Zarządzanie miejscem na pliki dla baz danych w usłudze Azure SQL Database
Dotyczy: ![]() Azure SQL Database
Azure SQL Database
W tym artykule opisano różne typy miejsca do magazynowania dla baz danych w usłudze Azure SQL Database oraz kroki, które można wykonać, gdy przydzielone miejsce na plik musi być jawnie zarządzane.
Omówienie
W usłudze Azure SQL Database istnieją wzorce obciążenia, w których alokacja bazowych plików danych dla baz danych może być większa niż liczba używanych stron danych. Ten warunek może wystąpić, gdy ilość używanego miejsca zwiększa się, a dane zostaną później usunięte. Przyczyną jest to, że przydzielone miejsce na pliki nie jest automatycznie odzyskiwane po usunięciu danych.
Monitorowanie użycia miejsca na pliki i zmniejszania plików danych może być konieczne w następujących scenariuszach:
- Zezwalanie na wzrost ilości danych w elastycznej puli, gdy miejsce na pliki przydzielone dla jej baz danych osiągnie maksymalny rozmiar dla puli.
- Zezwalanie na zmniejszenie maksymalnego rozmiaru pojedynczej bazy danych lub elastycznej puli.
- Zezwalanie na zmianę warstwy usługi lub wydajności dla pojedynczej bazy danych lub elastycznej puli na warstwę obsługującą mniejszy rozmiar maksymalny.
Uwaga
Operacje zmniejszania nie powinny być traktowane jako regularne operacje konserwacji. Pliki danych i dzienników, które rosną z powodu regularnych, cyklicznych operacji biznesowych nie wymagają operacji zmniejszania.
Monitorowanie użycia miejsca na plikach
Większość metryk miejsca do magazynowania wyświetlanych w następujących interfejsach API mierzy tylko rozmiar używanych stron danych:
- Interfejsy API metryk opartych na usłudze Azure Resource Manager, w tym get-metrics programu PowerShell
Jednak następujące interfejsy API mierzą również rozmiar miejsca przydzielonego dla baz danych i elastycznych pul:
- T-SQL: sys.resource_stats
- T-SQL: sys.elastic_pool_resource_stats
Omówienie typów miejsca do magazynowania dla bazy danych
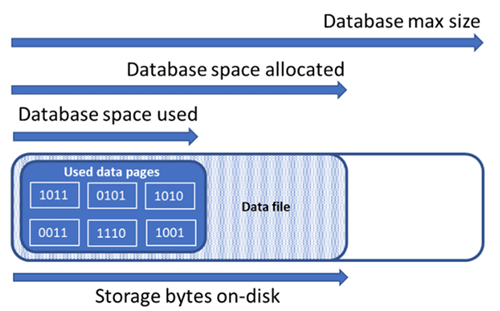
Zrozumienie następujących ilości miejsca do magazynowania jest ważne w przypadku zarządzania przestrzenią plików bazy danych.
| Liczba baz danych | Definicja | Komentarze |
|---|---|---|
| Używane miejsce danych | Ilość miejsca używanego do przechowywania danych bazy danych. | Ogólnie rzecz biorąc, używane miejsce zwiększa (zmniejsza) w wstawkach (usunięciach). W niektórych przypadkach używane miejsce nie zmienia się w wstawianiu ani usuwaniu w zależności od ilości i wzorca danych zaangażowanych w operację i wszelkich fragmentacji. Na przykład usunięcie jednego wiersza z każdej strony danych nie zawsze powoduje zmniejszenie ilości używanego miejsca. |
| Przydzielone miejsce na dane | Ilość miejsca na sformatowane pliki udostępnionego na potrzeby przechowywania danych bazy danych. | Ilość przydzielonego miejsca zwiększa się automatycznie, ale nigdy nie zmniejsza się po usunięciu danych. Takie zachowanie zapewnia szybsze wstawianie w przyszłości, ponieważ nie trzeba ponownie sformatować miejsca. |
| Przydzielone miejsce na dane, ale nieużywane | Różnica między ilością przydzielonego miejsca na dane a używanym miejscem na dane. | Ta wielkość odzwierciedla maksymalną ilość wolnego miejsca, którą można odzyskać, zmniejszając pliki danych bazy danych. |
| Maksymalny rozmiar danych | Maksymalna ilość miejsca, która może być używana do przechowywania danych bazy danych. | Ilość przydzielonego miejsca na dane nie może przekroczyć maksymalnego rozmiaru danych. |
Na poniższym diagramie przedstawiono relację między różnymi typami miejsca do magazynowania dla bazy danych.
