Omówienie zagadnień dotyczących ciągłości działalności biznesowej zapewnianej przez usługę Azure SQL Managed Instance
Dotyczy: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Ten artykuł zawiera omówienie możliwości ciągłości działania i odzyskiwania po awarii usługi Azure SQL Managed Instance, opisujących opcje i zalecenia dotyczące odzyskiwania po zdarzeniach powodujących zakłócenia, które mogą prowadzić do utraty danych lub spowodowania niedostępności wystąpienia i aplikacji. Dowiedz się, co zrobić, gdy błąd użytkownika lub aplikacji wpływa na integralność danych, strefę dostępności platformy Azure lub region ma awarię lub aplikacja wymaga konserwacji.
Omówienie
Ciągłość działalności biznesowej w usłudze Azure SQL Managed Instance odnosi się do mechanizmów, zasad i procedur, które umożliwiają firmie kontynuowanie działania w obliczu zakłóceń, zapewniając dostępność, wysoką dostępność i odzyskiwanie po awarii.
W większości przypadków usługa SQL Managed Instance obsługuje zdarzenia powodujące zakłócenia, które mogą wystąpić w środowisku chmury i utrzymuje uruchomione aplikacje i procesy biznesowe. Istnieją jednak pewne zakłócenia, w których środki zaradcze mogą zająć trochę czasu, takie jak:
- Użytkownik przypadkowo usuwa lub aktualizuje wiersz w tabeli.
- Złośliwy atakujący pomyślnie usuwa dane lub usuwa bazę danych.
- Katastrofalne zdarzenie klęski żywiołowej wyłącza centrum danych lub strefę dostępności lub region.
- Rzadkie awarie centrum danych, strefy dostępności lub całego regionu spowodowane przez zmianę konfiguracji, usterkę oprogramowania lub awarię składnika sprzętowego.
Dostępność
Usługa Azure SQL Managed Instance zapewnia podstawową odporność i niezawodność, która chroni ją przed awariami oprogramowania lub sprzętu. Kopie zapasowe bazy danych są zautomatyzowane w celu ochrony danych przed uszkodzeniem lub przypadkowym usunięciem. Jako usługa typu "platforma jako usługa" (PaaS) usługa Azure SQL Managed Instance zapewnia dostępność jako gotowej funkcji z wiodącą w branży umową SLA dostępności wynoszącą 99,99%.
Wysoka dostępność
Aby zapewnić wysoką dostępność w środowisku chmury platformy Azure, włącz nadmiarowość strefy, aby wystąpienie używało stref dostępności w celu zapewnienia odporności na awarie strefowe. Wiele regionów platformy Azure zapewnia strefy dostępności, które są oddzielnymi grupami centrów danych w regionie, w którym znajdują się niezależne zasilanie, chłodzenie i infrastruktura sieciowa. Strefy dostępności są przeznaczone do świadczenia usług regionalnych, pojemności i wysokiej dostępności w pozostałych strefach, jeśli jedna strefa wystąpi awaria. Dzięki włączeniu nadmiarowości strefy wystąpienie jest odporne na awarie sprzętu i oprogramowania strefowego, a odzyskiwanie jest niewidoczne dla aplikacji. Po włączeniu wysokiej dostępności usługa Azure SQL Managed Instance może zapewnić umowę SLA o wyższej dostępności wynoszącą 99,99%.
Odzyskiwanie po awarii
Aby uzyskać większą dostępność i nadmiarowość w różnych regionach, możesz włączyć możliwości odzyskiwania po awarii, aby szybko odzyskać wystąpienie po katastrofalnym awarii regionalnej. Opcje odzyskiwania po awarii za pomocą usługi Azure SQL Managed Instance to:
- Grupy trybu failover umożliwiają ciągłą synchronizację między wystąpieniem podstawowym i pomocniczym. Grupy trybu failover udostępniają punkty końcowe odbiornika tylko do odczytu i zapisu, które pozostają niezmienione, dlatego aktualizowanie parametry połączenia aplikacji po przejściu w tryb failover nie jest konieczne.
