Dostrajanie aplikacji i baz danych pod kątem wydajności w usłudze Azure SQL Managed Instance
Dotyczy: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Po zidentyfikowaniu problemu z wydajnością, który występuje w usłudze Azure SQL Managed Instance, ten artykuł został zaprojektowany w celu ułatwienia:
- Dostosuj aplikację i zastosuj najlepsze rozwiązania, które mogą poprawić wydajność.
- Dostrajanie bazy danych przez zmianę indeksów i zapytań w celu wydajniejszej pracy z danymi.
W tym artykule założono, że zapoznano się z omówieniem monitorowania i dostrajania i monitorowania wydajności przy użyciu magazynu zapytań. Ponadto w tym artykule założono, że nie masz problemu z wydajnością związanego z wykorzystaniem zasobów procesora CPU, które można rozwiązać przez zwiększenie rozmiaru obliczeniowego lub warstwy usługi w celu zapewnienia większej ilości zasobów do wystąpienia zarządzanego SQL.
Uwaga
Aby uzyskać podobne wskazówki w usłudze Azure SQL Database, zobacz Dostosowywanie aplikacji i baz danych pod kątem wydajności w usłudze Azure SQL Database.
Dostrajanie aplikacji
W tradycyjnym lokalnym programie SQL Server proces początkowego planowania pojemności jest często oddzielony od procesu uruchamiania aplikacji w środowisku produkcyjnym. Licencje sprzętowe i produktowe są najpierw kupowane, a dostrajanie wydajności odbywa się później. W przypadku korzystania z usługi Azure SQL warto przeplatać proces uruchamiania aplikacji i dostrajać go. Dzięki modelowi płacenia za pojemność na żądanie możesz dostosować aplikację do korzystania z zasobów minimalnych potrzebnych teraz, zamiast nadmiernie aprowizować sprzęt na podstawie odgadnięcia przyszłych planów wzrostu aplikacji, które często są niepoprawne.
Niektórzy klienci mogą zrezygnować z dostosowywania aplikacji, a zamiast tego zdecydować się na nadmierną aprowizację zasobów sprzętowych. Takie podejście może być dobrym pomysłem, jeśli nie chcesz zmieniać kluczowej aplikacji w okresie zajętości. Jednak dostrajanie aplikacji może zminimalizować wymagania dotyczące zasobów i obniżyć miesięczne rachunki.
Najlepsze rozwiązania i antywzorzec w projektowaniu aplikacji dla usługi Azure SQL Managed Instance
Mimo że warstwy usługi Azure SQL Managed Instance zostały zaprojektowane w celu zwiększenia stabilności wydajności i przewidywalności aplikacji, niektóre najlepsze rozwiązania mogą pomóc w dostosowaniu aplikacji, aby lepiej wykorzystać zasoby w rozmiarze obliczeniowym. Mimo że wiele aplikacji ma znaczne wzrosty wydajności, po prostu przełączając się na wyższy rozmiar obliczeniowy lub warstwę usług, niektóre aplikacje wymagają dodatkowego dostrajania, aby korzystać z wyższego poziomu usług.
Aby zwiększyć wydajność, rozważ dodatkowe dostrajanie aplikacji dla aplikacji, które mają następujące cechy:
Aplikacje, które mają niską wydajność z powodu zachowania "czatty"
Aplikacje chatty sprawiają, że nadmierne operacje dostępu do danych, które są wrażliwe na opóźnienie sieci. Może być konieczne zmodyfikowanie tego rodzaju aplikacji w celu zmniejszenia liczby operacji dostępu do danych do bazy danych. Na przykład możesz zwiększyć wydajność aplikacji przy użyciu technik, takich jak dzielenie zapytań ad hoc na partie lub przenoszenie zapytań do procedur składowanych. Aby uzyskać więcej informacji, zobacz Zapytania usługi Batch.