Wykonywanie zapytań względem pojedynczej bazy danych pod kątem informacji o przestrzeni plików
Użyj następującego zapytania w sys.database_files , aby zwrócić ilość przydzielonego miejsca na plik bazy danych i ilość przydzielonego nieużywanego miejsca. Wynik zapytania jest podawany w MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Omówienie typów miejsca do magazynowania dla elastycznej puli
Zrozumienie następujących ilości miejsca do magazynowania jest ważne w przypadku zarządzania przestrzenią plików elastycznej puli.
| Wielkość elastycznej puli | Definicja | Komentarze |
|---|---|---|
| Używane miejsce danych | Suma miejsca na dane używanego przez wszystkie bazy danych w elastycznej puli. | |
| Przydzielone miejsce na dane | Suma miejsca na dane przydzielonego przez wszystkie bazy danych w elastycznej puli. | |
| Przydzielone miejsce na dane, ale nieużywane | Różnica między ilością przydzielonego miejsca na dane a miejscem na dane używanym przez wszystkie bazy danych w elastycznej puli. | Ta wielkość odzwierciedla maksymalną ilość miejsca przydzielonego dla elastycznej puli, którą można odzyskać, zmniejszając pliki danych bazy danych. |
| Maksymalny rozmiar danych | Maksymalna ilość miejsca na dane, która może być używana przez elastyczną pulę dla wszystkich baz danych. | Miejsce przydzielone dla elastycznej puli nie powinno przekraczać jej maksymalnego rozmiaru. Jeśli ten warunek wystąpi, przydzielone miejsce, które jest nieużywane, można odzyskać przez zmniejszenie plików danych bazy danych. |
Uwaga
Komunikat o błędzie "Pula elastyczna osiągnęła limit magazynu" wskazuje, że obiekty bazy danych zostały przydzielone wystarczająco dużo miejsca, aby spełnić limit magazynu elastycznej puli, ale może istnieć nieużywane miejsce w alokacji przestrzeni danych. Rozważ zwiększenie limitu magazynu elastycznej puli lub jako krótkoterminowe rozwiązanie, zwalniając miejsce na danych przy użyciu przykładów w temacie Odzyskiwanie nieużywanego przydzielonego miejsca. Należy również pamiętać o potencjalnym negatywnym wpływie wydajności na zmniejszanie plików bazy danych, zobacz Konserwacja indeksu po zmniejszeniu.
Wykonywanie zapytań dotyczących elastycznej puli pod kątem informacji o miejscu do magazynowania
Poniższe zapytania mogą służyć do ustalenia ilości miejsca do magazynowania dla elastycznej puli.
Miejsce używane przez dane elastycznej puli
Zmodyfikuj następujące zapytanie, aby zwrócić ilość używanego miejsca danych elastycznej puli. Wynik zapytania jest podawany w MB.
-- Connect to master
-- Elastic pool data space used in MB
SELECT TOP 1 avg_storage_percent / 100.0 * elastic_pool_storage_limit_mb AS ElasticPoolDataSpaceUsedInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Przydzielone miejsce na dane elastycznej puli i nieużywane przydzielone miejsce
Zmodyfikuj poniższe przykłady, aby zwrócić tabelę zawierającą przydzielone miejsce i nieużywane przydzielone miejsce dla każdej bazy danych w elastycznej puli. Tabela zamawia bazy danych z tych baz danych z największą ilością nieużywanego przydzielonego miejsca do najmniejszej ilości nieużywanego przydzielonego miejsca. Wynik zapytania jest podawany w MB.
Wyniki zapytania dotyczące określania miejsca przydzielonego dla każdej bazy danych w puli można dodać razem, aby określić łączną ilość miejsca przydzielonego dla puli elastycznej. Przydzielone miejsce elastycznej puli nie powinno przekraczać maksymalnego rozmiaru puli elastycznej.
Ważne
Moduł Azure Resource Manager programu PowerShell jest nadal obsługiwany przez usługę Azure SQL Database, ale wszystkie przyszłe programowanie dotyczy modułu Az.Sql. Moduł AzureRM będzie nadal otrzymywać poprawki błędów do co najmniej grudnia 2020 r. Argumenty poleceń w module Az i modułach AzureRm są zasadniczo identyczne. Aby uzyskać więcej informacji na temat ich zgodności, zobacz Wprowadzenie do nowego modułu Az programu Azure PowerShell.
Skrypt programu PowerShell wymaga modułu PROGRAMU SQL Server PowerShell — zobacz Pobieranie modułu programu PowerShell do zainstalowania.
