Zarządzanie miejscem na pliki dla baz danych w usłudze Azure SQL Managed Instance
Dotyczy: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
W tym artykule opisano sposób monitorowania plików i zarządzania nimi w bazach danych w usłudze Azure SQL Managed Instance. Sprawdzamy, jak monitorować rozmiar pliku bazy danych, zmniejszać dziennik transakcji, powiększać plik dziennika transakcji i kontrolować wzrost pliku dziennika transakcji.
Ten artykuł dotyczy usługi Azure SQL Managed Instance. Chociaż bardzo podobne, aby uzyskać informacje na temat zarządzania rozmiarem plików dziennika transakcji w programie SQL Server, zobacz Zarządzanie rozmiarem pliku dziennika transakcji.
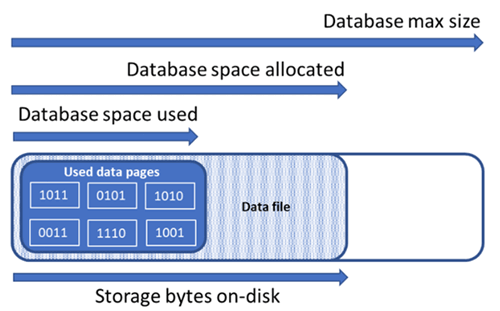
Omówienie typów miejsca do magazynowania dla bazy danych
Zrozumienie następujących ilości miejsca do magazynowania jest ważne w przypadku zarządzania przestrzenią plików bazy danych.
| Liczba baz danych | Definicja | Komentarze |
|---|---|---|
| Używane miejsce danych | Ilość miejsca używanego do przechowywania danych bazy danych. | Ogólnie rzecz biorąc, używane miejsce zwiększa (zmniejsza) w wstawkach (usunięciach). W niektórych przypadkach używane miejsce nie zmienia się w wstawianiu ani usuwaniu w zależności od ilości i wzorca danych zaangażowanych w operację i wszelkich fragmentacji. Na przykład usunięcie jednego wiersza z każdej strony danych nie zawsze powoduje zmniejszenie ilości używanego miejsca. |
| Przydzielone miejsce na dane | Ilość miejsca na sformatowane pliki udostępnionego na potrzeby przechowywania danych bazy danych. | Ilość przydzielonego miejsca zwiększa się automatycznie, ale nigdy nie zmniejsza się po usunięciu danych. Takie zachowanie zapewnia szybsze wstawianie w przyszłości, ponieważ nie trzeba ponownie sformatować miejsca. |
| Przydzielone miejsce na dane, ale nieużywane | Różnica między ilością przydzielonego miejsca na dane a używanym miejscem na dane. | Ta wielkość odzwierciedla maksymalną ilość wolnego miejsca, którą można odzyskać, zmniejszając pliki danych bazy danych. |
| Maksymalny rozmiar danych | Maksymalna ilość miejsca, która może być używana do przechowywania danych bazy danych. | Ilość przydzielonego miejsca na dane nie może przekroczyć maksymalnego rozmiaru danych. |
Na poniższym diagramie przedstawiono relację między różnymi typami miejsca do magazynowania dla bazy danych.
Wykonywanie zapytań względem pojedynczej bazy danych pod kątem informacji o przestrzeni plików
Użyj następującego zapytania w sys.database_files , aby zwrócić ilość przydzielonego miejsca na plik bazy danych i ilość przydzielonego nieużywanego miejsca. Wynik zapytania jest podawany w MB.
-- Connect to a user database
SELECT file_id, type_desc,
CAST(FILEPROPERTY(name, 'SpaceUsed') AS decimal(19,4)) * 8 / 1024. AS space_used_mb,
CAST(size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0 AS decimal(19,4)) AS space_unused_mb,
CAST(size AS decimal(19,4)) * 8 / 1024. AS space_allocated_mb,
CAST(max_size AS decimal(19,4)) * 8 / 1024. AS max_size_mb
FROM sys.database_files;
Monitorowanie użycia miejsca w dzienniku
Monitorowanie użycia miejsca w dzienniku przy użyciu sys.dm_db_log_space_usage. Ten dynamiczny widok zarządzania zwraca informacje o ilości aktualnie używanego miejsca w dzienniku i wskazuje, kiedy dziennik transakcji wymaga obcięcia.