- Przywracanie geograficzne umożliwia odzyskiwanie po awarii regionalnej przez przywrócenie z replikacji geograficznej kopii zapasowych, gdy nie można uzyskać dostępu do bazy danych w regionie podstawowym, tworząc nową bazę danych w dowolnym istniejącym wystąpieniu w dowolnym regionie świadczenia usługi Azure.
Funkcje zapewniające ciągłość działalności biznesowej
Na przykład istnieją cztery główne potencjalne scenariusze zakłóceń. W poniższej tabeli wymieniono funkcje ciągłości działania usługi SQL Managed Instance, których można użyć w celu ograniczenia potencjalnego scenariusza zakłóceń w działalności biznesowej:
| Scenariusz zakłóceń biznesowych | Funkcja ciągłości działania |
|---|---|
| Lokalne awarie sprzętu lub oprogramowania wpływające na węzeł bazy danych. | Aby wyeliminować lokalne awarie sprzętu i oprogramowania, usługa SQL Managed Instance obejmuje architekturę dostępności, która gwarantuje automatyczne odzyskiwanie po tych awariach z umową SLA gwarantującą maksymalnie 99,99% dostępności. |
| Uszkodzenie lub usunięcie danych zwykle spowodowane przez usterkę aplikacji lub błąd ludzki. Takie błędy są specyficzne dla aplikacji i zazwyczaj nie można ich wykryć przez usługę. | Aby chronić firmę przed utratą danych, usługa SQL Managed Instance automatycznie tworzy pełne kopie zapasowe bazy danych co tydzień, różnicowe kopie zapasowe baz danych co 12 lub 24 godziny, a kopie zapasowe dziennika transakcji co 5 – 10 minut. Domyślnie kopie zapasowe są przechowywane w magazynie geograficznie nadmiarowym przez siedem dni i obsługują konfigurowalny okres przechowywania kopii zapasowych dla przywracania do punktu w czasie do 35 dni. Możesz przywrócić usuniętą bazę danych do punktu, w którym została usunięta, jeśli wystąpienie nie zostało usunięte, lub jeśli skonfigurowano długoterminowe przechowywanie. |
| Rzadkie awarie centrum danych lub strefy dostępności, prawdopodobnie spowodowane przez zdarzenie klęski żywiołowej, zmianę konfiguracji, usterkę oprogramowania lub awarię składnika sprzętowego. | Aby ograniczyć awarię na poziomie centrum danych lub strefy dostępności, włącz nadmiarowość stref dla usługi SQL Managed Instance, aby korzystać z usługi Azure Strefy dostępności i zapewnić nadmiarowość w wielu strefach fizycznych w regionie świadczenia usługi Azure. Włączenie nadmiarowości strefy zapewnia odporność wystąpienia zarządzanego na awarie strefowe z umową SLA o wysokiej dostępności do 99,99%. |
| Rzadka awaria regionu wpływa na wszystkie strefy dostępności i składające się z niego centra danych, prawdopodobnie spowodowane katastrofalnym zdarzeniem klęski żywiołowej. | Aby wyeliminować awarię całego regionu, włącz odzyskiwanie po awarii przy użyciu jednej z opcji: — Ciągła synchronizacja danych z grupami trybu failover do replik w regionie pomocniczym używanym do pracy w trybie failover. — Ustawianie nadmiarowości magazynu kopii zapasowych na geograficznie nadmiarowy magazyn kopii zapasowych w celu korzystania z przywracania geograficznego. |
Cel czasu odzyskiwania i cel punktu odzyskiwania
Podczas opracowywania planu ciągłości działania należy zrozumieć maksymalny dopuszczalny czas przed pełnym odzyskaniem aplikacji po wystąpieniu zdarzenia powodującego zakłócenia. Czas wymagany do pełnego odzyskania aplikacji jest znany jako cel czasu odzyskiwania (RTO). Zapoznaj się również z maksymalnym okresem ostatnich aktualizacji danych (interwał czasu), który aplikacja może tolerować utratę podczas odzyskiwania po nieplanowanym zdarzeniu zakłócającym działanie. Potencjalna utrata danych jest znana jako cel punktu odzyskiwania (RPO).