$resourceGroupName = "<resourceGroupName>"
$serverName = "<serverName>"
$poolName = "<poolName>"
$userName = "<userName>"
$password = "<password>"
# get list of databases in elastic pool
$databasesInPool = Get-AzSqlElasticPoolDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName -ElasticPoolName $poolName
$databaseStorageMetrics = @()
# for each database in the elastic pool, get space allocated in MB and space allocated unused in MB
foreach ($database in $databasesInPool) {
$sqlCommand = "SELECT DB_NAME() as DatabaseName, `
SUM(size/128.0) AS DatabaseDataSpaceAllocatedInMB, `
SUM(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0) AS DatabaseDataSpaceAllocatedUnusedInMB `
FROM sys.database_files `
GROUP BY type_desc `
HAVING type_desc = 'ROWS'"
$serverFqdn = "tcp:" + $serverName + ".database.windows.net,1433"
$databaseStorageMetrics = $databaseStorageMetrics +
(Invoke-Sqlcmd -ServerInstance $serverFqdn -Database $database.DatabaseName `
-Username $userName -Password $password -Query $sqlCommand)
}
# display databases in descending order of space allocated unused
Write-Output "`n" "ElasticPoolName: $poolName"
Write-Output $databaseStorageMetrics | Sort -Property DatabaseDataSpaceAllocatedUnusedInMB -Descending | Format-Table
Poniższy zrzut ekranu to przykład danych wyjściowych skryptu:

Maksymalny rozmiar danych elastycznej puli
Zmodyfikuj następujące zapytanie T-SQL, aby zwrócić ostatni zarejestrowany rozmiar maksymalnego rozmiaru danych puli elastycznej. Wynik zapytania jest podawany w MB.
-- Connect to master
-- Elastic pools max size in MB
SELECT TOP 1 elastic_pool_storage_limit_mb AS ElasticPoolMaxSizeInMB
FROM sys.elastic_pool_resource_stats
WHERE elastic_pool_name = 'ep1'
ORDER BY end_time DESC;
Odzyskiwanie nieużywanego przydzielonego miejsca
Ważne
Polecenia zmniejszania mają wpływ na wydajność działającej bazy danych i, jeśli to możliwe, należy je uruchamiać w czasie niskiego użycia.
Zmniejszanie plików danych
Ze względu na potencjalny wpływ na wydajność bazy danych usługa Azure SQL Database nie zmniejsza automatycznie plików danych. Jednak klienci mogą zmniejszać pliki danych za pośrednictwem samoobsługi w wybranym momencie. Nie powinno to być regularnie zaplanowana operacja, ale raczej jednorazowe zdarzenie w odpowiedzi na poważne zmniejszenie zużycia miejsca w pliku danych.
Napiwek
Nie zaleca się zmniejszania plików danych, jeśli zwykłe obciążenie aplikacji spowoduje ponowny wzrost rozmiaru plików do tego samego przydzielonego rozmiaru.
W usłudze Azure SQL Database, aby zmniejszyć pliki, możesz użyć DBCC SHRINKDATABASE poleceń lub DBCC SHRINKFILE :
DBCC SHRINKDATABASEZmniejsza wszystkie pliki danych i dzienników w bazie danych przy użyciu jednego polecenia. Polecenie zmniejsza jeden plik danych jednocześnie, co może zająć dużo czasu dla większych baz danych. Zmniejsza również plik dziennika, co zwykle jest niepotrzebne, ponieważ usługa Azure SQL Database automatycznie zmniejsza pliki dziennika zgodnie z potrzebami.DBCC SHRINKFILEPolecenie obsługuje bardziej zaawansowane scenariusze:- Może być przeznaczony dla poszczególnych plików zgodnie z potrzebami, a nie zmniejszać wszystkich plików w bazie danych.
- Każde
DBCC SHRINKFILEpolecenie może działać równolegle z innymiDBCC SHRINKFILEpoleceniami, aby zmniejszyć wiele plików w tym samym czasie i zmniejszyć całkowity czas zmniejszania, kosztem wyższego użycia zasobów i większe szanse na blokowanie zapytań użytkowników, jeśli są wykonywane podczas zmniejszania.- Zmniejszanie wielu plików danych jednocześnie umożliwia szybsze wykonywanie operacji zmniejszania. Jeśli używasz współbieżnego zmniejszania pliku danych, możesz zaobserwować przejściowe blokowanie jednego żądania zmniejszania o inny.
- Jeśli ogon pliku nie zawiera danych, może znacznie szybciej zmniejszyć przydzielony rozmiar pliku, określając
TRUNCATEONLYargument. Nie wymaga to przenoszenia danych w pliku.
- Aby uzyskać więcej informacji na temat tych poleceń zmniejszania, zobacz DBCC SHRINKDATABASE i DBCC SHRINKFILE.
- Operacje zmniejszania bazy danych i plików są obsługiwane w wersji zapoznawczej dla hiperskala usługi Azure SQL Database. Aby uzyskać więcej informacji, zobacz Shrink for Azure SQL Database Hyperscale (Zmniejszanie skali usługi Azure SQL Database w warstwie Hiperskala).
