Samouczek: konfigurowanie partii danych
Z tego samouczka dowiesz się, jak skonfigurować już wdrożone usługi produktów danych. Usługa Azure Data Factory umożliwia integrowanie i organizowanie danych oraz używanie usługi Microsoft Purview do odnajdywania zasobów danych i zarządzania nimi oraz zarządzania nimi.
Instrukcje:
- Tworzenie i wdrażanie wymaganych zasobów
- Przypisywanie ról i uprawnień dostępu
- Połączenie zasobów na potrzeby integracji danych
Ten samouczek ułatwia zapoznanie się z usługami wdrożonymi w przykładowej <DMLZ-prefix>-dev-dp001 grupie zasobów produktu danych. Dowiedz się, jak interfejs usług platformy Azure ze sobą i jakie są środki zabezpieczeń.
Podczas wdrażania nowych składników będziesz mieć możliwość zbadania sposobu łączenia ładu usługi Purview w celu utworzenia całościowej, aktualnej mapy krajobrazu danych. Wynikiem jest automatyczne odnajdywanie danych, klasyfikacja poufnych danych i kompleksowe pochodzenie danych.
Wymagania wstępne
Przed rozpoczęciem konfigurowania partii produktów danych upewnij się, że zostały spełnione następujące wymagania wstępne:
Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, utwórz bezpłatne konto platformy Azure już dziś.
Uprawnienia do subskrypcji platformy Azure. Aby skonfigurować usługę Purview i usługę Azure Synapse Analytics na potrzeby wdrożenia, musisz mieć rolę Administracja istratora dostępu użytkowników lub rolę Właściciel w subskrypcji platformy Azure. W tym samouczku ustawisz więcej przypisań ról dla usług i jednostek usługi.
Wdrożone zasoby. Aby ukończyć samouczek, te zasoby muszą być już wdrożone w ramach subskrypcji platformy Azure:
- Strefa docelowa zarządzania danymi. Aby uzyskać więcej informacji, zobacz repozytorium GitHub strefy docelowej zarządzania danymi.
- Strefa docelowa danych. Aby uzyskać więcej informacji, zobacz repozytorium GitHub strefy docelowej danych.
- Dane wsadowe. Aby uzyskać więcej informacji, zobacz repozytorium GitHub wsadowe dane.
Konto usługi Microsoft Purview. Konto jest tworzone w ramach wdrożenia strefy docelowej zarządzania danymi.
Własne środowisko Integration Runtime. Środowisko uruchomieniowe jest tworzone w ramach wdrożenia strefy docelowej danych.
Uwaga
W tym samouczku symbole zastępcze odwołują się do zasobów wstępnych wdrażanych przed rozpoczęciem samouczka:
<DMLZ-prefix>odwołuje się do prefiksu wprowadzonego podczas tworzenia wdrożenia strefy docelowej zarządzania danymi.<DLZ-prefix>odwołuje się do prefiksu wprowadzonego podczas tworzenia wdrożenia strefy docelowej danych.<DP-prefix>odnosi się do prefiksu wprowadzonego podczas tworzenia wdrożenia wsadowego produktu danych.
Tworzenie wystąpień usługi Azure SQL Database
Aby rozpocząć pracę z tym samouczkiem, utwórz dwa przykładowe wystąpienia usługi SQL Database. Bazy danych będą używane do symulowania źródeł danych CRM i ERP w kolejnych sekcjach.
W witrynie Azure Portal w obszarze kontrolek globalnych portalu wybierz ikonę usługi Cloud Shell , aby otworzyć terminal usługi Azure Cloud Shell. Wybierz pozycję Bash jako typ terminalu.

W usłudze Cloud Shell uruchom następujący skrypt. Skrypt znajduje grupę
<DLZ-prefix>-dev-dp001zasobów i<DP-prefix>-dev-sqlserver001serwer Azure SQL, który znajduje się w grupie zasobów. Następnie skrypt tworzy dwa wystąpienia usługi SQL Database na<DP-prefix>-dev-sqlserver001serwerze. Bazy danych są wstępnie wypełniane przykładowymi danymi AdventureWorks. Dane obejmują tabele używane w tym samouczku.Upewnij się, że zastąpisz wartość symbolu zastępczego parametru
subscriptionwłasnym identyfikatorem subskrypcji platformy Azure.# Azure SQL Database instances setup # Create the AdatumCRM and AdatumERP databases to simulate customer and sales data. # Use the ID for the Azure subscription you used to deployed the data product. az account set --subscription "<your-subscription-ID>" # Get the resource group for the data product. resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, 'dp001')==\`true\`].name") # Get the existing Azure SQL Database server name. sqlServerName=$(az sql server list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'sqlserver001')==\`true\`].name") # Create the first SQL Database instance, AdatumCRM, to create the customer's data source. az sql db create --resource-group $resourceGroupName --server $sqlServerName --name AdatumCRM --service-objective Basic --sample-name AdventureWorksLT # Create the second SQL Database instance, AdatumERP, to create the sales data source. az sql db create --resource-group $resourceGroupName --server $sqlServerName --name AdatumERP --service-objective Basic --sample-name AdventureWorksLT
Po zakończeniu działania skryptu <DP-prefix>-dev-sqlserver001 na serwerze Azure SQL istnieją dwa nowe wystąpienia usługi SQL Database i AdatumCRM AdatumERP. Obie bazy danych znajdują się w warstwie obliczeniowej Podstawowa. Bazy danych znajdują się w tej samej <DLZ-prefix>-dev-dp001 grupie zasobów, która została użyta do wdrożenia partii produktu danych.
Konfigurowanie usługi Purview w celu wykazu partii danych produktu
Następnie wykonaj kroki konfigurowania usługi Purview w celu wykazu partii danych. Zacznij od utworzenia jednostki usługi. Następnie skonfigurujesz wymagane zasoby i przypiszesz role i uprawnienia dostępu.
Tworzenie jednostki usługi
W witrynie Azure Portal w obszarze kontrolek globalnych portalu wybierz ikonę usługi Cloud Shell , aby otworzyć terminal usługi Azure Cloud Shell. Wybierz pozycję Bash jako typ terminalu.
Popraw następujący skrypt:
- Zastąp wartość symbolu zastępczego parametru
subscriptionIdwłasnym identyfikatorem subskrypcji platformy Azure. - Zastąp wartość symbolu zastępczego
spnameparametru nazwą, której chcesz użyć dla jednostki usługi. Nazwa główna usługi musi być unikatowa w subskrypcji.
Po zaktualizowaniu wartości parametrów uruchom skrypt w usłudze Cloud Shell.
# Replace the parameter values with the name you want to use for your service principal name and your Azure subscription ID. spname="<your-service-principal-name>" subscriptionId="<your-subscription-id>" # Set the scope to the subscription. scope="/subscriptions/$subscriptionId" # Create the service principal. az ad sp create-for-rbac \ --name $spname \ --role "Contributor" \ --scope $scope- Zastąp wartość symbolu zastępczego parametru
Sprawdź dane wyjściowe JSON, aby uzyskać wynik podobny do poniższego przykładu. Zanotuj lub skopiuj wartości w danych wyjściowych, aby użyć ich w kolejnych krokach.
{ "appId": "<your-app-id>", "displayName": "<service-principal-display-name>", "name": "<your-service-principal-name>", "password": "<your-service-principal-password>", "tenant": "<your-tenant>" }
Konfigurowanie dostępu i uprawnień jednostki usługi
Z danych wyjściowych JSON wygenerowanych w poprzednim kroku uzyskaj następujące zwrócone wartości:
- Identyfikator jednostki usługi (
appId) - Klucz jednostki usługi (
password)
Jednostka usługi musi mieć następujące uprawnienia:
- Rola Czytelnik danych obiektu blob usługi Storage na kontach magazynu.
- Uprawnienia czytelnika danych w wystąpieniach usługi SQL Database.
Aby skonfigurować jednostkę usługi z wymaganą rolą i uprawnieniami, wykonaj następujące kroki.
Uprawnienia konta usługi Azure Storage
W witrynie Azure Portal przejdź do
<DLZ-prefix>devrawkonta usługi Azure Storage. W menu zasobów wybierz pozycję Kontrola dostępu (Zarządzanie dostępem i tożsamościami).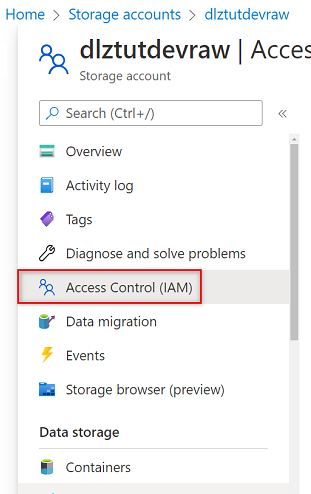
Wybierz pozycję Dodaj>Dodaj przypisanie roli.
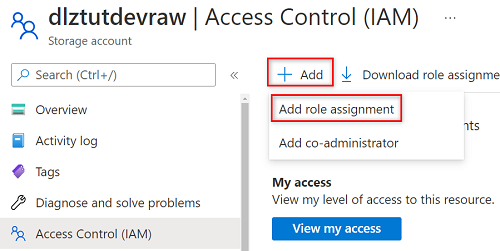
W obszarze Dodawanie przypisania roli na karcie Rola wyszukaj i wybierz pozycję Czytelnik danych obiektu blob usługi Storage. Następnie wybierz Dalej.
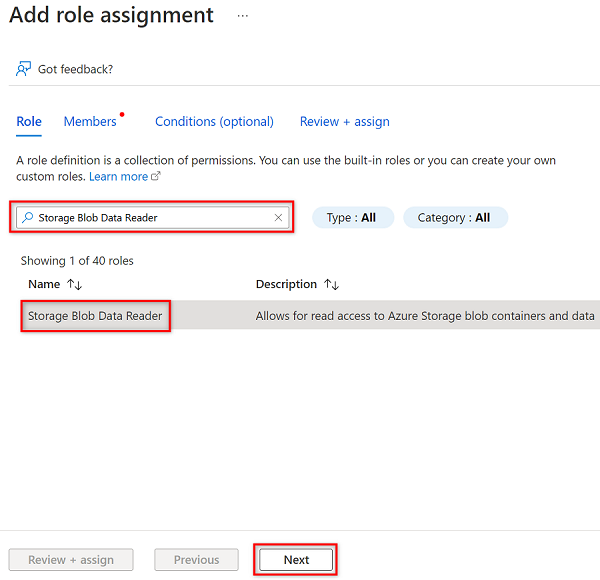
W obszarze Członkowie wybierz pozycję Wybierz członków.
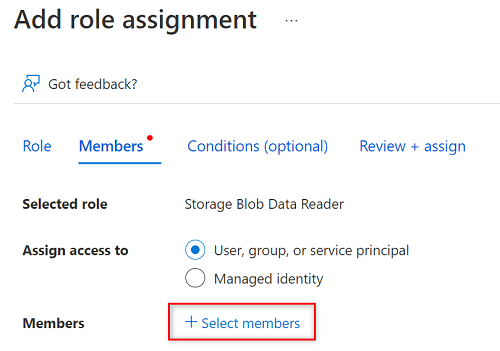
W obszarze Wybierz członków wyszukaj nazwę utworzonej jednostki usługi.

W wynikach wyszukiwania wybierz jednostkę usługi, a następnie wybierz pozycję Wybierz.
Aby ukończyć przypisanie roli, wybierz dwukrotnie pozycję Przejrzyj i przypisz .
Powtórz kroki opisane w tej sekcji dla pozostałych kont magazynu:
<DLZ-prefix>devencur<DLZ-prefix>devwork
Uprawnienia usługi SQL Database
Aby ustawić uprawnienia usługi SQL Database, nawiąż połączenie z maszyną wirtualną Usługi Azure SQL przy użyciu edytora zapytań. Ponieważ wszystkie zasoby znajdują się za prywatnym punktem końcowym, musisz najpierw zalogować się do witryny Azure Portal przy użyciu maszyny wirtualnej hosta usługi Azure Bastion.
W witrynie Azure Portal nawiąż połączenie z maszyną wirtualną wdrożną w <DMLZ-prefix>-dev-bastion grupie zasobów. Jeśli nie masz pewności, jak nawiązać połączenie z maszyną wirtualną przy użyciu usługi hosta bastionu, zobacz Połączenie z maszyną wirtualną.
Aby dodać jednostkę usługi jako użytkownika w bazie danych, może być konieczne dodanie siebie jako administratora firmy Microsoft Entra. W krokach 1 i 2 dodaj siebie jako administratora firmy Microsoft Entra. W krokach od 3 do 5 nadasz jednostce usługi uprawnienia do bazy danych. Po zalogowaniu się do portalu z maszyny wirtualnej hosta usługi Bastion wyszukaj maszyny wirtualne Azure SQL w witrynie Azure Portal.
Przejdź do maszyny
<DP-prefix>-dev-sqlserver001wirtualnej usługi Azure SQL. W menu zasobów w obszarze Ustawienia wybierz pozycję Microsoft Entra ID.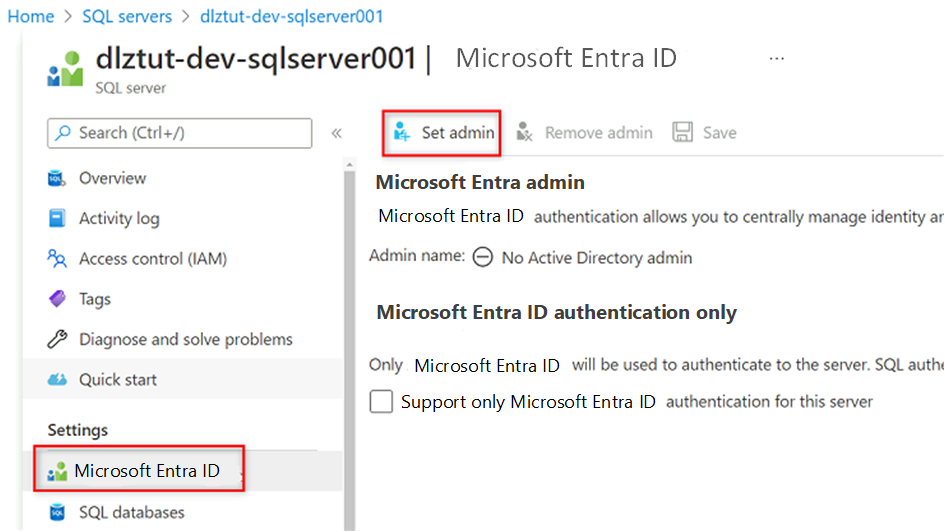
Na pasku poleceń wybierz pozycję Ustaw administratora. Wyszukaj i wybierz własne konto. Naciśnij przycisk Wybierz.
W menu zasobów wybierz pozycję Bazy danych SQL, a następnie wybierz
AdatumCRMbazę danych.
W menu zasobów AdatumCRM wybierz pozycję Edytor zapytań (wersja zapoznawcza). W obszarze Uwierzytelnianie usługi Active Directory wybierz przycisk Kontynuuj jako , aby się zalogować.
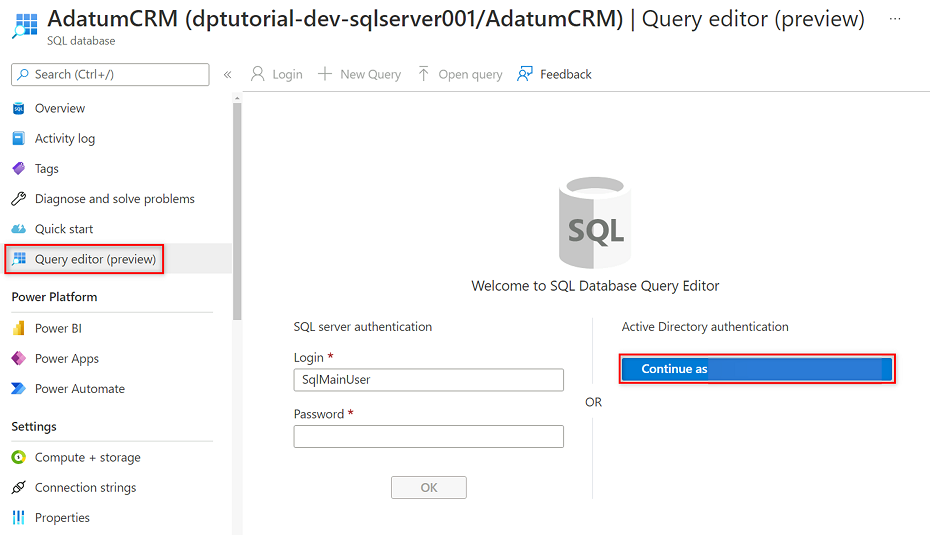
W edytorze zapytań popraw następujące instrukcje, aby zastąpić
<service principal name>ciąg nazwą utworzonej jednostki usługi (na przykładpurview-service-principal). Następnie uruchom instrukcje .CREATE USER [<service principal name>] FROM EXTERNAL PROVIDER GO EXEC sp_addrolemember 'db_datareader', [<service principal name>] GO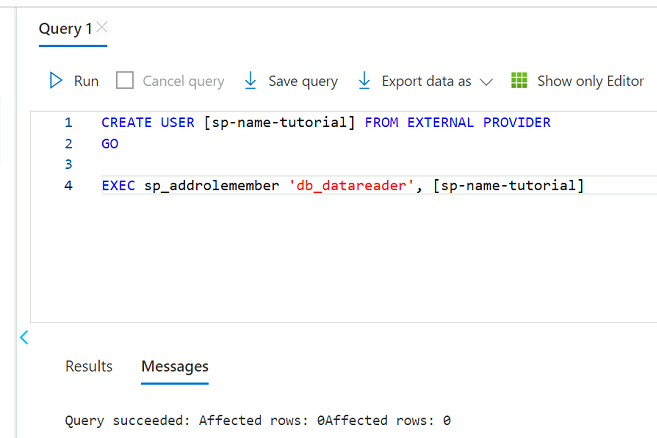
Powtórz kroki od 3 do 5 dla AdatumERP bazy danych.
