Szybki start: tworzenie modelu klasyfikacji obrazów za pomocą portalu Custom Vision
W tym przewodniku Szybki start dowiesz się, jak utworzyć model klasyfikacji obrazów za pomocą portalu internetowego usługi Custom Vision. Po utworzeniu modelu możesz przetestować go przy użyciu nowych obrazów i w końcu zintegrować go z własną aplikacją do rozpoznawania obrazów.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Wymagania wstępne
- Zestaw obrazów do trenowania modelu klasyfikacji. Możesz użyć zestawu przykładowych obrazów w usłudze GitHub. Możesz też wybrać własne obrazy, korzystając z poniższych wskazówek.
- Obsługiwana przeglądarka internetowa
Tworzenie zasobów usługi Custom Vision
Aby korzystać z usługi Custom Vision Service, należy utworzyć zasoby trenowania i przewidywania usługi Custom Vision na platformie Azure. Aby to zrobić w witrynie Azure Portal, wypełnij okno dialogowe na stronie Tworzenie usługi Custom Vision , aby utworzyć zasób trenowania i przewidywania.
Tworzenie nowego projektu
W przeglądarce internetowej przejdź do strony internetowej usługi Custom Vision i wybierz pozycję Zaloguj. Zaloguj się przy użyciu tego samego konta, które zostało użyte do zalogowania się w witrynie Azure Portal.
Aby utworzyć pierwszy projekt, wybierz pozycję Nowy projekt. Zostanie wyświetlone okno dialogowe Tworzenie nowego projektu .
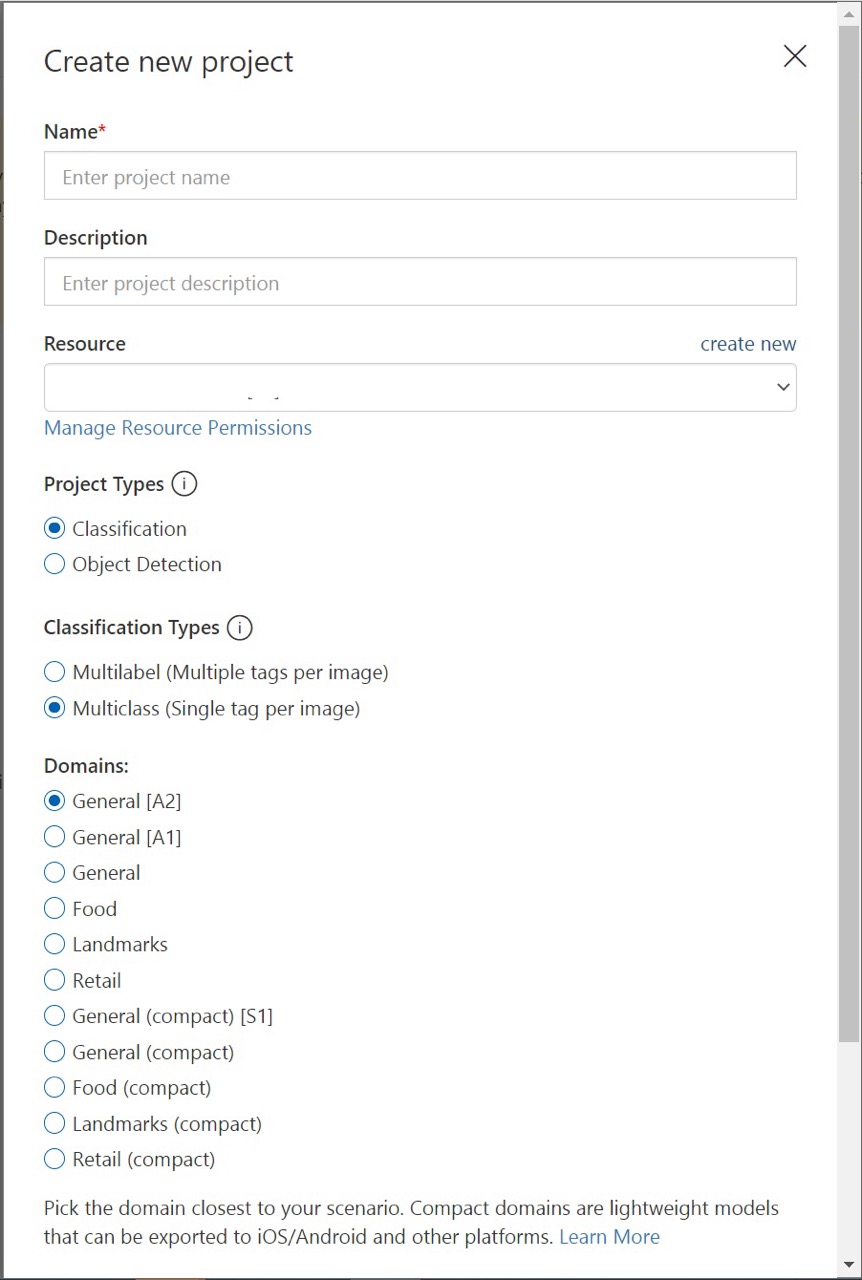
Wprowadź nazwę i opis projektu. Następnie wybierz zasób trenowania usługi Custom Vision. Jeśli zalogowane konto jest skojarzone z kontem platformy Azure, na liście rozwijanej Zasób zostaną wyświetlone wszystkie zgodne zasoby platformy Azure.
Uwaga
Jeśli żaden zasób nie jest dostępny, upewnij się, że zalogowano się do customvision.ai przy użyciu tego samego konta, które zostało użyte do zalogowania się w witrynie Azure Portal. Upewnij się również, że wybrano ten sam katalog w witrynie internetowej usługi Custom Vision co katalog w witrynie Azure Portal, w której znajdują się zasoby usługi Custom Vision. W obu witrynach możesz wybrać katalog z menu rozwijanego konta w prawym górnym rogu ekranu.