Aby uzyskać informacje o bieżącym rozmiarze pliku dziennika, jego maksymalnym rozmiarze i opcji automatycznego zwiększania dla pliku, możesz również użyć sizemax_sizekolumn , i growth dla tego pliku dziennika w sys.database_files.
Metryki miejsca do magazynowania wyświetlane w interfejsach API metryk opartych na usłudze Azure Resource Manager mierzą tylko rozmiar używanych stron danych. Przykłady można znaleźć w temacie PowerShell get-metrics (Pobieranie metryk programu PowerShell).
Zmniejsz rozmiar pliku dziennika
Aby zmniejszyć rozmiar fizyczny pliku dziennika fizycznego, usuwając nieużywane miejsce, zmniejsz plik dziennika. Zmniejszanie ma znaczenie tylko wtedy, gdy plik dziennika transakcji zawiera nieużywane miejsce. Jeśli plik dziennika jest pełny, prawdopodobnie z powodu otwartych transakcji, zbadaj , co uniemożliwia obcinanie dziennika transakcji.
Uwaga
Operacje zmniejszania nie powinny być traktowane jako regularne operacje konserwacji. Pliki danych i dzienników, które rosną z powodu regularnych, cyklicznych operacji biznesowych nie wymagają operacji zmniejszania. Polecenia zmniejszania mają wpływ na wydajność działającej bazy danych i, jeśli to możliwe, należy je uruchamiać w czasie niskiego użycia. Nie zaleca się zmniejszania plików danych, jeśli zwykłe obciążenie aplikacji spowoduje ponowny wzrost rozmiaru plików do tego samego przydzielonego rozmiaru.
Należy pamiętać o potencjalnym negatywnym wpływie wydajności na zmniejszanie plików bazy danych, zobacz Konserwacja indeksu po zmniejszeniu. W rzadkich przypadkach operacje zmniejszania mogą mieć wpływ na automatyczne kopie zapasowe bazy danych. W razie potrzeby spróbuj ponownie wykonać operację zmniejszania.
Przed zmniejszeniem dziennika transakcji należy pamiętać o czynnikach, które mogą opóźnić obcinanie dziennika. Jeśli miejsce do magazynowania jest wymagane ponownie po zmniejszeniu dziennika, dziennik transakcji będzie ponownie rosnąć i w ten sposób wprowadzać obciążenie wydajności podczas operacji zwiększania dziennika. Aby uzyskać więcej informacji, zobacz Zalecenia.
Można zmniejszyć plik dziennika tylko wtedy, gdy baza danych jest w trybie online, a co najmniej jeden plik dziennika wirtualnego (VLF) jest bezpłatny. W niektórych przypadkach zmniejszanie dziennika może nie być możliwe dopiero po następnym obcięciu dziennika.
Czynniki, takie jak długotrwała transakcja, mogą utrzymywać aktywne funkcje VFS przez dłuższy czas, mogą ograniczać zmniejszanie dzienników, a nawet zapobiegać zmniejszaniu dziennika. Aby uzyskać informacje, zobacz Czynniki, które mogą opóźnić obcinanie dziennika.
Zmniejszanie pliku dziennika usuwa co najmniej jeden plik VFS , który nie zawiera żadnej części dziennika logicznego (czyli nieaktywnych plików VFS). Po zmniejszeniu pliku dziennika transakcji nieaktywne pliki VFS są usuwane z końca pliku dziennika, aby zmniejszyć dziennik do około rozmiaru docelowego.
Aby uzyskać więcej informacji na temat operacji zmniejszania, zapoznaj się z następującymi tematami:
Zmniejszanie pliku dziennika (bez zmniejszania plików bazy danych)
Monitorowanie zdarzeń zmniejszania pliku dziennika
- Klasa zdarzeń automatycznego zmniejszania pliku dziennika.
Monitorowanie miejsca w dzienniku
sys.database_files (Transact-SQL) (zobacz
sizekolumny ,max_sizeigrowthdla pliku dziennika lub plików).
