest gotowy do podjęcia połączeń.
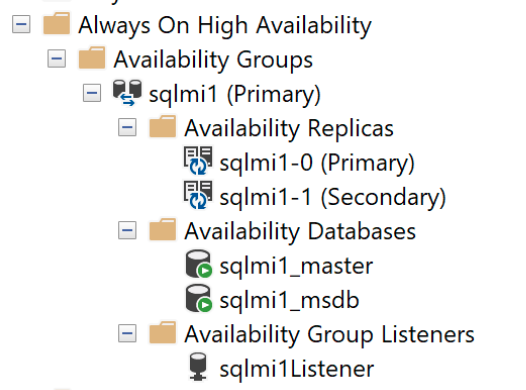
Zawarte grupy dostępności
Grupa dostępności wiąże co najmniej jedną bazę danych użytkowników z grupą logiczną, tak aby w przypadku przejścia w tryb failover cała grupa baz danych przechodziła w tryb failover do repliki pomocniczej jako pojedyncza jednostka. Grupa dostępności replikuje tylko dane w bazach danych użytkowników, ale nie dane w systemowych bazach danych, takich jak identyfikatory logowania, uprawnienia lub zadania agenta. Zawarta grupa dostępności zawiera metadane z systemowych baz danych, takich jak msdb i master bazy danych. Gdy identyfikatory logowania są tworzone lub modyfikowane w replice podstawowej, są one również automatycznie tworzone w replikach pomocniczych. Podobnie, gdy zadanie agenta zostanie utworzone lub zmodyfikowane w repliki podstawowej, repliki pomocnicze również otrzymają te zmiany.
Usługa SQL Managed Instance włączona przez usługę Azure Arc przyjmuje tę koncepcję zawartej grupy dostępności i dodaje operator Kubernetes, dzięki czemu można je wdrażać i zarządzać na dużą skalę.
Możliwości, które zawierały grupy dostępności, umożliwiają:
Po wdrożeniu z wieloma replikami tworzona jest pojedyncza grupa dostępności o takiej samej nazwie jak wystąpienie zarządzane SQL z obsługą usługi Arc. Domyślnie zawarta grupa dostępności ma trzy repliki, w tym podstawowe. Wszystkie operacje CRUD dla grupy dostępności są zarządzane wewnętrznie, w tym tworzenie grupy dostępności lub dołączanie replik do utworzonej grupy dostępności. Nie można utworzyć większej liczby grup dostępności w wystąpieniu.
Wszystkie bazy danych są automatycznie dodawane do grupy dostępności, w tym wszystkich baz danych użytkowników i systemów, takich jak
masterimsdb. Ta funkcja zapewnia widok pojedynczego systemu w replikach grup dostępności. Zwróć uwagę zarówno nacontainedag_masterbazy danych, jak icontainedag_msdbw przypadku bezpośredniego nawiązania połączenia z wystąpieniem. Bazycontainedag_*danych reprezentują elementmasterimsdbwewnątrz grupy dostępności.Zewnętrzny punkt końcowy jest automatycznie aprowizowany do łączenia się z bazami danych w grupie dostępności. Ten punkt końcowy
<managed_instance_name>-external-svcodgrywa rolę odbiornika grupy dostępności.