Wybierz pozycję Klasyfikacja w obszarze Typy projektów. Następnie w obszarze Typy klasyfikacji wybierz pozycję Multilabel lub Multiclass w zależności od przypadku użycia. Klasyfikacja wieloklasowa stosuje dowolną liczbę tagów do obrazu (zero lub więcej), podczas gdy klasyfikacja wieloklasowa sortuje obrazy w pojedyncze kategorie (każdy przesłany obraz zostanie posortowany w najbardziej prawdopodobny tag). Jeśli chcesz, będzie można później zmienić typ klasyfikacji.
Następnie wybierz jedną z dostępnych domen. Każda domena optymalizuje model pod kątem określonych typów obrazów, zgodnie z opisem w poniższej tabeli. Jeśli chcesz, możesz później zmienić domenę.
Domain Purpose Ogólny Zoptymalizowane pod kątem szerokiego zakresu zadań klasyfikacji obrazów. Jeśli żadna z innych domen nie jest odpowiednia lub nie masz pewności, którą domenę wybrać, wybierz domenę ogólną. Żywności Zoptymalizowane pod kątem zdjęć potraw, jak można je zobaczyć w menu restauracji. Jeśli chcesz sklasyfikować zdjęcia pojedynczych owoców lub warzyw, użyj domeny Food. Zabytki Zoptymalizowany pod kątem rozpoznawalnych zabytków, zarówno naturalnych, jak i sztucznych. Ta domena działa najlepiej, gdy punkt orientacyjny jest wyraźnie widoczny na zdjęciu. Ta domena działa, nawet jeśli punkt orientacyjny jest nieco utrudniony przez ludzi przed nim. Retail Zoptymalizowane pod kątem obrazów znajdujących się w katalogu zakupów lub witrynie internetowej zakupów. Jeśli potrzebujesz wysokiej precyzji klasyfikowania między sukienkami, spodniami i koszulami, użyj tej domeny. Domeny kompaktowe Zoptymalizowane pod kątem ograniczeń klasyfikacji w czasie rzeczywistym na urządzeniach przenośnych. Modele generowane przez domeny kompaktowe można eksportować do uruchamiania lokalnie. Na koniec wybierz pozycję Utwórz projekt.