Konserwacja indeksu po zmniejszeniu
Po zakończeniu operacji zmniejszania względem plików danych indeksy mogą zostać pofragmentowane. Zmniejsza to skuteczność optymalizacji wydajności dla niektórych obciążeń, takich jak zapytania korzystające z dużych skanów. Jeśli spadek wydajności wystąpi po zakończeniu operacji zmniejszania, rozważ konserwację indeksu w celu ponownego skompilowania indeksów. Należy pamiętać, że ponowne kompilowanie indeksu wymaga wolnego miejsca w bazie danych, dlatego może spowodować zwiększenie przydzielonego miejsca, przeciwdziałając efektowi zmniejszania.
Aby uzyskać więcej informacji na temat konserwacji indeksu, zobacz Optymalizowanie konserwacji indeksu w celu zwiększenia wydajności zapytań i zmniejszenia zużycia zasobów.
Ocena gęstości stron indeksu
Jeśli obcięcie plików danych nie spowodowało wystarczającej redukcji przydzielonego miejsca, możesz zdecydować się na zmniejszenie plików danych bazy danych w celu odzyskania nieużywanego miejsca z tych plików. Jednak jako opcjonalny, ale zalecany krok należy najpierw określić średnią gęstość stron dla indeksów w bazie danych. W przypadku tej samej ilości danych zmniejszanie zostanie ukończone szybciej, jeśli gęstość stron jest wysoka, ponieważ będzie musiała przenieść mniej stron. Jeśli gęstość stron jest niska dla niektórych indeksów, rozważ przeprowadzenie konserwacji tych indeksów w celu zwiększenia gęstości stron przed zmniejszeniem plików danych. Pozwoli to również zmniejszyć zmniejszenie ilości przydzielonego miejsca do magazynowania.
Aby określić gęstość stron dla wszystkich indeksów w bazie danych, użyj następującego zapytania. Gęstość strony jest zgłaszana w kolumnie avg_page_space_used_in_percent .
SELECT OBJECT_SCHEMA_NAME(ips.object_id) AS schema_name,
OBJECT_NAME(ips.object_id) AS object_name,
i.name AS index_name,
i.type_desc AS index_type,
ips.avg_page_space_used_in_percent,
ips.avg_fragmentation_in_percent,
ips.page_count,
ips.alloc_unit_type_desc,
ips.ghost_record_count
FROM sys.dm_db_index_physical_stats(DB_ID(), default, default, default, 'SAMPLED') AS ips
INNER JOIN sys.indexes AS i
ON ips.object_id = i.object_id
AND
ips.index_id = i.index_id
ORDER BY page_count DESC;
Jeśli istnieją indeksy o dużej liczbie stron o gęstości mniejszej niż 60–70%, rozważ ponowne skompilowanie lub reorganizację tych indeksów przed zmniejszeniem plików danych.
Uwaga
W przypadku większych baz danych zapytanie określające gęstość stron może zająć dużo czasu (godzin). Ponadto ponowne kompilowanie lub reorganizacja dużych indeksów wymaga również znacznego czasu i użycia zasobów. Istnieje kompromis między poświęcaniem dodatkowego czasu na zwiększenie gęstości stron z jednej strony, a zmniejszenie czasu trwania zmniejszania i osiąganie wyższych oszczędności miejsca na innym.
Jeśli istnieje wiele indeksów o niskiej gęstości stron, możesz je ponownie skompilować równolegle w wielu sesjach bazy danych, aby przyspieszyć proces. Upewnij się jednak, że nie zbliżasz się do limitów zasobów bazy danych, pozostawiając wystarczającą ilość zasobów dla obciążeń aplikacji. Monitorowanie użycia zasobów (procesor CPU, operacje we/wy danych, operacje we/wy dziennika) w witrynie Azure Portal lub korzystanie z widoku sys.dm_db_resource_stats oraz ponowne ponowne kompilowanie dodatkowych równoległych operacji tylko wtedy, gdy wykorzystanie zasobów w każdym z tych wymiarów pozostaje znacznie niższe niż 100%. Jeśli użycie procesora CPU, operacji we/wy danych lub operacji we/wy dziennika wynosi 100%, możesz skalować bazę danych w górę, aby mieć więcej rdzeni procesora CPU i zwiększyć przepływność operacji we/wy, co pozwala na szybsze ponowne kompilowanie dodatkowych równoległych operacji.