Konfigurowanie magazynu kluczy
Usługa Purview odczytuje klucz jednostki usługi z wystąpienia usługi Azure Key Vault. Magazyn kluczy jest tworzony we wdrożeniu strefy docelowej zarządzania danymi. Do skonfigurowania magazynu kluczy wymagane są następujące kroki:
Dodaj klucz jednostki usługi do magazynu kluczy jako wpis tajny.
Nadaj czytelnikowi wpisów tajnych msi usługi Purview uprawnienia w magazynie kluczy.
Dodaj magazyn kluczy do usługi Purview jako połączenie magazynu kluczy.
Utwórz poświadczenie w usłudze Purview wskazujące wpis tajny magazynu kluczy.
Dodawanie uprawnień do dodawania wpisu tajnego do magazynu kluczy
W witrynie Azure Portal przejdź do usługi Azure Key Vault.
<DMLZ-prefix>-dev-vault001Wyszukaj magazyn kluczy.
W menu zasobów wybierz pozycję Kontrola dostępu (Zarządzanie dostępem i tożsamościami). Na pasku poleceń wybierz pozycję Dodaj, a następnie wybierz pozycję Dodaj przypisanie roli.
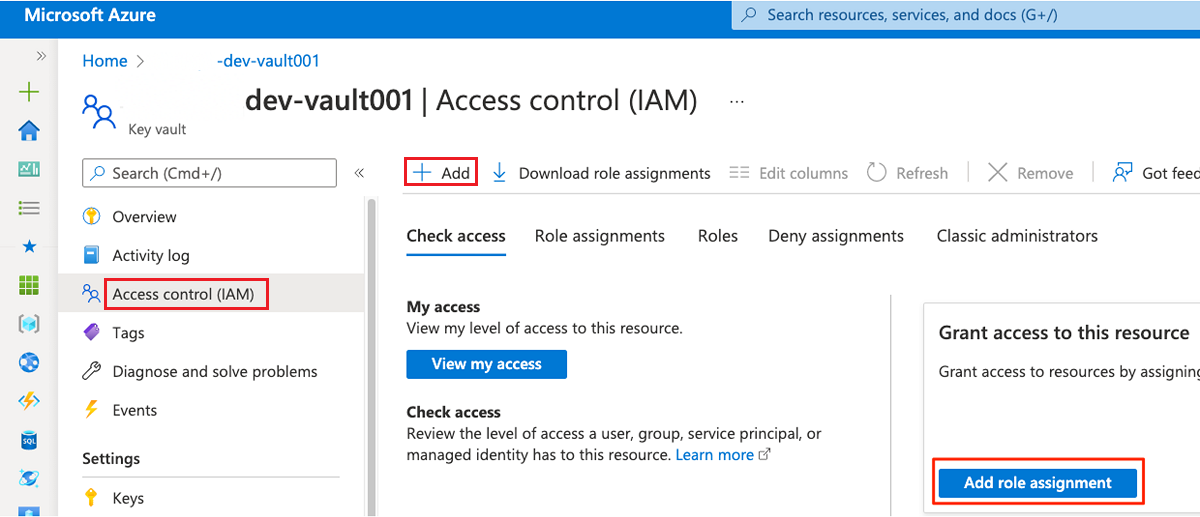
Na karcie Rola wyszukaj, a następnie wybierz pozycję Key Vault Administracja istrator. Wybierz Dalej.
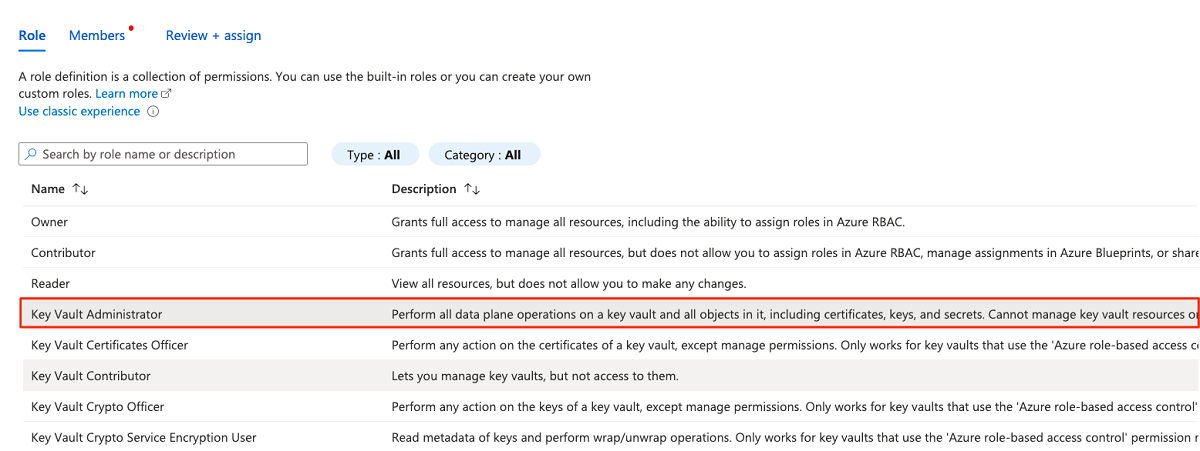
W obszarze Członkowie wybierz pozycję Wybierz członków , aby dodać aktualnie zalogowane konto.
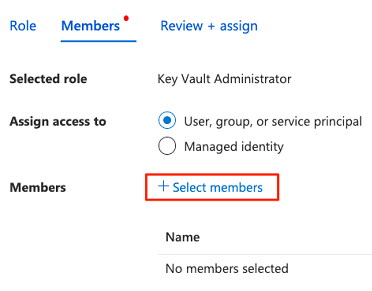
W obszarze Wybierz członków wyszukaj aktualnie zalogowane konto. Wybierz konto, a następnie wybierz pozycję Wybierz.
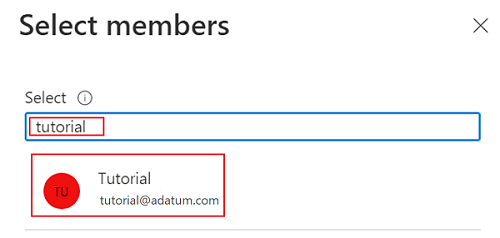
Aby ukończyć proces przypisywania roli, wybierz dwukrotnie pozycję Przejrzyj i przypisz .
Dodawanie wpisu tajnego do magazynu kluczy
Wykonaj poniższe kroki, aby zalogować się do witryny Azure Portal z maszyny wirtualnej hosta usługi Bastion.
<DMLZ-prefix>-dev-vault001W menu zasobów magazynu kluczy wybierz pozycję Wpisy tajne. Na pasku poleceń wybierz pozycję Generuj/Importuj , aby utworzyć nowy wpis tajny.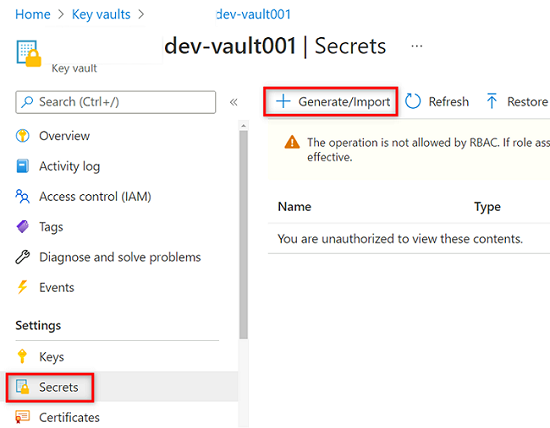
W obszarze Tworzenie wpisu tajnego wybierz lub wprowadź następujące wartości:
Ustawienie Akcja Opcje przekazywania Wybierz pozycję Ręczne. Nazwa/nazwisko Wprowadź wartość service-principal-secret. Wartość Wprowadź utworzone wcześniej hasło jednostki usługi. 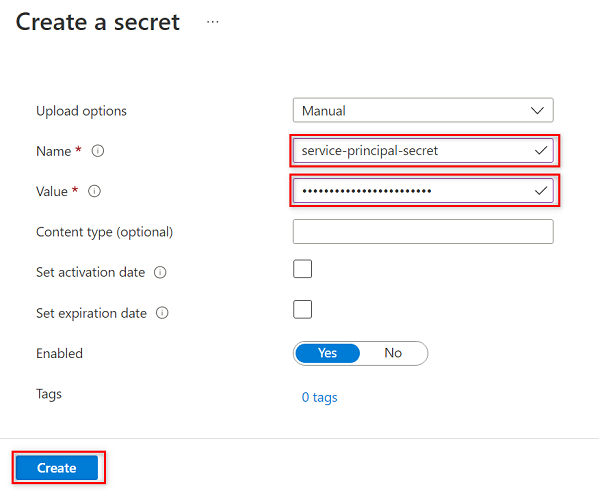
Uwaga
Ten krok tworzy wpis tajny o nazwie
service-principal-secretw magazynie kluczy przy użyciu klucza hasła jednostki usługi. Usługa Purview używa wpisu tajnego do nawiązywania połączenia z źródłami danych i skanowania ich. Jeśli wprowadzisz nieprawidłowe hasło, nie będzie można ukończyć poniższych sekcji.Wybierz pozycję Utwórz.
Konfigurowanie uprawnień usługi Purview w magazynie kluczy
Aby wystąpienie usługi Purview odczytywało wpisy tajne przechowywane w magazynie kluczy, należy przypisać usłudze Purview odpowiednie uprawnienia w magazynie kluczy. Aby ustawić uprawnienia, należy dodać tożsamość zarządzaną usługi Purview do roli Czytelnik wpisów tajnych magazynu kluczy.
<DMLZ-prefix>-dev-vault001W menu zasobów magazynu kluczy wybierz pozycję Kontrola dostępu (Zarządzanie dostępem i tożsamościami).Na pasku poleceń wybierz pozycję Dodaj, a następnie wybierz pozycję Dodaj przypisanie roli.
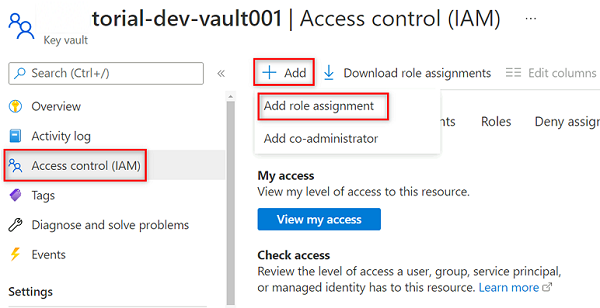
W obszarze Rola wyszukaj i wybierz pozycję Użytkownik wpisów tajnych usługi Key Vault. Wybierz Dalej.
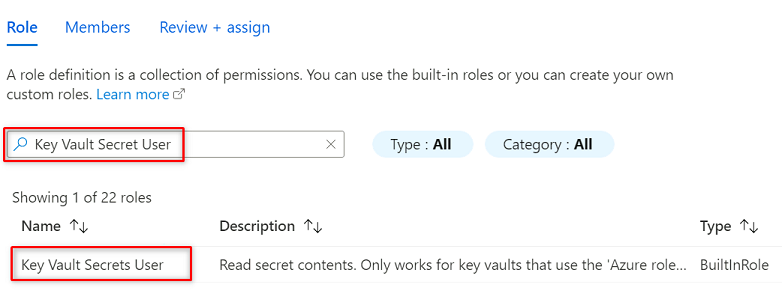
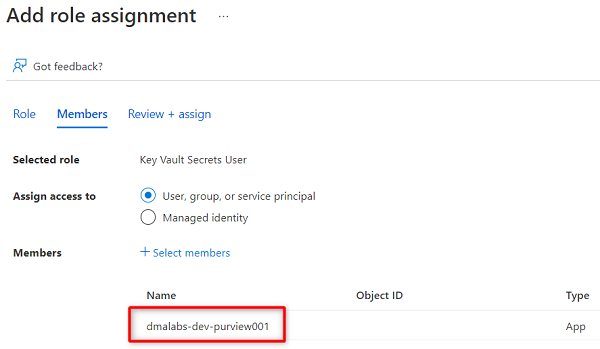
W obszarze Członkowie wybierz pozycję Wybierz członków.
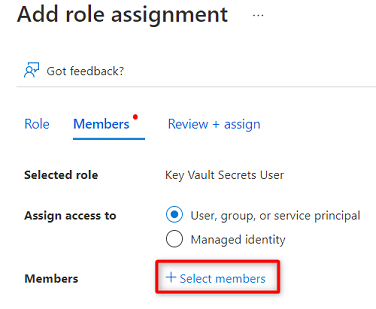
Wyszukaj wystąpienie usługi
<DMLZ-prefix>-dev-purview001Purview. Wybierz wystąpienie, aby dodać odpowiednie konto. Następnie wybierz pozycję Wybierz.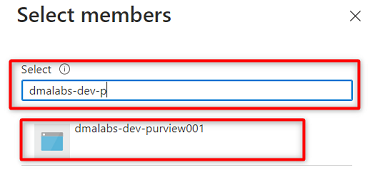
Aby ukończyć proces przypisywania roli, wybierz dwukrotnie pozycję Przejrzyj i przypisz .
Konfigurowanie połączenia magazynu kluczy w usłudze Purview
Aby skonfigurować połączenie magazynu kluczy z usługą Purview, musisz zalogować się do witryny Azure Portal przy użyciu maszyny wirtualnej hosta usługi Azure Bastion.
W witrynie Azure Portal przejdź do
<DMLZ-prefix>-dev-purview001konta usługi Purview. W obszarze Wprowadzenie w obszarze Otwórz portal ładu usługi Microsoft Purview wybierz pozycję Otwórz.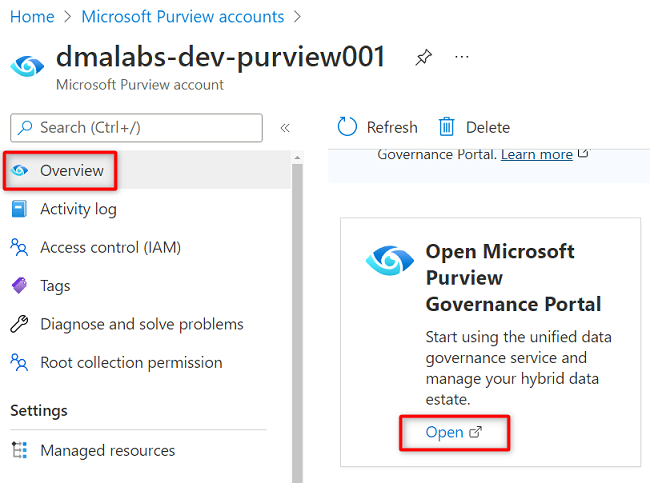
W programie Purview Studio wybierz pozycję Poświadczenia zarządzania>. Na pasku poleceń Poświadczenia wybierz pozycję Zarządzaj połączeniami usługi Key Vault, a następnie wybierz pozycję Nowy.