Wybieranie obrazów szkoleniowych
Zalecamy co najmniej użycie co najmniej 30 obrazów na tag w początkowym zestawie treningowym. Po wytrenowanym modelu warto również zebrać kilka dodatkowych obrazów.
Aby efektywnie trenować model, użyj obrazów z różnymi wizualizacjami. Wybierz obrazy, które różnią się w zależności od:
- kąt kamery
- Oświetlenie
- tło
- styl wizualizacji
- osoby/pogrupowane podmioty
- size
- type
Ponadto upewnij się, że wszystkie obrazy szkoleniowe spełniają następujące kryteria:
- format .jpg, .png, .bmp lub .gif
- rozmiar nie większy niż 6 MB (4 MB dla obrazów przewidywania)
- nie mniej niż 256 pikseli na najkrótszej krawędzi; wszystkie obrazy krótsze niż te zostaną automatycznie skalowane w górę przez usługę Custom Vision Service
Przekazywanie i tagowanie obrazów
W tej sekcji przekażesz i ręcznie oznaczysz obrazy, aby ułatwić trenowanie klasyfikatora.
Aby dodać obrazy, wybierz pozycję Dodaj obrazy , a następnie wybierz pozycję Przeglądaj pliki lokalne. Wybierz pozycję Otwórz, aby przejść do tagowania. Wybór tagu jest stosowany do całej grupy obrazów wybranych do przekazania, dzięki czemu łatwiej jest przekazywać obrazy w osobnych grupach zgodnie z zastosowanymi tagami. Tagi poszczególnych obrazów można również zmienić po przekazaniu.
Aby utworzyć tag, wprowadź tekst w polu Moje tagi i naciśnij klawisz Enter. Jeśli tag już istnieje, zostanie wyświetlony w menu rozwijanym. W projekcie wieloklasowym można dodać do obrazów więcej niż jeden tag, ale w projekcie wieloklasowym można dodać tylko jeden tag. Aby zakończyć przekazywanie obrazów, użyj przycisku Przekaż pliki [number].
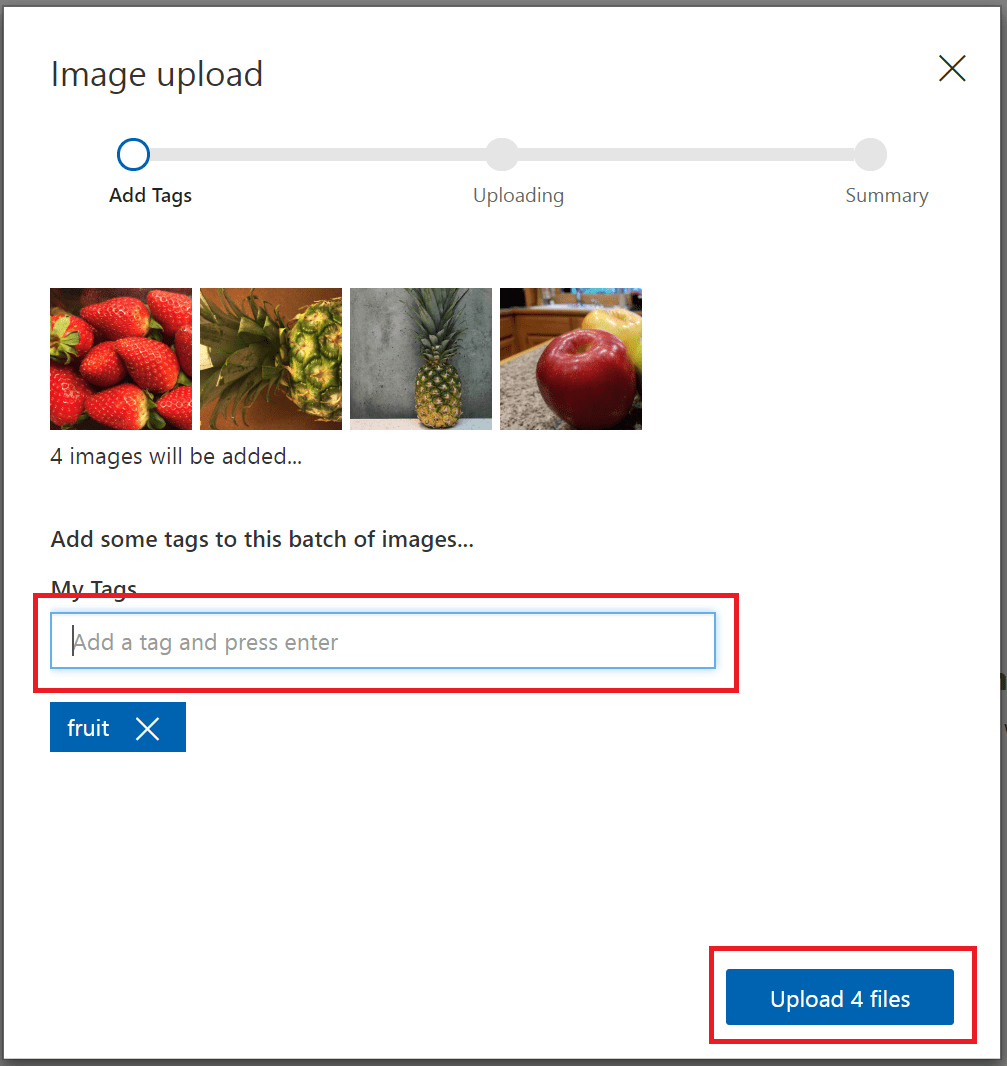
Po przekazaniu obrazów wybierz pozycję Gotowe .
Aby przekazać inny zestaw obrazów, wróć do góry tej sekcji i powtórz kroki.
Szkolenie klasyfikatora
Aby wytrenować klasyfikator, wybierz przycisk Trenuj . Klasyfikator używa wszystkich bieżących obrazów do utworzenia modelu identyfikującego cechy wizualne każdego tagu. Ten proces może potrwać kilka minut.

Proces trenowania powinien potrwać tylko kilka minut. W tym czasie informacje o procesie trenowania są wyświetlane na karcie Wydajność .
Ocena klasyfikatora
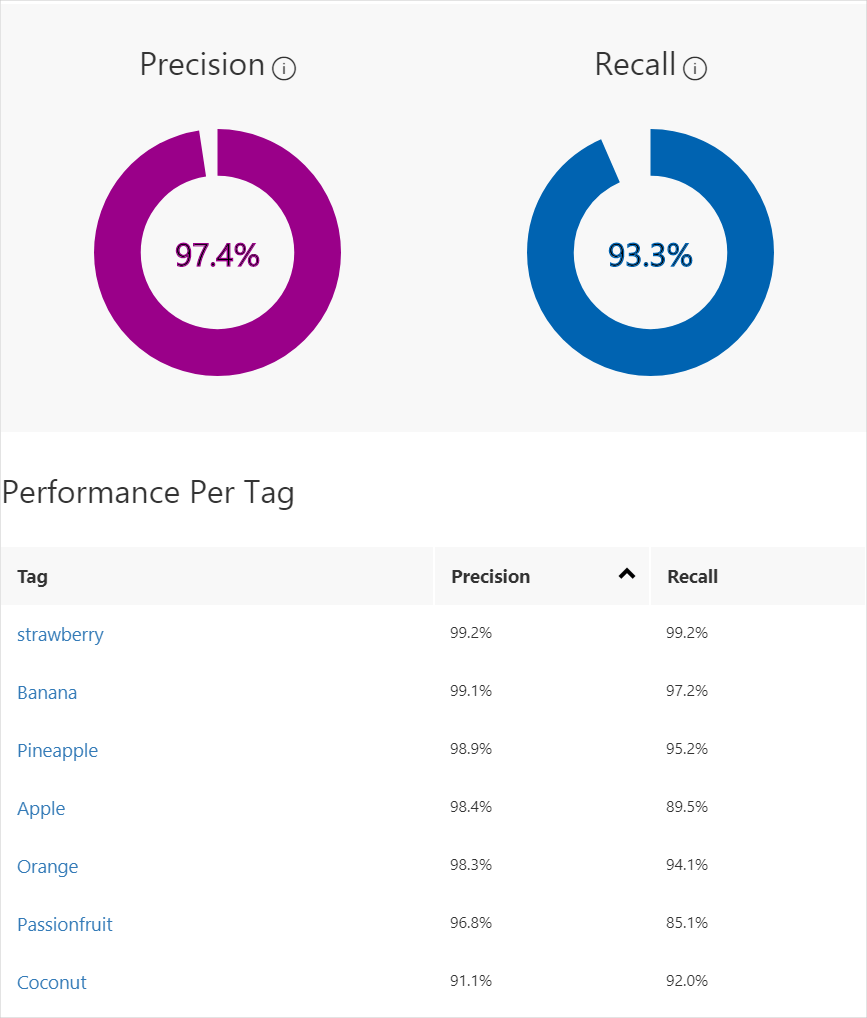
Po zakończeniu trenowania wydajność modelu jest szacowana i wyświetlana. Usługa Custom Vision Service używa obrazów przesłanych do trenowania w celu obliczenia dokładności i kompletności. Precyzja i kompletność to dwa różne pomiary skuteczności klasyfikatora:
- Precyzja wskazuje ułamek zidentyfikowanych klasyfikacji, które były poprawne. Jeśli na przykład model zidentyfikował 100 obrazów jako psy, a 99 z nich było rzeczywiście psami, precyzja wynosiłaby 99%.
- Kompletność wskazuje ułamek rzeczywistych klasyfikacji, które zostały prawidłowo zidentyfikowane. Jeśli na przykład faktycznie było 100 obrazów jabłek, a model zidentyfikował 80 jako jabłka, kompletność wyniesie 80%.
Próg prawdopodobieństwa
Zwróć uwagę na suwak Próg prawdopodobieństwa w lewym okienku karty Wydajność . Jest to poziom pewności, że przewidywanie musi być uznane za poprawne (na potrzeby obliczania precyzji i kompletności).
W przypadku interpretowania wywołań przewidywania z progiem wysokiego prawdopodobieństwa mają tendencję do zwracania wyników z wysoką precyzją kosztem kompletności — wykryte klasyfikacje są poprawne, ale wiele z nich pozostaje niezakrytych. Próg niskiego prawdopodobieństwa jest odwrotny — większość rzeczywistych klasyfikacji jest wykrywana, ale w tym zestawie jest więcej wyników fałszywie dodatnich. Mając to na uwadze, należy ustawić próg prawdopodobieństwa zgodnie z określonymi potrzebami projektu. Później, gdy otrzymujesz wyniki przewidywania po stronie klienta, należy użyć tej samej wartości progu prawdopodobieństwa, jak w tym miejscu.
Zarządzanie iteracjami trenowania
Za każdym razem, gdy trenujesz klasyfikator, należy utworzyć nową iterację ze zaktualizowanymi metrykami wydajności. Wszystkie iteracji można wyświetlić w lewym okienku karty Wydajność . Znajdziesz również przycisk Usuń , którego można użyć do usunięcia iteracji, jeśli jest przestarzała. Usunięcie iteracji powoduje usunięcie wszystkich obrazów, które są z nią unikatowo skojarzone.
Zobacz Używanie modelu z interfejsem API przewidywania, aby dowiedzieć się, jak programowo uzyskiwać dostęp do wytrenowanych modeli.
Następne kroki
W tym przewodniku Szybki start przedstawiono sposób tworzenia i trenowania modelu klasyfikacji obrazów przy użyciu portalu internetowego usługi Custom Vision. Następnie uzyskaj więcej informacji na temat iteracyjnego procesu ulepszania modelu.