Wdrażanie usługi SQL Managed Instance włączonej przez usługę Azure Arc z wieloma replikami przy użyciu witryny Azure Portal
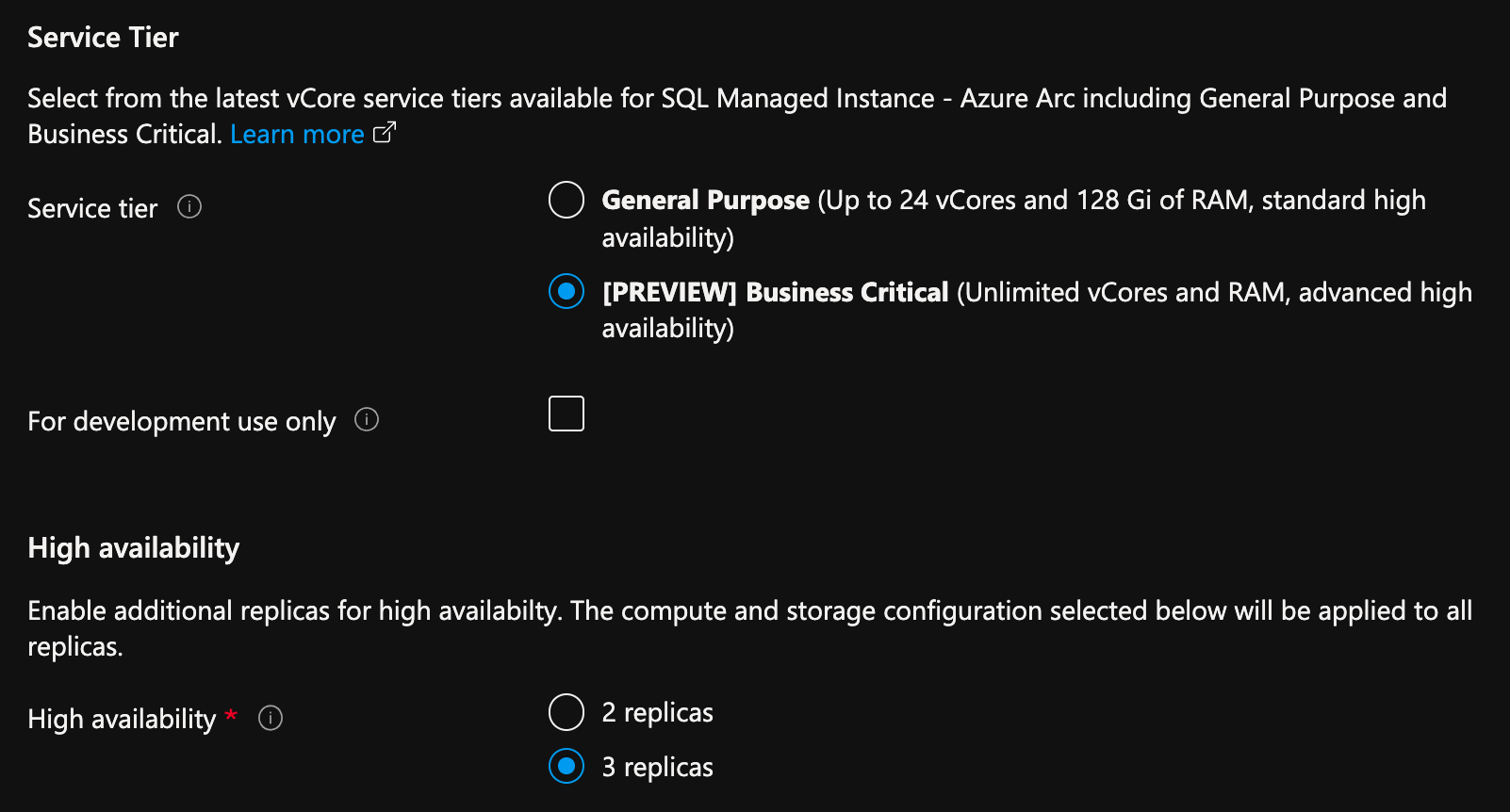
W witrynie Azure Portal na stronie tworzenia wystąpienia zarządzanego SQL włączonego przez usługę Azure Arc:
- Wybierz pozycję Konfiguruj obliczenia i magazyn w obszarze Obliczenia i magazyn. W portalu są wyświetlane ustawienia zaawansowane.
- W obszarze Warstwa usługi wybierz pozycję Krytyczne dla działania firmy.
- Sprawdź wartość "Tylko do użytku programistycznego", jeśli jest używana do celów programistycznych.
- W obszarze Wysoka dostępność wybierz 2 repliki lub 3 repliki.
