Wdrażanie kontenera usługi Azure SQL Edge na platformie Kubernetes
Ważne
Azure SQL Edge nie obsługuje już platformy ARM64.
Azure SQL Edge można wdrożyć w klastrze Kubernetes zarówno jako moduł IoT Edge za pośrednictwem usługi Azure IoT Edge działającego na platformie Kubernetes, jak i jako autonomicznego zasobnika kontenera. W pozostałej części tego artykułu skupimy się na autonomicznym wdrożeniu kontenera w klastrze Kubernetes. Aby uzyskać informacje na temat wdrażania usługi Azure IoT Edge na platformie Kubernetes, zobacz Azure IoT Edge on Kubernetes (wersja zapoznawcza).
W tym samouczku pokazano, jak skonfigurować wystąpienie usługi Azure SQL Edge o wysokiej dostępności w kontenerze w klastrze Kubernetes.
- Tworzenie hasła sa
- Tworzenie magazynu
- Tworzenie wdrożenia
- Nawiązywanie połączenia za pomocą programu SQL Server Management Studio (SSMS)
- Weryfikowanie niepowodzenia i odzyskiwania
Platforma Kubernetes 1.6 lub nowsza obsługuje klasy magazynu, oświadczenia trwałego woluminu i typ woluminu dysku platformy Azure. Wystąpienia usługi Azure SQL Edge można tworzyć i zarządzać nimi natywnie na platformie Kubernetes. W przykładzie w tym artykule pokazano, jak utworzyć wdrożenie w celu osiągnięcia konfiguracji wysokiej dostępności podobnej do wystąpienia klastra trybu failover dysku udostępnionego. W tej konfiguracji platforma Kubernetes odgrywa rolę koordynatora klastra. Gdy wystąpienie usługi Azure SQL Edge w kontenerze zakończy się niepowodzeniem, program orchestrator uruchamia kolejne wystąpienie kontenera, które jest dołączane do tego samego magazynu trwałego.
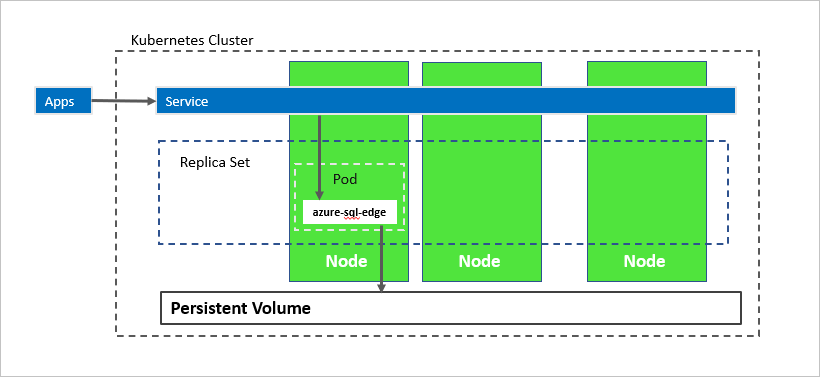
Na powyższym diagramie azure-sql-edge jest kontenerem w zasobniku. Platforma Kubernetes organizuje zasoby w klastrze. Zestaw replik gwarantuje, że zasobnik zostanie automatycznie odzyskany po awarii węzła. Aplikacje łączą się z usługą. W takim przypadku usługa reprezentuje moduł równoważenia obciążenia, który hostuje adres IP, który pozostaje taki sam po awarii azure-sql-edge.