Przykładowe polecenie ponownego kompilowania indeksu
Poniżej przedstawiono przykładowe polecenie służące do ponownego kompilowania indeksu i zwiększania gęstości strony przy użyciu instrukcji ALTER INDEX :
ALTER INDEX [index_name] ON [schema_name].[table_name]
REBUILD WITH (FILLFACTOR = 100, MAXDOP = 8,
ONLINE = ON (WAIT_AT_LOW_PRIORITY (MAX_DURATION = 5 MINUTES, ABORT_AFTER_WAIT = NONE)),
RESUMABLE = ON);
To polecenie inicjuje ponowne kompilowanie indeksu w trybie online i wznawiania. Dzięki temu współbieżne obciążenia będą nadal korzystać z tabeli, gdy ponowne kompilowanie jest w toku, i umożliwia wznowienie ponownej kompilacji, jeśli zostanie przerwane z jakiegokolwiek powodu. Jednak ten typ odbudowy jest wolniejszy niż ponowne kompilowanie w trybie offline, co blokuje dostęp do tabeli. Jeśli żadne inne obciążenia nie muszą uzyskiwać dostępu do tabeli podczas ponownej kompilacji, ustaw ONLINE opcje i RESUMABLE na OFF i usuń klauzulę WAIT_AT_LOW_PRIORITY .
Aby dowiedzieć się więcej na temat konserwacji indeksu, zobacz Optymalizowanie konserwacji indeksu w celu zwiększenia wydajności zapytań i zmniejszenia zużycia zasobów.
Zmniejszanie wielu plików danych
Jak wspomniano wcześniej, zmniejszanie ruchu danych jest długotrwałym procesem. Jeśli baza danych zawiera wiele plików danych, możesz przyspieszyć proces przez równoległe zmniejszanie wielu plików danych. W tym celu należy otworzyć wiele sesji bazy danych i użyć ich DBCC SHRINKFILE w każdej sesji z inną file_id wartością. Podobnie jak w przypadku wcześniejszego ponownego kompilowania indeksów, przed rozpoczęciem każdego nowego polecenia zmniejszania równoległego upewnij się, że masz wystarczającą ilość zasobów (procesor CPU, operacje we/wy danych, operacje we/wy dziennika).
Następujące przykładowe polecenie zmniejsza plik danych z wartością file_id 4, próbując zmniejszyć przydzielony rozmiar do 52 000 MB, przenosząc strony w pliku:
DBCC SHRINKFILE (4, 52000);
Jeśli chcesz zmniejszyć przydzielone miejsce dla pliku do minimum możliwe, wykonaj instrukcję bez określania rozmiaru docelowego:
DBCC SHRINKFILE (4);
Jeśli obciążenie jest uruchomione współbieżnie z zmniejszeniem, może zacząć używać miejsca do magazynowania zwolnionego przez zmniejszenie przed zakończeniem zmniejszania i obcięciem pliku. W takim przypadku zmniejszanie nie będzie mogło zmniejszyć przydzielonego miejsca do określonego celu.
Można temu zapobiec, zmniejszając każdy plik w mniejszych krokach. Oznacza to, że w poleceniu DBCC SHRINKFILE należy ustawić element docelowy, który jest nieco mniejszy niż bieżące przydzielone miejsce dla pliku. Jeśli na przykład przydzielone miejsce dla pliku z file_id 4 wynosi 200 000 MB i chcesz zmniejszyć go do 100 000 MB, możesz najpierw ustawić docelowy rozmiar 170 000 MB:
DBCC SHRINKFILE (4, 170000);
Po zakończeniu tego polecenia plik zostanie obcięty i zmniejszy rozmiar przydzielony do 170 000 MB. Następnie można powtórzyć to polecenie, ustawiając element docelowy najpierw na 140 000 MB, a następnie do 110 000 MB itd., aż plik zostanie przesunięty do żądanego rozmiaru. Jeśli polecenie zostanie ukończone, ale plik nie zostanie obcięty, wykonaj mniejsze kroki, na przykład 15 000 MB, a nie 30 000 MB.