Wdrażanie przy użyciu wielu replik przy użyciu interfejsu wiersza polecenia platformy Azure
Gdy wystąpienie zarządzane SQL włączone przez usługę Azure Arc jest wdrażane w Krytyczne dla działania firmy warstwie usługi, wdrożenie tworzy wiele replik. Konfiguracja i konfiguracja zawartych grup dostępności między tymi wystąpieniami jest wykonywana automatycznie podczas aprowizacji.
Na przykład następujące polecenie tworzy wystąpienie zarządzane z 3 replikami.
Pośrednio połączony tryb:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
Przykład:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
Tryb bezpośrednio połączony:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
Przykład:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
Domyślnie wszystkie repliki są konfigurowane w trybie synchronicznym. Oznacza to, że wszystkie aktualizacje w wystąpieniu podstawowym są synchronicznie replikowane do każdego z wystąpień pomocniczych.
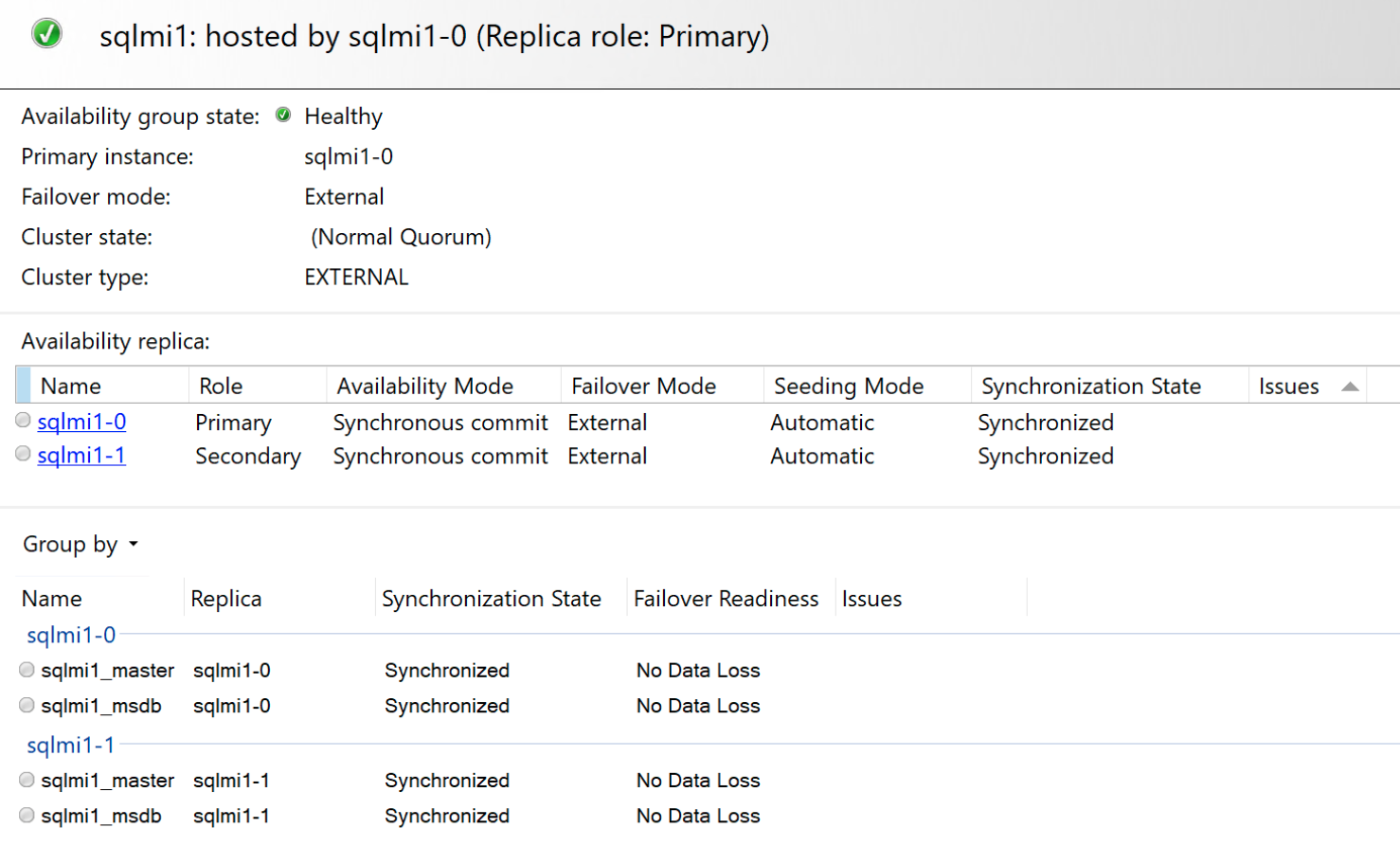
Wyświetlanie i monitorowanie stanu wysokiej dostępności
Po zakończeniu wdrażania połącz się z podstawowym punktem końcowym z programu SQL Server Management Studio.