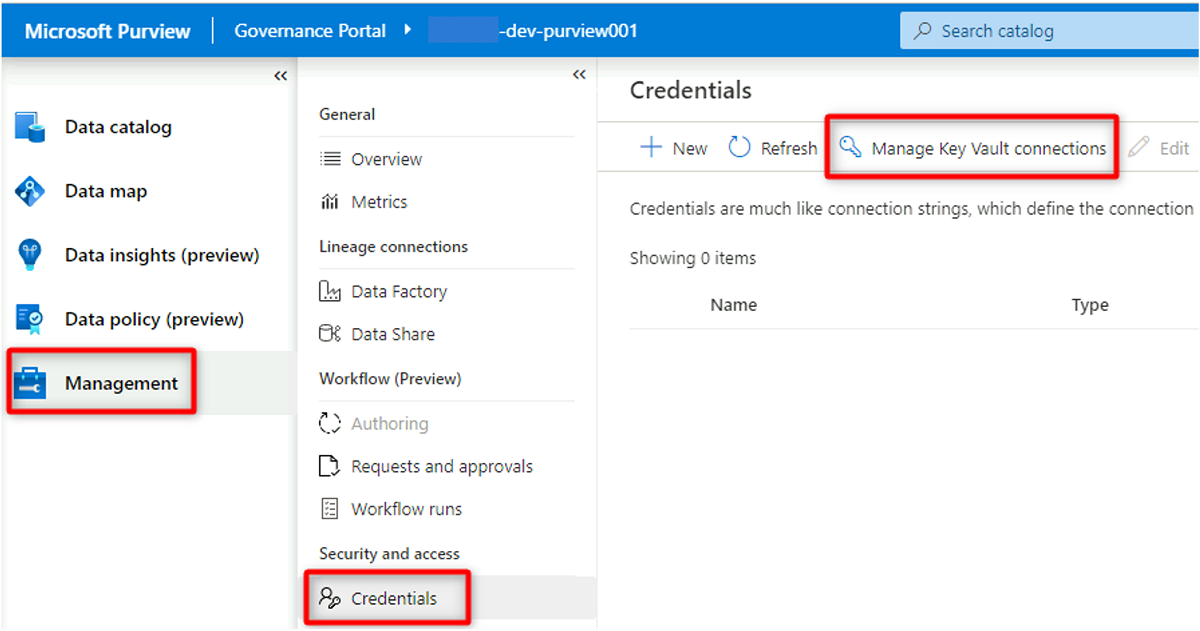
W obszarze Nowe połączenie magazynu kluczy wybierz lub wprowadź następujące informacje:
Ustawienie Akcja Nazwa/nazwisko Wprowadź DMLZ-prefix-dev-vault001><. Subskrypcja platformy Azure Wybierz subskrypcję, która hostuje magazyn kluczy. Nazwa magazynu kluczy <Wybierz magazyn kluczy DMLZ-prefiks-dev-vault001>. 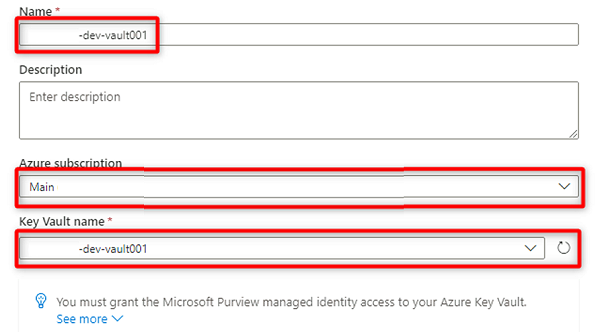
Wybierz pozycję Utwórz.
W obszarze Potwierdzanie udzielania dostępu wybierz pozycję Potwierdź.
Tworzenie poświadczeń w usłudze Purview
Ostatnim krokiem konfigurowania magazynu kluczy jest utworzenie poświadczenia w usłudze Purview wskazującego wpis tajny utworzony w magazynie kluczy dla jednostki usługi.
W programie Purview Studio wybierz pozycję Poświadczenia zarządzania>. Na pasku poleceń Poświadczenia wybierz pozycję Nowy.
W obszarze Nowe poświadczenie wybierz lub wprowadź następujące informacje:
Ustawienie Akcja Nazwa/nazwisko Wprowadź wartość purviewServicePrincipal. Metoda uwierzytelniania Wybierz pozycję Jednostka usługi. Identyfikator dzierżawy Wartość jest wypełniana automatycznie. Identyfikator jednostki usługi Wprowadź identyfikator aplikacji lub identyfikator klienta jednostki usługi. Połączenie usługi Key Vault Wybierz połączenie magazynu kluczy utworzone w poprzedniej sekcji. Nazwa wpisu tajnego Wprowadź nazwę wpisu tajnego w magazynie kluczy (service-principal-secret). 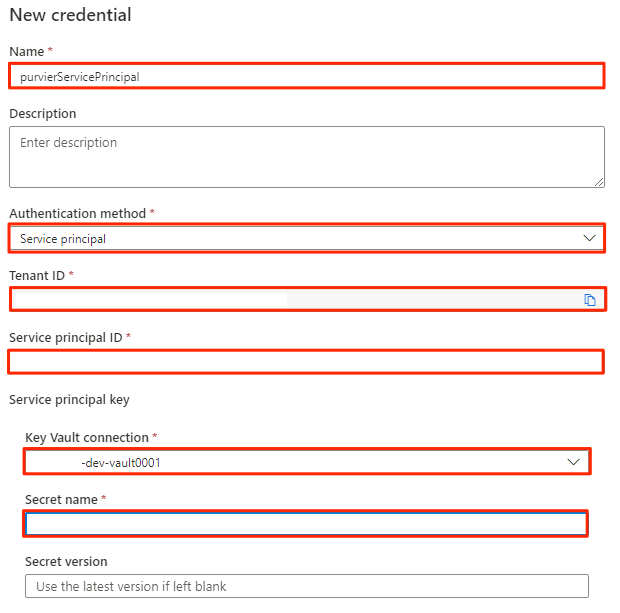
Wybierz pozycję Utwórz.
Rejestrowanie źródeł danych
W tym momencie usługa Purview może nawiązać połączenie z jednostką usługi. Teraz możesz zarejestrować i skonfigurować źródła danych.
Rejestrowanie kont usługi Azure Data Lake Storage Gen2
W poniższych krokach opisano proces rejestrowania konta magazynu usługi Azure Data Lake Storage Gen2.
W programie Purview Studio wybierz ikonę mapy danych, wybierz pozycję Źródła, a następnie wybierz pozycję Zarejestruj.
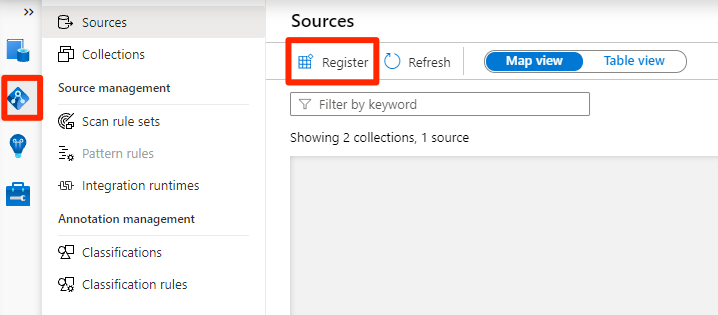
W obszarze Rejestrowanie źródeł wybierz pozycję Azure Data Lake Storage Gen2, a następnie wybierz pozycję Kontynuuj.

W obszarze Register sources (Azure Data Lake Storage Gen2) (Rejestrowanie źródeł (Azure Data Lake Storage Gen2) wybierz lub wprowadź następujące informacje:
Ustawienie Akcja Nazwa/nazwisko Wprowadź ciąg <DLZ-prefiks>dldevraw. Subskrypcja platformy Azure Wybierz subskrypcję, która hostuje konto magazynu. Nazwa konta magazynu Wybierz odpowiednie konto magazynu. Punkt końcowy Wartość jest wypełniana automatycznie na podstawie wybranego konta magazynu. Wybieranie kolekcji Wybierz kolekcję główną. 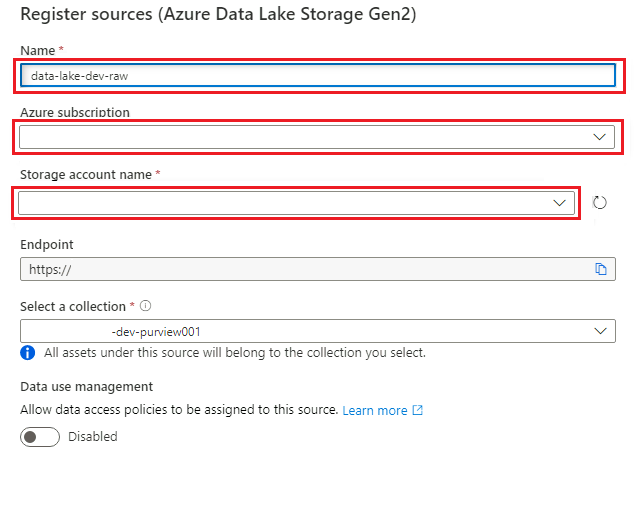
Wybierz pozycję Zarejestruj , aby utworzyć źródło danych.
Powtórz następujące kroki dla następujących kont magazynu:
<DMLZ-prefix>devencur<DMLZ-prefix>devwork
Rejestrowanie wystąpienia usługi SQL Database jako źródła danych
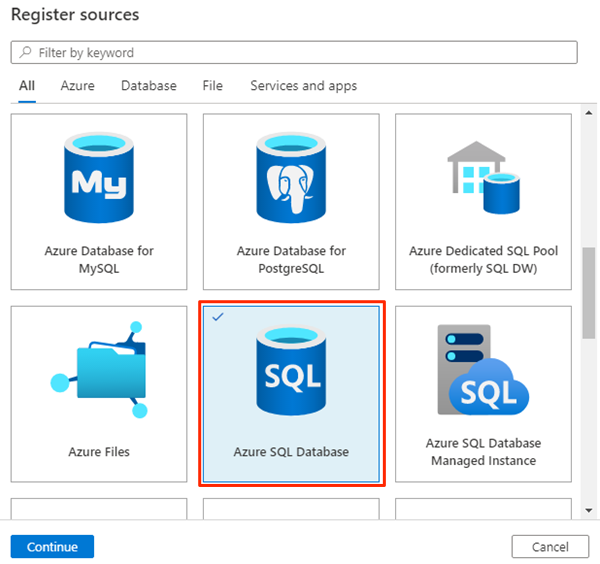
W programie Purview Studio wybierz ikonę Mapa danych, wybierz pozycję Źródła, a następnie wybierz pozycję Zarejestruj.
W obszarze Rejestrowanie źródeł wybierz pozycję Azure SQL Database, a następnie wybierz pozycję Kontynuuj.
W obszarze Register sources (Azure SQL Database) (Rejestrowanie źródeł (Azure SQL Database) wybierz lub wprowadź następujące informacje:
Ustawienie Akcja Nazwa/nazwisko Wprowadź sqlDatabase (nazwa bazy danych utworzonej w obszarze Tworzenie wystąpień usługi Azure SQL Database). Subskrypcja Wybierz subskrypcję, która hostuje bazę danych. Nazwa serwera Wprowadź wartość DP-prefix-dev-sqlserver001>.< 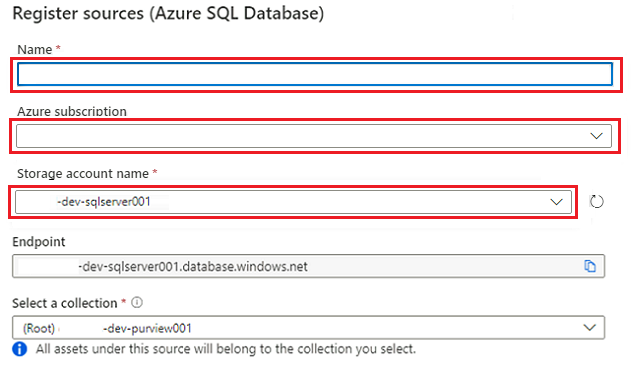
Wybierz pozycję Zarejestruj.
Konfigurowanie skanowania
Następnie skonfiguruj skanowanie źródeł danych.
Skanowanie źródła danych usługi Data Lake Storage Gen2
W programie Purview Studio przejdź do mapy danych. W źródle danych wybierz ikonę Nowe skanowanie .
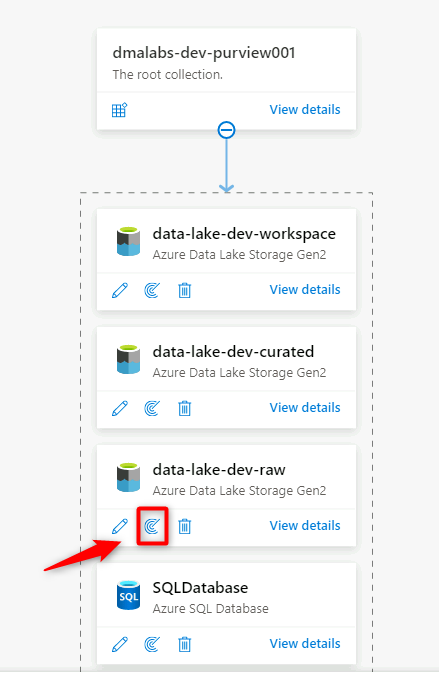
W nowym okienku skanowania wybierz lub wprowadź następujące informacje:
Ustawienie Akcja Nazwa/nazwisko Wprowadź Scan_<DLZ-prefiks>devraw. Połączenie za pośrednictwem środowiska Integration Runtime Wybierz własne środowisko Integration Runtime wdrożone ze strefą docelową danych. Poświadczeń Wybierz jednostkę usługi skonfigurowaną dla usługi Purview. 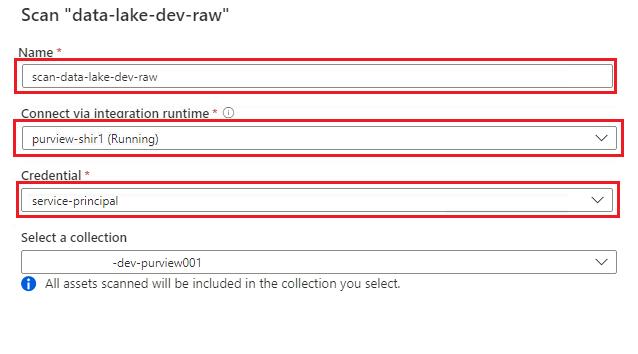
Wybierz pozycję Testuj połączenie , aby zweryfikować łączność i czy uprawnienia są spełnione. Wybierz Kontynuuj.
W obszarze Zakres skanowania wybierz całe konto magazynu jako zakres skanowania, a następnie wybierz pozycję Kontynuuj.
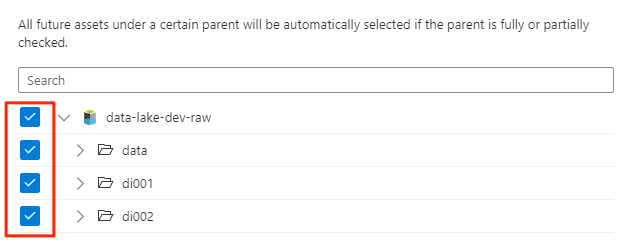
W obszarze Wybierz zestaw reguł skanowania wybierz pozycję AdlsGen2, a następnie wybierz pozycję Kontynuuj.
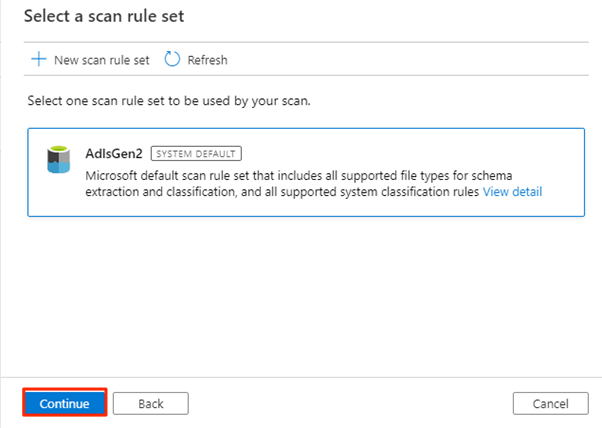
W obszarze Ustaw wyzwalacz skanowania wybierz pozycję Raz, a następnie wybierz pozycję Kontynuuj.
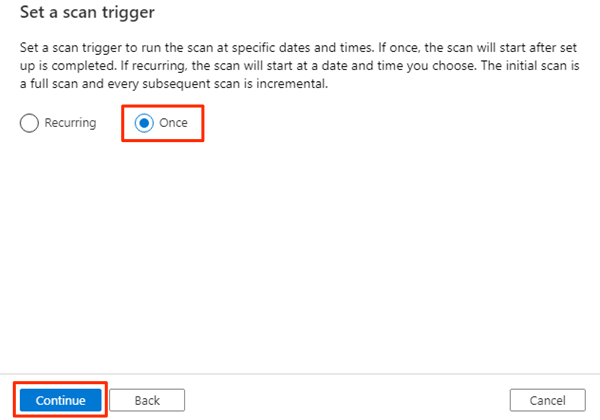
W obszarze Przejrzyj skanowanie przejrzyj ustawienia skanowania. Wybierz pozycję Zapisz i uruchom , aby rozpocząć skanowanie.
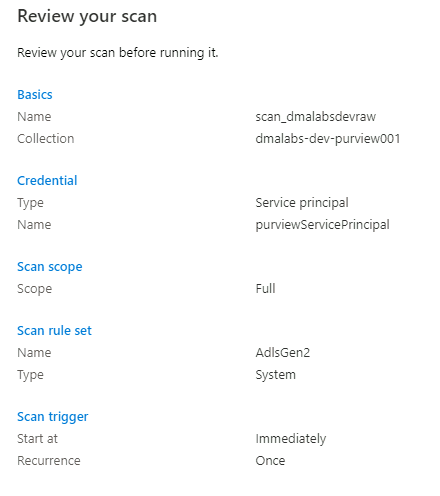
Powtórz następujące kroki dla następujących kont magazynu:
<DMLZ-prefix>devencur<DMLZ-prefix>devwork
Skanowanie źródła danych usługi SQL Database
W źródle danych usługi Azure SQL Database wybierz pozycję Nowe skanowanie.