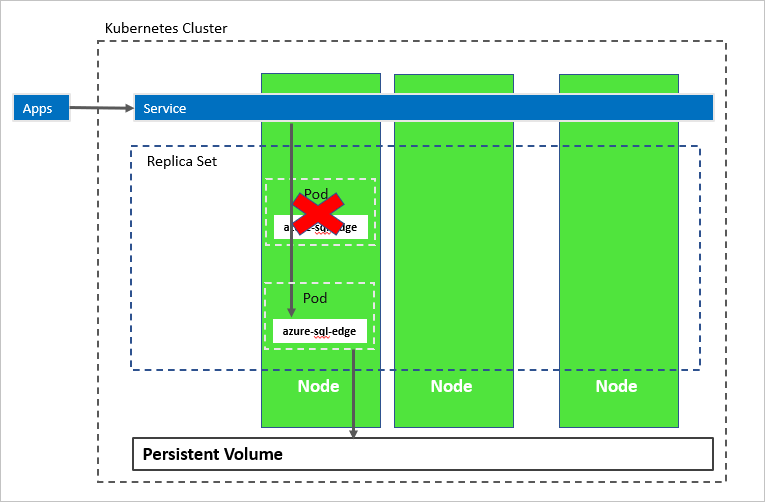
Na poniższym diagramie azure-sql-edge kontener zakończył się niepowodzeniem. Jako koordynator platforma Kubernetes gwarantuje poprawną liczbę wystąpień w dobrej kondycji w zestawie replik i uruchamia nowy kontener zgodnie z konfiguracją. Koordynator uruchamia nowy zasobnik w tym samym węźle i azure-sql-edge ponownie łączy się z tym samym magazynem trwałym. Usługa łączy się z utworzonym ponownie elementem azure-sql-edge.
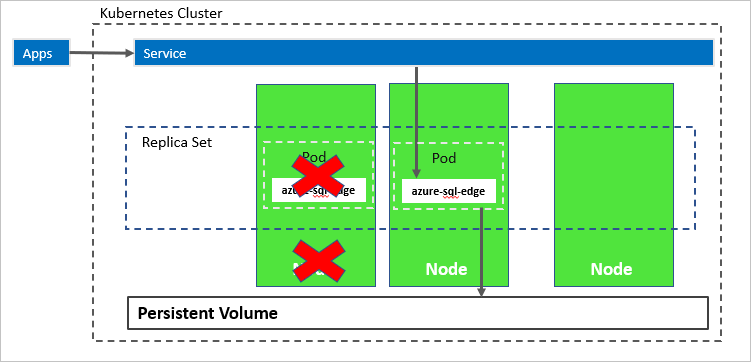
Na poniższym diagramie węzeł hostowany azure-sql-edge kontener nie powiódł się. Koordynator uruchamia nowy zasobnik w innym węźle i azure-sql-edge ponownie łączy się z tym samym magazynem trwałym. Usługa łączy się z utworzonym ponownie elementem azure-sql-edge.
Wymagania wstępne
Klaster Kubernetes
Samouczek wymaga klastra Kubernetes. Kroki używania narzędzia kubectl do zarządzania klastrem.
Na potrzeby tego samouczka używamy Azure Kubernetes Service do wdrażania usługi Azure SQL Edge. Zobacz Deploy an Azure Kubernetes Service cluster (AKS) to create and connect to a single-node Kubernetes cluster in AKS with
kubectl.
Uwaga
Aby chronić przed awarią węzła, klaster Kubernetes wymaga więcej niż jednego węzła.
Interfejs wiersza polecenia platformy Azure
- Instrukcje opisane w tym samouczku zostały zweryfikowane względem interfejsu wiersza polecenia platformy Azure 2.10.1.
Tworzenie przestrzeni nazw Kubernetes dla wdrożenia usługi SQL Edge
Utwórz nową przestrzeń nazw w klastrze kubernetes. Ta przestrzeń nazw służy do wdrażania programu SQL Edge i wszystkich wymaganych artefaktów. Aby uzyskać więcej informacji na temat przestrzeni nazw platformy Kubernetes, zobacz przestrzenie nazw.
kubectl create namespace <namespace name>
Tworzenie hasła sa
Utwórz hasło sa w klastrze Kubernetes. Platforma Kubernetes może zarządzać poufnymi informacjami o konfiguracji, takimi jak hasła jako wpisy tajne.
Następujące polecenie tworzy hasło dla konta sa:
kubectl create secret generic mssql --from-literal=SA_PASSWORD="MyC0m9l&xP@ssw0rd" -n <namespace name>
Zastąp ciąg MyC0m9l&xP@ssw0rd złożonym hasłem.