Poniższe przykłady muszą być wykonywane podczas nawiązywania połączenia z docelową bazą danych użytkownika, a nie z bazą master danych.
Aby użyć DBCC SHRINKDATABASE polecenia , aby zmniejszyć wszystkie pliki danych i dzienników w danej bazie danych:
-- Shrink database data space allocated.
DBCC SHRINKDATABASE (N'database_name');
W usłudze Azure SQL Database baza danych może mieć co najmniej jeden plik danych utworzony automatycznie w miarę wzrostu danych. Aby określić układ pliku bazy danych, w tym używany i przydzielony rozmiar każdego pliku, wykonaj zapytanie dotyczące sys.database_files widoku wykazu przy użyciu następującego przykładowego skryptu:
-- Review file properties, including file_id and name values to reference in shrink commands
SELECT file_id,
name,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_file_size_mb
FROM sys.database_files
WHERE type_desc IN ('ROWS','LOG');
Możesz wykonać zmniejszanie względem jednego pliku tylko za pomocą DBCC SHRINKFILE polecenia , na przykład:
-- Shrink database data file named 'data_0` by removing all unused at the end of the file, if any.
DBCC SHRINKFILE ('data_0', TRUNCATEONLY);
GO
Należy pamiętać o potencjalnym negatywnym wpływie wydajności na zmniejszanie plików bazy danych, zobacz Konserwacja indeksu po zmniejszeniu.
Zmniejszanie pliku dziennika transakcji
W przeciwieństwie do plików danych usługa Azure SQL Database automatycznie zmniejsza plik dziennika transakcji, aby uniknąć nadmiernego użycia miejsca, które może prowadzić do błędów braku miejsca. Zazwyczaj klienci nie muszą zmniejszać pliku dziennika transakcji.
W warstwach usługi Premium i Krytyczne dla działania firmy, jeśli dziennik transakcji stanie się duży, może znacząco przyczynić się do użycia magazynu lokalnego w celu osiągnięcia maksymalnego limitu magazynu lokalnego. Jeśli użycie magazynu lokalnego zbliża się do limitu, klienci mogą zdecydować się zmniejszyć dziennik transakcji przy użyciu polecenia DBCC SHRINKFILE , jak pokazano w poniższym przykładzie. Spowoduje to wydanie magazynu lokalnego natychmiast po zakończeniu działania polecenia bez oczekiwania na okresową operację automatycznego zmniejszania.
Poniższy przykład powinien być wykonywany podczas nawiązywania połączenia z docelową bazą danych użytkownika, a nie z bazą master danych.
-- Shrink the database log file (always file_id 2), by removing all unused space at the end of the file, if any.
DBCC SHRINKFILE (2, TRUNCATEONLY);
Automatyczne zmniejszanie
Alternatywą dla ręcznego zmniejszania plików danych może być automatyczne zmniejszanie bazy danych. Jednak automatyczne zmniejszanie może być mniej skuteczne w odzyskiwaniu miejsca na plikach niż DBCC SHRINKDATABASE i DBCC SHRINKFILE.
Domyślnie automatyczne zmniejszanie jest wyłączone, co jest zalecane w przypadku większości baz danych. Jeśli konieczne jest włączenie automatycznego zmniejszania, zaleca się wyłączenie go po osiągnięciu celów zarządzania miejscem, zamiast trwale go włączać. Aby uzyskać więcej informacji, zobacz Zagadnienia dotyczące właściwości AUTO_SHRINK.
Na przykład automatyczne zmniejszanie może być przydatne w konkretnym scenariuszu, w którym elastyczna pula zawiera wiele baz danych, które mają znaczny wzrost i zmniejszenie używanego miejsca do plików danych, co powoduje, że pula zbliża się do maksymalnego limitu rozmiaru. Nie jest to typowy scenariusz.
Aby włączyć automatyczne zmniejszanie, wykonaj następujące polecenie podczas nawiązywania połączenia z bazą danych (a nie z bazą master danych).
-- Enable auto-shrink for the current database.
ALTER DATABASE CURRENT SET AUTO_SHRINK ON;
Aby uzyskać więcej informacji na temat tego polecenia, zobacz OPCJE ZESTAWU BAZY DANYCH.
Konserwacja indeksu po zmniejszeniu
Po zakończeniu operacji zmniejszania względem plików danych indeksy mogą zostać pofragmentowane. Zmniejsza to skuteczność optymalizacji wydajności dla niektórych obciążeń, takich jak zapytania korzystające z dużych skanów. Jeśli spadek wydajności wystąpi po zakończeniu operacji zmniejszania, rozważ konserwację indeksu w celu ponownego skompilowania indeksów. Należy pamiętać, że ponowne kompilowanie indeksu wymaga wolnego miejsca w bazie danych, dlatego może spowodować zwiększenie przydzielonego miejsca, przeciwdziałając efektowi zmniejszania.