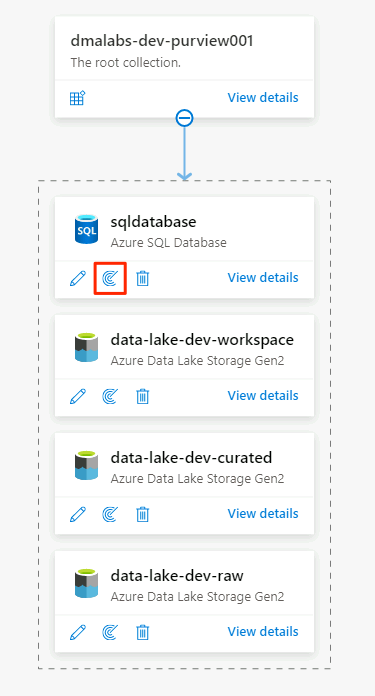
W nowym okienku skanowania wybierz lub wprowadź następujące informacje:
Ustawienie Akcja Nazwa/nazwisko Wprowadź Scan_Database001. Połączenie za pośrednictwem środowiska Integration Runtime Wybierz pozycję Purview-SHIR. Nazwa bazy danych Wybierz nazwę bazy danych. Poświadczeń Wybierz poświadczenia magazynu kluczy utworzone w usłudze Purview. Wyodrębnianie pochodzenia (wersja zapoznawcza) Wybierz pozycję Wyłączone. 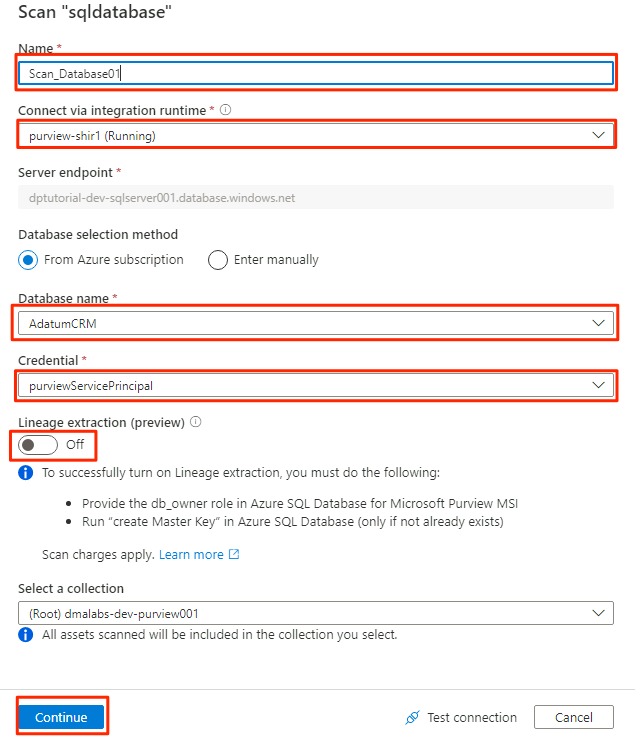
Wybierz pozycję Testuj połączenie , aby zweryfikować łączność i czy uprawnienia są spełnione. Wybierz Kontynuuj.
Wybierz zakres skanowania. Aby przeskanować całą bazę danych, użyj wartości domyślnej.
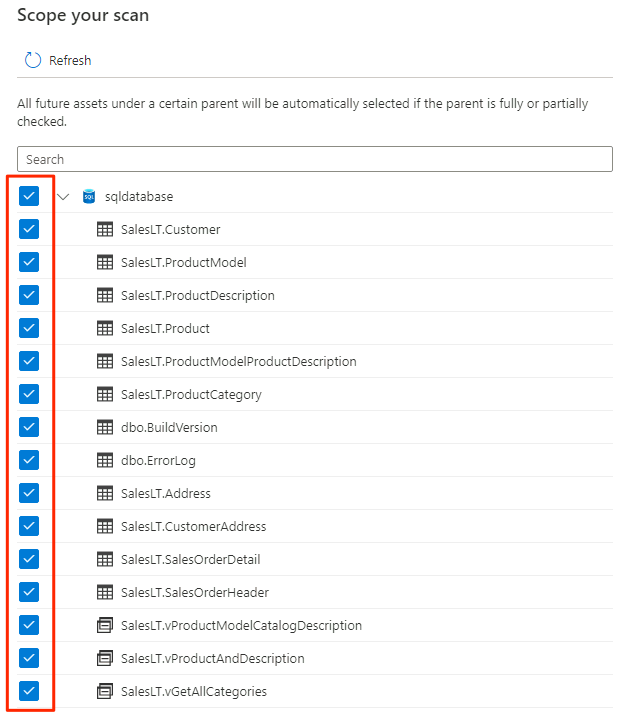
W obszarze Wybierz zestaw reguł skanowania wybierz pozycję AzureSqlDatabase, a następnie wybierz pozycję Kontynuuj.
W obszarze Ustaw wyzwalacz skanowania wybierz pozycję Raz, a następnie wybierz pozycję Kontynuuj.
W obszarze Przejrzyj skanowanie przejrzyj ustawienia skanowania. Wybierz pozycję Zapisz i uruchom , aby rozpocząć skanowanie.
Powtórz te kroki dla AdatumERP bazy danych.
Usługa Purview jest teraz skonfigurowana w celu zapewnienia ładu danych dla zarejestrowanych źródeł danych.
Kopiowanie danych usługi SQL Database do usługi Data Lake Storage Gen2
W poniższych krokach użyjesz narzędzia do kopiowania danych w usłudze Data Factory, aby utworzyć potok, aby skopiować tabele z wystąpień AdatumCRM usługi SQL Database i AdatumERP do plików CSV na <DLZ-prefix>devraw koncie usługi Data Lake Storage Gen2.
Środowisko jest zablokowane do dostępu publicznego, dlatego najpierw należy skonfigurować prywatne punkty końcowe. Aby użyć prywatnych punktów końcowych, zalogujesz się do witryny Azure Portal w przeglądarce lokalnej, a następnie połączysz się z maszyną wirtualną hosta usługi Bastion, aby uzyskać dostęp do wymaganych usług platformy Azure.
Tworzenie prywatnych punktów końcowych
Aby skonfigurować prywatne punkty końcowe dla wymaganych zasobów:
<DMLZ-prefix>-dev-bastionW grupie zasobów wybierz pozycję<DMLZ-prefix>-dev-vm001.
Na pasku poleceń wybierz pozycję Połączenie i wybierz pozycję Bastion.
Wprowadź nazwę użytkownika i hasło maszyny wirtualnej, a następnie wybierz pozycję Połączenie.
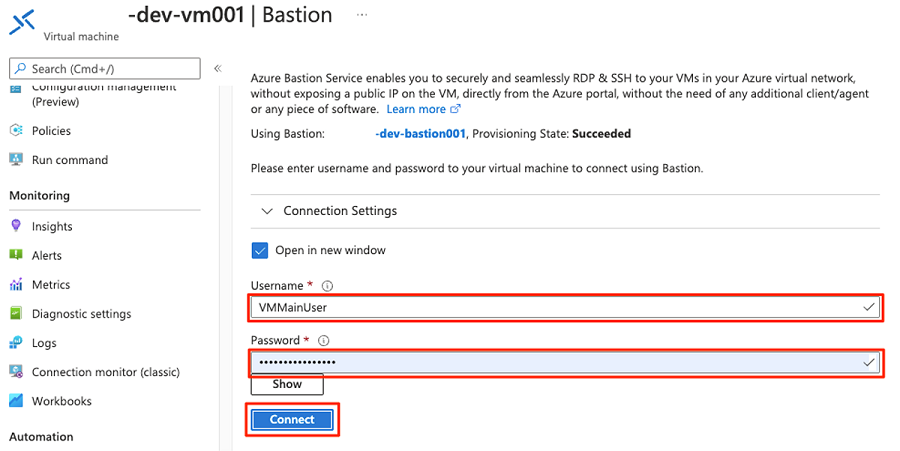
W przeglądarce internetowej maszyny wirtualnej przejdź do witryny Azure Portal. Przejdź do
<DLZ-prefix>-dev-shared-integrationgrupy zasobów i otwórz fabrykę<DLZ-prefix>-dev-integration-datafactory001danych.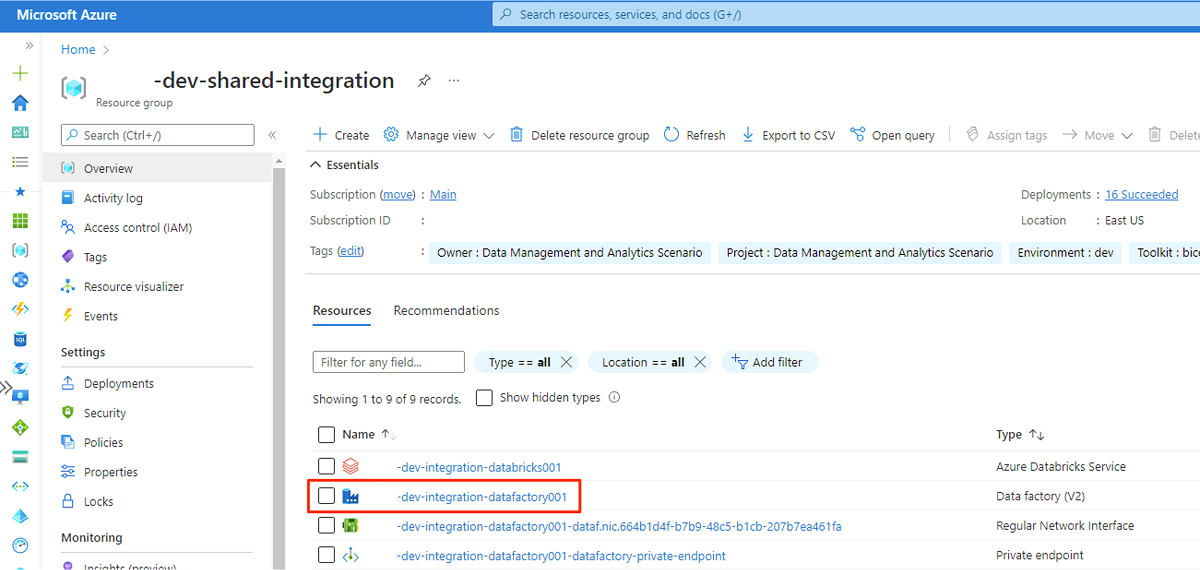
W obszarze Wprowadzenie w obszarze Otwórz program Azure Data Factory Studio wybierz pozycję Otwórz.
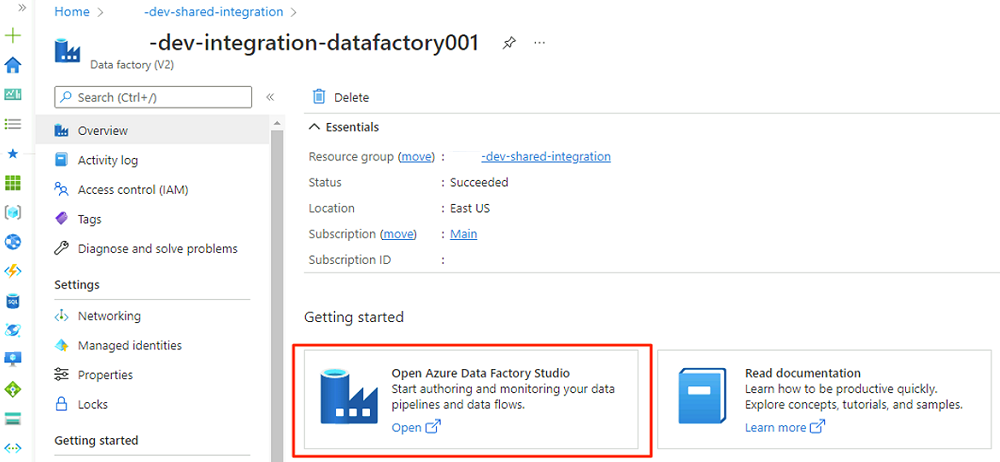
W menu Data Factory Studio wybierz ikonę Zarządzaj (ikona wygląda jak kwadratowy przybornik z zapieczętowaną kluczem). W menu zasobów wybierz pozycję Zarządzane prywatne punkty końcowe, aby utworzyć prywatne punkty końcowe wymagane do połączenia usługi Data Factory z innymi zabezpieczonymi usługami platformy Azure.
Zatwierdzanie żądań dostępu dla prywatnych punktów końcowych zostało omówione w dalszej sekcji. Po zatwierdzeniu żądań dostępu do prywatnego punktu końcowego ich stan zatwierdzenia to Zatwierdzone, jak w poniższym przykładzie
<DLZ-prefix>devencurkonta magazynu.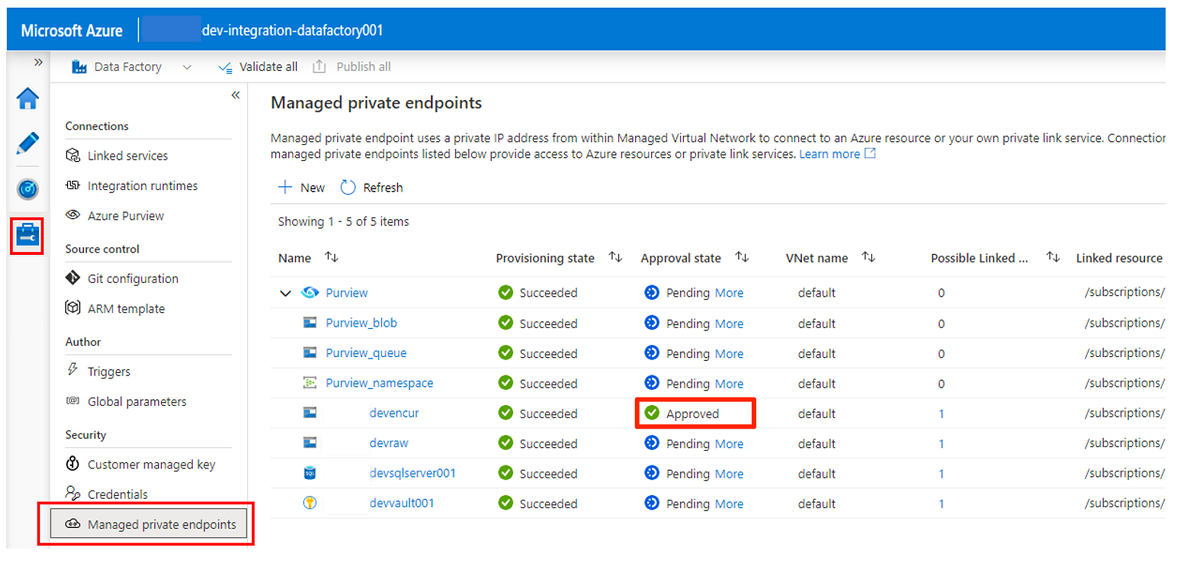
Przed zatwierdzeniem połączeń prywatnych punktów końcowych wybierz pozycję Nowy. Wprowadź wartość Azure SQL , aby znaleźć łącznik usługi Azure SQL Database używany do utworzenia nowego zarządzanego prywatnego punktu końcowego dla
<DP-prefix>-dev-sqlserver001maszyny wirtualnej usługi Azure SQL. Maszyna wirtualna zawieraAdatumCRMutworzone wcześniej bazy danych i .AdatumERPW obszarze Nowy zarządzany prywatny punkt końcowy (Azure SQL Database) w polu Nazwa wprowadź wartość data-product-dev-sqlserver001. Wprowadź subskrypcję platformy Azure użytą do utworzenia zasobów. W polu Nazwa serwera wybierz
<DP-prefix>-dev-sqlserver001opcję , aby można było nawiązać z nią połączenie z tej fabryki danych w następnych sekcjach.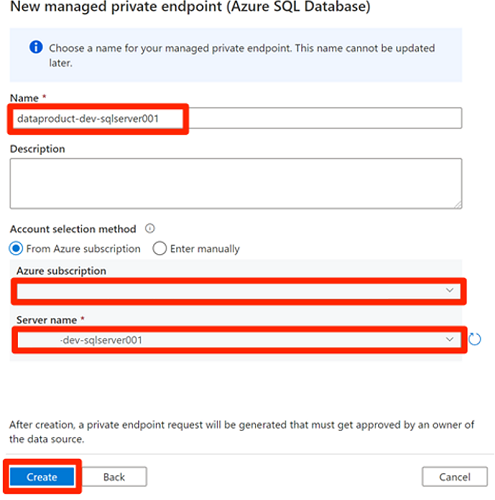



Zatwierdzanie żądań dostępu do prywatnego punktu końcowego
Aby zapewnić usłudze Data Factory dostęp do prywatnych punktów końcowych dla wymaganych usług, masz kilka opcji:
Opcja 1. W każdej usłudze, do której żądasz dostępu, w witrynie Azure Portal przejdź do opcji połączenia sieci lub prywatnego punktu końcowego usługi i zatwierdź żądania dostępu do prywatnego punktu końcowego.
Opcja 2. Uruchom następujące skrypty w usłudze Azure Cloud Shell w trybie powłoki Bash, aby zatwierdzić wszystkie żądania dostępu do wymaganych prywatnych punktów końcowych jednocześnie.