Aby monitorować postęp zmniejszania dla wszystkich współbieżnie uruchomionych sesji zmniejszania, można użyć następującego zapytania:
SELECT command,
percent_complete,
status,
wait_resource,
session_id,
wait_type,
blocking_session_id,
cpu_time,
reads,
CAST(((DATEDIFF(s,start_time, GETDATE()))/3600) AS varchar) + ' hour(s), '
+ CAST((DATEDIFF(s,start_time, GETDATE())%3600)/60 AS varchar) + 'min, '
+ CAST((DATEDIFF(s,start_time, GETDATE())%60) AS varchar) + ' sec' AS running_time
FROM sys.dm_exec_requests AS r
LEFT JOIN sys.databases AS d
ON r.database_id = d.database_id
WHERE r.command IN ('DbccSpaceReclaim','DbccFilesCompact','DbccLOBCompact','DBCC');
Uwaga
Postęp zmniejszania może być nieliniowy, a wartość w percent_complete kolumnie może pozostać praktycznie niezmieniona przez długi czas, mimo że zmniejszanie jest nadal w toku.
Po zakończeniu zmniejszania dla wszystkich plików danych użyj zapytania o użycie miejsca, aby określić wynikowy spadek przydzielonego rozmiaru magazynu. Jeśli nadal istnieje duża różnica między używanym miejscem a przydzielonym miejscem, można ponownie skompilować indeksy. Może to spowodować dalsze zwiększenie przydzielonego miejsca, jednak ponowne zmniejszanie plików danych po ponownym skompilowaniu indeksów powinno spowodować głębsze zmniejszenie przydzielonego miejsca.
Powiększanie pliku dziennika
W usłudze Azure SQL Managed Instance dodaj miejsce do pliku dziennika, powiększając istniejący plik dziennika (jeśli miejsce na dysku zezwala). Dodawanie pliku dziennika do bazy danych nie jest obsługiwane. Jeden plik dziennika transakcji jest wystarczający, chyba że brakuje miejsca w dzienniku, a miejsce na dysku również kończy się na woluminie, który zawiera plik dziennika.
Aby powiększyć plik dziennika, użyj MODIFY FILE klauzuli instrukcji ALTER DATABASE , określając składnię SIZE i MAXSIZE . Aby uzyskać więcej informacji, zobacz ALTER DATABASE (Transact-SQL) File and Filegroup options (Opcje pliku ALTER DATABASE (Transact-SQL) i grupy plików.
Aby uzyskać więcej informacji, zobacz Zalecenia.
Kontrolowanie wzrostu pliku dziennika transakcji
Użyj instrukcji Alter DATABASE (Transact-SQL) File and Filegroup, aby zarządzać wzrostem pliku dziennika transakcji. Należy zwrócić uwagę na następujące kwestie:
- Aby zmienić bieżący rozmiar pliku w jednostkach KB, MB, GB i TB, użyj
SIZEopcji . - Aby zmienić przyrost wzrostu, użyj
FILEGROWTHopcji . Wartość 0 oznacza, że automatyczny wzrost jest wyłączony i nie jest dozwolone żadne dodatkowe miejsce. - Aby kontrolować maksymalny rozmiar pliku dziennika w kb, MB, GB i TB jednostek lub ustawić wzrost na NIEOGRANICZONE, użyj
MAXSIZEopcji .
Zalecenia
Poniżej przedstawiono ogólne zalecenia dotyczące pracy z plikami dziennika transakcji:
Automatyczne zwiększanie (automatyczne zwiększanie) dziennika transakcji zgodnie z ustawieniem
FILEGROWTHopcji musi być wystarczająco duże, aby wyprzedzać potrzeby transakcji obciążenia. Przyrost wzrostu pliku w pliku dziennika powinien być wystarczająco duży, aby uniknąć częstego rozszerzania. Dobrym wskaźnikiem do prawidłowego rozmiaru dziennika transakcji jest monitorowanie ilości dziennika zajmowanego podczas:- Czas wymagany do wykonania pełnej kopii zapasowej, ponieważ nie można wykonać kopii zapasowych dziennika, dopóki nie zakończy się.