Aby uzyskać więcej informacji na temat konserwacji indeksu, zobacz Optymalizowanie konserwacji indeksu w celu zwiększenia wydajności zapytań i zmniejszenia zużycia zasobów.
Zmniejszanie dużych baz danych
Gdy przydzielone miejsce w bazie danych znajduje się w setkach gigabajtów lub wyższym, zmniejszanie może wymagać znacznego czasu, często mierzonego w godzinach lub dniach dla baz danych z wieloma terabajtami. Istnieją optymalizacje procesów i najlepsze rozwiązania, których można użyć, aby ten proces był bardziej wydajny i mniej istotny dla obciążeń aplikacji.
Przechwytywanie punktu odniesienia użycia miejsca
Przed rozpoczęciem zmniejszania przechwyć bieżące używane i przydzielone miejsce w każdym pliku bazy danych, wykonując następujące zapytanie dotyczące użycia miejsca:
SELECT file_id,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS bigint) * 8 / 1024. AS space_used_mb,
CAST(size AS bigint) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS bigint) * 8 / 1024. AS max_size_mb
FROM sys.database_files
WHERE type_desc = 'ROWS';
Po zakończeniu zmniejszania można wykonać to zapytanie ponownie i porównać wynik z początkowym punktem odniesienia.
Obcinanie plików danych
Zaleca się najpierw wykonanie zmniejszania dla każdego pliku danych z parametrem TRUNCATEONLY . Dzięki temu, jeśli na końcu pliku zostanie przydzielone jakiekolwiek przydzielone, ale nieużywane miejsce, zostanie ono szybko usunięte i bez żadnego przenoszenia danych. Następujące przykładowe polecenie obcina plik danych z file_id 4:
DBCC SHRINKFILE (4, TRUNCATEONLY);
Po wykonaniu tego polecenia dla każdego pliku danych możesz ponownie uruchomić zapytanie dotyczące użycia miejsca, aby zobaczyć zmniejszenie przydzielonego miejsca, jeśli istnieje. Możesz również wyświetlić przydzielone miejsce dla bazy danych w witrynie Azure Portal.
Ocena gęstości stron indeksu
Jeśli obcięcie plików danych nie spowodowało wystarczającej redukcji przydzielonego miejsca, należy zmniejszyć pliki danych. Jednak jako opcjonalny, ale zalecany krok należy najpierw określić średnią gęstość stron dla indeksów w bazie danych. W przypadku tej samej ilości danych zmniejszanie zostanie ukończone szybciej, jeśli gęstość stron jest wysoka, ponieważ będzie musiała przenieść mniej stron. Jeśli gęstość stron jest niska dla niektórych indeksów, rozważ przeprowadzenie konserwacji tych indeksów w celu zwiększenia gęstości stron przed zmniejszeniem plików danych. Pozwoli to również zmniejszyć zmniejszenie ilości przydzielonego miejsca do magazynowania.
Aby określić gęstość stron dla wszystkich indeksów w bazie danych, użyj następującego zapytania. Gęstość strony jest zgłaszana w kolumnie avg_page_space_used_in_percent .
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Jeśli istnieją indeksy o dużej liczbie stron o gęstości mniejszej niż 60–70%, rozważ ponowne skompilowanie lub reorganizację tych indeksów przed zmniejszeniem plików danych.
Uwaga
W przypadku większych baz danych zapytanie określające gęstość stron może zająć dużo czasu (godzin). Ponadto ponowne kompilowanie lub reorganizacja dużych indeksów wymaga również znacznego czasu i użycia zasobów. Istnieje kompromis między poświęcaniem dodatkowego czasu na zwiększenie gęstości stron z jednej strony, a zmniejszenie czasu trwania zmniejszania i osiąganie wyższych oszczędności miejsca na innym.
Jeśli istnieje wiele indeksów o niskiej gęstości stron, możesz je ponownie skompilować równolegle w wielu sesjach bazy danych, aby przyspieszyć proces. Upewnij się jednak, że nie zbliżasz się do limitów zasobów bazy danych, i pozostaw wystarczającą ilość zasobów dla obciążeń aplikacji, które mogą być uruchomione. Monitorowanie użycia zasobów (procesor CPU, operacje we/wy danych, operacje we/wy dziennika) w witrynie Azure Portal lub korzystanie z widoku sys.dm_db_resource_stats oraz ponowne ponowne kompilowanie dodatkowych równoległych operacji tylko wtedy, gdy wykorzystanie zasobów w każdym z tych wymiarów pozostaje znacznie niższe niż 100%. Jeśli użycie procesora CPU, operacji we/wy danych lub operacji we/wy dziennika wynosi 100%, możesz skalować bazę danych w górę, aby mieć więcej rdzeni procesora CPU i zwiększyć przepływność operacji we/wy. Może to umożliwić szybsze ponowne kompilowanie dodatkowych równoległych operacji.
Przykładowe polecenie ponownego kompilowania indeksu
Poniżej przedstawiono przykładowe polecenie służące do ponownego kompilowania indeksu i zwiększania gęstości strony przy użyciu instrukcji ALTER INDEX :
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
To polecenie inicjuje ponowne kompilowanie indeksu w trybie online i wznawiania. Dzięki temu współbieżne obciążenia będą nadal korzystać z tabeli, gdy ponowne kompilowanie jest w toku, i umożliwia wznowienie ponownej kompilacji, jeśli zostanie przerwane z jakiegokolwiek powodu. Jednak ten typ odbudowy jest wolniejszy niż ponowne kompilowanie w trybie offline, co blokuje dostęp do tabeli. Jeśli żadne inne obciążenia nie muszą uzyskiwać dostępu do tabeli podczas ponownej kompilacji, ustaw ONLINE opcje i RESUMABLE na OFF i usuń klauzulę WAIT_AT_LOW_PRIORITY .
Aby dowiedzieć się więcej na temat konserwacji indeksu, zobacz Optymalizowanie konserwacji indeksu w celu zwiększenia wydajności zapytań i zmniejszenia zużycia zasobów.
Zmniejszanie wielu plików danych
Jak wspomniano wcześniej, zmniejszanie ruchu danych jest długotrwałym procesem. Jeśli baza danych zawiera wiele plików danych, możesz przyspieszyć proces przez równoległe zmniejszanie wielu plików danych. W tym celu należy otworzyć wiele sesji bazy danych i użyć ich DBCC SHRINKFILE w każdej sesji z inną file_id wartością. Podobnie jak w przypadku wcześniejszego ponownego kompilowania indeksów, przed rozpoczęciem każdego nowego polecenia zmniejszania równoległego upewnij się, że masz wystarczającą ilość zasobów (procesor CPU, operacje we/wy danych, operacje we/wy dziennika).
Następujące przykładowe polecenie zmniejsza plik danych z file_id 4, próbując zmniejszyć przydzielony rozmiar do 52 000 MB, przenosząc strony w pliku:
DBCC SHRINKFILE (4, 52000);
Jeśli chcesz zmniejszyć przydzielone miejsce dla pliku do minimum możliwe, wykonaj instrukcję bez określania rozmiaru docelowego:
DBCC SHRINKFILE (4);
Jeśli obciążenie jest uruchomione współbieżnie z zmniejszeniem, może zacząć używać miejsca do magazynowania zwolnionego przez zmniejszenie przed zakończeniem zmniejszania i obcięciem pliku. W takim przypadku zmniejszanie nie będzie mogło zmniejszyć przydzielonego miejsca do określonego celu.
Można temu zapobiec, zmniejszając każdy plik w mniejszych krokach. Oznacza to, że w poleceniu DBCC SHRINKFILE ustawisz element docelowy, który jest nieco mniejszy niż bieżące przydzielone miejsce dla pliku, jak pokazano w wynikach zapytania użycia obszaru bazowego. Jeśli na przykład przydzielone miejsce dla pliku z file_id 4 wynosi 200 000 MB i chcesz zmniejszyć go do 100 000 MB, możesz najpierw ustawić docelowy rozmiar 170 000 MB:
DBCC SHRINKFILE (4, 170000);
Po zakończeniu tego polecenia plik zostanie obcięty i zmniejszy rozmiar przydzielony do 170 000 MB. Następnie można powtórzyć to polecenie, ustawiając element docelowy najpierw na 140 000 MB, a następnie do 110 000 MB itd., aż plik zostanie przesunięty do żądanego rozmiaru. Jeśli polecenie zostanie ukończone, ale plik nie zostanie obcięty, wykonaj mniejsze kroki, na przykład 15 000 MB, a nie 30 000 MB.
Aby monitorować postęp zmniejszania dla wszystkich współbieżnie uruchomionych sesji zmniejszania, można użyć następującego zapytania:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Uwaga
Postęp zmniejszania może być nieliniowy, a wartość w percent_complete kolumnie może pozostać praktycznie niezmieniona przez długi czas, mimo że zmniejszanie jest nadal w toku.
Po zakończeniu zmniejszania dla wszystkich plików danych ponownie uruchom zapytanie dotyczące użycia miejsca (lub zaewidencjonuj w witrynie Azure Portal), aby określić wynikową redukcję przydzielonego rozmiaru magazynu. Jeśli nadal istnieje duża różnica między używanym miejscem a przydzielonym miejscem, można ponownie skompilować indeksy zgodnie z wcześniejszym opisem. Może to spowodować dalsze zwiększenie przydzielonego miejsca, jednak ponowne zmniejszanie plików danych po ponownym skompilowaniu indeksów powinno spowodować głębsze zmniejszenie przydzielonego miejsca.
Błędy przejściowe podczas zmniejszania
Czasami polecenie zmniejszania może zakończyć się niepowodzeniem z różnymi błędami, takimi jak przekroczenia limitu czasu i zakleszczenia. Ogólnie rzecz biorąc, te błędy są przejściowe i nie występują ponownie, jeśli to samo polecenie jest powtarzane. Jeśli zmniejszanie zakończy się niepowodzeniem z powodu błędu, postęp, jaki poczynił do tej pory podczas przenoszenia stron danych, zostanie zachowane, a to samo polecenie zmniejszania można wykonać ponownie, aby kontynuować zmniejszanie pliku.
Poniższy przykładowy skrypt pokazuje, jak można uruchomić zmniejszanie pętli ponawiania prób, aby automatycznie ponowić próbę do konfigurowalnej liczby razy, gdy wystąpi błąd przekroczenia limitu czasu lub błąd zakleszczenia. To podejście ponawiania ma zastosowanie do wielu innych błędów, które mogą wystąpić podczas zmniejszania.
DECLARE @RetryCount int = 3; -- adjust to configure desired number of retries
DECLARE @Delay char(12);
-- Retry loop
WHILE @RetryCount >= 0
BEGIN
BEGIN TRY
DBCC SHRINKFILE (1); -- adjust file_id and other shrink parameters
-- Exit retry loop on successful execution
SELECT @RetryCount = -1;
END TRY
BEGIN CATCH
-- Retry for the declared number of times without raising an error if deadlocked or timed out waiting for a lock
IF ERROR_NUMBER() IN (1205, 49516) AND @RetryCount > 0
BEGIN
SELECT @RetryCount -= 1;
PRINT CONCAT('Retry at ', SYSUTCDATETIME());
-- Wait for a random period of time between 1 and 10 seconds before retrying
SELECT @Delay = '00:00:0' + CAST(CAST(1 + RAND() * 8.999 AS decimal(5,3)) AS varchar(5));
WAITFOR DELAY @Delay;
END
ELSE -- Raise error and exit loop
BEGIN
SELECT @RetryCount = -1;
THROW;
END
END CATCH
END;
Oprócz przekroczenia limitu czasu i zakleszczenia zmniejszanie może napotkać błędy z powodu niektórych znanych problemów.
Zwrócone błędy i kroki ograniczania ryzyka są następujące:
- Numer błędu: 49503, komunikat o błędzie: %.*ls: Nie można przenieść strony %d:%d, ponieważ jest to strona magazynu wersji trwałej poza wierszem. Przyczyna blokady strony: %ls. Sygnatura czasowa blokady strony: %I64d.
Ten błąd występuje, gdy istnieją długotrwałe aktywne transakcje, które wygenerowały wersje wierszy w trwałym magazynie wersji (PVS). Nie można przenosić stron zawierających te wersje wierszy za pomocą zmniejszania, dlatego nie może on poczynić postępów i kończy się niepowodzeniem z powodu tego błędu.
Aby rozwiązać ten problem, musisz poczekać na ukończenie tych długotrwałych transakcji. Alternatywnie można zidentyfikować i zakończyć te długotrwałe transakcje, ale może to mieć wpływ na aplikację, jeśli nie obsługuje ona bezproblemowo błędów transakcji. Jednym ze sposobów znalezienia długotrwałych transakcji jest uruchomienie następującego zapytania w bazie danych, w której uruchomiono polecenie zmniejszania:
-- Transactions sorted by duration
SELECT st.session_id,
dt.database_transaction_begin_time,
DATEDIFF(second, dt.database_transaction_begin_time, CURRENT_TIMESTAMP) AS transaction_duration_seconds,
dt.database_transaction_log_bytes_used,
dt.database_transaction_log_bytes_reserved,
st.is_user_transaction,
st.open_transaction_count,
ib.event_type,
ib.parameters,
ib.event_info
FROM sys.dm_tran_database_transactions AS dt
INNER JOIN sys.dm_tran_session_transactions AS st
ON dt.transaction_id = st.transaction_id
OUTER APPLY sys.dm_exec_input_buffer(st.session_id, default) AS ib
WHERE dt.database_id = DB_ID()
ORDER BY transaction_duration_seconds DESC;
Transakcję można zakończyć przy użyciu KILL polecenia i określić skojarzona session_id wartość z wyniku zapytania:
KILL 4242; -- replace 4242 with the session_id value from query results
Uwaga
Zakończenie transakcji może negatywnie wpłynąć na obciążenia.
