Uzyskiwanie pozycji twarzy z viseme
Uwaga
Aby zapoznać się z ustawieniami regionalnymi obsługiwanymi dla identyfikatorów viseme i kształtów mieszania, zapoznaj się z listą wszystkich obsługiwanych ustawień regionalnych. Skalowalna grafika wektorowa (SVG) jest obsługiwana tylko dla en-US ustawień regionalnych.
Viseme to wizualny opis fonemy w języku mówionym. Definiuje położenie twarzy i ust, gdy osoba mówi. Każdy viseme przedstawia kluczowe pozy twarzy dla określonego zestawu fonezy.
Można użyć visemes do kontrolowania ruchu modeli awatarów 2D i 3D, aby pozycje twarzy były najlepiej dopasowane do syntetycznej mowy. Można na przykład:
- Utwórz animowanego wirtualnego asystenta głosowego dla inteligentnych kiosków, tworząc usługi zintegrowane w wielu trybach dla klientów.
- Twórz immersyjne transmisje wiadomości i ulepszaj środowiska odbiorców dzięki naturalnym ruchom twarzy i ust.
- Generuj więcej interaktywnych awatarów gier i postaci kreskówek, które mogą mówić z zawartością dynamiczną.
- Zrób bardziej efektywne filmy nauczania języka, które pomagają uczniom języka zrozumieć zachowanie ust każdego słowa i phoneme.
- Osoby z upośledzeniem słuchu może również odbierać dźwięki wizualnie i "czytanie ust" treści mowy, która pokazuje wizje na animowanej twarzy.
Aby uzyskać więcej informacji na temat wizemes, zobacz ten film wprowadzający.
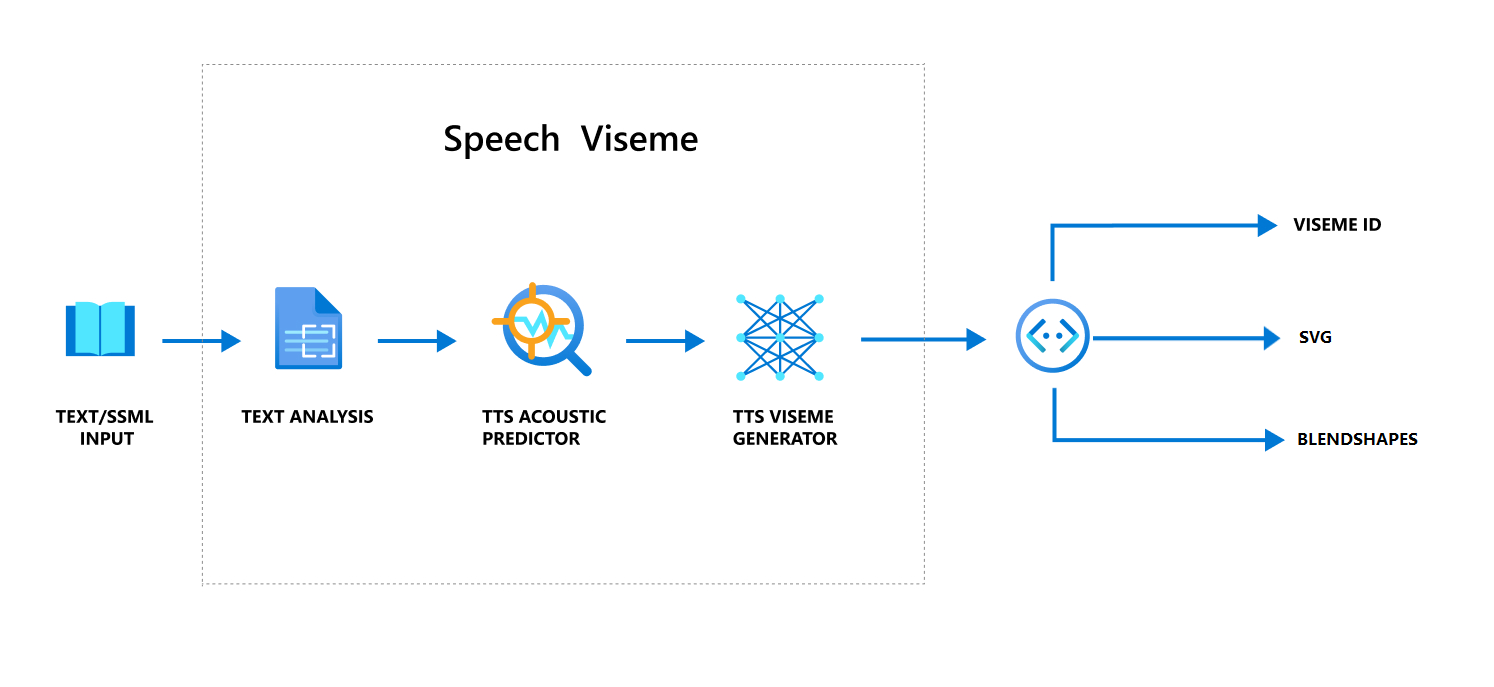
Ogólny przepływ pracy tworzenia wizualizacji z mową
Neuronowy tekst na mowę (neuronowy TTS) zamienia tekst wejściowy lub SSML (Język znaczników syntezy mowy) w żywą syntetyzację mowy. Dane wyjściowe dźwięku mowy mogą być dołączone za pomocą identyfikatora viseme, skalowalnej grafiki wektorowej (SVG) lub mieszania kształtów. Korzystając z aparatu renderowania 2D lub 3D, możesz użyć tych zdarzeń viseme do animowania awatara.
Ogólny przepływ pracy wizualizacji przedstawiono w następującym schemacie blokowym:
Identyfikator viseme
Identyfikator viseme odnosi się do liczby całkowitej, która określa viseme. Oferujemy 22 różne wizje, z których każda przedstawia położenie ust dla określonego zestawu fonemów. Nie ma żadnej korespondencji jeden do jednego między wizjerami i fonezami. Często kilka fonemów odpowiada jednemu wizjerowi, ponieważ wyglądało to samo na twarzy głośnika, gdy są produkowane, takie jak s i z. Aby uzyskać bardziej szczegółowe informacje, zobacz tabelę mapowania phonemes na identyfikatory viseme.
Do danych wyjściowych dźwięku mowy mogą towarzyszyć identyfikatory viseme i Audio offset. Wskazuje Audio offset znacznik czasu przesunięcia, który reprezentuje godzinę rozpoczęcia każdej viseme, w kleszczach (100 nanosekund).
Mapuj fonemy na wizje
Visemes różnią się w zależności od języka i ustawień regionalnych. Każde ustawienia regionalne mają zestaw wizjerów, które odpowiadają jego konkretnym fonemom. Dokumentacja alfabetów fonetycznych SSML mapuje identyfikatory viseme na odpowiadające fonemy International Telefon tic Alphabet (IPA). W tabeli w tej sekcji przedstawiono relację mapowania między identyfikatorami viseme i pozycjami ust, wyświetlając listę typowych phonemów IPA dla każdego identyfikatora viseme.
| Identyfikator viseme | IPA | Położenie ust |
|---|---|---|
| 0 | Wyciszyć |  |
| 1 | æ, , əʌ |
 |
| 2 | ɑ |
 |
| 3 | ɔ |
 |
| 100 | ɛ, ʊ |
 |
| 5 | ɝ |
 |
| 6 | j, , iɪ |
 |
| 7 | w, u |
 |
| 8 | o |
 |
| 9 | aʊ |
 |
| 10 | ɔɪ |
 |
| 11 | aɪ |
 |
| 12 | h |
 |
| 13 | ɹ |
 |
| 14 | l |
 |
| 15 | s, z |
 |
| 16 | ʃ, , tʃ, , dʒʒ |
 |
| 17 | ð |
 |
| 18 | f, v |
 |
| 19 | d, , t, , nθ |
 |
| 20 | k, , gŋ |
 |
| 21 | p, , bm |
 |
Animacja 2D SVG
W przypadku znaków 2D można zaprojektować znak odpowiadający scenariuszowi i użyć skalowalnej grafiki wektorowej (SVG) dla każdego identyfikatora wizeme, aby uzyskać położenie twarzy opartej na czasie.
W przypadku tagów czasowych, które są udostępniane w przypadku viseme, te dobrze zaprojektowane pliki SVGs są przetwarzane z wygładzonymi modyfikacjami i zapewniają niezawodną animację dla użytkowników. Na przykład poniższa ilustracja przedstawia znak z czerwoną wargą przeznaczoną do nauki języka.

Animacja kształtów mieszanych 3-W
Możesz użyć kształtów mieszania, aby napędzać ruchy twarzy znaku 3D, który został zaprojektowany.
Ciąg JSON kształtów mieszanych jest reprezentowany jako macierz dwuwymiarowa. Każdy wiersz reprezentuje ramkę. Każda ramka (w 60 FPS) zawiera tablicę 55 pozycji twarzy.
Uzyskiwanie zdarzeń viseme za pomocą zestawu Speech SDK
Aby uzyskać wizeme za pomocą syntetyzowanej mowy, zasubskrybuj VisemeReceived zdarzenie w zestawie SPEECH SDK.
Uwaga
Aby zażądać danych wyjściowych formatu SVG lub kształtów mieszania, należy użyć mstts:viseme elementu w języku SSML. Aby uzyskać szczegółowe informacje, zobacz , jak używać elementu viseme w języku SSML.
Poniższy fragment kodu przedstawia sposób subskrybowania zdarzenia viseme:
using (var synthesizer = new SpeechSynthesizer(speechConfig, audioConfig))
{
// Subscribes to viseme received event
synthesizer.VisemeReceived += (s, e) =>
{
Console.WriteLine($"Viseme event received. Audio offset: " +
$"{e.AudioOffset / 10000}ms, viseme id: {e.VisemeId}.");
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
var result = await synthesizer.SpeakSsmlAsync(ssml);
}
auto synthesizer = SpeechSynthesizer::FromConfig(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer->VisemeReceived += [](const SpeechSynthesisVisemeEventArgs& e)
{
cout << "viseme event received. "
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
<< "Audio offset: " << e.AudioOffset / 10000 << "ms, "
<< "viseme id: " << e.VisemeId << "." << endl;
// `Animation` is an xml string for SVG or a json string for blend shapes
auto animation = e.Animation;
};
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
auto result = synthesizer->SpeakSsmlAsync(ssml).get();
SpeechSynthesizer synthesizer = new SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.VisemeReceived.addEventListener((o, e) -> {
// The unit of e.AudioOffset is tick (1 tick = 100 nanoseconds), divide by 10,000 to convert to milliseconds.
System.out.print("Viseme event received. Audio offset: " + e.getAudioOffset() / 10000 + "ms, ");
System.out.println("viseme id: " + e.getVisemeId() + ".");
// `Animation` is an xml string for SVG or a json string for blend shapes
String animation = e.getAnimation();
});
// If VisemeID is the only thing you want, you can also use `SpeakTextAsync()`
SpeechSynthesisResult result = synthesizer.SpeakSsmlAsync(ssml).get();
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
def viseme_cb(evt):
print("Viseme event received: audio offset: {}ms, viseme id: {}.".format(
evt.audio_offset / 10000, evt.viseme_id))
# `Animation` is an xml string for SVG or a json string for blend shapes
animation = evt.animation
# Subscribes to viseme received event
speech_synthesizer.viseme_received.connect(viseme_cb)
# If VisemeID is the only thing you want, you can also use `speak_text_async()`
result = speech_synthesizer.speak_ssml_async(ssml).get()
var synthesizer = new SpeechSDK.SpeechSynthesizer(speechConfig, audioConfig);
// Subscribes to viseme received event
synthesizer.visemeReceived = function (s, e) {
window.console.log("(Viseme), Audio offset: " + e.audioOffset / 10000 + "ms. Viseme ID: " + e.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
var animation = e.animation;
}
// If VisemeID is the only thing you want, you can also use `speakTextAsync()`
synthesizer.speakSsmlAsync(ssml);
SPXSpeechSynthesizer *synthesizer =
[[SPXSpeechSynthesizer alloc] initWithSpeechConfiguration:speechConfig
audioConfiguration:audioConfig];
// Subscribes to viseme received event
[synthesizer addVisemeReceivedEventHandler: ^ (SPXSpeechSynthesizer *synthesizer, SPXSpeechSynthesisVisemeEventArgs *eventArgs) {
NSLog(@"Viseme event received. Audio offset: %fms, viseme id: %lu.", eventArgs.audioOffset/10000., eventArgs.visemeId);
// `Animation` is an xml string for SVG or a json string for blend shapes
NSString *animation = eventArgs.Animation;
}];
// If VisemeID is the only thing you want, you can also use `SpeakText`
[synthesizer speakSsml:ssml];
Oto przykład danych wyjściowych viseme.
(Viseme), Viseme ID: 1, Audio offset: 200ms.
(Viseme), Viseme ID: 5, Audio offset: 850ms.
……
(Viseme), Viseme ID: 13, Audio offset: 2350ms.
Po uzyskaniu danych wyjściowych viseme można użyć tych zdarzeń do prowadzenia animacji znaków. Możesz tworzyć własne postacie i automatycznie animować je.