Bazy danych z intensywnym obciążeniem, które nie mogą być obsługiwane przez całą jedną maszynę
Bazy danych, które przekraczają zasoby najwyższego rozmiaru obliczeniowego Premium, mogą korzystać ze skalowania obciążenia w poziomie. Aby uzyskać więcej informacji, zobacz Partycjonowanie między bazami danych i Partycjonowanie funkcjonalne.
Aplikacje, które mają nieoptymalne zapytania
Aplikacje, które mają słabo dostrojone zapytania, mogą nie korzystać z większego rozmiaru obliczeniowego. Dotyczy to zapytań, które nie zawierają klauzuli WHERE, brakujących indeksów lub nieaktualnych statystyk. Te aplikacje korzystają ze standardowych technik dostrajania wydajności zapytań. Aby uzyskać więcej informacji, zobacz Brakujące indeksy i Dostrajanie zapytań i wskazówki.
Aplikacje, które mają nieoptymalny projekt dostępu do danych
Aplikacje, które mają nieodłączne problemy ze współbieżnością dostępu do danych, na przykład zakleszczenia, mogą nie korzystać z wyższego rozmiaru obliczeniowego. Rozważ zmniejszenie liczby rund względem bazy danych przez buforowanie danych po stronie klienta przy użyciu usługi Azure usługa buforowania lub innej technologii buforowania. Zobacz Buforowanie warstwy aplikacji.
Aby zapobiec zakleszczeniom w usłudze Azure SQL Managed Instance, zobacz Narzędzia zakleszczenia przewodnika zakleszczenia.
Dostrajanie bazy danych
W tej sekcji przyjrzymy się niektórym technikom, których można użyć do dostrajania bazy danych w celu uzyskania najlepszej wydajności aplikacji i uruchomienia jej przy najniższym możliwym rozmiarze obliczeniowym. Niektóre z tych technik są zgodne z tradycyjnymi najlepszymi rozwiązaniami dotyczącymi dostrajania programu SQL Server, ale inne są specyficzne dla usługi Azure SQL Managed Instance. W niektórych przypadkach możesz zbadać zużyte zasoby dla bazy danych, aby znaleźć obszary w celu dalszego dostosowywania i rozszerzania tradycyjnych technik programu SQL Server do pracy w usłudze Azure SQL Managed Instance.
Identyfikowanie i dodawanie brakujących indeksów
Typowy problem z wydajnością bazy danych OLTP odnosi się do projektu fizycznej bazy danych. Często schematy baz danych są projektowane i dostarczane bez testowania na dużą skalę (w obciążeniu lub woluminie danych). Niestety wydajność planu zapytania może być akceptowalna na małą skalę, ale znacznie obniżyć wydajność woluminów danych na poziomie produkcyjnym. Najczęstszym źródłem tego problemu jest brak odpowiednich indeksów w celu spełnienia filtrów lub innych ograniczeń w zapytaniu. Często brakujące manifesty indeksów są skanowane w postaci tabeli, gdy wyszukiwanie indeksu może wystarczyć.
W tym przykładzie wybrany plan zapytania używa skanowania, gdy wyszukiwanie wystarczy:
DROP TABLE dbo.missingindex;
CREATE TABLE dbo.missingindex (col1 INT IDENTITY PRIMARY KEY, col2 INT);
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO dbo.missingindex(col2) VALUES (@a);
SET @a += 1;
END
COMMIT TRANSACTION;
GO
SELECT m1.col1
FROM dbo.missingindex m1 INNER JOIN dbo.missingindex m2 ON(m1.col1=m2.col1)
WHERE m1.col2 = 4;
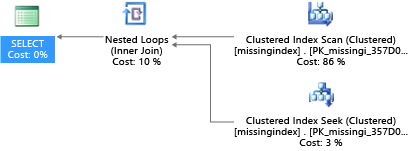
Dynamiczne widoki zarządzania wbudowane w program SQL Server od 2005 r. przyglądają się kompilacjom zapytań, w których indeks znacznie obniży szacowany koszt uruchamiania zapytania. Podczas wykonywania zapytań aparat bazy danych śledzi, jak często jest wykonywany każdy plan zapytania, i śledzi szacowaną lukę między wykonywaniem planu zapytania a wyobrażonym, w którym istniał ten indeks. Za pomocą tych widoków DMV można szybko odgadnąć, które zmiany projektu fizycznej bazy danych mogą poprawić ogólny koszt obciążenia bazy danych i rzeczywistego obciążenia.