- Czas wymagany dla największych operacji konserwacji indeksu.
- Czas wymagany do wykonania największej partii w bazie danych.
Podczas ustawiania automatycznego zwiększania dla plików danych i dzienników przy użyciu
FILEGROWTHopcji może być preferowane ustawienie gosizezamiastpercentage, aby umożliwić lepszą kontrolę nad współczynnikiem wzrostu, ponieważ wartość procentowa jest coraz większą ilością.- W usłudze Azure SQL Managed Instance natychmiastowe inicjowanie plików może przynieść korzyści zdarzeń wzrostu dziennika transakcji do 64 MB. Domyślny przyrost rozmiaru automatycznego wzrostu dla nowych baz danych to 64 MB. Zdarzenia automatycznego zwiększania pliku dziennika transakcji większe niż 64 MB nie mogą korzystać z natychmiastowej inicjowania pliku.
- Najlepszym rozwiązaniem jest ustawienie
FILEGROWTHwartości opcji powyżej 1024 MB dla dzienników transakcji.
Mały przyrost automatycznego zwiększania może generować zbyt wiele małych plików VDF i może zmniejszyć wydajność. Aby określić optymalną dystrybucję VLF dla bieżącego rozmiaru dziennika transakcji wszystkich baz danych w danym wystąpieniu oraz wymagane przyrosty wzrostu w celu osiągnięcia wymaganego rozmiaru, zobacz ten skrypt do analizowania i naprawiania plików VFS dostarczonych przez zespół ds. tygrysów SQL.
Duży przyrost automatycznego zwiększania może powodować dwa problemy:
- Duży przyrost automatycznego zwiększania może spowodować wstrzymanie bazy danych podczas przydzielania nowego miejsca, co może spowodować przekroczenie limitu czasu zapytania.
- Duży przyrost automatycznego zwiększania może generować zbyt mało i dużych plików VDF , a także wpływać na wydajność. Aby określić optymalną dystrybucję VLF dla bieżącego rozmiaru dziennika transakcji wszystkich baz danych w danym wystąpieniu oraz wymagane przyrosty wzrostu w celu osiągnięcia wymaganego rozmiaru, zobacz ten skrypt do analizowania i naprawiania plików VFS dostarczonych przez zespół ds. tygrysów SQL.
Nawet w przypadku włączenia automatycznego zwiększania można otrzymać komunikat informujący, że dziennik transakcji jest pełny, jeśli nie może być wystarczająco szybki, aby zaspokoić potrzeby zapytania. Aby uzyskać więcej informacji na temat zmiany przyrostu wzrostu, zobacz ALTER DATABASE (Transact-SQL) File (Transact-SQL) file and Filegroup options (Opcje pliku ALTER DATABASE (Transact-SQL).
Pliki dziennika można ustawić tak, aby zmniejszały się automatycznie. Nie jest to jednak zalecane, a właściwość bazy danych auto_shrink jest domyślnie ustawiona na wartość FALSE. Jeśli auto_shrink jest ustawiona na wartość TRUE, automatyczne zmniejszanie zmniejsza rozmiar pliku tylko wtedy, gdy więcej niż 25 procent jego miejsca jest nieużywane.
- Plik jest zmniejszany do rozmiaru, w którym tylko 25 procent pliku nie ma miejsca lub oryginalnego rozmiaru pliku, w zależności od tego, co jest większe.
- Aby uzyskać informacje o zmianie ustawienia właściwości auto_shrink , zobacz Wyświetlanie lub zmienianie właściwości bazy danych i ALTER DATABASE SET Options (Transact-SQL).
Powiązana zawartość
- Automatyczne kopie zapasowe w usłudze Azure SQL Managed Instance
- ALTER DATABASE (Transact-SQL) File and Filegroup options (Opcje instrukcji ALTER DATABASE w języku Transact-SQL dla pliku i grupy plików)
- Omówienie limitów zasobów usługi Azure SQL Managed Instance
- Rozwiązywanie problemów z błędami dziennika transakcji w usłudze Azure SQL Managed Instance