Zweryfikuj i pobierz punkt końcowy repliki podstawowej i połącz się z nim z programu SQL Server Management Studio.
Jeśli na przykład wystąpienie SQL zostało wdrożone przy użyciu service-type=loadbalancerpolecenia , uruchom poniższe polecenie, aby pobrać punkt końcowy w celu nawiązania połączenia z:
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
lub
kubectl get sqlmi -A
Pobieranie podstawowych i pomocniczych punktów końcowych oraz stanu grupy dostępności
kubectl describe sqlmi Użyj poleceń lubaz sql mi-arc show, aby wyświetlić podstawowe i pomocnicze punkty końcowe oraz stan wysokiej dostępności.
Przykład:
kubectl describe sqlmi sqldemo -n my-namespace
lub
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
Przykładowe wyjście:
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
Możesz nawiązać połączenie z podstawowym punktem końcowym za pomocą programu SQL Server Management Studio i zweryfikować dynamiczne widoki zarządzania jako:
SELECT * FROM sys.dm_hadr_availability_replica_states
A pulpit nawigacyjny zawartej dostępności:
Scenariusze trybu failover
W przeciwieństwie do zawsze włączonych grup dostępności programu SQL Server zawarta grupa dostępności jest zarządzanym rozwiązaniem o wysokiej dostępności. W związku z tym tryby trybu failover są ograniczone w porównaniu z typowymi trybami dostępnymi w przypadku zawsze włączonych grup dostępności programu SQL Server.
Wdróż Krytyczne dla działania firmy wystąpienia zarządzane SQL w konfiguracji z dwiema replikami lub w trzech konfiguracjach repliki. Skutki awarii i kolejne możliwości odzyskiwania różnią się w przypadku każdej konfiguracji. Trzy wystąpienie repliki zapewnia wyższy poziom dostępności i odzyskiwania niż dwa wystąpienie repliki.
W konfiguracji dwóch replik, gdy oba stany węzła to SYNCHRONIZED, jeśli replika podstawowa stanie się niedostępna, replika pomocnicza jest automatycznie promowana do podstawowej. Gdy replika, która uległa awarii, stanie się dostępna, zostanie zaktualizowana o wszystkie oczekujące zmiany. Jeśli występują problemy z łącznością między replikami, replika podstawowa może nie zatwierdzać żadnych transakcji, ponieważ każda transakcja musi zostać zatwierdzona w obu replikach, zanim powodzenie zostanie zwrócone z powrotem na serwerze podstawowym.
W przypadku trzech konfiguracji replik transakcja musi zatwierdzić co najmniej 2 z 3 replik przed zwróceniem komunikatu o powodzeniu z powrotem do aplikacji. W przypadku awarii jeden z drugich jest automatycznie awansowany do podstawowego, podczas gdy platforma Kubernetes próbuje odzyskać replikę, która zakończyła się niepowodzeniem. Gdy replika stanie się dostępna, jest automatycznie przyłączona z powrotem do zawartej grupy dostępności i oczekujące zmiany są synchronizowane. Jeśli występują problemy z łącznością między replikami, a więcej niż 2 repliki nie są zsynchronizowane, replika podstawowa nie zatwierdzi żadnych transakcji.