To zapytanie umożliwia ocenę potencjalnych brakujących indeksów:
SELECT
CONVERT (varchar, getdate(), 126) AS runtime
, mig.index_group_handle
, mid.index_handle
, CONVERT (decimal (28,1), migs.avg_total_user_cost * migs.avg_user_impact *
(migs.user_seeks + migs.user_scans)) AS improvement_measure
, 'CREATE INDEX missing_index_' + CONVERT (varchar, mig.index_group_handle) + '_' +
CONVERT (varchar, mid.index_handle) + ' ON ' + mid.statement + '
(' + ISNULL (mid.equality_columns,'')
+ CASE WHEN mid.equality_columns IS NOT NULL
AND mid.inequality_columns IS NOT NULL
THEN ',' ELSE '' END + ISNULL (mid.inequality_columns, '') + ')'
+ ISNULL (' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement
, migs.*
, mid.database_id
, mid.[object_id]
FROM sys.dm_db_missing_index_groups AS mig
INNER JOIN sys.dm_db_missing_index_group_stats AS migs
ON migs.group_handle = mig.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS mid
ON mig.index_handle = mid.index_handle
ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC
W tym przykładzie zapytanie spowodowało następującą sugestię:
CREATE INDEX missing_index_5006_5005 ON [dbo].[missingindex] ([col2])
Po jego utworzeniu ta sama instrukcja SELECT wybiera inny plan, który używa wyszukiwania zamiast skanowania, a następnie wykonuje plan wydajniej:
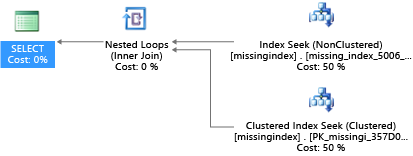
Kluczową analizą jest to, że pojemność operacji we/wy współużytkowanego systemu towarowego jest bardziej ograniczona niż pojemność dedykowanego komputera serwera. Istnieje premia za zminimalizowanie niepotrzebnych operacji we/wy, aby maksymalnie wykorzystać system w zasobach każdego rozmiaru obliczeniowego warstw usług. Odpowiednie opcje projektowania fizycznej bazy danych mogą znacznie poprawić opóźnienie poszczególnych zapytań, zwiększyć przepływność współbieżnych żądań obsługiwanych na jednostkę skalowania i zminimalizować koszty wymagane do spełnienia zapytania.
Aby uzyskać więcej informacji na temat dostrajania indeksów przy użyciu brakujących żądań indeksu, zobacz Dostosowywanie indeksów nieklastrowanych z brakującymi sugestiami indeksu.
Dostrajanie zapytań i podpowiedzi
Optymalizator zapytań w usłudze Azure SQL Managed Instance jest podobny do tradycyjnego optymalizatora zapytań programu SQL Server. Większość najlepszych rozwiązań dotyczących dostrajania zapytań i zrozumienia ograniczeń modelu rozumowania dla optymalizatora zapytań dotyczy również usługi Azure SQL Managed Instance. Jeśli dostrajasz zapytania w usłudze Azure SQL Managed Instance, możesz uzyskać dodatkową korzyść z zmniejszenia zagregowanych wymagań dotyczących zasobów. Aplikacja może być w stanie działać przy niższych kosztach niż odpowiednik nieostrożny, ponieważ może działać przy niższym rozmiarze obliczeniowym.