Po zakończeniu długotrwałych transakcji lub zakończeniu zadania wewnętrznego w tle nie będą już potrzebne wersje wierszy po pewnym czasie. Rozmiar pvS można monitorować, aby ocenić postęp oczyszczania, korzystając z następującego zapytania. Uruchom zapytanie w bazie danych, w której uruchomiono polecenie shrink:
SELECT pvss.persistent_version_store_size_kb / 1024. / 1024 AS persistent_version_store_size_gb,
pvss.online_index_version_store_size_kb / 1024. / 1024 AS online_index_version_store_size_gb,
pvss.current_aborted_transaction_count,
pvss.aborted_version_cleaner_start_time,
pvss.aborted_version_cleaner_end_time,
dt.database_transaction_begin_time AS oldest_transaction_begin_time,
asdt.session_id AS active_transaction_session_id,
asdt.elapsed_time_seconds AS active_transaction_elapsed_time_seconds
FROM sys.dm_tran_persistent_version_store_stats AS pvss
LEFT JOIN sys.dm_tran_database_transactions AS dt
ON pvss.oldest_active_transaction_id = dt.transaction_id
AND
pvss.database_id = dt.database_id
LEFT JOIN sys.dm_tran_active_snapshot_database_transactions AS asdt
ON pvss.min_transaction_timestamp = asdt.transaction_sequence_num
OR
pvss.online_index_min_transaction_timestamp = asdt.transaction_sequence_num
WHERE pvss.database_id = DB_ID();
Gdy rozmiar pvS zgłoszony w kolumnie jest znacznie zmniejszony w persistent_version_store_size_gb porównaniu z oryginalnym rozmiarem, ponowne ponowne zmniejszanie powinno zakończyć się powodzeniem.
- Numer błędu: 5223, komunikat o błędzie: %.*ls: Nie można cofnąć przydziału pustej strony %d:%d.
Ten błąd może wystąpić, jeśli istnieją trwające operacje konserwacji indeksu, takie jak ALTER INDEX. Spróbuj ponownie wykonać polecenie zmniejszania po zakończeniu tych operacji.
Jeśli ten błąd będzie się powtarzać, może być konieczne ponowne skompilowanie skojarzonego indeksu. Aby znaleźć indeks do ponownego skompilowania, wykonaj następujące zapytanie w tej samej bazie danych, w której uruchomiono polecenie zmniejszania:
SELECT OBJECT_SCHEMA_NAME(pg.object_id) AS schema_name,
OBJECT_NAME(pg.object_id) AS object_name,
i.name AS index_name,
p.partition_number
FROM sys.dm_db_page_info(DB_ID(), <file_id>, <page_id>, default) AS pg
INNER JOIN sys.indexes AS i
ON pg.object_id = i.object_id
AND
pg.index_id = i.index_id
INNER JOIN sys.partitions AS p
ON pg.partition_id = p.partition_id;
Przed wykonaniem tego zapytania zastąp <file_id> symbole zastępcze i <page_id> rzeczywistymi wartościami odebranego komunikatu o błędzie. Jeśli na przykład komunikat ma wartość Pusta strona 1:62669, nie można cofnąć przydziału, <file_id> to jest i 1 <page_id> ma wartość 62669.
Ponownie skompiluj indeks zidentyfikowany przez zapytanie i spróbuj ponownie wykonać polecenie shrink.
- Numer błędu: 5201, komunikat o błędzie: DBCC SHRINKDATABASE: identyfikator pliku %d identyfikatora bazy danych %d został pominięty, ponieważ plik nie ma wystarczającej ilości wolnego miejsca do odzyskania.
Ten błąd oznacza, że nie można jeszcze bardziej skurczyć pliku danych. Możesz przejść do następnego pliku danych.
Powiązana zawartość
Aby uzyskać informacje o maksymalnych rozmiarach bazy danych, zobacz:
- Limity modelu zakupów opartego na rdzeniach wirtualnych usługi Azure SQL Database dla pojedynczej bazy danych
- Limity zasobów dla pojedynczych baz danych w przypadku modelu zakupów opartego na jednostkach DTU
- Limity modelu zakupów opartego na rdzeniach wirtualnych usługi Azure SQL Database dla elastycznych pul
- Limity zasobów dla pul elastycznych przy użyciu modelu zakupów opartego na jednostkach DTU