W poniższej tabeli porównaliśmy cel punktu odzyskiwania i cel czasu odzyskiwania dla każdej opcji ciągłości działania:
Listy kontrolne ciągłości działalności biznesowej
Aby zapoznać się z zaleceniami wstępnymi w celu zmaksymalizowania dostępności i osiągnięcia wyższej ciągłości działania, zapoznaj się z tematem:
- Lista kontrolna dotycząca dostępności
- Lista kontrolna wysokiej dostępności
- Lista kontrolna odzyskiwania po awarii
Odzyskiwanie bazy danych w tym samym regionie świadczenia usługi Azure
Automatyczne kopie zapasowe bazy danych umożliwiają przywrócenie bazy danych do punktu w czasie w przeszłości. Dzięki temu można odzyskać dane po uszkodzeniach danych spowodowanych błędami ludzkimi. Przywracanie do punktu w czasie (PITR) umożliwia utworzenie nowej bazy danych w tym samym wystąpieniu lub innym wystąpieniu, które reprezentuje stan danych przed uszkodzeniem zdarzenia. Operacja przywracania jest rozmiarem operacji danych, która również zależy od bieżącego obciążenia wystąpienia docelowego. Odzyskiwanie bardzo dużej lub bardzo aktywnej bazy danych może potrwać dłużej. Aby uzyskać więcej informacji na temat czasu odzyskiwania, zobacz czas odzyskiwania bazy danych.
Jeśli maksymalny obsługiwany okres przechowywania kopii zapasowych dla przywracania do punktu w czasie (PITR) nie jest wystarczający dla aplikacji, możesz ją rozszerzyć, konfigurując zasady przechowywania długoterminowego (LTR) dla baz danych. Aby uzyskać więcej informacji, zobacz Długoterminowe przechowywanie kopii zapasowych.
Odzyskiwanie bazy danych do istniejącego wystąpienia
Mimo że rzadko centrum danych platformy Azure może mieć awarię. Taka awaria powoduje zakłócenia działania firmy, które mogą trwać tylko kilka minut, ale mogą też trwać wiele godzin.
- Jedną z opcji jest oczekiwanie na powrót wystąpienia do trybu online, gdy awaria centrum danych się skończyła. Działa to w przypadku aplikacji, które mogą pozwolić sobie na ich bazę danych w trybie offline. Może to na przykład dotyczyć projektu tworzenia oprogramowania lub bezpłatnej wersji próbnej, nad którymi nie trzeba pracować na bieżąco. Jeśli centrum danych ma awarię, nie wiesz, jak długo może trwać awaria, więc ta opcja działa tylko wtedy, gdy nie potrzebujesz bazy danych przez jakiś czas.
- Jeśli używasz magazynu geograficznie nadmiarowego (GRS) lub magazynu geograficznie nadmiarowego (GZRS), inną opcją jest przywrócenie bazy danych do dowolnego wystąpienia zarządzanego SQL w dowolnym regionie platformy Azure przy użyciu geograficznie nadmiarowych kopii zapasowych bazy danych (przywracanie geograficzne). Przywracanie geograficzne używa geograficznie nadmiarowej kopii zapasowej jako źródła i może służyć do odzyskania bazy danych do ostatniego dostępnego punktu w czasie, nawet jeśli baza danych lub centrum danych jest niedostępna z powodu awarii. Dostępną kopię zapasową można znaleźć w sparowanym regionie.
- Na koniec możesz szybko odzyskać sprawę po awarii, jeśli skonfigurowano pomocniczą lokalizację geograficzną przy użyciu grupy trybu failover dla danego wystąpienia przy użyciu klienta (zalecanego) lub trybu failover zarządzanego przez firmę Microsoft. Mimo że przejście w tryb failover trwa tylko kilka sekund, w przypadku skonfigurowania usługi aktywacja geograficznego trybu failover zarządzanego przez firmę Microsoft trwa co najmniej 1 godzinę. Jest to konieczne, aby zapewnić, że przejście w tryb failover jest uzasadnione skalą awarii. Ponadto przejście w tryb failover może spowodować utratę ostatnio zmienionych danych ze względu na charakter replikacji asynchronicznej między sparowanymi regionami.
