Przyspieszanie analizy danych big data w czasie rzeczywistym przy użyciu łącznika platformy Spark
Dotyczy:![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Uwaga
Od września 2020 r. ten łącznik nie jest aktywnie obsługiwany. Jednak usługa Apache Spark Połączenie or dla programu SQL Server i usługi Azure SQL jest teraz dostępna z obsługą powiązań języka Python i języka R, łatwiejszego w użyciu interfejsu do zbiorczego wstawiania danych i wielu innych ulepszeń. Zdecydowanie zachęcamy do oceny i używania nowego łącznika zamiast tego. Informacje o starym łączniku (tej stronie) są przechowywane tylko do celów archiwalnych.
Łącznik Spark umożliwia bazom danych w usłudze Azure SQL Database, usłudze Azure SQL Managed Instance i programie SQL Server działanie jako wejściowe źródło danych lub ujście danych wyjściowych dla zadań platformy Spark. Umożliwia ona korzystanie z danych transakcyjnych w czasie rzeczywistym w analizie danych big data i utrwalanie wyników na potrzeby zapytań ad hoc lub raportowania. W porównaniu z wbudowanym łącznikiem JDBC ten łącznik zapewnia możliwość zbiorczego wstawiania danych do bazy danych. Może ona przewyższać wstawiania wiersz po wierszu z 10x do 20x szybciej. Łącznik Spark obsługuje uwierzytelnianie za pomocą identyfikatora Entra firmy Microsoft (dawniej Azure Active Directory) w celu nawiązania połączenia z usługami Azure SQL Database i Azure SQL Managed Instance, co umożliwia łączenie bazy danych z usługi Azure Databricks przy użyciu konta microsoft Entra. Zapewnia on podobne interfejsy z wbudowanym łącznikiem JDBC. Migracja istniejących zadań platformy Spark jest łatwa do korzystania z tego nowego łącznika.
Uwaga
Microsoft Entra ID był wcześniej znany jako Azure Active Directory (Azure AD).
Pobieranie i tworzenie łącznika platformy Spark
Repozytorium GitHub dla starego łącznika wcześniej połączonego z tą stroną nie jest aktywnie obsługiwane. Zamiast tego zdecydowanie zachęcamy do oceny i używania nowego łącznika.
Oficjalne obsługiwane wersje
| Składnik | Wersja |
|---|---|
| Apache Spark | 2.0.2 lub nowsza |
| Scala | 2.10 lub nowszy |
| Sterownik JDBC firmy Microsoft dla programu SQL Server | 6.2 lub nowsza wersja |
| Microsoft SQL Server | SQL Server 2008 lub nowszy |
| Azure SQL Database | Obsługiwane |
| Wystąpienie zarządzane Azure SQL | Obsługiwane |
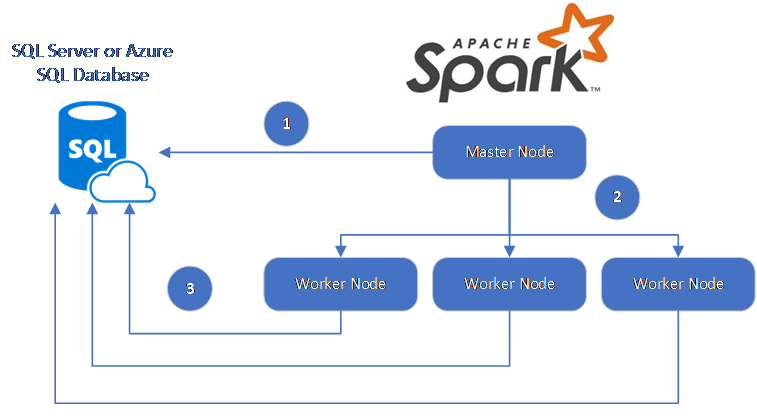
Łącznik Spark wykorzystuje sterownik JDBC firmy Microsoft dla programu SQL Server do przenoszenia danych między węzłami procesu roboczego platformy Spark i bazami danych:
Przepływ danych jest następujący:
- Węzeł główny platformy Spark łączy się z bazami danych w usłudze SQL Database lub programie SQL Server i ładuje dane z określonej tabeli lub przy użyciu określonego zapytania SQL.