# Storage managed private endpoint approval # devencur resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-storage')==\`true\`].name") storageAcctName=$(az storage account list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'devencur')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $storageAcctName --type Microsoft.Storage/storageAccounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $storageAcctName --type Microsoft.Storage/storageAccounts --description "Approved" # devraw resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-storage')==\`true\`].name") storageAcctName=$(az storage account list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'devraw')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $storageAcctName --type Microsoft.Storage/storageAccounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $storageAcctName --type Microsoft.Storage/storageAccounts --description "Approved" # SQL Database managed private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-dp001')==\`true\`].name") sqlServerName=$(az sql server list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'sqlserver001')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $sqlServerName --type Microsoft.Sql/servers -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $sqlServerName --type Microsoft.Sql/servers --description "Approved" # Key Vault private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-metadata')==\`true\`].name") keyVaultName=$(az keyvault list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'dev-vault001')==\`true\`].name") endPointConnectionID=$(az network private-endpoint-connection list -g $resourceGroupName -n $keyVaultName --type Microsoft.Keyvault/vaults -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].id") az network private-endpoint-connection approve -g $resourceGroupName --id $endPointConnectionID --resource-name $keyVaultName --type Microsoft.Keyvault/vaults --description "Approved" # Purview private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, 'dev-governance')==\`true\`].name") purviewAcctName=$(az purview account list -g $resourceGroupName -o tsv --query "[?contains(@.name, '-dev-purview001')==\`true\`].name") for epn in $(az network private-endpoint-connection list -g $resourceGroupName -n $purviewAcctName --type Microsoft.Purview/accounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") do az network private-endpoint-connection approve -g $resourceGroupName -n $epn --resource-name $purviewAcctName --type Microsoft.Purview/accounts --description "Approved" done
W poniższym przykładzie <DLZ-prefix>devraw pokazano, jak konto magazynu zarządza żądaniami dostępu prywatnego punktu końcowego. W menu zasobów dla konta magazynu wybierz pozycję Sieć. Na pasku poleceń wybierz pozycję Połączenia prywatnego punktu końcowego.

W przypadku niektórych zasobów platformy Azure wybierz pozycję Połączenia prywatnego punktu końcowego w menu zasobów. Przykład serwera Azure SQL jest pokazany na poniższym zrzucie ekranu.
Aby zatwierdzić żądanie dostępu prywatnego punktu końcowego, w obszarze Połączenia prywatnego punktu końcowego wybierz oczekujące żądanie dostępu, a następnie wybierz pozycję Zatwierdź:

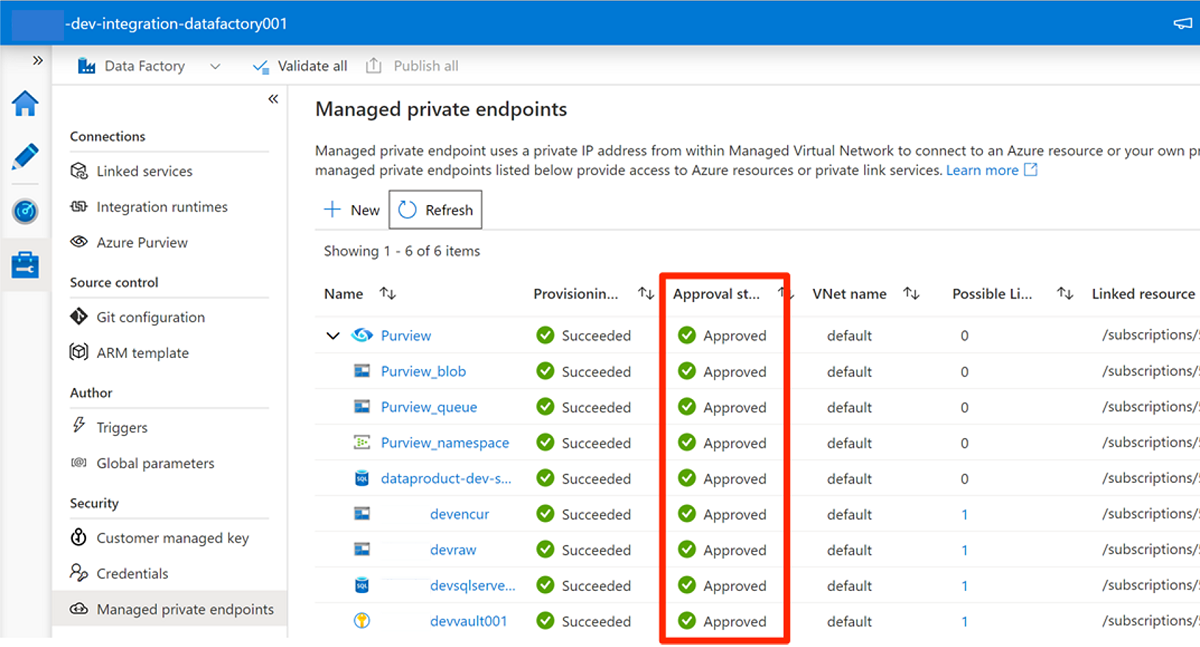
Po zatwierdzeniu żądania dostępu w każdej wymaganej usłudze żądanie może potrwać kilka minut, aby żądanie było wyświetlane jako Zatwierdzone w zarządzanych prywatnych punktach końcowych w narzędziu Data Factory Studio. Nawet jeśli wybierzesz pozycję Odśwież na pasku poleceń, stan zatwierdzenia może być nieaktualny przez kilka minut.
Po zakończeniu zatwierdzania wszystkich żądań dostępu dla wymaganych usług w obszarze Zarządzane prywatne punkty końcowe wartość stanu zatwierdzenia dla wszystkich usług jest zatwierdzona:
Przypisania ról
Po zakończeniu zatwierdzania żądań dostępu do prywatnego punktu końcowego dodaj odpowiednie uprawnienia roli dla usługi Data Factory, aby uzyskać dostęp do tych zasobów:
- Wystąpienia
AdatumCRMusługi SQL Database iAdatumERPna<DP-prefix>-dev-sqlserver001serwerze Azure SQL - Konta
<DLZ-prefix>devrawmagazynu ,<DLZ-prefix>devencuri<DLZ-prefix>devwork - Konto usługi Purview
<DMLZ-prefix>-dev-purview001
Maszyna wirtualna usługi Azure SQL
Aby dodać przypisania ról, zacznij od maszyny wirtualnej usługi Azure SQL.
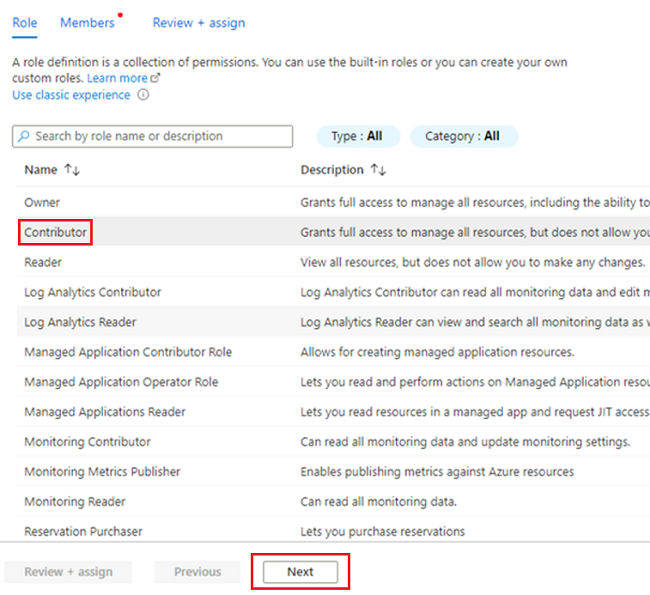
<DMLZ-prefix>-dev-dp001W grupie zasobów przejdź do strony<DP-prefix>-dev-sqlserver001.W menu zasobów wybierz pozycję Kontrola dostępu (Zarządzanie dostępem i tożsamościami). Na pasku poleceń wybierz pozycję Dodaj>przypisanie roli.
Na karcie Rola wybierz pozycję Współautor, a następnie wybierz pozycję Dalej.
W obszarze Członkowie w polu Przypisz dostęp do wybierz pozycję Tożsamość zarządzana. W obszarze Członkowie wybierz pozycję Wybierz członków.
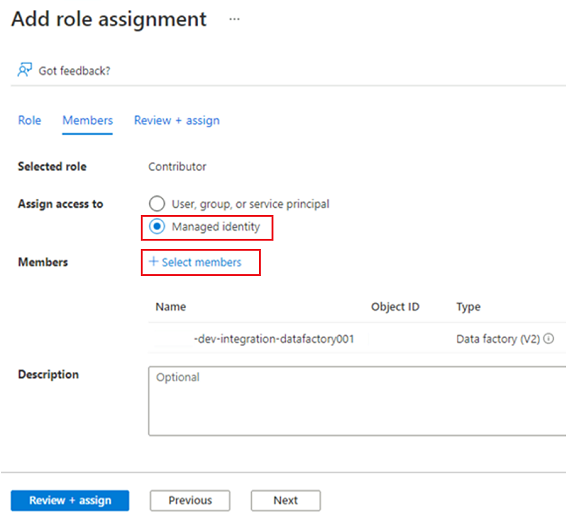
W obszarze Wybieranie tożsamości zarządzanych wybierz subskrypcję platformy Azure. W obszarze Tożsamość zarządzana wybierz pozycję Data Factory (wersja 2), aby wyświetlić dostępne fabryki danych. Na liście fabryk danych wybierz pozycję Azure Data Factory <DLZ-prefix-dev-integration-datafactory001>. Naciśnij przycisk Wybierz.
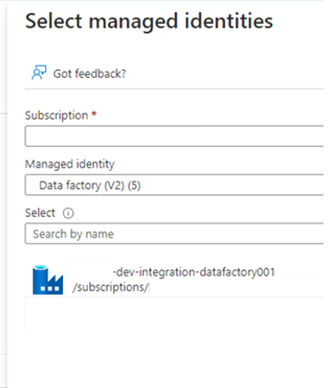
Wybierz pozycję Przejrzyj i przypisz dwa razy, aby ukończyć proces.
Konta magazynu
Następnie przypisz wymagane role do <DLZ-prefix>devrawkont magazynu , <DLZ-prefix>devencuri <DLZ-prefix>devwork .
Aby przypisać role, wykonaj te same kroki, które użyto do utworzenia przypisania roli serwera Azure SQL. Jednak dla roli wybierz pozycję Współautor danych obiektu blob usługi Storage zamiast Współautor.
Po przypisaniu ról dla wszystkich trzech kont magazynu usługa Data Factory może łączyć się z kontami magazynu i uzyskiwać do niego dostęp.
Microsoft Purview
Ostatnim krokiem dodawania przypisań ról jest dodanie roli Kurator danych usługi Purview w usłudze Microsoft Purview do konta tożsamości zarządzanej <DLZ-prefix>-dev-integration-datafactory001 fabryki danych. Wykonaj poniższe kroki, aby usługa Data Factory mogła wysyłać informacje o zasobach wykazu danych z wielu źródeł danych do konta usługi Purview.
W grupie
<DMLZ-prefix>-dev-governancezasobów przejdź do<DMLZ-prefix>-dev-purview001konta usługi Purview.W programie Purview Studio wybierz ikonę Mapa danych, a następnie wybierz pozycję Kolekcje.
Wybierz kartę Przypisania ról dla kolekcji. W obszarze Kuratorzy danych dodaj tożsamość zarządzaną dla elementu
<DLZ-prefix>-dev-integration-datafactory001: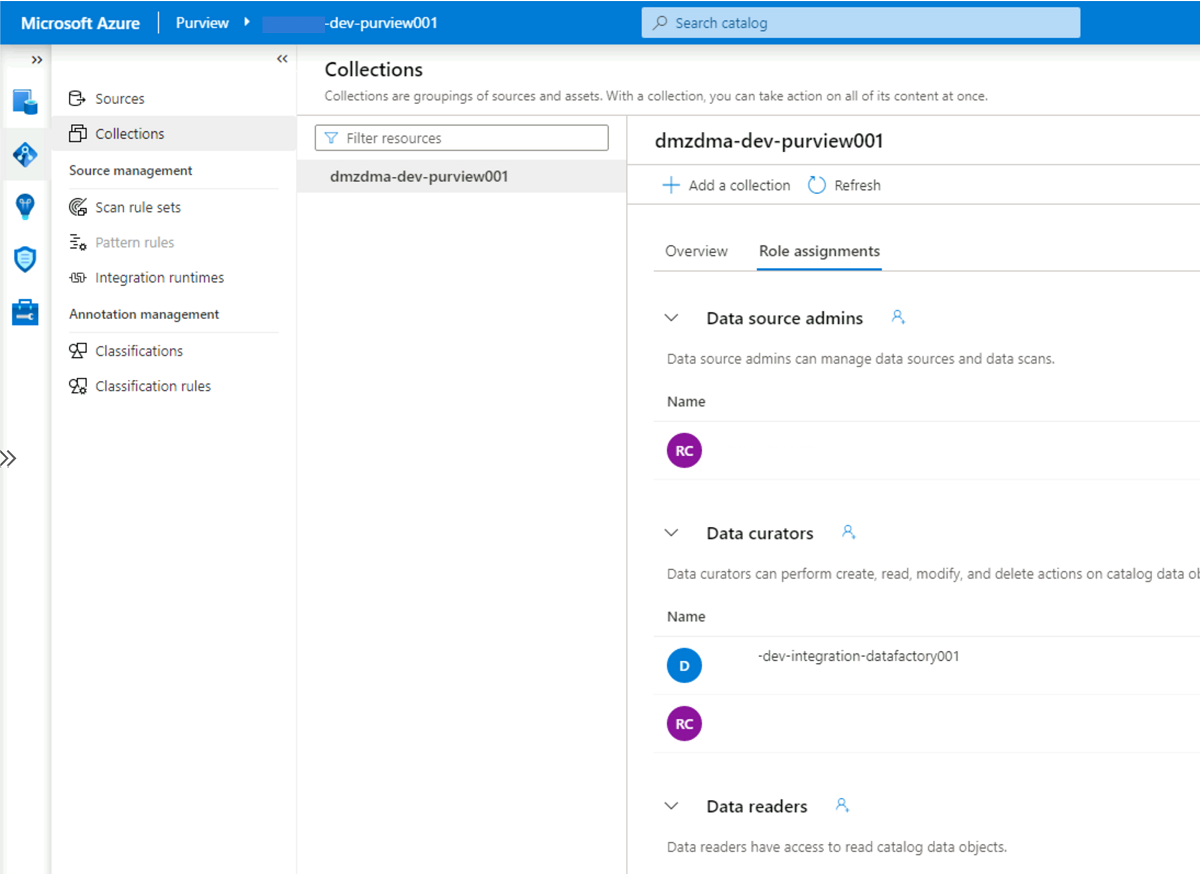
Połączenie Data Factory do usługi Purview
Uprawnienia są ustawione, a usługa Purview może teraz zobaczyć fabrykę danych. Następnym krokiem jest nawiązanie połączenia z usługą <DMLZ-prefix>-dev-purview001 <DLZ-prefix>-dev-integration-datafactory001.
W programie Purview Studio wybierz ikonę Zarządzanie , a następnie wybierz pozycję Fabryka danych. Wybierz pozycję Nowy , aby utworzyć połączenie z usługą Data Factory.
W okienku Nowe połączenia usługi Data Factory wprowadź subskrypcję platformy Azure i wybierz fabrykę
<DLZ-prefix>-dev-integration-datafactory001danych. Wybierz przycisk OK.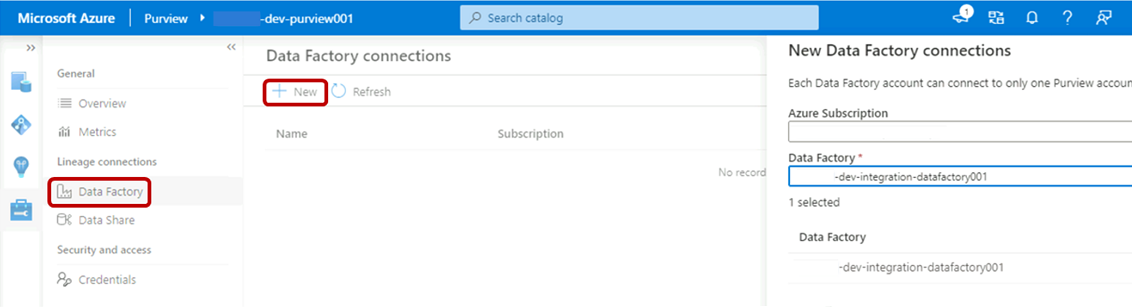
W wystąpieniu
<DLZ-prefix>-dev-integration-datafactory001usługi Data Factory Studio w obszarze Zarządzanie usługą>Azure Purview odśwież konto usługi Azure Purview.Integracja
Data Lineage - Pipelinezawiera teraz zieloną ikonę Połączenie ed.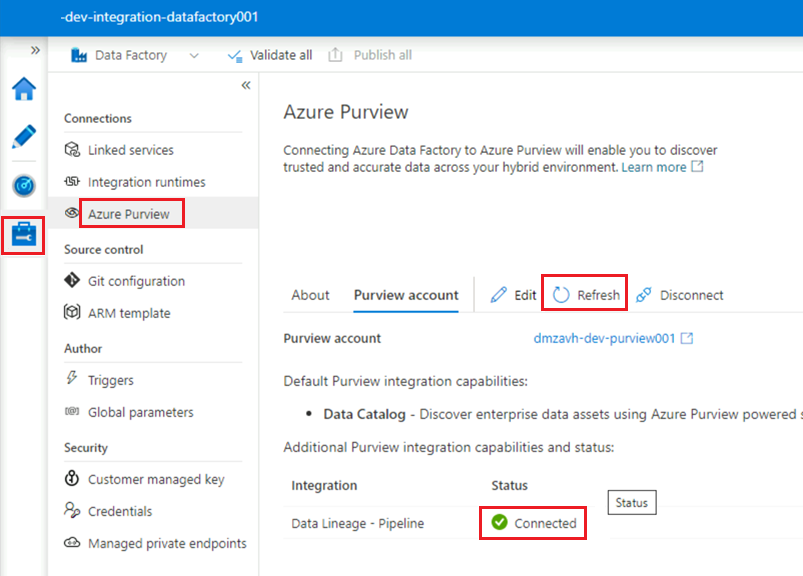

Tworzenie potoku ETL
Teraz, gdy użytkownik <DLZ-prefix>-dev-integration-datafactory001 ma wymagane uprawnienia dostępu, utwórz działanie kopiowania w usłudze Data Factory, aby przenieść dane z wystąpień usługi SQL Database do pierwotnego <DLZ-prefix>devraw konta magazynu.