Podczas opracowywania planu zapewniania ciągłości działalności biznesowej należy zrozumieć znaczenie maksymalnego dopuszczalnego czasu oczekiwania na pełne odzyskanie aplikacji po wystąpieniu zdarzenia powodującego zakłócenia. Czas wymagany przez aplikację do pełnego odzyskania jest znany jako cel czasu odzyskiwania (RTO). Należy również zrozumieć maksymalny okres ostatnich aktualizacji danych (interwał czasu), który aplikacja może tolerować utratę podczas odzyskiwania po nieplanowanym zdarzeniu zakłócającym działanie. Potencjalna utrata danych jest znana jako cel punktu odzyskiwania (RPO).
Różne metody odzyskiwania oferują różne poziomy celu punktu odzyskiwania i celu odzyskiwania. Możesz wybrać określoną metodę odzyskiwania lub użyć kombinacji metod w celu uzyskania pełnego odzyskiwania aplikacji.
Użyj grup trybu failover, jeśli aplikacja spełnia dowolne z następujących kryteriów:
- Ma kluczowe znaczenie.
- Ma umowę dotyczącą poziomu usług (SLA), która nie zezwala na 12 godzin lub więcej przestojów.
- Przestój może spowodować odpowiedzialność finansową.
- Ma wysoką szybkość zmian danych i 1 godzina utraty danych nie jest akceptowalna.
- Dodatkowy koszt związany z aktywną replikacją geograficzną jest niższy niż potencjalna odpowiedzialność finansowa i powiązane straty biznesowe.
W zależności od wymagań aplikacji możesz użyć kombinacji kopii zapasowych bazy danych i grup trybu failover.
Poniższe sekcje zawierają omówienie kroków odzyskiwania przy użyciu kopii zapasowych bazy danych lub grup trybu failover.
Przygotowanie do awarii
Niezależnie od używanej funkcji zapewniania ciągłości działalności biznesowej należy:
- Zidentyfikuj i przygotuj wystąpienie docelowe, w tym reguły zapory adresów IP sieci, identyfikatory logowania i
masteruprawnienia na poziomie bazy danych. - Określanie sposobu przekierowywania klientów i aplikacji klienckich do nowego wystąpienia
- Udokumentować inne zależności, takie jak ustawienia inspekcji i alerty
Jeśli nie przygotujesz się prawidłowo, przełączenie aplikacji do trybu online po przejściu w tryb failover lub odzyskanie bazy danych zajmuje dodatkowy czas, a prawdopodobnie wymaga również rozwiązywania problemów w czasie stresu — złej kombinacji.
Przechodzenie w tryb failover do wystąpienia pomocniczego replikowanego geograficznie
Jeśli używasz grup trybu failover jako mechanizmu odzyskiwania, możesz skonfigurować zasady automatycznego trybu failover. Po zainicjowaniu tryb failover powoduje, że wystąpienie pomocnicze stanie się nowym podstawowym, gotowym do rejestrowania nowych transakcji i reagowania na zapytania — przy minimalnej utracie danych dla danych, które nie zostały jeszcze zreplikowane.
Uwaga
Gdy centrum danych wróci do trybu online, stare podstawowe automatycznie ponownie połączy się z nowym podstawowym, aby stać się wystąpieniem pomocniczym. Jeśli musisz przenieść podstawowy z powrotem do oryginalnego regionu, możesz zainicjować planowane przejście w tryb failover ręcznie (powrót po awarii).