Uwaga
Zaleca się wdrożenie usługi Krytyczne dla działania firmy SQL Managed Instance w konfiguracji z trzema replikami niż dwie konfiguracje repliki w celu osiągnięcia niemal zerowej utraty danych.
Aby przejść w tryb failover z repliki podstawowej do jednego z drugich, w przypadku planowanego zdarzenia uruchom następujące polecenie:
Jeśli nawiąższ połączenie z serwerem podstawowym, możesz użyć następującego języka T-SQL, aby przejąć wystąpienie SQL w tryb failover z jednym z serwerów pomocniczych:
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
Jeśli łączysz się z pomocniczym elementem pomocniczym, możesz użyć następującego języka T-SQL, aby podwyższyć poziom żądanej repliki pomocniczej do repliki podstawowej.
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
Preferowana replika podstawowa
Można również ustawić określoną replikę jako replikę podstawową przy użyciu interfejsu wiersza polecenia az w następujący sposób:
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
Przykład:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
Uwaga
Platforma Kubernetes podejmie próbę ustawienia preferowanej repliki, jednak nie jest gwarantowana.
Przywracanie bazy danych do wystąpienia z wieloma replikami
Aby przywrócić bazę danych do grupy dostępności, wymagane są dodatkowe kroki. W poniższych krokach pokazano, jak przywrócić bazę danych do wystąpienia zarządzanego i dodać ją do grupy dostępności.
Uwidocznij zewnętrzny punkt końcowy wystąpienia podstawowego, tworząc nową usługę Kubernetes.
Określ zasobnik hostujący replikę podstawową. Połącz się z wystąpieniem zarządzanym i uruchom polecenie:
SELECT @@SERVERNAMEZapytanie zwraca zasobnik hostujący replikę podstawową.
Utwórz usługę Kubernetes w wystąpieniu podstawowym, uruchamiając następujące polecenie, jeśli klaster Kubernetes korzysta z
NodePortusług. Zastąp<podName>ciąg nazwą serwera zwróconą w poprzednim kroku<serviceName>z preferowaną nazwą utworzonej usługi Kubernetes.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortW przypadku usługi LoadBalancer uruchom to samo polecenie, z tą różnicą, że typ utworzonej usługi to
LoadBalancer. Na przykład:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerOto przykład tego polecenia uruchamianego w usłudze Azure Kubernetes Service, gdzie zasobnik hostuje element podstawowy:
sql2-0kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancerPobierz adres IP utworzonej usługi Kubernetes:
kubectl get services -n <namespaceName>Przywróć bazę danych do punktu końcowego wystąpienia podstawowego.
Dodaj plik kopii zapasowej bazy danych do kontenera wystąpienia podstawowego.
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>Przykład
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arcPrzywróć plik kopii zapasowej bazy danych, uruchamiając poniższe polecenie.
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GOPrzykład
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GODodaj bazę danych do grupy dostępności.
Aby baza danych została dodana do grupy dostępności, musi działać w trybie pełnego odzyskiwania i należy wykonać kopię zapasową dziennika. Uruchom poniższe instrukcje TSQL, aby dodać przywróconą bazę danych do grupy dostępności.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>Poniższy przykład dodaje bazę danych o nazwie
WideWorldImporters, która została przywrócona w wystąpieniu:ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
Ważne
Najlepszym rozwiązaniem jest usunięcie usługi Kubernetes utworzonej powyżej, uruchamiając następujące polecenie:
kubectl delete svc sql2-0-p -n arc
Ograniczenia
Wystąpienie zarządzane SQL włączone przez grupy dostępności usługi Azure Arc ma takie same ograniczenia jak grupy dostępności klastra danych big data. Aby uzyskać więcej informacji, zobacz Wdrażanie klastra danych big data programu SQL Server o wysokiej dostępności.
Powiązana zawartość
Dowiedz się więcej o funkcjach i możliwościach usługi SQL Managed Instance włączonej przez usługę Azure Arc