Przykładem typowym w programie SQL Server, który ma również zastosowanie do usługi Azure SQL Managed Instance, jest sposób, w jaki parametry "sniffs" optymalizatora zapytań. Podczas kompilacji optymalizator zapytań ocenia bieżącą wartość parametru, aby określić, czy może wygenerować bardziej optymalny plan zapytania. Mimo że ta strategia często może prowadzić do tego, że plan jest znacznie szybszy niż plan skompilowany bez znanych wartości parametrów, obecnie działa on w usłudze Azure SQL Managed Instance. (Nowa funkcja inteligentnej wydajności zapytań wprowadzona w programie SQL Server 2022 o nazwie Optymalizacja planu poufności parametrów dotyczy scenariusza, w którym pojedynczy buforowany plan zapytania sparametryzowanego nie jest optymalny dla wszystkich możliwych wartości parametrów przychodzących. Obecnie optymalizacja planu poufności parametrów nie jest dostępna w usłudze Azure SQL Managed Instance).
Czasami parametr nie jest wąchany, a czasami parametr jest wąchany, ale wygenerowany plan jest nieoptymalny dla pełnego zestawu wartości parametrów w obciążeniu. Firma Microsoft zawiera wskazówki dotyczące zapytań (dyrektywy), dzięki czemu można określić intencję bardziej celowo i zastąpić domyślne zachowanie wąchania parametrów. Możesz użyć wskazówek, gdy domyślne zachowanie jest niedoskonałe dla określonego obciążenia klienta.
W następnym przykładzie pokazano, jak procesor zapytań może wygenerować plan, który jest nieoptymalny zarówno dla wymagań dotyczących wydajności, jak i zasobów. W tym przykładzie pokazano również, że jeśli używasz wskazówki dotyczącej zapytania, możesz skrócić czas wykonywania zapytań i wymagania dotyczące zasobów dla bazy danych:
DROP TABLE psptest1;
CREATE TABLE psptest1(col1 int primary key identity, col2 int, col3 binary(200));
DECLARE @a int = 0;
SET NOCOUNT ON;
BEGIN TRANSACTION
WHILE @a < 20000
BEGIN
INSERT INTO psptest1(col2) values (1);
INSERT INTO psptest1(col2) values (@a);
SET @a += 1;
END
COMMIT TRANSACTION
CREATE INDEX i1 on psptest1(col2);
GO
CREATE PROCEDURE psp1 (@param1 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1
WHERE col2 = @param1
ORDER BY col2;
END
GO
CREATE PROCEDURE psp2 (@param2 int)
AS
BEGIN
INSERT INTO t1 SELECT * FROM psptest1 WHERE col2 = @param2
ORDER BY col2
OPTION (OPTIMIZE FOR (@param2 UNKNOWN))
END
GO
CREATE TABLE t1 (col1 int primary key, col2 int, col3 binary(200));
GO
Kod konfiguracji tworzy tabelę, która ma nieregularnie rozproszone dane w t1 tabeli. Optymalny plan zapytania różni się w zależności od wybranego parametru. Niestety, zachowanie buforowania planu nie zawsze rekompiluje zapytanie na podstawie najbardziej typowej wartości parametru. Dlatego można buforować nieoptymalny plan i używać go dla wielu wartości, nawet jeśli inny plan może być lepszym wyborem planu średnio. Następnie plan zapytania tworzy dwie procedury składowane, które są identyczne, z tą różnicą, że jeden ma specjalną wskazówkę dotyczącą zapytania.
-- Prime Procedure Cache with scan plan
EXEC psp1 @param1=1;
TRUNCATE TABLE t1;
-- Iterate multiple times to show the performance difference
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp1 @param1=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Zalecamy odczekanie co najmniej 10 minut przed rozpoczęciem części 2 przykładu, dzięki czemu wyniki są odrębne w wynikowych danych telemetrycznych.
EXEC psp2 @param2=1;
TRUNCATE TABLE t1;
DECLARE @i int = 0;
WHILE @i < 1000
BEGIN
EXEC psp2 @param2=2;
TRUNCATE TABLE t1;
SET @i += 1;
END
Każda część tego przykładu próbuje uruchomić sparametryzowaną instrukcję insert 1000 razy (aby wygenerować wystarczające obciążenie do użycia jako zestaw danych testowych). Podczas wykonywania procedur składowanych procesor zapytań sprawdza wartość parametru przekazywaną do procedury podczas pierwszej kompilacji (parametr "sniffing"). Procesor buforuje wynikowy plan i używa go do późniejszego wywołania, nawet jeśli wartość parametru jest inna. Optymalny plan może nie być używany we wszystkich przypadkach. Czasami należy kierować optymalizatorem, aby wybrać plan, który jest lepszy dla średniej wielkości liter, a nie z konkretnego przypadku podczas pierwszego skompilowania zapytania. W tym przykładzie początkowy plan generuje plan "skanowania", który odczytuje wszystkie wiersze, aby znaleźć każdą wartość zgodną z parametrem:

Ponieważ wykonaliśmy procedurę przy użyciu wartości 1, wynikowy plan był optymalny dla wartości 1 , ale był nieoptymalny dla wszystkich innych wartości w tabeli. Wynik prawdopodobnie nie jest tym, czego chcesz, jeśli chcesz losowo wybrać każdy plan, ponieważ plan działa wolniej i używa większej ilości zasobów.
Jeśli uruchomisz test z ustawioną wartością SET STATISTICS IO ON, logiczna praca skanowania w tym przykładzie zostanie wykonana w tle. Widać, że plan wykonuje 1148 odczytów (co jest nieefektywne, jeśli średni przypadek ma zwrócić tylko jeden wiersz):

W drugiej części przykładu użyto wskazówki dotyczącej zapytania, aby powiedzieć optymalizatorowi użycie określonej wartości podczas procesu kompilacji. W takim przypadku wymusza procesor zapytań ignorowanie wartości przekazanej jako parametru, a zamiast tego przyjmuje wartość UNKNOWN. Odnosi się to do wartości, która ma średnią częstotliwość w tabeli (ignorując niesymetryczność). Wynikowy plan jest planem opartym na wyszukiwaniu, który jest szybszy i zużywa średnio mniej zasobów niż plan w części 1 tego przykładu:
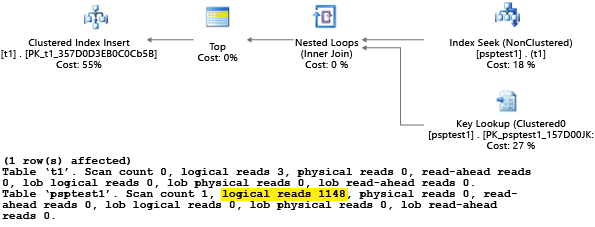
Efekt można zobaczyć w widoku katalogu systemu sys.server_resource_stats . Dane są zbierane, agregowane i aktualizowane w przedziale od 5 do 10 minut. Istnieje jeden wiersz co 15 sekund raportowania. Na przykład:
SELECT TOP 1000 *
FROM sys.server_resource_stats
ORDER BY start_time DESC
Możesz sprawdzić sys.server_resource_stats , czy zasób testu używa więcej lub mniej zasobów niż inny test. Podczas porównywania danych rozdziel czas testów, aby nie były one w tym samym 5-minutowym oknie w sys.server_resource_stats widoku. Celem ćwiczenia jest zminimalizowanie całkowitej ilości używanych zasobów, a nie zminimalizowanie szczytowych zasobów. Ogólnie rzecz biorąc, optymalizacja fragmentu kodu pod kątem opóźnień zmniejsza również zużycie zasobów. Upewnij się, że zmiany wprowadzone w aplikacji są niezbędne i że zmiany nie wpływają negatywnie na środowisko klienta dla osoby, która może używać wskazówek dotyczących zapytań w aplikacji.
Jeśli obciążenie ma zestaw powtarzających się zapytań, często warto przechwycić i zweryfikować optymalność wyborów planu, ponieważ jest to jednostka minimalnego rozmiaru zasobów wymagana do hostowania bazy danych. Po jego zweryfikowaniu od czasu do czasu ponownie przejmiesz plany, aby upewnić się, że nie uległy pogorszeniu. Więcej informacji na temat wskazówek dotyczących zapytań (Transact-SQL) można dowiedzieć się więcej.
Najlepsze rozwiązania dotyczące bardzo dużych architektur baz danych w usłudze Azure SQL Managed Instance
W poniższych dwóch sekcjach omówiono dwie opcje rozwiązywania problemów z bardzo dużymi bazami danych w usłudze Azure SQL Managed Instance.
Fragmentowanie między bazami danych
Ponieważ usługa Azure SQL Managed Instance działa na sprzęcie towarowym, limity pojemności dla pojedynczej bazy danych są niższe niż w przypadku tradycyjnej lokalnej instalacji programu SQL Server. Niektórzy klienci używają technik dzielenia na fragmenty w celu rozłożenia operacji bazy danych na wiele baz danych, gdy operacje nie mieszczą się w granicach pojedynczej bazy danych w usłudze Azure SQL Managed Instance. Większość klientów korzystających z technik fragmentowania w usłudze Azure SQL Managed Instance dzieli dane na jeden wymiar w wielu bazach danych. W przypadku tego podejścia należy zrozumieć, że aplikacje OLTP często wykonują transakcje, które dotyczą tylko jednego wiersza lub małej grupy wierszy w schemacie.
Jeśli na przykład baza danych ma nazwę klienta, zamówienie i szczegóły zamówienia (na przykład w AdventureWorks bazie danych), możesz podzielić te dane na wiele baz danych, grupując klienta na powiązane informacje dotyczące zamówienia i szczegółów zamówienia. Możesz zagwarantować, że dane klienta pozostaną w pojedynczej bazie danych. Aplikacja dzieliłaby różnych klientów między bazy danych, efektywnie rozkładając obciążenie na wiele baz danych. Dzięki fragmentowaniu klienci nie tylko mogą uniknąć maksymalnego limitu rozmiaru bazy danych, ale usługa Azure SQL Managed Instance może również przetwarzać obciążenia znacznie większe niż limity różnych rozmiarów obliczeniowych, o ile każda pojedyncza baza danych mieści się w limitach warstwy usług.
Chociaż fragmentowanie bazy danych nie zmniejsza zagregowanej pojemności zasobów dla rozwiązania, bardzo skuteczne jest obsługę bardzo dużych rozwiązań, które są rozłożone na wiele baz danych. Każda baza danych może działać w innym rozmiarze obliczeniowym, aby obsługiwać bardzo duże, "skuteczne" bazy danych z wysokimi wymaganiami dotyczącymi zasobów.
Partycjonowanie funkcjonalne
Użytkownicy często łączą wiele funkcji w pojedynczej bazie danych. Jeśli na przykład aplikacja ma logikę do zarządzania spisem dla sklepu, ta baza danych może mieć logikę skojarzoną ze spisem, śledzenie zamówień zakupu, procedur składowanych i indeksowanych lub zmaterializowanych widoków, które zarządzają raportowaniem końca miesiąca. Ta technika ułatwia administrowanie bazą danych na potrzeby operacji, takich jak tworzenie kopii zapasowych, ale wymaga również rozmiaru sprzętu w celu obsługi szczytowego obciążenia we wszystkich funkcjach aplikacji.
Jeśli używasz architektury skalowanej w poziomie w usłudze Azure SQL Managed Instance, dobrym pomysłem jest podzielenie różnych funkcji aplikacji na różne bazy danych. Jeśli używasz tej techniki, każda aplikacja skaluje się niezależnie. Gdy aplikacja staje się bardziej ruchliwa (i zwiększa się obciążenie bazy danych), administrator może wybrać niezależne rozmiary obliczeniowe dla każdej funkcji w aplikacji. W przypadku tej architektury aplikacja może być większa niż jedna maszyna towarów może obsłużyć, ponieważ obciążenie jest rozłożone na wiele maszyn.