Przeprowadzanie przywracania geograficznego
Jeśli używasz automatycznych kopii zapasowych z magazynem geograficznie nadmiarowym (domyślną opcją magazynu podczas tworzenia wystąpienia), możesz odzyskać bazę danych przy użyciu przywracania geograficznego. Odzyskiwanie odbywa się zwykle w ciągu 12 godzin — przy utracie danych do jednej godziny określonej przez czas utworzenia i zreplikowania ostatniej kopii zapasowej dziennika. Do momentu ukończenia odzyskiwania baza danych nie może rejestrować żadnych transakcji ani odpowiadać na żadne zapytania. Pamiętaj, że przywracanie geograficzne przywraca tylko bazę danych do ostatniego dostępnego punktu w czasie.
Uwaga
Jeśli centrum danych wróci do trybu online przed przełączeniem aplikacji do odzyskanej bazy danych, możesz anulować odzyskiwanie.
Wykonywanie zadań po przejściu do trybu failover lub po odzyskiwaniu
Po odzyskaniu za pomocą dowolnego mechanizmu odzyskiwania należy wykonać następujące zadania dodatkowe, zanim będzie możliwe ponowne rozpoczęcie pracy przez użytkowników i aplikacje:
- Przekieruj klientów i aplikacje klienckie do nowego wystąpienia i przywróconej bazy danych.
- Upewnij się, że istnieją odpowiednie reguły zapory adresów IP sieci, aby umożliwić użytkownikom nawiązywanie połączenia.
- Upewnij się, że obowiązują odpowiednie identyfikatory logowania i
masteruprawnienia na poziomie bazy danych (lub użyj zawartych użytkowników). - W razie potrzeby skonfiguruj inspekcję.
- W razie potrzeby skonfiguruj alerty.
Uwaga
Jeśli używasz grupy trybu failover i łączysz się z wystąpieniem przy użyciu odbiornika odczytu i zapisu, przekierowanie po przejściu w tryb failover nastąpi automatycznie i w sposób niewidoczny dla aplikacji.
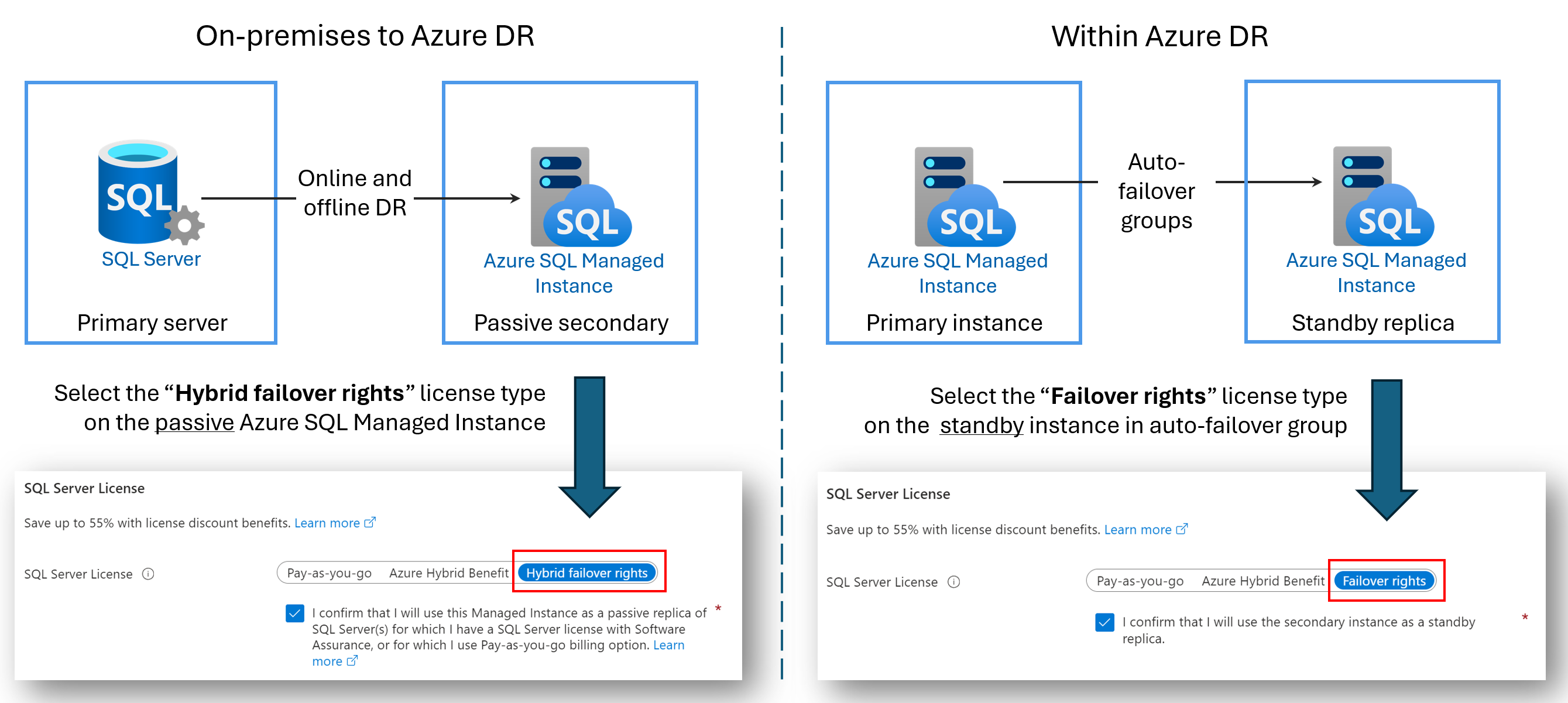
Repliki odzyskiwania po awarii bez licencji