Tworzenie magazynu
Konfigurowanie trwałego woluminu i trwałego oświadczenia woluminu w klastrze Kubernetes. Wykonaj poniższe czynności:
Utwórz manifest, aby zdefiniować klasę magazynu i oświadczenie trwałego woluminu. Manifest określa aprowizację magazynu, parametry i zasady odzyskiwania. Klaster Kubernetes używa tego manifestu do utworzenia magazynu trwałego.
Poniższy przykład yaml definiuje klasę magazynu i trwałe oświadczenie woluminu. Aprowizacja klasy magazynu to
azure-disk, ponieważ ten klaster Kubernetes znajduje się na platformie Azure. Typ konta magazynu toStandard_LRS. Oświadczenie trwałego woluminu nosi nazwęmssql-data. Metadane oświadczeń trwałych woluminów zawierają adnotację łączącą ją z klasą magazynu.kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: azure-disk provisioner: kubernetes.io/azure-disk parameters: storageaccounttype: Standard_LRS kind: managed --- kind: PersistentVolumeClaim apiVersion: v1 metadata: name: mssql-data annotations: volume.beta.kubernetes.io/storage-class: azure-disk spec: accessModes: - ReadWriteOnce resources: requests: storage: 8GiZapisz plik (na przykład pvc.yaml).
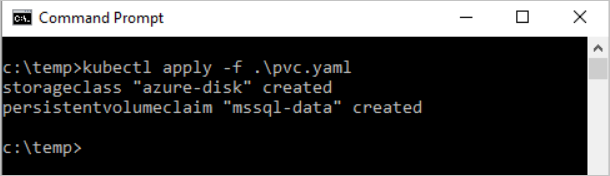
Utwórz oświadczenie trwałego woluminu na platformie Kubernetes.
kubectl apply -f <Path to pvc.yaml file> -n <namespace name><Path to pvc.yaml file>to lokalizacja, w której zapisano plik.Wolumin trwały jest tworzony automatycznie jako konto usługi Azure Storage i powiązany z trwałym oświadczeniem woluminu.
Sprawdź trwałe oświadczenie woluminu.
kubectl describe pvc <PersistentVolumeClaim> -n <name of the namespace><PersistentVolumeClaim>jest nazwą oświadczenia trwałego woluminu.W poprzednim kroku oświadczenie trwałego woluminu nosi nazwę
mssql-data. Aby wyświetlić metadane dotyczące trwałego oświadczenia woluminu, uruchom następujące polecenie:kubectl describe pvc mssql-data -n <namespace name>Zwrócone metadane zawierają wartość o nazwie
Volume. Ta wartość jest mapowania na nazwę obiektu blob.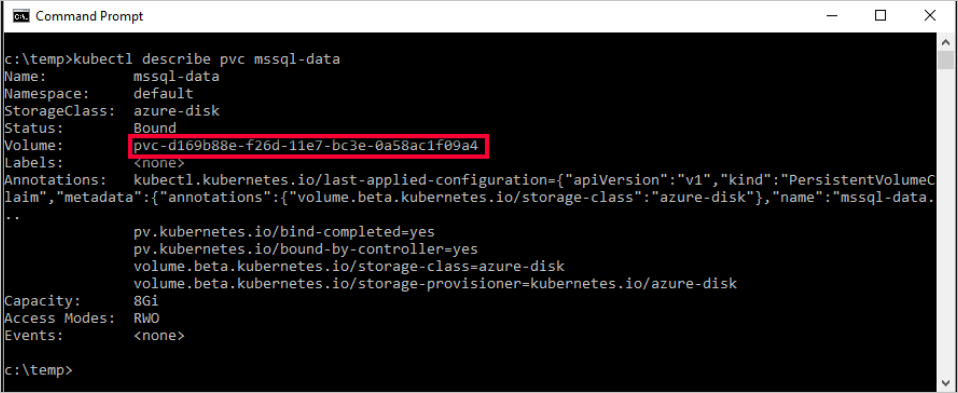
Sprawdź wolumin trwały.
kubectl describe pv -n <namespace name>kubectlzwraca metadane dotyczące woluminu trwałego, który został utworzony automatycznie i powiązany z trwałym oświadczeniem woluminu.