Korzystanie z narzędzia do kopiowania danych za pomocą narzędzia AdatumCRM
Ten proces wyodrębnia dane klienta z AdatumCRM wystąpienia usługi SQL Database i kopiuje je do magazynu usługi Data Lake Storage Gen2.
W narzędziu Data Factory Studio wybierz ikonę Autor , a następnie wybierz pozycję Zasoby fabryczne. Wybierz znak plus (+) i wybierz pozycję Narzędzie do kopiowania danych.
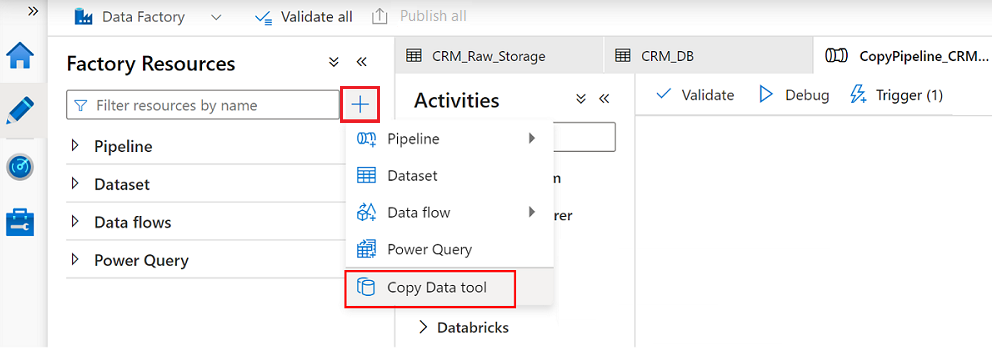
Wykonaj każdy krok w kreatorze narzędzia do kopiowania danych:
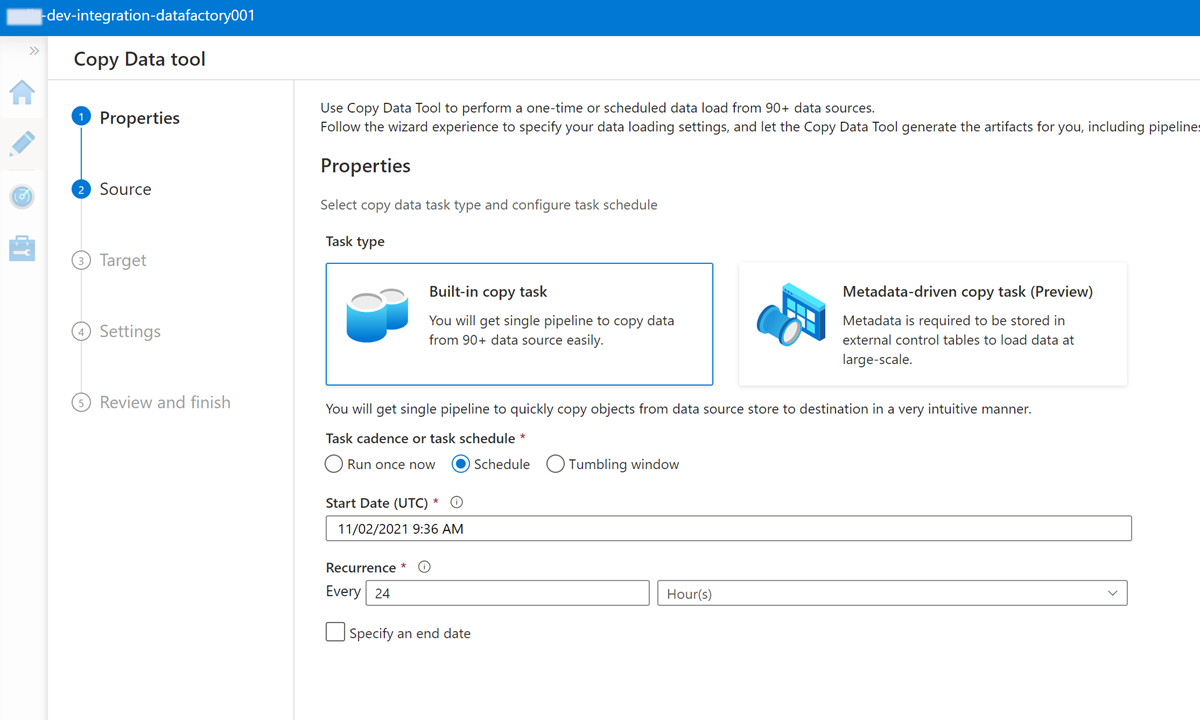
Aby utworzyć wyzwalacz do uruchamiania potoku co 24 godziny, wybierz pozycję Harmonogram.
Aby utworzyć połączoną usługę w celu połączenia tej fabryki
AdatumCRMdanych z wystąpieniem usługi SQL Database na<DP-prefix>-dev-sqlserver001serwerze (źródło), wybierz pozycję Nowa Połączenie ion.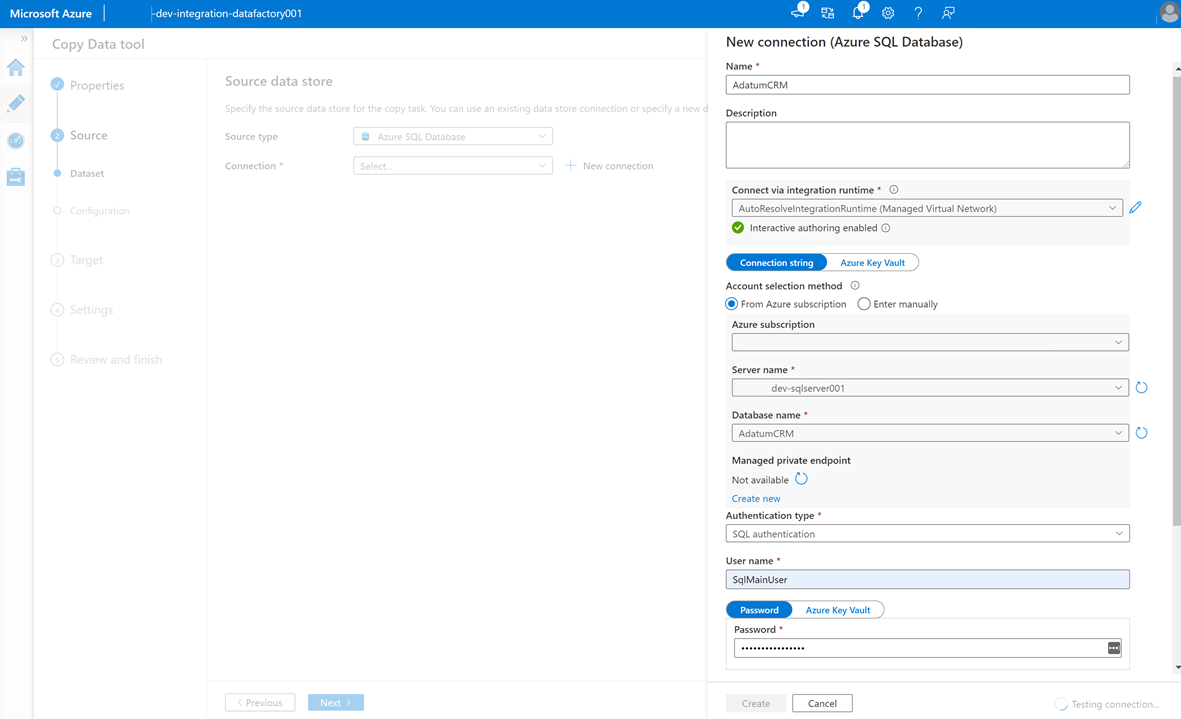
Uwaga
Jeśli wystąpią błędy podczas nawiązywania połączenia z danymi lub uzyskiwania do ich dostępu w wystąpieniach usługi SQL Database lub kontach magazynu, przejrzyj swoje uprawnienia w subskrypcji platformy Azure. Upewnij się, że fabryka danych ma wymagane poświadczenia i uprawnienia dostępu do dowolnego problematycznego zasobu.
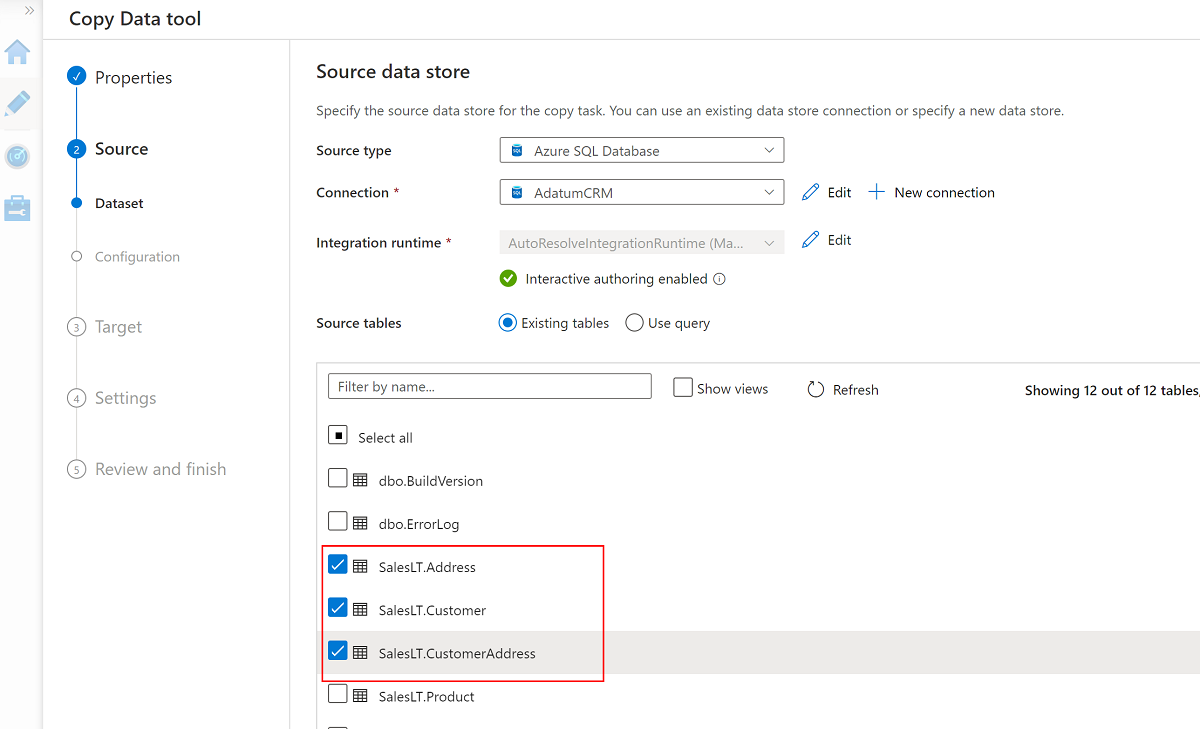
Wybierz te trzy tabele:
SalesLT.AddressSalesLT.CustomerSalesLT.CustomerAddress
Utwórz nową połączoną usługę, aby uzyskać dostęp do
<DLZ-prefix>devrawmagazynu usługi Azure Data Lake Storage Gen2 (miejsce docelowe).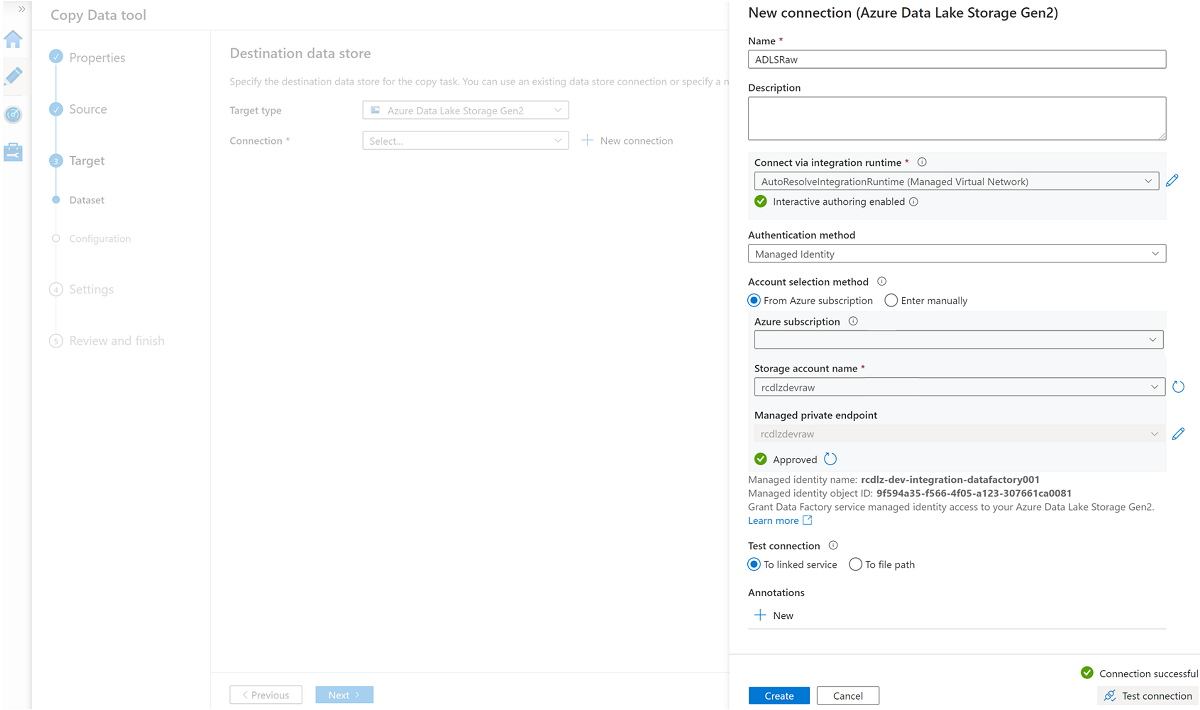
Przeglądaj foldery w
<DLZ-prefix>devrawmagazynie i wybierz pozycję Dane jako miejsce docelowe.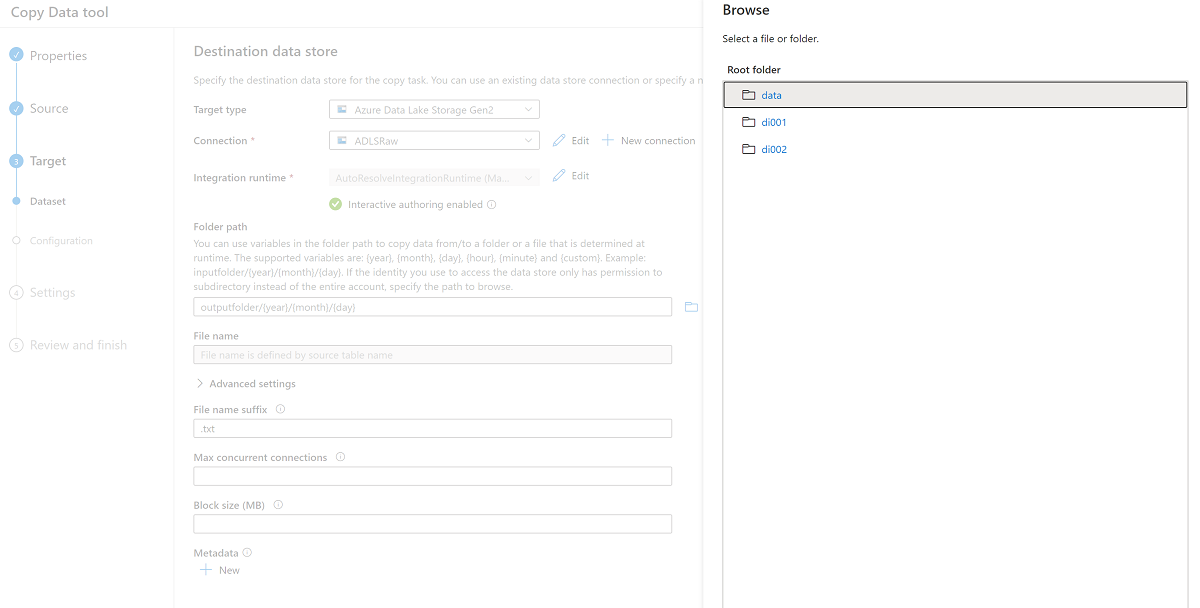
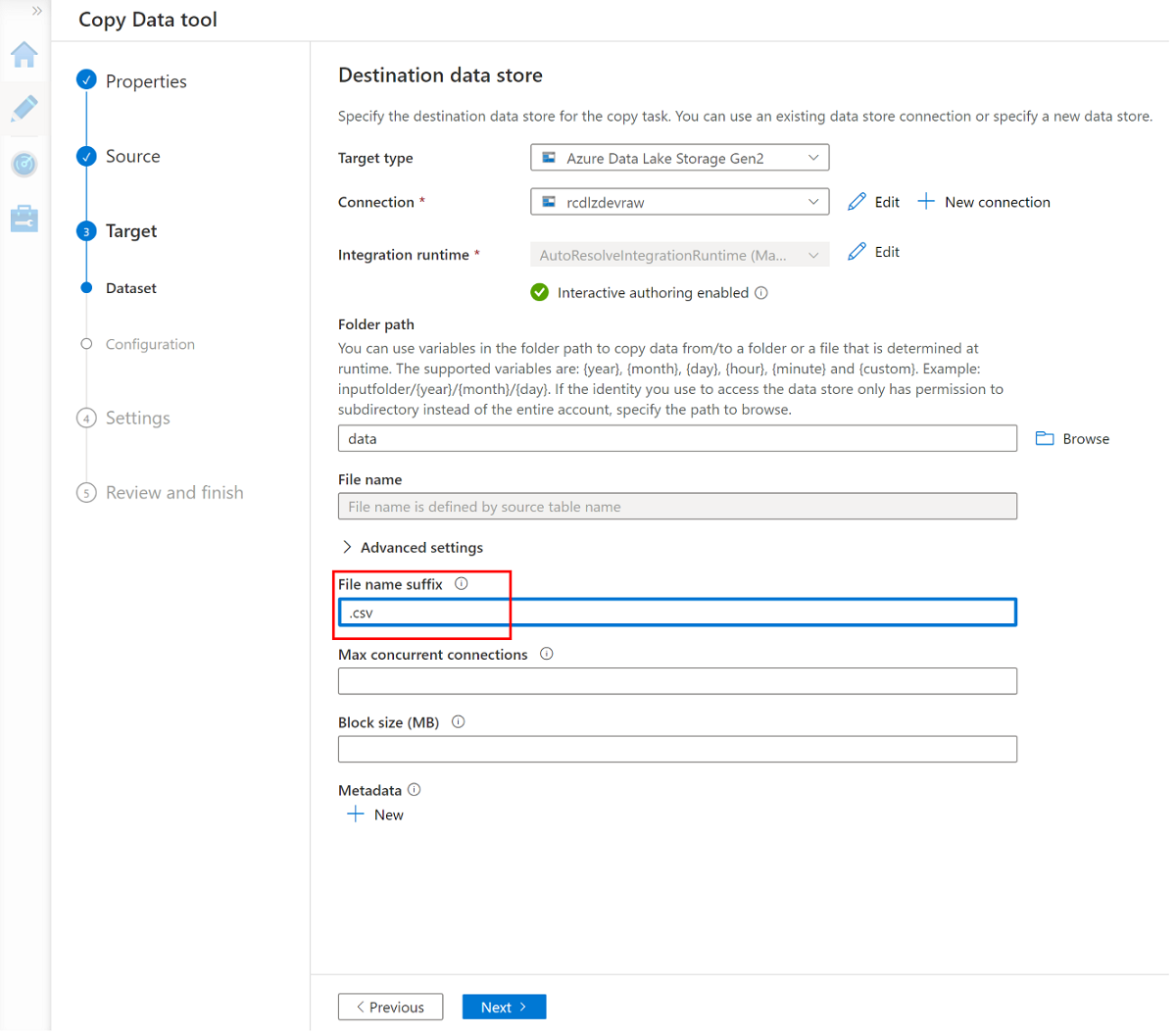
Zmień sufiks nazwy pliku na .csv i użyj innych opcji domyślnych.