- Węzeł główny platformy Spark dystrybuuje dane do węzłów roboczych w celu przekształcenia.
- Węzeł Proces roboczy łączy się z bazami danych, które łączą się z usługą SQL Database i programem SQL Server, i zapisuje dane w bazie danych. Użytkownik może wybrać użycie wstawiania wiersz po wierszu lub wstawiania zbiorczego.
Na poniższym diagramie przedstawiono przepływ danych.
Tworzenie łącznika platformy Spark
Obecnie projekt łącznika używa narzędzia maven. Aby skompilować łącznik bez zależności, możesz uruchomić następujące polecenie:
- pakiet clean mvn
- Pobierz najnowsze wersje pliku JAR z folderu wydania
- Uwzględnij plik JAR spark usługi SQL Database
Połączenie i odczytywanie danych przy użyciu łącznika Spark
Możesz nawiązać połączenie z bazami danych w usłudze SQL Database i programie SQL Server z zadania platformy Spark, aby odczytywać lub zapisywać dane. Można również uruchomić zapytanie DML lub DDL w bazach danych w usługach SQL Database i SQL Server.
Odczytywanie danych z usług Azure SQL i SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Odczytywanie danych z usług Azure SQL i SQL Server przy użyciu określonego zapytania SQL
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Zapisywanie danych w usługach Azure SQL i SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Uruchamianie zapytań DML lub DDL w usługach Azure SQL i SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Połączenie z platformy Spark przy użyciu uwierzytelniania firmy Microsoft Entra
Połączenie z usługą SQL Database i wystąpieniem zarządzanym SQL można nawiązać przy użyciu uwierzytelniania firmy Microsoft Entra. Użyj uwierzytelniania Entra firmy Microsoft, aby centralnie zarządzać tożsamościami użytkowników bazy danych i jako alternatywą dla uwierzytelniania SQL.
Połączenie przy użyciu trybu uwierzytelniania ActiveDirectoryPassword
Wymaganie dotyczące konfiguracji
Jeśli używasz trybu uwierzytelniania ActiveDirectoryPassword, musisz pobrać bibliotekę microsoft-authentication-library-for-java i jej zależności oraz dołączyć je do ścieżki kompilacji języka Java.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Połączenie przy użyciu tokenu dostępu
Wymaganie dotyczące konfiguracji
Jeśli używasz trybu uwierzytelniania opartego na tokenach dostępu, musisz pobrać bibliotekę microsoft-authentication-library-for-java i jej zależności oraz dołączyć je do ścieżki kompilacji języka Java.
Zobacz Używanie uwierzytelniania entra firmy Microsoft, aby dowiedzieć się, jak uzyskać token dostępu do bazy danych w usłudze Azure SQL Database lub usłudze Azure SQL Managed Instance.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Zapis danych przy użyciu operacji wstawiania zbiorczego
Tradycyjny łącznik jdbc zapisuje dane w bazie danych przy użyciu wstawiania wiersz po wierszu. Łącznik Spark umożliwia zapisywanie danych w usługach Azure SQL i SQL Server przy użyciu operacji wstawiania zbiorczego. Znacznie poprawia wydajność zapisu podczas ładowania dużych zestawów danych lub ładowania danych do tabel, w których jest używany indeks magazynu kolumn.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Następne kroki
Jeśli jeszcze tego nie zrobiono, pobierz łącznik Spark z repozytorium azure-sqldb-spark GitHub i zapoznaj się z dodatkowymi zasobami w repozytorium:
Warto również zapoznać się z dokumentacją apache Spark SQL, DataFrames i Datasets Guide (Przewodnik po usłudze Apache Spark SQL, dataframes i zestawach danych) oraz dokumentację usługi Azure Databricks.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla