Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować się zalogować lub zmienić katalog.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Usługa Azure Backup oferuje wbudowaną strukturę prescript i postscript , aby zapewnić spójność aplikacji dla maszyn wirtualnych z systemem Linux podczas tworzenia kopii zapasowych. Ta struktura automatycznie uruchamia skrypt wstępny, aby wyciszyć aplikacje przed wykonaniem migawek dysku, oraz skrypt końcowy w celu przywrócenia aplikacji do normalnego działania po migawkach.
Zarządzanie niestandardowymi indeksami i postscriptami jest często złożone i czasochłonne. Aby uprościć ten proces, usługa Azure Backup udostępnia gotowe do użycia skrypty wstępne i końcowe dla popularnych baz danych, aby umożliwić tworzenie migawek, które są spójne z aplikacjami, przy minimalnym nakładzie pracy i konserwacji.
Na poniższym diagramie pokazano, w jaki sposób usługa Azure Backup używa rozszerzonych skryptów prescript i postscript w celu uzyskania migawek spójnych na poziomie aplikacji dla baz danych systemu Linux w celu zapewnienia niezawodnej kopii zapasowej i odzyskiwania.
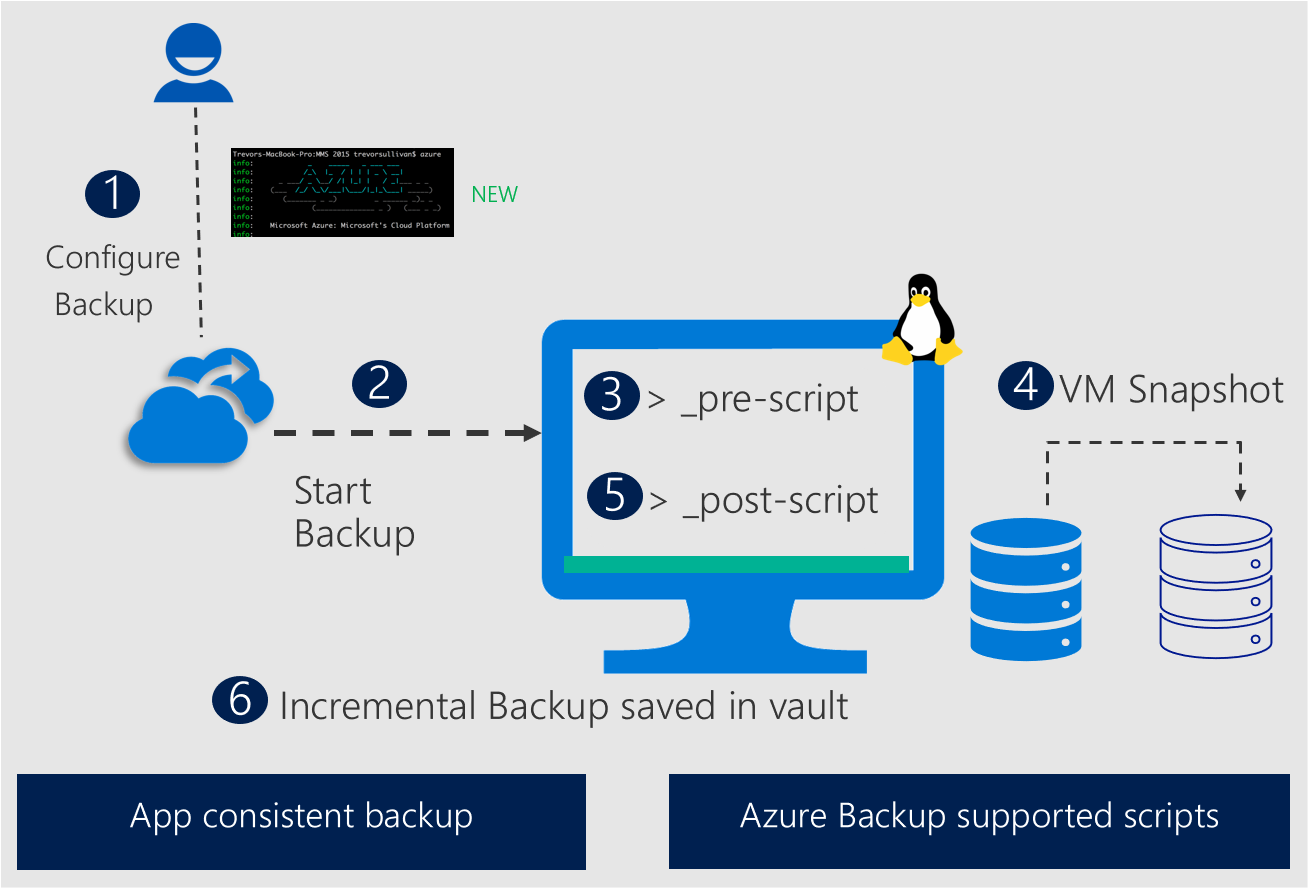
Najważniejsze korzyści wynikające z rozszerzonej struktury prescript i postscript
Nowa rozszerzona struktura prescript i postscript ma następujące kluczowe korzyści:
- Te preskrypty i postscripty są instalowane bezpośrednio na maszynach wirtualnych platformy Azure wraz z rozszerzeniem do kopii zapasowych, co pomaga wyeliminować potrzebę tworzenia i pobierania ich z lokalizacji zewnętrznej.
- Definicja i treść preskryptów i postskryptów są dostępne do wyświetlenia na GitHub. Możesz przesyłać sugestie i zmiany za pomocą GitHub, które są klasyfikowane i dodawane na korzyść szerszej społeczności.
- Nowe prescripty i postscripty dla innych baz danych są dostępne za pośrednictwem usługi GitHub, które są klasyfikowane i rozwiązywane, aby przynosić korzyści szerszej społeczności.
- Niezawodna struktura jest wydajna do obsługi scenariuszy, takich jak niepowodzenie wykonywania w indeksie wstępnym lub awarie. W każdym przypadku skrypt postscript jest uruchamiany automatycznie, aby wycofać wszystkie zmiany wprowadzone w stenogramie.
- Platforma udostępnia również kanał komunikatów dla narzędzi zewnętrznych do pobierania aktualizacji i przygotowywania własnego planu działania na każdy komunikat lub zdarzenie.
Przepływ rozwiązań rozszerzonej struktury prescript i postscript
Na poniższym diagramie przedstawiono przepływ rozwiązań rozszerzonej struktury prescript i postscript dla migawek spójnych na poziomie bazy danych.
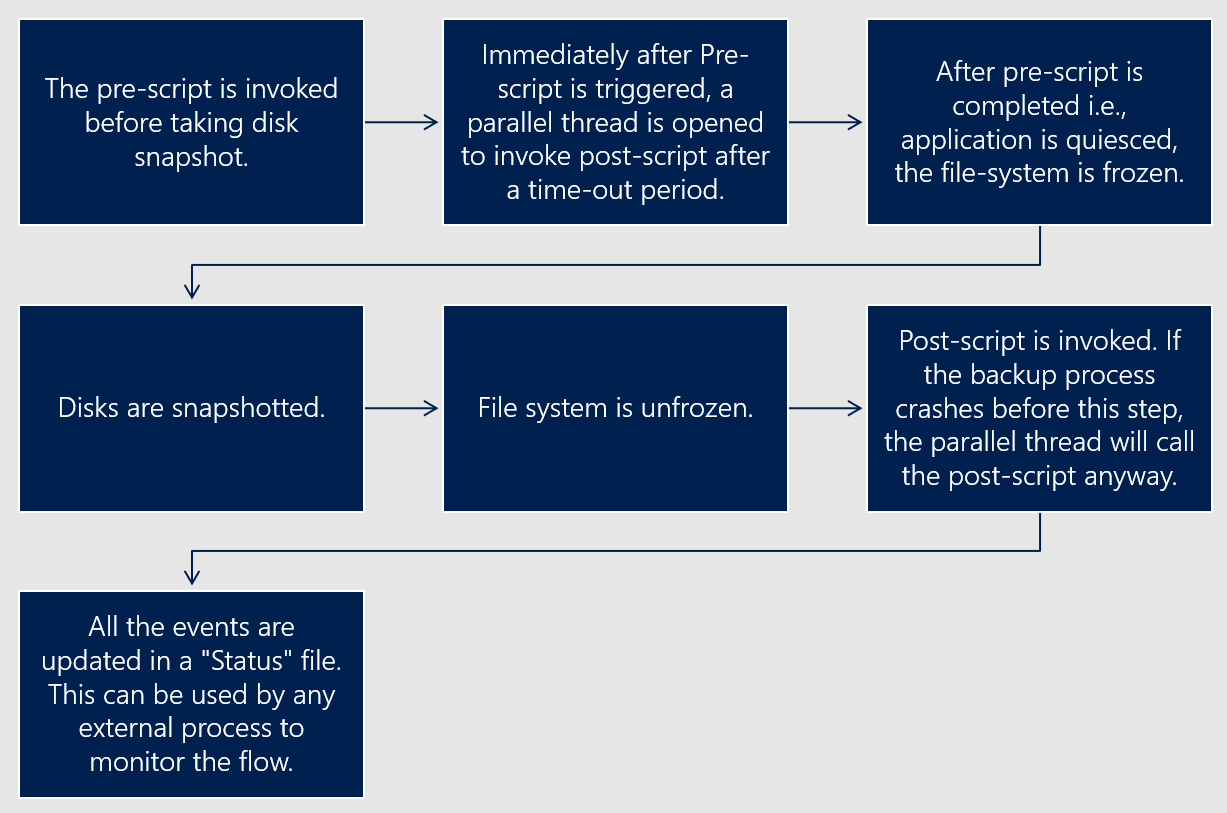
Diagram pomocy technicznej
W ramach rozszerzonej struktury omówiono następujące bazy danych:
- Oracle (ogólnie dostępna): zobacz Macierz obsługi kopii zapasowych maszyn wirtualnych platformy Azure.
- MySQL (wersja zapoznawcza).
Prerequisites
Aby podać szczegóły połączenia, należy zmodyfikować tylko plik konfiguracji, workload.conf w /etc/azurepliku . W ten sposób usługa Azure Backup może łączyć się z odpowiednią aplikacją i uruchamiać przeskrypty i postskrypty. Plik konfiguracji ma następujące parametry:
[workload]
# valid values are mysql, oracle
workload_name =
command_path =
linux_user =
credString =
ipc_folder =
timeout =
W poniższej tabeli opisano parametry.
| Parameter | Mandatory | Explanation |
|---|---|---|
workload_name |
Yes | Zawiera nazwę bazy danych, dla której potrzebna jest kopia zapasowa spójna na poziomie aplikacji. Bieżące obsługiwane wartości to oracle lub mysql. |
command_path/configuration_path |
Zawiera ścieżkę do pliku binarnego aplikacji obciążeniowej. To pole nie jest obowiązkowe, jeśli binarium obciążenia jest ustawione jako zmienna ścieżkowa. | |
linux_user |
Yes | Zawiera nazwę użytkownika systemu Linux z dostępem do logowania użytkownika bazy danych. Jeśli ta wartość nie jest ustawiona, użytkownik root jest traktowany jako użytkownik domyślny. |
credString |
Oznacza ciąg poświadczeń umożliwiający nawiązanie połączenia z bazą danych. Zawiera pełen ciąg tekstowy logowania. | |
ipc_folder |
Obciążenie może zapisywać do tylko określonych ścieżek systemu plików. Podaj tę ścieżkę folderu, aby prekrypcja mogła zapisywać stany w tej ścieżce folderu. | |
timeout |
Yes | Maksymalny limit czasu, dla którego baza danych jest w stanie cichym. Wartość domyślna to 90 sekund. Nie ustawiaj wartości mniejszej niż 60 sekund. |
Note
Definicja JSON jest szablonem, który usługa Azure Backup może modyfikować tak, aby odpowiadała określonej bazie danych. Aby zrozumieć plik konfiguracji dla każdej bazy danych, zapoznaj się z instrukcjami poszczególnych baz danych.
Ogólne doświadczenie związane z korzystaniem z rozszerzonej struktury prescript i postscript jest następujące:
- Przygotuj środowisko bazy danych.
- Edytuj plik konfiguracji.
- Wyzwalanie kopii zapasowej maszyny wirtualnej.
- W razie potrzeby przywróć maszyny wirtualne lub dyski lub pliki z punktu odzyskiwania spójnego na poziomie aplikacji.
Tworzenie strategii tworzenia kopii zapasowej bazy danych
Użyj migawek zamiast przesyłania strumieniowego
Zazwyczaj kopie zapasowe przesyłania strumieniowego (takie jak pełne, różnicowe lub przyrostowe) i dzienniki są używane przez administratorów bazy danych w strategii tworzenia kopii zapasowych. Kluczowe kwestie w projekcie to:
- Wydajność i koszty: codzienna pełna kopia zapasowa i dzienniki są najszybsze podczas przywracania, ale wiąże się ze znacznymi kosztami. Uwzględnienie różnicowego lub przyrostowego typu kopii zapasowej strumieniowej zmniejsza koszty, ale może wpłynąć na wydajność przywracania. Jednak migawki zapewniają najlepszą kombinację wydajności i kosztów. Ponieważ migawki są z natury przyrostowe, mają najmniejszy wpływ na wydajność podczas tworzenia kopii zapasowej, są szybko przywracane oraz pozwalają zaoszczędzić koszty.
- Wpływ na bazę danych lub infrastrukturę: Wydajność kopii zapasowej przesyłania strumieniowego zależy od podstawowej IOPS magazynu i przepustowości sieci dostępnej, kiedy strumień jest kierowany do lokalizacji zdalnej. Migawki nie mają tej zależności, a zapotrzebowanie na IOPS i przepustowość sieci zostało zmniejszone.
- Możliwość ponownego użycia: polecenia wyzwalania różnych typów kopii zapasowych przesyłania strumieniowego są różne dla każdej bazy danych, więc skrypty nie mogą być łatwo używane ponownie. Ponadto jeśli używasz różnych typów kopii zapasowych, pamiętaj, aby ocenić łańcuch zależności w celu zachowania cyklu życia. W przypadku migawek można łatwo napisać skrypt, ponieważ nie ma łańcucha zależności.
- Długoterminowe przechowywanie: pełne kopie zapasowe są zawsze korzystne w przypadku długoterminowego przechowywania, ponieważ można je przenosić i odzyskiwać niezależnie. W przypadku kopii zapasowych operacyjnych z krótkoterminowym przechowywaniem migawki są korzystne.
Codzienna migawka oraz dzienniki z okazjonalną pełną kopią zapasową na potrzeby długoterminowego przechowywania to najlepsze zasady tworzenia kopii zapasowych baz danych.
Strategia tworzenia kopii zapasowych dzienników
Ulepszony framework prescript i postscript jest oparty na kopii zapasowej maszyny wirtualnej platformy Azure, która umożliwia wykonywanie kopii zapasowej raz dziennie. Z tego powodu okno utraty danych z celem punktu odzyskiwania (RPO) wynoszącym 24 godziny nie jest odpowiednie dla produkcyjnych baz danych. To rozwiązanie jest uzupełniane strategią tworzenia kopii zapasowej dziennika, w której kopie zapasowe dzienników są przesyłane strumieniowo jawnie.
System Plików Sieciowych (NFS) w usłudze Azure Blob Storage i System Plików Sieciowych NFS w wersji zapoznawczej AFS ułatwia łatwe montowanie woluminów bezpośrednio na maszynach wirtualnych baz danych i używanie klientów baz danych do przesyłania kopii zapasowych dzienników. Okno utraty danych, czyli RPO, zależy od częstotliwości tworzenia kopii zapasowych dziennika. Ponadto elementy docelowe systemu plików NFS nie muszą być wysoce wydajne. Po wykonaniu migawek spójnych na poziomie bazy danych może nie być konieczne uruchamianie regularnego przesyłania strumieniowego (zarówno pełnego, jak i przyrostowego) dla operacyjnych kopii zapasowych.
Note
Rozszerzony rozkaz zwykle dba o opróżnienie wszystkich transakcji dziennika będących w trakcie przesyłania do miejsca docelowego kopii zapasowej dziennika przed wyciszeniem bazy danych w celu utworzenia migawki. W wyniku tego migawki są zgodne z bazą danych i niezawodne podczas odzyskiwania.
Strategia odzyskiwania
Po utworzeniu migawek spójnych na poziomie bazy danych i przesyłaniu kopii zapasowych dziennika do woluminu NFS strategia odzyskiwania bazy danych może korzystać z funkcji odzyskiwania kopii zapasowych maszyn wirtualnych platformy Azure. Możliwość tworzenia kopii zapasowych dzienników jest również stosowana przy użyciu klienta bazy danych. Poniżej przedstawiono następujące opcje strategii odzyskiwania:
- Utwórz nowe maszyny wirtualne z punktu odzyskiwania, który jest spójny z bazą danych. Maszyna wirtualna powinna już mieć połączony punkt instalacji dziennika. Użyj klientów bazy danych, aby uruchamiać polecenia odzyskiwania na potrzeby odzyskiwania do punktu w czasie.
- Utwórz dyski z punktu odzyskiwania zgodnego z bazą danych i dołącz je do innej maszyny wirtualnej. Następnie zamontuj miejsce docelowe logowania i użyj klientów bazy danych do uruchamiania poleceń odzyskiwania na potrzeby odzyskiwania w określonym punkcie czasowym.
- Użyj opcji odzyskiwania plików i wygeneruj skrypt. Uruchom skrypt na docelowej maszynie wirtualnej i dołącz punkt odzyskiwania jako dyski iSCSI. Następnie użyj klientów bazy danych, aby uruchomić funkcje weryfikacji specyficzne dla bazy danych na dołączonych dyskach i zweryfikować dane kopii zapasowej. Ponadto należy użyć klientów bazy danych, aby wyeksportować lub odzyskać kilka tabel lub plików zamiast odzyskiwać całą bazę danych.
- Użyj funkcji przywracania między regionami, aby wykonać poprzednie akcje z pomocniczych sparowanych regionów podczas regionalnej awarii.
Summary
Dzięki migawkom zgodnym ze spójnością bazy danych oraz dziennikom tworzonym przy użyciu rozwiązania niestandardowego, można zbudować rozwiązanie do wykonywania kopii zapasowych bazy danych, które jest wydajne i ekonomiczne. To rozwiązanie korzysta z zalet tworzenia kopii zapasowych maszyn wirtualnych platformy Azure, a także ponownie używa możliwości klientów bazy danych.