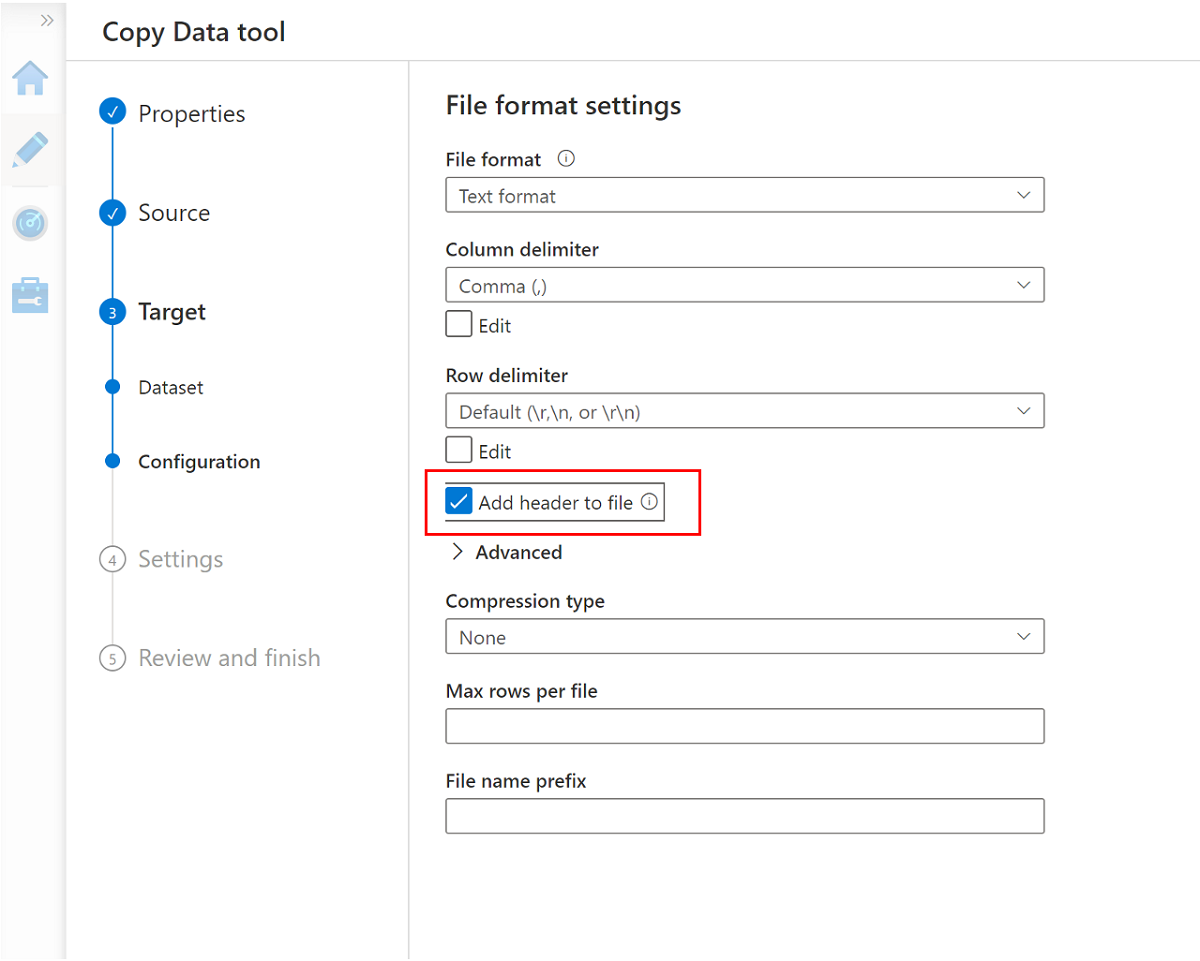
Przejdź do następnego okienka i wybierz pozycję Dodaj nagłówek do pliku.
Po zakończeniu pracy kreatora okienko Ukończenie wdrażania wygląda podobnie do tego przykładu:
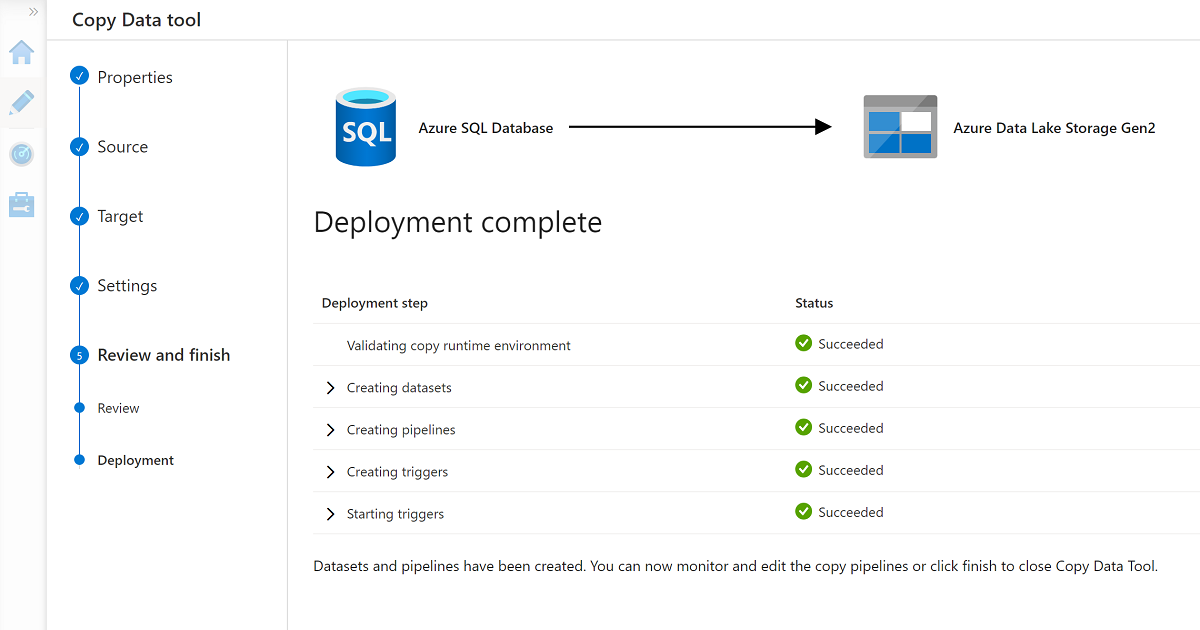




Nowy potok znajduje się na liście Potoki.
Uruchamianie potoku
Ten proces tworzy trzy pliki .csv w folderze Data\CRM , po jednym dla każdej z wybranych tabel w AdatumCRM bazie danych.
Zmień nazwę potoku
CopyPipeline_CRM_to_Raw.Zmień nazwy zestawów
CRM_Raw_Storagedanych iCRM_DB.Na pasku poleceń Zasoby fabryki wybierz pozycję Opublikuj wszystko.
Wybierz potok, a następnie
CopyPipeline_CRM_to_Rawna pasku poleceń potoku wybierz pozycję Wyzwalacz , aby skopiować trzy tabele z usługi SQL Database do usługi Data Lake Storage Gen2.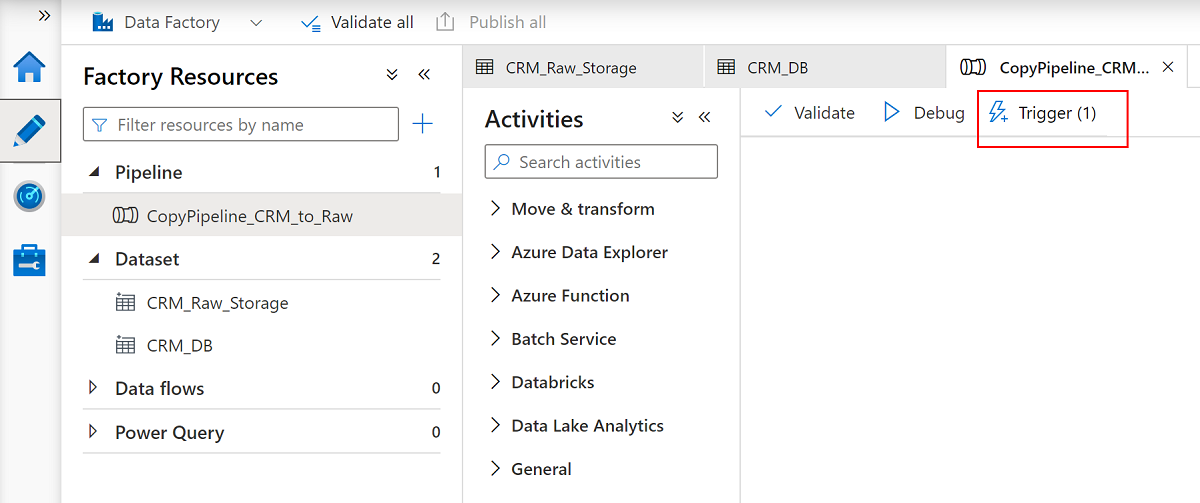
Korzystanie z narzędzia do kopiowania danych z rozwiązaniem AdatumERP
Następnie wyodrębnij dane z AdatumERP bazy danych. Dane reprezentują dane sprzedaży pochodzące z systemu ERP.
Nadal w programie Data Factory Studio utwórz nowy potok przy użyciu narzędzia do kopiowania danych. Tym razem wysyłasz dane sprzedaży z
AdatumERPfolderu<DLZ-prefix>devrawdanych konta magazynu w taki sam sposób, jak w przypadku danych CRM. Wykonaj te same kroki, ale użyjAdatumERPbazy danych jako źródła.Utwórz harmonogram wyzwalający co godzinę.
Utwórz połączoną usługę z wystąpieniem
AdatumERPusługi SQL Database.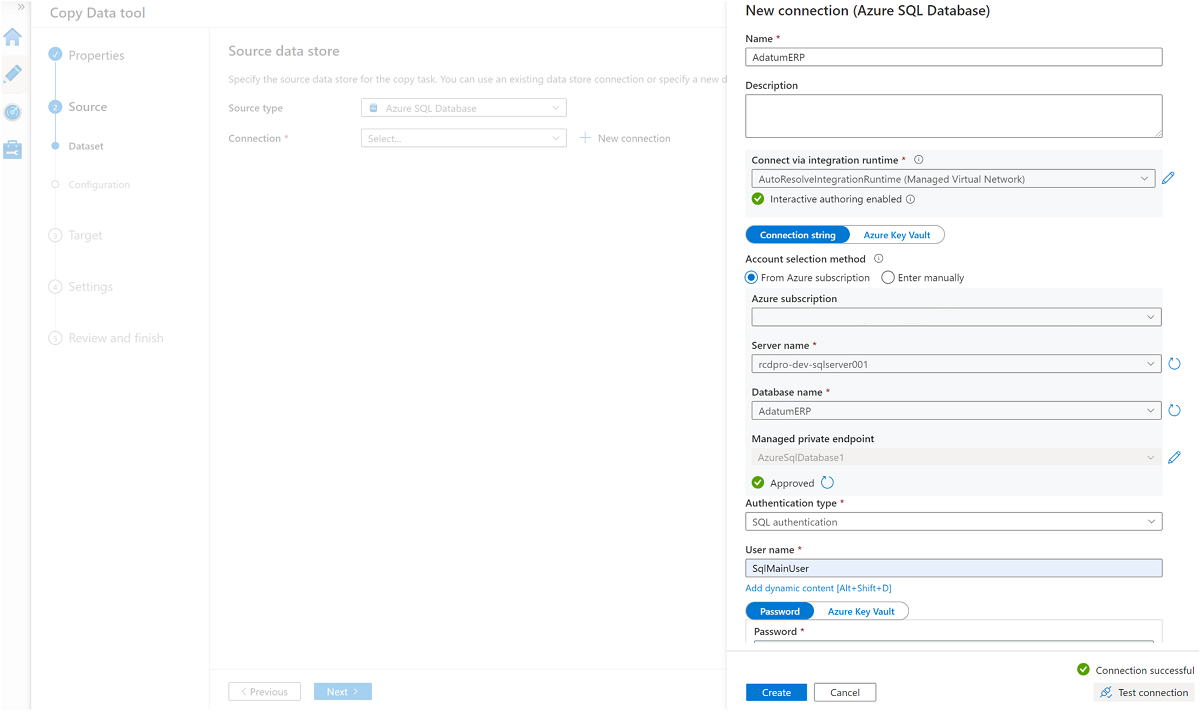
Wybierz te siedem tabel:
SalesLT.ProductSalesLT.ProductCategorySalesLT.ProductDescriptionSalesLT.ProductModelSalesLT.ProductModelProductDescriptionSalesLT.SalesOrderDetailSalesLT.SalesOrderHeader
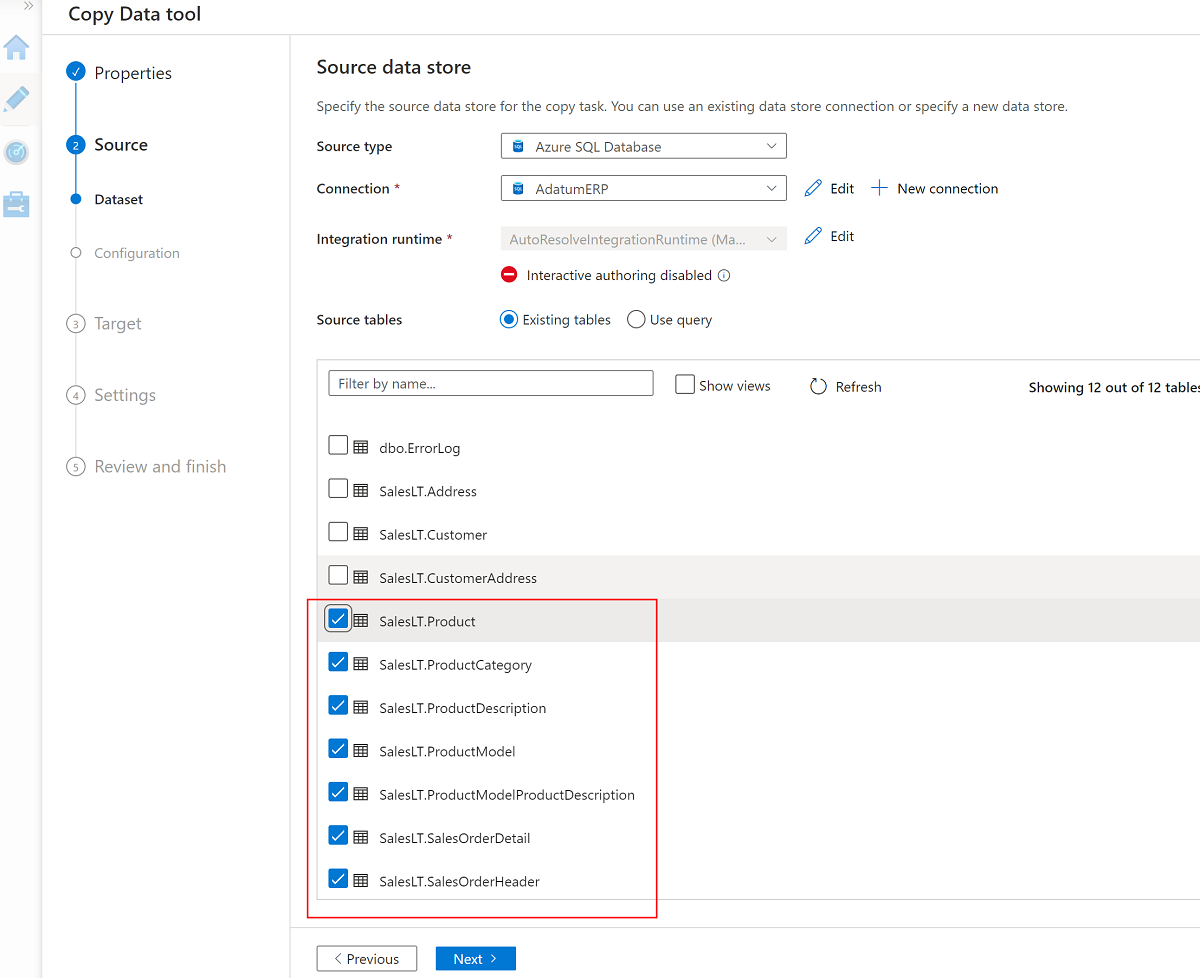
Użyj istniejącej połączonej usługi do
<DLZ-prefix>devrawkonta magazynu i ustaw rozszerzenie pliku na .csv.
Wybierz pozycję Dodaj nagłówek do pliku.
Ponownie ukończ kreatora i zmień nazwę potoku
CopyPipeline_ERP_to_DevRaw. Następnie na pasku poleceń wybierz pozycję Opublikuj wszystko. Na koniec uruchom wyzwalacz w tym nowo utworzonym potoku, aby skopiować siedem wybranych tabel z usługi SQL Database do usługi Data Lake Storage Gen2.

Po zakończeniu tych kroków 10 plików CSV znajduje się w <DLZ-prefix>devraw magazynie usługi Data Lake Storage Gen2. W następnej sekcji tworzysz pliki w <DLZ-prefix>devencur magazynie usługi Data Lake Storage Gen2.
Curate data in Data Lake Storage Gen2
Po zakończeniu tworzenia 10 plików CSV w nieprzetworzonym <DLZ-prefix>devraw magazynie usługi Data Lake Storage Gen2 przekształć te pliki zgodnie z potrzebami podczas kopiowania ich do wyselekcjonowanych <DLZ-prefix>devencur magazynów usługi Data Lake Storage Gen2.
Kontynuuj korzystanie z usługi Azure Data Factory, aby utworzyć te nowe potoki w celu organizowania przenoszenia danych.
Curate CRM to customer data (Curate CRM to customer data)
Utwórz przepływ danych, który pobiera pliki CSV w folderze Data\CRM w folderze <DLZ-prefix>devraw. Przekształć pliki i skopiować przekształcone pliki w formacie pliku parquet do folderu Data\Customer w folderze <DLZ-prefix>devencur.
W usłudze Azure Data Factory przejdź do fabryki danych i wybierz pozycję Orkiestruj.
W obszarze Ogólne nadaj potokowi
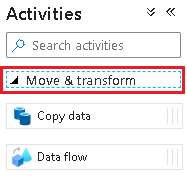
Pipeline_transform_CRMnazwę .W okienku Działania rozwiń węzeł Przenieś i Przekształć. Przeciągnij działanie przepływu danych i upuść je na kanwie potoku.
W obszarze Dodawanie Przepływ danych wybierz pozycję Utwórz nowy przepływ danych i nadaj przepływowi
CRM_to_Customerdanych nazwę . Wybierz Zakończ.Uwaga
Na pasku poleceń kanwy potoku włącz debugowanie przepływu danych. W trybie debugowania można interaktywnie przetestować logikę przekształcania względem dynamicznego klastra Apache Spark. Rozgrzanie klastrów przepływu danych trwa od 5 do 7 minut. Zalecamy włączenie debugowania przed rozpoczęciem opracowywania przepływu danych.

Po zakończeniu wybierania opcji w przepływie
Pipeline_transform_CRMdanych potok wygląda podobnie do tego przykładuCRM_to_Customer: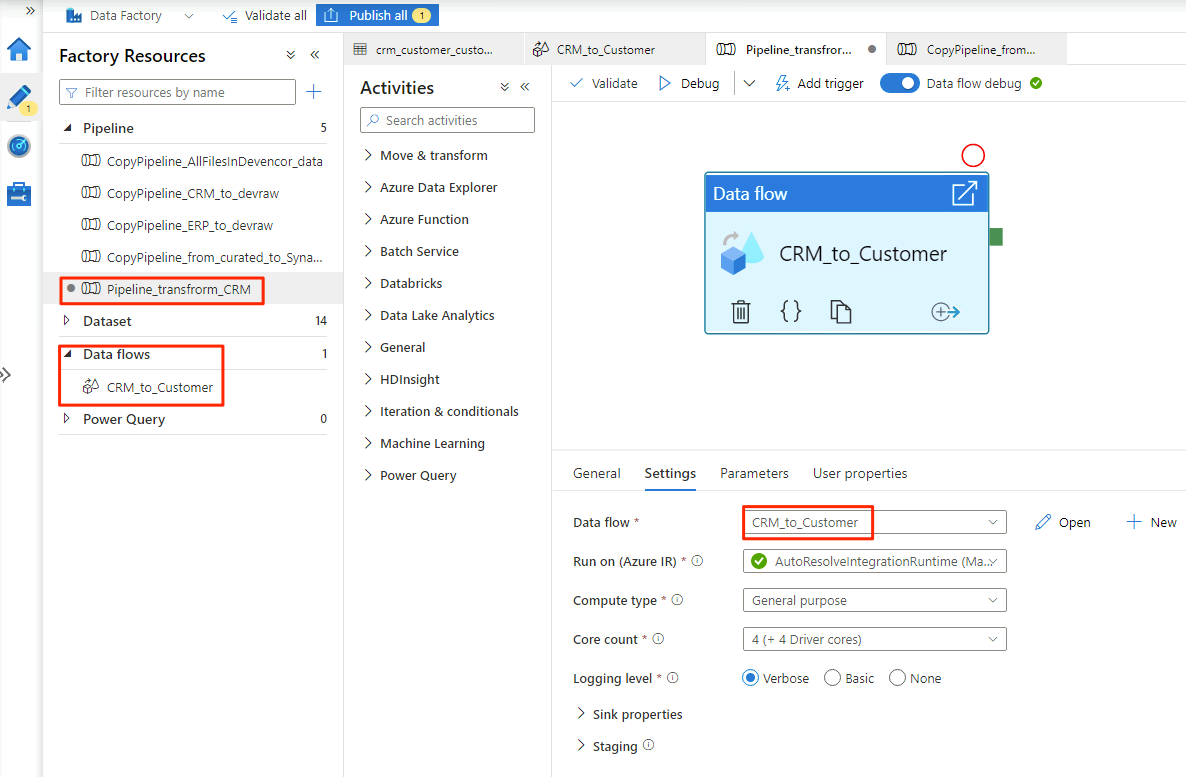
Przepływ danych wygląda następująco:
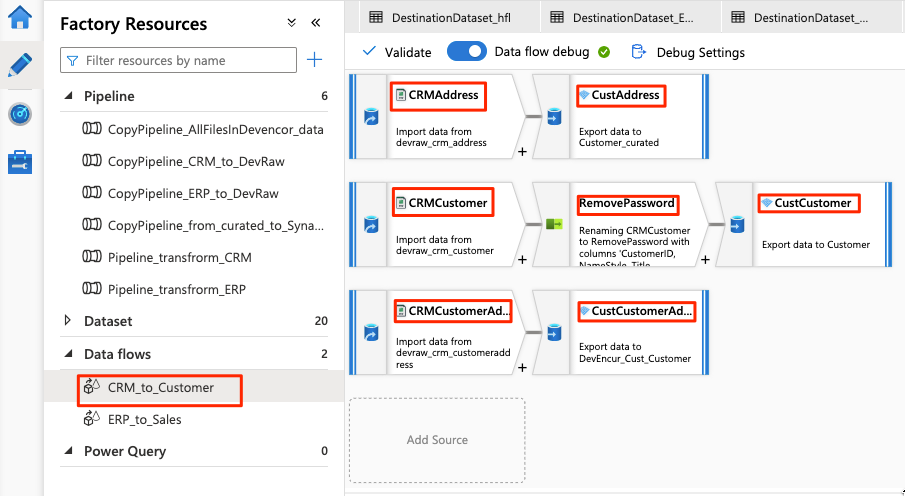
Następnie zmodyfikuj te ustawienia w przepływie
CRMAddressdanych dla źródła:Utwórz nowy zestaw danych z usługi Data Lake Storage Gen2. Użyj formatu DelimitedText. Nadaj zestawowi danych
DevRaw_CRM_Addressnazwę .Połączenie połączoną usługę z .
<DLZ-prefix>devrawData\CRM\SalesLTAddress.csvWybierz plik jako źródło.
Zmodyfikuj te ustawienia w przepływie danych dla sparowanego ujścia
CustAddress:Utwórz nowy zestaw danych o nazwie
DevEncur_Cust_Address.Wybierz folder Data\Customer w
<DLZ-prefix>devencurfolderze jako ujście.W obszarze Ustawienia\Output do pojedynczego pliku przekonwertuj plik na Address.parquet.
W pozostałej części konfiguracji przepływu danych użyj informacji w poniższych tabelach dla każdego składnika. Zwróć uwagę, że CRMAddress i CustAddress są pierwszymi dwoma wierszami. Użyj ich jako przykładów dla innych obiektów.
Element, który nie znajduje się w żadnej z poniższych tabel, jest RemovePasswords modyfikatorem schematu. Powyższy zrzut ekranu pokazuje, że ten element przechodzi między elementami CRMCustomer i CustCustomer. Aby dodać ten modyfikator schematu, przejdź do pozycji Wybierz ustawienia i usuń pozycję PasswordHash i PasswordSalt.
CRMCustomer Zwraca schemat 15-kolumnowy z pliku crv. CustCustomer Zapisuje tylko 13 kolumn po usunięciu dwóch kolumn haseł przez modyfikator schematu.
Kompletna tabela
| Nazwisko | Object type | Nazwa zestawu danych | Magazyn danych | Typ formatu | Połączona usługa | Plik lub folder |
|---|---|---|---|---|---|---|
CRMAddress |
source | DevRaw_CRM_Address |
Azure Data Lake Storage Gen2 | Rozdzielany tekst | devraw |
Data\CRM\SalesLTAddress.csv |
CustAddress |
Zlew | DevEncur_Cust_Address |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\Address.parquet |
CRMCustomer |
source | DevRaw_CRM_Customer |
Azure Data Lake Storage Gen2 | Rozdzielany tekst | devraw |
Data\CRM\SalesLTCustomer.csv |
CustCustomer |
Zlew | DevEncur_Cust_Customer |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\Customer.parquet |
CRMCustomerAddress |
source | DevRaw_CRM_CustomerAddress |
Azure Data Lake Storage Gen2 | Rozdzielany tekst | devraw |
Data\CRM\SalesLTCustomerAddress.csv |
CustCustomerAddress |
Zlew | DevEncur_Cust_CustomerAddress |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Customer\CustomerAddress.parquet |
Tabela ERP to Sales
Teraz powtórz podobne kroki, aby utworzyć Pipeline_transform_ERP potok, utwórz ERP_to_Sales przepływ danych, aby przekształcić pliki .csv w folderze Data\ERP w <DLZ-prefix>devrawfolderze , a następnie skopiuj przekształcone pliki do folderu Data\Sales w <DLZ-prefix>devencurprogramie .
W poniższej tabeli znajdziesz obiekty do utworzenia w przepływie ERP_to_Sales danych i ustawienia, które należy zmodyfikować dla każdego obiektu. Każdy plik .csv jest mapowany na ujście .parquet .
| Nazwisko | Object type | Nazwa zestawu danych | Magazyn danych | Typ formatu | Połączona usługa | Plik lub folder |
|---|---|---|---|---|---|---|
ERPProduct |
source | DevRaw_ERP_Product |
Azure Data Lake Storage Gen2 | Rozdzielany tekst | devraw |
Data\ERP\SalesLTProduct.csv |
SalesProduct |
Zlew | DevEncur_Sales_Product |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\Product.parquet |
ERPProductCategory |
source | DevRaw_ERP_ProductCategory |
Azure Data Lake Storage Gen2 | Rozdzielany tekst | devraw |
Data\ERP\SalesLTProductCategory.csv |
SalesProductCategory |
Zlew | DevEncur_Sales_ProductCategory |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductCategory.parquet |
ERPProductDescription |
source | DevRaw_ERP_ProductDescription |
Azure Data Lake Storage Gen2 | Rozdzielany tekst | devraw |
Data\ERP\SalesLTProductDescription.csv |
SalesProductDescription |
Zlew | DevEncur_Sales_ProductDescription |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductDescription.parquet |
ERPProductModel |
source | DevRaw_ERP_ProductModel |
Azure Data Lake Storage Gen2 | Rozdzielany tekst | devraw |
Data\ERP\SalesLTProductModel.csv |
SalesProductModel |
Zlew | DevEncur_Sales_ProductModel |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductModel.parquet |
ERPProductModelProductDescription |
source | DevRaw_ERP_ProductModelProductDescription |
Azure Data Lake Storage Gen2 | Rozdzielany tekst | devraw |
Data\ERP\SalesLTProductModelProductDescription.csv |
SalesProductModelProductDescription |
Zlew | DevEncur_Sales_ProductModelProductDescription |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductModelProductDescription.parquet |
ERPProductSalesOrderDetail |
source | DevRaw_ERP_ProductSalesOrderDetail |
Azure Data Lake Storage Gen2 | Rozdzielany tekst | devraw |
Data\ERP\SalesLTProductSalesOrderDetail.csv |
SalesProductSalesOrderDetail |
Zlew | DevEncur_Sales_ProductSalesOrderDetail |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductSalesOrderDetail.parquet |
ERPProductSalesOrderHeader |
source | DevRaw_ERP_ProductSalesOrderHeader |
Azure Data Lake Storage Gen2 | Rozdzielany tekst | devraw |
Data\ERP\SalesLTProductSalesOrderHeader.csv |
SalesProductSalesOrderHeader |
Zlew | DevEncur_Sales_ProductSalesOrderHeader |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Data\Sales\ProductSalesOrderHeader.parquet |