Możesz zaoszczędzić na kosztach licencjonowania, konfigurując pomocniczą usługę Azure SQL Managed Instance tylko na potrzeby odzyskiwania po awarii. Ta korzyść jest dostępna, jeśli używasz grupy trybu failover między dwoma wystąpieniami zarządzanymi SQL lub skonfigurowano połączenie hybrydowe między programem SQL Server i usługą Azure SQL Managed Instance. Jeśli wystąpienie pomocnicze nie ma na nim żadnych obciążeń odczytu lub zapisu i jest tylko pasywnym wstrzymaniem odzyskiwania po awarii, nie są naliczane opłaty za koszty licencjonowania rdzeni wirtualnych używane przez wystąpienie pomocnicze.
Po wyznaczeniu wystąpienia pomocniczego tylko do odzyskiwania po awarii, a w wystąpieniu nie są uruchomione żadne obciążenia odczytu lub zapisu, firma Microsoft udostępnia liczbę rdzeni wirtualnych, które są licencjonowane na wystąpienie podstawowe bez dodatkowych opłat w ramach korzyści z praw do trybu failover. Nadal są naliczane opłaty za zasoby obliczeniowe i magazyn używane przez wystąpienie pomocnicze. Aby uzyskać dokładne warunki i postanowienia dotyczące korzyści z praw hybrydowego trybu failover, zobacz postanowienia licencyjne dotyczące programu SQL Server w trybie online w sekcji "SQL Server — prawa do trybu failover".
Nazwa korzyści zależy od twojego scenariusza:
- Hybrydowe prawa trybu failover dla repliki pasywnej: podczas konfigurowania połączenia między programem SQL Server i usługą Azure SQL Managed Instance możesz użyć korzyści z hybrydowych praw trybu failover, aby zaoszczędzić na kosztach licencjonowania rdzeni wirtualnych dla pasywnej repliki pomocniczej.
- Prawa trybu failover dla repliki rezerwowej: podczas konfigurowania grupy trybu failover między dwoma wystąpieniami zarządzanymi można użyć korzyści z praw trybu failover, aby zaoszczędzić na kosztach licencjonowania rdzeni wirtualnych dla repliki pomocniczej rezerwowej.
Na poniższym diagramie przedstawiono korzyść dla każdego scenariusza:
Następne kroki
Aby dowiedzieć się więcej na temat funkcji ciągłości działania, zobacz Automatyczne kopie zapasowe i grupy trybu failover. Aby uzyskać informacje na temat odzyskiwania po awarii, zobacz Odzyskiwanie bazy danych i włączanie nadmiarowości stref dla usługi Azure SQL Managed Instance.