Zapytania usługi Batch
W przypadku aplikacji, które uzyskują dostęp do danych przy użyciu dużych, częstych zapytań ad hoc, znaczna ilość czasu odpowiedzi jest poświęcana na komunikację sieciową między warstwą aplikacji a warstwą bazy danych. Nawet jeśli zarówno aplikacja, jak i baza danych znajdują się w tym samym centrum danych, opóźnienie sieci między nimi może zostać powiększone przez dużą liczbę operacji dostępu do danych. Aby zmniejszyć liczbę rund sieci dla operacji dostępu do danych, rozważ użycie opcji wsadowej zapytań ad hoc lub skompilowania ich jako procedur składowanych. W przypadku dzielenia na partie zapytań ad hoc można wysłać wiele zapytań jako jedną dużą partię w jednej podróży do bazy danych. Jeśli skompilujesz zapytania ad hoc w procedurze składowanej, możesz osiągnąć taki sam wynik, jak w przypadku ich dzielenia na partie. Użycie procedury składowanej daje również korzyści z zwiększenia szans buforowania planów zapytań w bazie danych, dzięki czemu można ponownie użyć procedury składowanej.
Niektóre aplikacje intensywnie korzystają z zapisu. Czasami można zmniejszyć łączne obciążenie operacji we/wy w bazie danych, biorąc pod uwagę sposób wsadowego zapisu razem. Często jest to tak proste, jak używanie jawnych transakcji zamiast transakcji automatycznego zatwierdzania w procedurach składowanych i partiach ad hoc. Aby zapoznać się z oceną różnych technik, których można użyć, zobacz Techniki przetwarzania wsadowego dla aplikacji baz danych na platformie Azure. Poeksperymentuj z własnym obciążeniem, aby znaleźć odpowiedni model do dzielenia na partie. Pamiętaj, aby zrozumieć, że model może mieć nieco inne gwarancje spójności transakcyjnej. Znalezienie odpowiedniego obciążenia, które minimalizuje użycie zasobów, wymaga znalezienia odpowiedniej kombinacji kompromisów spójności i wydajności.
Buforowanie warstwy aplikacji
Niektóre aplikacje bazy danych mają obciążenia z dużym obciążeniem odczytu. Warstwy buforowania mogą zmniejszyć obciążenie bazy danych i potencjalnie zmniejszyć rozmiar obliczeniowy wymagany do obsługi bazy danych przy użyciu usługi Azure SQL Managed Instance. W usłudze Azure Cache for Redis, jeśli masz obciążenie z dużym obciążeniem odczytu, możesz odczytać dane raz (a może raz na maszynę w warstwie aplikacji, w zależności od tego, jak są skonfigurowane), a następnie przechowywać te dane poza bazą danych. Jest to sposób zmniejszenia obciążenia bazy danych (procesora CPU i odczytu operacji we/wy), ale istnieje wpływ na spójność transakcyjną, ponieważ dane odczytywane z pamięci podręcznej mogą nie być zsynchronizowane z danymi w bazie danych. Chociaż w wielu aplikacjach akceptowalny jest pewien poziom niespójności, nie dotyczy to wszystkich obciążeń. Przed zaimplementowaniem strategii buforowania warstwy aplikacji należy w pełni zrozumieć wszelkie wymagania aplikacji.
Powiązana zawartość
- Model zakupów rdzeni wirtualnych — Azure SQL Managed Instance
- Konfigurowanie ustawień bazy danych tempdb dla usługi Azure SQL Managed Instance
- Monitorowanie wydajności usługi Microsoft Azure SQL Managed Instance przy użyciu dynamicznych widoków zarządzania
- Dostrajanie indeksów nieklastrowanych za pomocą sugestii brakujących indeksów
- Monitorowanie usługi Azure SQL Managed Instance za pomocą usługi Azure Monitor