Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY:
![]() NoSQL
NoSQL
![]() MongoDB
MongoDB
![]() Kasandra
Kasandra
![]() Gremlin
Gremlin
![]() Stół
Stół
Azure Cosmos DB to podstawowa usługa na platformie Azure, więc jest wdrażana we wszystkich regionach świadczenia usługi Azure na całym świecie, w tym w chmurach publicznych, suwerennych, Departamentu Obrony (DoD) i chmur rządowych.
Na wysokim poziomie dane kontenera usługi Azure Cosmos DB są partycjonowane w poziomie na wiele zestawów replik, które replikują zapisy w każdym regionie. Zestawy replik trwale zatwierdzają zapisy przy użyciu kworum większościowego.
Każdy region zawiera wszystkie partycje danych kontenera usługi Azure Cosmos DB i może obsługiwać odczyty, a także służyć do zapisu, gdy włączono zapisy w wielu regionach. Jeśli twoje konto usługi Azure Cosmos DB jest dystrybuowane w regionach N platformy Azure, będzie istnieć co najmniej N x 4 kopie wszystkich danych.
W centrum danych wdrażamy usługę Azure Cosmos DB i zarządzamy nią na ogromnych sygnaturach maszyn, z których każda ma dedykowany magazyn lokalny. W centrum danych usługa Azure Cosmos DB jest wdrażana w wielu klastrach, z których każda potencjalnie korzysta z wielu generacji sprzętu. Maszyny w klastrze są zwykle rozłożone na 10–20 domen błędów w celu zapewnienia wysokiej dostępności w regionie. Na poniższej ilustracji przedstawiono topologię globalnego systemu dystrybucji usługi Azure Cosmos DB:
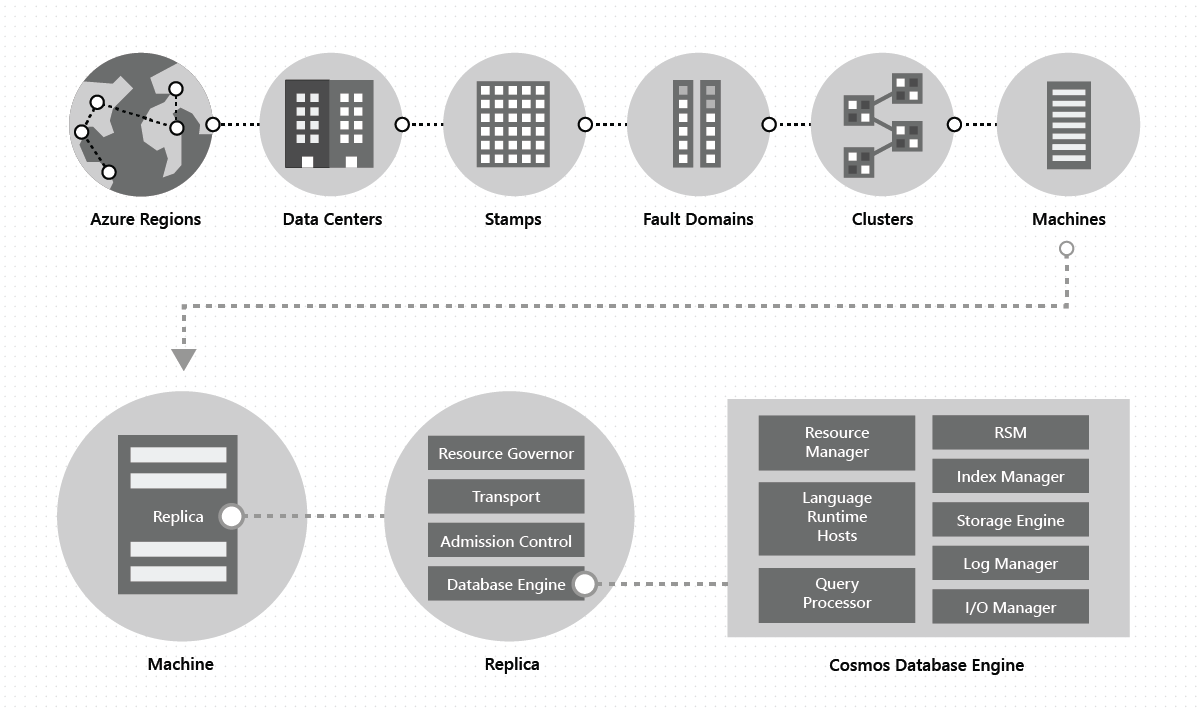
Dystrybucja globalna w usłudze Azure Cosmos DB jest gotowa do użycia: w dowolnym momencie za pomocą kilku kliknięć lub programowo za pomocą jednego wywołania interfejsu API można dodawać lub usuwać regiony geograficzne skojarzone z bazą danych usługi Azure Cosmos DB. Z kolei baza danych usługi Azure Cosmos DB składa się z zestawu kontenerów usługi Azure Cosmos DB. W usłudze Azure Cosmos DB kontenery służą jako jednostki logiczne dystrybucji i skalowalności. Tworzone kolekcje, tabele i grafy to (wewnętrznie) tylko kontenery usługi Azure Cosmos DB. Kontenery są całkowicie niezależne od schematu i zapewniają zakres zapytania. Dane w kontenerze usługi Azure Cosmos DB są automatycznie indeksowane podczas pozyskiwania. Automatyczne indeksowanie umożliwia użytkownikom wykonywanie zapytań dotyczących danych bez problemów z zarządzaniem schematem lub indeksem, szczególnie w konfiguracji rozproszonej globalnie.
W danym regionie dane w kontenerze są dystrybuowane przy użyciu klucza partycji, który podajesz i jest w sposób przezroczysty zarządzany przez bazowe partycje fizyczne (dystrybucja lokalna).
Każda partycja fizyczna jest również replikowana w różnych regionach geograficznych (dystrybucja globalna).
Gdy aplikacja korzystająca z usługi Azure Cosmos DB elastycznie skaluje przepływność w kontenerze usługi Azure Cosmos DB lub zużywa więcej miejsca do magazynowania, usługa Azure Cosmos DB w sposób przezroczysty obsługuje operacje zarządzania partycjami (podzielone, klonowanie, usuwanie) we wszystkich regionach. Niezależnie od skali, dystrybucji lub awarii usługa Azure Cosmos DB nadal udostępnia pojedynczy obraz systemu danych w kontenerach, które są globalnie rozproszone w dowolnej liczbie regionów.
Jak pokazano na poniższej ilustracji, dane w kontenerze są dystrybuowane wzdłuż dwóch wymiarów — w regionie i w różnych regionach na całym świecie:
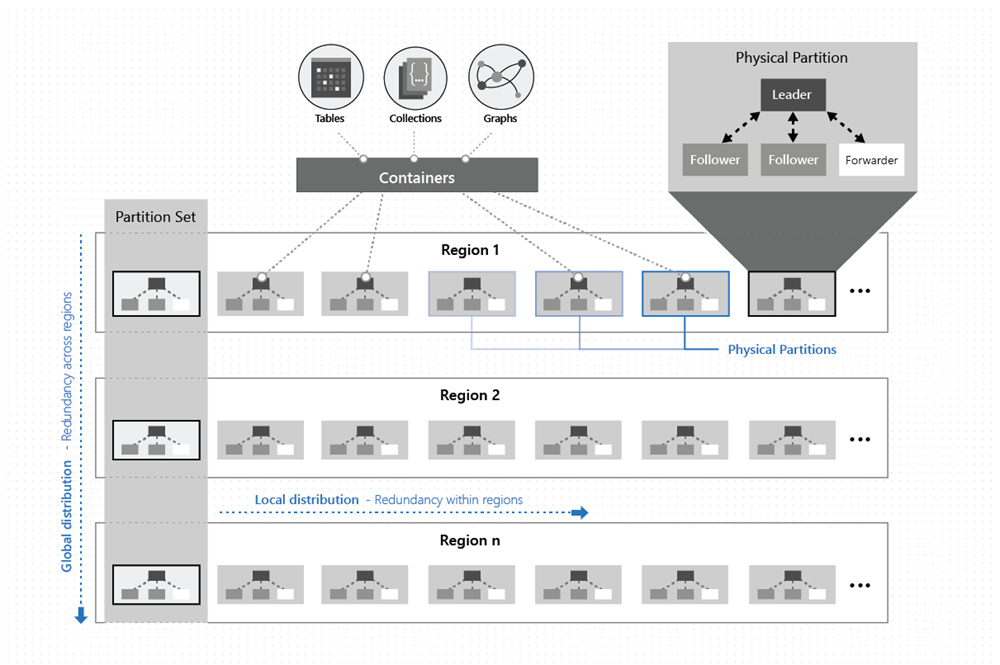
Partycja fizyczna jest implementowana przez grupę replik nazywanych zestawem replik. Każda maszyna hostuje setki replik odpowiadających różnym partycjom fizycznym w stałym zestawie procesów, jak pokazano na powyższym obrazie. Repliki odpowiadające partycjom fizycznym są dynamicznie umieszczane i równoważone obciążenie między maszynami w klastrze i centrach danych w regionie.
Replika unikatowo należy do dzierżawy usługi Azure Cosmos DB. Każda replika hostuje wystąpienie aparatu bazy danych usługi Azure Cosmos DB, które zarządza zasobami, a także skojarzonymi indeksami. Aparat bazy danych usługi Azure Cosmos DB działa w systemie typów opartym na atom-record-sequence (ARS). Aparat jest niezależny od koncepcji schematu, rozmycia granicy między strukturą a wartościami wystąpień rekordów. Usługa Azure Cosmos DB zapewnia pełną agnostykę schematu, automatycznie indeksując wszystko po pozyskiwaniu w wydajny sposób, co umożliwia użytkownikom wykonywanie zapytań o dane globalnie rozproszone bez konieczności zarządzania schematami lub indeksami.
Aparat bazy danych usługi Azure Cosmos DB składa się ze składników, w tym implementacji kilku elementów pierwotnych koordynacji, środowisk uruchomieniowych języka, procesora zapytań oraz podsystemów magazynowania i indeksowania odpowiedzialnych odpowiednio za magazyn transakcyjny i indeksowanie danych. Aby zapewnić trwałość i wysoką dostępność, aparat bazy danych utrzymuje swoje dane i indeksy na dyskach SSD i replikuje je między wystąpieniami aparatu bazy danych odpowiednio w zestawach replik. Większe dzierżawy odpowiadają wyższej skali przepływności i magazynu oraz mają większą lub większą liczbę replik lub obie. Każdy składnik systemu jest w pełni asynchroniczny — żaden wątek nigdy nie blokuje, a każdy wątek wykonuje krótkotrwałą pracę bez ponoszenia niepotrzebnych przełączników wątków. Ograniczanie szybkości i ciśnienie wsteczne są rozmieszczone w całym stosie z kontroli dostępu do wszystkich ścieżek we/wy. Aparat bazy danych usługi Azure Cosmos DB został zaprojektowany w celu wykorzystania szczegółowej współbieżności i zapewnienia wysokiej przepływności podczas pracy w oszczędnych ilościach zasobów systemowych.
Globalna dystrybucja usługi Azure Cosmos DB opiera się na dwóch kluczowych abstrakcji — zestawach replik i zestawach partycji. Zestaw replik jest modułowym blokiem konstrukcyjnym do koordynacji, a zestaw partycji to dynamiczna nakładka jednej lub większej liczby geograficznie rozproszonych partycji fizycznych. Aby zrozumieć, jak działa dystrybucja globalna, musimy zrozumieć te dwa kluczowe abstrakcji.
Zestawy replik
Partycja fizyczna jest zmaterializowana jako samozarządzana i dynamicznie zrównoważona obciążeniem grupa replik rozmieszczonych w wielu domenach błędów nazywanych zestawem replik. Ten zestaw zbiorczo implementuje zreplikowany protokół maszyny stanu, aby dane w partycji fizycznej były wysoce dostępne, trwałe i spójne. Członkostwo zestawu replik N jest dynamiczne — utrzymuje wahania między NMin i NMax w oparciu o błędy, operacje administracyjne i czas ponownego wygenerowania/odzyskania replik z niepowodzeniem. Na podstawie zmian członkostwa protokół replikacji zmienia również rozmiar kworum odczytu i zapisu. Aby równomiernie rozłożyć przepływność przypisaną do danej partycji fizycznej, stosujemy dwa pomysły:
Po pierwsze, koszt przetwarzania żądań zapisu na lidera jest wyższy niż koszt stosowania aktualizacji w obserwowaniu. W związku z tym lider jest budżetowany więcej zasobów systemowych niż obserwatorzy.
Po drugie, jeśli jest to możliwe, kworum odczytu dla danego poziomu spójności składa się wyłącznie z replik obserwowanych. Unikamy kontaktowania się z liderem w celu obsługi odczytów, chyba że jest to wymagane. Korzystamy z wielu pomysłów z badań przeprowadzonych na temat relacji obciążenia i pojemności w systemach opartych na kworum dla pięciu modeli spójności, które obsługuje usługa Azure Cosmos DB.
Zestawy partycji
Grupa partycji fizycznych, po jednym z każdego ze skonfigurowanych regionów bazy danych usługi Azure Cosmos DB, składa się z zarządzania tym samym zestawem kluczy replikowanych we wszystkich skonfigurowanych regionach. Ten wyższy element pierwotny koordynacji jest nazywany zestawem partycji — geograficznie rozproszoną dynamiczną nakładką partycji fizycznych zarządzających danym zestawem kluczy. Chociaż dana partycja fizyczna (zestaw replik) jest ograniczona w ramach klastra, zestaw partycji może obejmować klastry, centra danych i regiony geograficzne, jak pokazano na poniższej ilustracji:
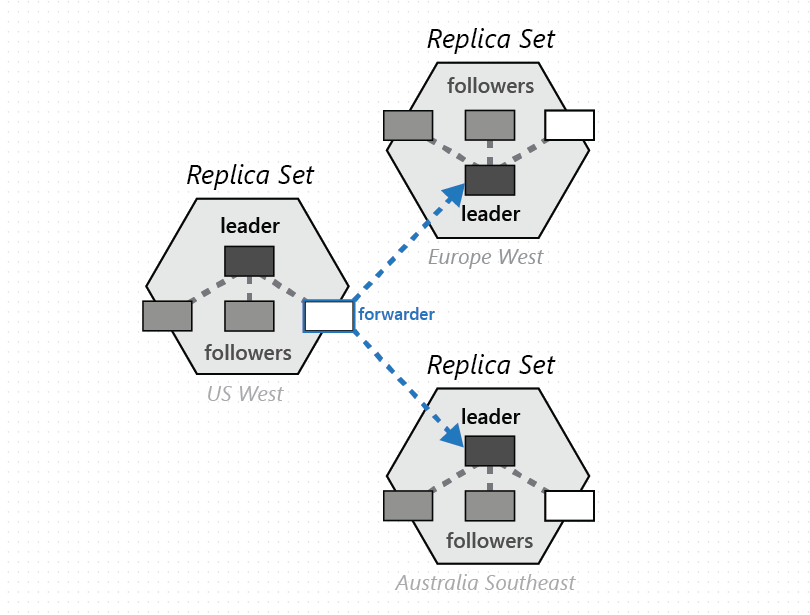
Zestaw partycji można traktować jako rozproszony geograficznie "super replica-set", który składa się z wielu zestawów replik będących właścicielem tego samego zestawu kluczy. Podobnie jak w przypadku zestawu replik, członkostwo zestawu partycji jest również dynamiczne — zmienia się na podstawie niejawnych operacji zarządzania partycjami fizycznymi w celu dodania/usunięcia nowych partycji do/z danego zestawu partycji (na przykład podczas skalowania przepływności w poziomie w kontenerze, dodawania/usuwania regionu do bazy danych Usługi Azure Cosmos DB lub wystąpienia awarii). Ze względu na to, że każda partycja (zestawu partycji) zarządza członkostwem zestawu partycji w ramach własnego zestawu replik, członkostwo jest w pełni zdecentralizowane i wysoce dostępne. Podczas ponownej konfiguracji zestawu partycji ustanawiana jest również topologia nakładki między partycjami fizycznymi. Topologia jest dynamicznie wybierana na podstawie poziomu spójności, odległości geograficznej i dostępnej przepustowości sieci między źródłem a docelowymi partycjami fizycznymi.
Usługa umożliwia skonfigurowanie baz danych usługi Azure Cosmos DB z jednym regionem zapisu lub wieloma regionami zapisu, a w zależności od wybranego wyboru zestawy partycji są skonfigurowane do akceptowania zapisów w dokładnie jednym lub wszystkich regionach. System stosuje dwu-poziomowy, zagnieżdżony protokół konsensusu — jeden poziom działa w ramach replik zestawu replik partycji fizycznej akceptującej zapisy, a drugi działa na poziomie zestawu partycji, aby zapewnić pełne gwarancje kolejności dla wszystkich zatwierdzonych zapisów w zestawie partycji. Ten wielowarstwowy, zagnieżdżony konsensus ma kluczowe znaczenie dla implementacji naszych rygorystycznych umów SLA w celu zapewnienia wysokiej dostępności, a także implementacji modeli spójności, które usługa Azure Cosmos DB oferuje swoim klientom.
Rozwiązywanie konfliktów
Nasz projekt propagacji aktualizacji, rozwiązywania konfliktów i śledzenia przyczynowości jest inspirowany wcześniejszymi pracami nad algorytmami epidemii i systemem Bayou. Podczas gdy jądra pomysłów przetrwały i zapewniają wygodną ramę referencyjną do komunikowania projektu systemu usługi Azure Cosmos DB, zostały one również poddane znaczącej transformacji, ponieważ zastosowano je do systemu usługi Azure Cosmos DB. Było to konieczne, ponieważ poprzednie systemy nie zostały zaprojektowane ani z zarządzaniem zasobami, ani ze skalą, w której usługa Azure Cosmos DB musi działać, ani nie zapewnia możliwości (na przykład powiązana spójność nieaktualności) oraz rygorystycznych i kompleksowych umów SLA oferowanych przez usługę Azure Cosmos DB klientom.
Pamiętaj, że zestaw partycji jest dystrybuowany w wielu regionach i jest zgodny z protokołem replikacji usługi Azure Cosmos DB (zapisy w wielu regionach), aby replikować dane między partycjami fizycznymi składającymi się z danego zestawu partycji. Każda partycja fizyczna (z zestawu partycji) akceptuje zapisy i obsługuje operacje odczytu zazwyczaj do klientów lokalnych w tym regionie. Zapisy akceptowane przez partycję fizyczną w regionie są trwale zatwierdzane i udostępniane w ramach partycji fizycznej przed ich potwierdzeniem dla klienta. Są to wstępne zapisy i są propagowane do innych partycji fizycznych w zestawie partycji przy użyciu kanału antyenttropii. Klienci mogą żądać wstępnie lub zatwierdzonych zapisów, przekazując nagłówek żądania. Propagacja antyenttropii (w tym częstotliwość propagacji) jest dynamiczna w oparciu o topologię zestawu partycji, regionalną bliskość partycji fizycznych i skonfigurowany poziom spójności. W ramach zestawu partycji usługa Azure Cosmos DB jest zgodna z podstawowym schematem zatwierdzeń z dynamicznie wybraną partycją arbitera. Wybór arbitera jest dynamiczny i jest integralną częścią rekonfiguracji zestawu partycji na podstawie topologii nakładki. Zatwierdzone zapisy (w tym aktualizacje wielowierszowe/wsadowe) są gwarantowane.
Stosujemy zakodowane zegary wektorowe (zawierające identyfikator regionu i zegary logiczne odpowiadające każdemu poziomowi konsensusu odpowiednio w zestawie replik i zestawie partycji) na potrzeby śledzenia przyczynowości i wektorów wersji w celu wykrywania i rozwiązywania konfliktów aktualizacji. Topologia i algorytm wyboru elementów równorzędnych zostały zaprojektowane w celu zapewnienia stałego i minimalnego nakładu pracy wektorów wersji oraz minimalnego obciążenia sieciowego. Algorytm gwarantuje ścisłą właściwość zbieżności.
W przypadku baz danych usługi Azure Cosmos DB skonfigurowanych w wielu regionach zapisu system oferuje szereg elastycznych zasad automatycznego rozwiązywania konfliktów dla deweloperów do wyboru, w tym:
- Last-Write-Wins (LWW), która domyślnie używa właściwości sygnatury czasowej zdefiniowanej przez system (która jest oparta na protokole zegara synchronizacji czasowej). Usługa Azure Cosmos DB umożliwia również określenie dowolnej innej niestandardowej właściwości liczbowej, która ma być używana do rozwiązywania konfliktów.
- Zasady rozwiązywania konfliktów zdefiniowane przez aplikację (niestandardowe) (wyrażone za pośrednictwem procedur scalania), które są przeznaczone do semantyki zdefiniowanej przez aplikację w celu uzgadniania konfliktów. Te procedury są wywoływane po wykryciu konfliktów zapisu i zapisu w ramach pomyślności transakcji bazy danych po stronie serwera. System zapewnia dokładnie raz gwarancję wykonania procedury scalania w ramach protokołu zobowiązania. Dostępnych jest kilka przykładów rozwiązywania konfliktów , z których można korzystać.
Modele spójności
Niezależnie od tego, czy konfigurujesz bazę danych usługi Azure Cosmos DB z jednym lub wieloma regionami zapisu, możesz wybrać spośród pięciu dobrze zdefiniowanych modeli spójności. W przypadku wielu regionów zapisu poniżej przedstawiono kilka istotnych aspektów poziomów spójności:
Spójność powiązana nieaktualność gwarantuje, że wszystkie operacje odczytu będą znajdować się w prefiksach K lub T sekundach od najnowszego zapisu w dowolnym z regionów. Ponadto operacje odczytu z powiązaną spójnością nieaktualności mają gwarancję monotonicznego i spójnego gwarancji prefiksu. Protokół antyenttropii działa w sposób ograniczony do szybkości i zapewnia, że prefiksy nie gromadzą się, a backpressure na zapisach nie trzeba stosować. Spójność sesji gwarantuje monotoniczny odczyt, monotoniczny zapis, odczyt własnych zapisów, zapis jest zgodny z gwarancją odczytu i spójnym prefiksem na całym świecie. W przypadku baz danych skonfigurowanych z silną spójnością korzyści (małe opóźnienia zapisu, wysoka dostępność zapisu) wielu regionów zapisu nie mają zastosowania ze względu na synchroniczną replikację między regionami.
Semantyka pięciu modeli spójności w usłudze Azure Cosmos DB została opisana tutaj i matematycznie opisana przy użyciu specyfikacji TLA+ wysokiego poziomu w tym miejscu.
Następne kroki
Następnie dowiedz się, jak skonfigurować dystrybucję globalną, korzystając z następujących artykułów:
- Dodawanie/usuwanie regionów z konta bazy danych
- Jak utworzyć niestandardowe zasady rozwiązywania konfliktów
- Próbujesz zaplanować pojemność migracji do usługi Azure Cosmos DB? Informacje o istniejącym klastrze bazy danych można użyć do planowania pojemności.
- Jeśli wiesz, ile rdzeni wirtualnych i serwerów znajduje się w istniejącym klastrze bazy danych, przeczytaj o szacowaniu jednostek żądań przy użyciu rdzeni wirtualnych lub procesorów wirtualnych
- Jeśli znasz typowe stawki żądań dla bieżącego obciążenia bazy danych, przeczytaj o szacowaniu jednostek żądań przy użyciu planisty pojemności usługi Azure Cosmos DB