Tworzenie wdrożenia
W tym przykładzie kontener hostujący wystąpienie usługi Azure SQL Edge jest opisany jako obiekt wdrożenia Kubernetes. Wdrożenie tworzy zestaw replik. Zestaw replik tworzy zasobnik.
W tym kroku utwórz manifest opisujący kontener na podstawie obrazu platformy Docker usługi Azure SQL Edge. Manifest odwołuje się do oświadczenia trwałego woluminu mssql-data i wpisu tajnego mssql , który został już zastosowany do klastra Kubernetes. Manifest opisuje również usługę. Ta usługa jest modułem równoważenia obciążenia. Moduł równoważenia obciążenia gwarantuje, że adres IP będzie się powtarzać po odzyskaniu wystąpienia usługi Azure SQL Edge.
Utwórz manifest (plik YAML), aby opisać wdrożenie. W poniższym przykładzie opisano wdrożenie, w tym kontener oparty na obrazie kontenera usługi Azure SQL Edge.
apiVersion: apps/v1 kind: Deployment metadata: name: sqledge-deployment spec: replicas: 1 selector: matchLabels: app: sqledge template: metadata: labels: app: sqledge spec: volumes: - name: sqldata persistentVolumeClaim: claimName: mssql-data containers: - name: azuresqledge image: mcr.microsoft.com/azure-sql-edge:latest ports: - containerPort: 1433 volumeMounts: - name: sqldata mountPath: /var/opt/mssql env: - name: MSSQL_PID value: "Developer" - name: ACCEPT_EULA value: "Y" - name: SA_PASSWORD valueFrom: secretKeyRef: name: mssql key: SA_PASSWORD - name: MSSQL_AGENT_ENABLED value: "TRUE" - name: MSSQL_COLLATION value: "SQL_Latin1_General_CP1_CI_AS" - name: MSSQL_LCID value: "1033" terminationGracePeriodSeconds: 30 securityContext: fsGroup: 10001 --- apiVersion: v1 kind: Service metadata: name: sqledge-deployment spec: selector: app: sqledge ports: - protocol: TCP port: 1433 targetPort: 1433 name: sql type: LoadBalancerSkopiuj powyższy kod do nowego pliku o nazwie
sqldeployment.yaml. Zaktualizuj następujące wartości:value: "Developer"MSSQL_PID: ustawia kontener na uruchamianie wersji Azure SQL Edge Developer. Wersja deweloperów nie jest licencjonowana na dane produkcyjne. Jeśli wdrożenie jest używane w środowisku produkcyjnym, ustaw wersję naPremium.Uwaga
Aby uzyskać więcej informacji, zobacz Jak licencjonować Azure SQL Edge.
persistentVolumeClaim: Ta wartość wymaga wpisu, któryclaimName:mapuje nazwę używaną dla oświadczenia trwałego woluminu. W tym samouczku użyto regionumssql-data.name: SA_PASSWORD: Konfiguruje obraz kontenera w celu ustawienia hasła administratora systemu , zgodnie z definicją w tej sekcji.valueFrom: secretKeyRef: name: mssql key: SA_PASSWORDGdy platforma Kubernetes wdraża kontener, odwołuje się do wpisu tajnego o nazwie
mssql, aby uzyskać wartość hasła.
Uwaga
Korzystając z
LoadBalancertypu usługi, wystąpienie usługi Azure SQL Edge jest dostępne zdalnie (za pośrednictwem Internetu) na porcie 1433.Zapisz plik (na przykład
sqledgedeploy.yaml).Utwórz wdrożenie.
kubectl apply -f <Path to sqledgedeploy.yaml file> -n <namespace name><Path to sqldeployment.yaml file>to lokalizacja, w której zapisano plik.
Zostanie utworzone wdrożenie i usługa. Wystąpienie usługi Azure SQL Edge znajduje się w kontenerze połączonym z magazynem trwałym.
Aby wyświetlić stan zasobnika, wpisz
kubectl get pod -n <namespace name>.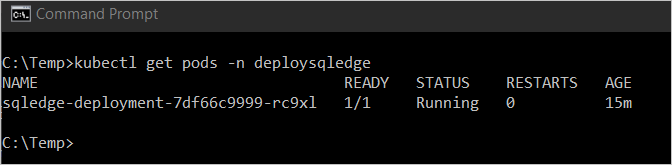
Na powyższym obrazie zasobnik ma stan
Running. Ten stan wskazuje, że kontener jest gotowy. Może to potrwać kilka minut.Uwaga
Po utworzeniu wdrożenia może upłynąć kilka minut, zanim zasobnik będzie widoczny. Opóźnienie jest spowodowane tym, że klaster ściąga obraz kontenera usługi Azure SQL Edge z centrum Platformy Docker. Po pierwszym ściągnięciu obrazu kolejne wdrożenia mogą być szybsze, jeśli wdrożenie jest w węźle, który ma już zapisany obraz w pamięci podręcznej.
Sprawdź, czy usługi są uruchomione. Uruchom następujące polecenie:
kubectl get services -n <namespace name>To polecenie zwraca uruchomione usługi, a także wewnętrzne i zewnętrzne adresy IP dla usług. Zanotuj zewnętrzny adres
mssql-deploymentIP usługi. Użyj tego adresu IP, aby nawiązać połączenie z usługą Azure SQL Edge.
Aby uzyskać więcej informacji na temat stanu obiektów w klastrze Kubernetes, uruchom polecenie:
az aks browse --resource-group <MyResourceGroup> --name <MyKubernetesClustername>
Nawiązywanie połączenia z wystąpieniem usługi Azure SQL Edge
Jeśli skonfigurowano kontener zgodnie z opisem, możesz nawiązać połączenie z aplikacją spoza sieci wirtualnej platformy Azure.
sa Użyj konta i zewnętrznego adresu IP dla usługi. Użyj hasła skonfigurowanego jako wpis tajny platformy Kubernetes. Aby uzyskać więcej informacji na temat nawiązywania połączenia z wystąpieniem usługi Azure SQL Edge, zobacz Nawiązywanie połączenia z usługą Azure SQL Edge.
Weryfikowanie niepowodzenia i odzyskiwania
Aby zweryfikować niepowodzenie i odzyskiwanie, możesz usunąć zasobnik. Wykonaj następujące czynności:
Wyświetl listę zasobników z uruchomioną usługą Azure SQL Edge.
kubectl get pods -n <namespace name>Zanotuj nazwę zasobnika uruchomionego Azure SQL Edge.
Usuń zasobnik.
kubectl delete pod sqledge-deployment-7df66c9999-rc9xlsqledge-deployment-7df66c9999-rc9xlto wartość zwrócona z poprzedniego kroku dla nazwy zasobnika.
Platforma Kubernetes automatycznie ponownie tworzy zasobnik w celu odzyskania wystąpienia usługi Azure SQL Edge i nawiązania połączenia z magazynem trwałym. Użyj polecenia kubectl get pods , aby sprawdzić, czy jest wdrożony nowy zasobnik. Użyj polecenia kubectl get services , aby sprawdzić, czy adres IP nowego kontenera jest taki sam.
Podsumowanie
W tym samouczku przedstawiono sposób wdrażania kontenerów usługi Azure SQL Edge w klastrze Kubernetes w celu zapewnienia wysokiej dostępności.
- Tworzenie hasła administratora systemu
- Tworzenie magazynu
- Tworzenie wdrożenia
- Nawiązywanie połączenia z Azure SQL Edge Management Studios (SSMS)
- Weryfikowanie niepowodzenia i odzyskiwania
Następne kroki
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla