Używanie grafu podzielonego na partycje w usłudze Azure Cosmos DB
DOTYCZY: ![]() Gremlin
Gremlin
Jedną z kluczowych funkcji interfejsu API dla języka Gremlin w usłudze Azure Cosmos DB jest możliwość obsługi grafów na dużą skalę przez skalowanie w poziomie. Kontenery mogą być skalowane niezależnie pod względem magazynu i przepływności. Kontenery można tworzyć w usłudze Azure Cosmos DB, które można automatycznie skalować w celu przechowywania danych grafu. Dane są automatycznie zrównoważone na podstawie określonego klucza partycji.
Partycjonowanie odbywa się wewnętrznie, jeśli kontener ma przechowywać więcej niż 20 GB rozmiaru lub jeśli chcesz przydzielić więcej niż 10 000 jednostek żądań na sekundę (jednostki RU). Dane są automatycznie partycjonowane na podstawie określonego klucza partycji. Klucz partycji jest wymagany w przypadku tworzenia kontenerów grafów w witrynie Azure Portal lub w wersji 3.x lub nowszej sterowników języka Gremlin. Klucz partycji nie jest wymagany, jeśli używasz sterowników Języka Gremlin w wersji 2.x lub niższej.
Te same ogólne zasady z mechanizmu partycjonowania usługi Azure Cosmos DB mają zastosowanie z kilkoma optymalizacjami specyficznymi dla grafu opisanymi poniżej.
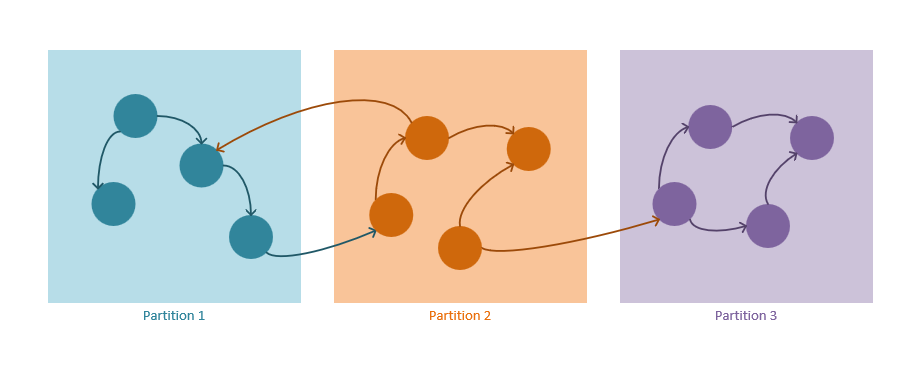
Mechanizm partycjonowania grafu
W poniższych wytycznych opisano sposób działania strategii partycjonowania w usłudze Azure Cosmos DB:
Oba wierzchołki i krawędzie są przechowywane jako dokumenty JSON.
Wierzchołki wymagają klucza partycji. Ten klucz określi, w której partycji wierzchołek będzie przechowywany za pomocą algorytmu wyznaczania wartości skrótu. Nazwa właściwości klucza partycji jest definiowana podczas tworzenia nowego kontenera i ma format:
/partitioning-key-name.Krawędzie będą przechowywane z ich wierzchołkiem źródłowym. Innymi słowy, dla każdego wierzchołka klucz partycji definiuje, gdzie są przechowywane wraz z jego krawędziami wychodzącymi. Ta optymalizacja jest wykonywana w celu uniknięcia zapytań obejmujących wiele partycji podczas korzystania z
out()kardynalności w zapytaniach grafu.Krawędzie zawierają odwołania do wierzchołków, do których wskazują. Wszystkie krawędzie są przechowywane z kluczami partycji i identyfikatorami wierzchołków, na które wskazują. To obliczenie sprawia, że wszystkie
out()zapytania w każdym kierunku są zawsze zapytaniem podzielonym na partycje w zakresie, a nie ślepym zapytaniem między partycjami.Zapytania programu Graph muszą określać klucz partycji. Aby w pełni wykorzystać partycjonowanie poziome w usłudze Azure Cosmos DB, klucz partycji należy określić po wybraniu pojedynczego wierzchołka zawsze, gdy jest to możliwe. Poniżej przedstawiono zapytania dotyczące wybierania jednego lub wielu wierzchołków na wykresie podzielonym na partycje:
/idi/labelnie są obsługiwane jako klucze partycji dla kontenera w interfejsie API dla języka Gremlin.Wybranie wierzchołka według identyfikatora, a następnie użycie
.has()kroku w celu określenia właściwości klucza partycji:g.V('vertex_id').has('partitionKey', 'partitionKey_value')Wybranie wierzchołka przez określenie krotki zawierającej wartość klucza partycji i identyfikator:
g.V(['partitionKey_value', 'vertex_id'])Wybranie zestawu wierzchołków z ich identyfikatorami i określenie listy wartości klucza partycji:
g.V('vertex_id0', 'vertex_id1', 'vertex_id2', …).has('partitionKey', within('partitionKey_value0', 'partitionKey_value01', 'partitionKey_value02', …)Korzystając ze strategii partycjonowania na początku zapytania i określając partycję dla zakresu pozostałej części zapytania Gremlin:
g.withStrategies(PartitionStrategy.build().partitionKey('partitionKey').readPartitions('partitionKey_value').create()).V()
Najlepsze rozwiązania dotyczące korzystania z partycjonowanego grafu
Skorzystaj z poniższych wskazówek, aby zapewnić wydajność i skalowalność podczas korzystania z partycjonowanych grafów z nieograniczonymi kontenerami:
Zawsze należy określić wartość klucza partycji podczas wykonywania zapytań względem wierzchołka. Pobieranie wierzchołka ze znanej partycji to sposób na osiągnięcie wydajności. Wszystkie kolejne operacje sąsiedztwa będą zawsze ograniczone do partycji, ponieważ krawędzie zawierają identyfikator odwołania i klucz partycji do ich wierzchołków docelowych.
Użyj kierunku wychodzącego podczas wykonywania zapytań dotyczących krawędzi, gdy jest to możliwe. Jak wspomniano powyżej, krawędzie są przechowywane ze swoimi wierzchołkami źródłowymi w kierunku wychodzącym. Dlatego szanse na uciekanie się do zapytań obejmujących wiele partycji są zminimalizowane, gdy dane i zapytania są zaprojektowane z myślą o tym wzorcu. Wręcz przeciwnie,
in()zapytanie zawsze będzie kosztowną kwerendą fan-out.Wybierz klucz partycji, który będzie równomiernie dystrybuować dane między partycjami. Ta decyzja w dużym stopniu zależy od modelu danych rozwiązania. Przeczytaj więcej na temat tworzenia odpowiedniego klucza partycji w temacie Partycjonowanie i skalowanie w usłudze Azure Cosmos DB.
Zoptymalizuj zapytania, aby uzyskać dane w granicach partycji. Optymalna strategia partycjonowania zostanie dopasowana do wzorców wykonywania zapytań. Zapytania, które uzyskują dane z jednej partycji, zapewniają najlepszą możliwą wydajność.
Następne kroki
Następnie możesz przeczytać następujące artykuły:
- Dowiedz się więcej na temat partycjonowania i skalowania w usłudze Azure Cosmos DB.
- Dowiedz się więcej o obsłudze języka Gremlin w interfejsie API dla języka Gremlin.
- Dowiedz się więcej na temat wprowadzenia do interfejsu API dla języka Gremlin.