Migrowanie setek terabajtów danych do usługi Azure Cosmos DB
DOTYCZY: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Kasandra
Kasandra ![]() Gremlin
Gremlin ![]() Stół
Stół
Usługa Azure Cosmos DB może przechowywać terabajty danych. Można przeprowadzić migrację danych na dużą skalę, aby przenieść obciążenie produkcyjne do usługi Azure Cosmos DB. W tym artykule opisano wyzwania związane z przenoszeniem danych na dużą skalę do usługi Azure Cosmos DB oraz przedstawiono narzędzie, które pomaga sprostać tym wyzwaniom i migruje dane do usługi Azure Cosmos DB. W tym badaniu przypadku klient użył interfejsu API usługi Azure Cosmos DB dla noSQL.
Przed przeprowadzeniem migracji całego obciążenia do usługi Azure Cosmos DB możesz przeprowadzić migrację podzestawu danych, aby zweryfikować niektóre aspekty, takie jak wybór klucza partycji, wydajność zapytań i modelowanie danych. Po zweryfikowaniu weryfikacji koncepcji możesz przenieść całe obciążenie do usługi Azure Cosmos DB.
Narzędzia do migracji danych
Strategie migracji usługi Azure Cosmos DB różnią się obecnie w zależności od wyboru interfejsu API i rozmiaru danych. Aby przeprowadzić migrację mniejszych zestawów danych — do sprawdzania poprawności modelowania danych, wydajności zapytań, wyboru klucza partycji itp. — możesz użyć łącznika usługi Azure Cosmos DB w usłudze Azure Data Factory. Jeśli znasz platformę Spark, możesz również użyć łącznika Spark usługi Azure Cosmos DB do migracji danych.
Wyzwania związane z migracjami na dużą skalę
Istniejące narzędzia do migrowania danych do usługi Azure Cosmos DB mają pewne ograniczenia, które stają się szczególnie widoczne na dużych skalach:
Ograniczone możliwości skalowania w poziomie: aby migrować terabajty danych do usługi Azure Cosmos DB tak szybko, jak to możliwe, i aby efektywnie korzystać z całej aprowizowanej przepływności, klienci migracji powinni mieć możliwość skalowania w poziomie na czas nieokreślony.
Brak śledzenia postępu i wskazywania kontrolnego: ważne jest, aby śledzić postęp migracji i sprawdzać podczas migrowania dużych zestawów danych. W przeciwnym razie wszelkie błędy występujące podczas migracji spowodują zatrzymanie migracji i należy uruchomić proces od podstaw. Ponowne uruchomienie całego procesu migracji nie byłoby wydajne, gdy 99% zostało już ukończonych.
Brak kolejki utraconych komunikatów: w przypadku dużych zestawów danych w niektórych przypadkach mogą występować problemy z częściami danych źródłowych. Ponadto mogą wystąpić przejściowe problemy z klientem lub siecią. Żaden z tych przypadków nie powinien powodować niepowodzenia całej migracji. Mimo że większość narzędzi migracji ma niezawodne możliwości ponawiania prób, które chronią przed sporadycznymi problemami, nie zawsze jest to wystarczające. Jeśli na przykład mniej niż 0,01% dokumentów danych źródłowych jest większe niż 2 MB, spowoduje to niepowodzenie zapisu dokumentu w usłudze Azure Cosmos DB. Najlepiej jest, aby narzędzie do migracji utrwalało te "nieudane" dokumenty do innej kolejki utraconych komunikatów, które można przetworzyć po migracji.
Wiele z tych ograniczeń jest stałych dla narzędzi, takich jak Azure Data factory, Azure Data Migration Services.
Narzędzie niestandardowe z biblioteką funkcji wykonawczej operacji zbiorczych
Wyzwania opisane w powyższej sekcji można rozwiązać za pomocą niestandardowego narzędzia, które można łatwo skalować w poziomie w wielu wystąpieniach i jest odporny na błędy przejściowe. Ponadto narzędzie niestandardowe może wstrzymywać i wznawiać migrację w różnych punktach kontrolnych. Usługa Azure Cosmos DB udostępnia już bibliotekę funkcji wykonawczej operacji zbiorczych, która zawiera niektóre z tych funkcji. Na przykład biblioteka funkcji wykonawczej operacji zbiorczych ma już funkcje do obsługi błędów przejściowych i może skalować wątki w poziomie w jednym węźle, aby korzystać z około 500 jednostek RU na węzeł. Biblioteka funkcji wykonawczej operacji zbiorczych dzieli również źródłowy zestaw danych na mikrosady, które są obsługiwane niezależnie jako forma tworzenia punktów kontrolnych.
Narzędzie niestandardowe używa biblioteki funkcji wykonawczej operacji zbiorczych i obsługuje skalowanie w poziomie przez wielu klientów oraz śledzenie błędów podczas procesu pozyskiwania. Aby użyć tego narzędzia, dane źródłowe powinny być podzielone na odrębne pliki w usłudze Azure Data Lake Storage (ADLS), aby różne procesy robocze migracji mogły odebrać każdy plik i pozyskać je do usługi Azure Cosmos DB. Narzędzie niestandardowe korzysta z oddzielnej kolekcji, która przechowuje metadane dotyczące postępu migracji dla każdego pojedynczego pliku źródłowego w usłudze ADLS i śledzi wszelkie skojarzone z nimi błędy.
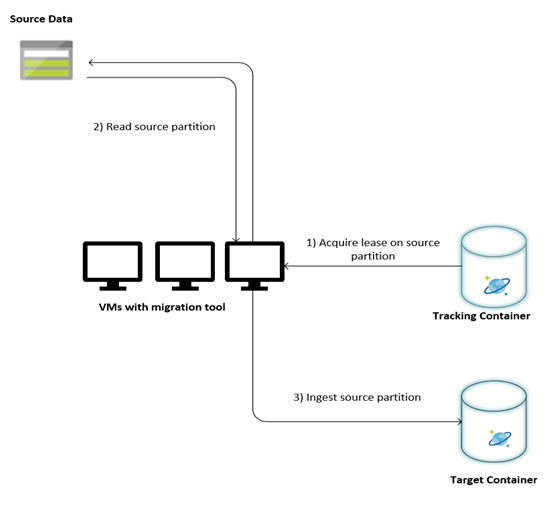
Na poniższej ilustracji opisano proces migracji przy użyciu tego narzędzia niestandardowego. Narzędzie jest uruchomione na zestawie maszyn wirtualnych, a każda maszyna wirtualna wysyła zapytanie do kolekcji śledzenia w usłudze Azure Cosmos DB w celu uzyskania dzierżawy na jednej z partycji danych źródłowych. Po wykonaniu tej czynności źródłowa partycja danych jest odczytywana przez narzędzie i pozyskiwana do usługi Azure Cosmos DB przy użyciu biblioteki funkcji wykonawczej zbiorczej. Następnie kolekcja śledzenia zostanie zaktualizowana w celu zarejestrowania postępu pozyskiwania danych i napotkanych błędów. Po przetworzeniu partycji danych narzędzie próbuje wysłać zapytanie o następną dostępną partycję źródłową. Będzie ona nadal przetwarzać następną partycję źródłową do momentu zmigrowania wszystkich danych. Kod źródłowy narzędzia jest dostępny w repozytorium pozyskiwania zbiorczego usługi Azure Cosmos DB.
Kolekcja śledzenia zawiera dokumenty, jak pokazano w poniższym przykładzie. Takie dokumenty będą widoczne dla każdej partycji w danych źródłowych. Każdy dokument zawiera metadane partycji danych źródłowych, takie jak jego lokalizacja, stan migracji i błędy (jeśli istnieją):
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
Wymagania wstępne dotyczące migracji danych
Przed rozpoczęciem migracji danych należy wziąć pod uwagę kilka wymagań wstępnych:
Szacowanie rozmiaru danych:
Rozmiar danych źródłowych może nie być dokładnie mapowy na rozmiar danych w usłudze Azure Cosmos DB. W celu sprawdzenia rozmiaru danych w usłudze Azure Cosmos DB można wstawić kilka przykładowych dokumentów ze źródła. W zależności od rozmiaru przykładowego dokumentu można oszacować całkowity rozmiar danych po migracji w usłudze Azure Cosmos DB.
Jeśli na przykład każdy dokument po migracji w usłudze Azure Cosmos DB wynosi około 1 KB, a w źródłowym zestawie danych znajduje się około 60 miliardów dokumentów, oznaczałoby to, że szacowany rozmiar w usłudze Azure Cosmos DB będzie zbliżony do 60 TB.
Wstępnie utwórz kontenery z wystarczającą ilością jednostek RU:
Chociaż usługa Azure Cosmos DB automatycznie skaluje magazyn w poziomie, nie zaleca się rozpoczynania od najmniejszego rozmiaru kontenera. Mniejsze kontenery mają niższą dostępność przepływności, co oznacza, że ukończenie migracji potrwa znacznie dłużej. Zamiast tego warto utworzyć kontenery o końcowym rozmiarze danych (szacowanym w poprzednim kroku) i upewnić się, że obciążenie migracji w pełni zużywa aprowizowaną przepływność.
W poprzednim kroku. ponieważ rozmiar danych oszacowano na około 60 TB, do obsługi całego zestawu danych wymagany jest kontener o rozmiarze co najmniej 2,4 M JEDNOSTEK RU.
Szacowanie szybkości migracji:
Zakładając, że obciążenie migracji może zużywać całą aprowizowaną przepływność, aprowizowanie w całym systemie zapewni oszacowanie szybkości migracji. Kontynuując poprzedni przykład, do pisania dokumentu o rozmiarze 1 KB do interfejsu API usługi Azure Cosmos DB dla konta NoSQL wymagane jest 5 jednostek RU. 2,4 mln jednostek RU umożliwiłoby przeniesienie 480 000 dokumentów na sekundę (lub 480 MB/s). Oznacza to, że całkowita migracja 60 TB potrwa 125 000 sekund lub około 34 godzin.
Jeśli chcesz, aby migracja została ukończona w ciągu dnia, należy zwiększyć aprowizowaną przepływność do 5 milionów jednostek RU.
Wyłącz indeksowanie:
Ponieważ migracja powinna zostać ukończona tak szybko, jak to możliwe, zaleca się zminimalizowanie czasu i jednostek RU spędzonych na tworzeniu indeksów dla każdego pozyskanego dokumentu. Usługa Azure Cosmos DB automatycznie indeksuje wszystkie właściwości. Warto zminimalizować indeksowanie do wybranych kilku terminów lub wyłączyć je całkowicie na potrzeby migracji. Zasady indeksowania kontenera można wyłączyć, zmieniając wartość indexingMode na brak, jak pokazano poniżej:
{
"indexingMode": "none"
}
Po zakończeniu migracji można zaktualizować indeksowanie.
Proces migracji
Po zakończeniu wymagań wstępnych możesz przeprowadzić migrację danych, wykonując następujące kroki:
Najpierw zaimportuj dane ze źródła do usługi Azure Blob Storage. Aby zwiększyć szybkość migracji, warto zrównać różne partycje źródłowe. Przed rozpoczęciem migracji zestaw danych źródłowych powinien zostać podzielony na pliki o rozmiarze około 200 MB.
Biblioteka funkcji wykonawczej operacji zbiorczych może być skalowana w górę, aby korzystać z 500 000 jednostek RU na jednej maszynie wirtualnej klienta. Ponieważ dostępna przepływność wynosi 5 milionów jednostek RU, należy aprowizować 10 maszyn wirtualnych z systemem Ubuntu 16.04 (Standard_D32_v3) w tym samym regionie, w którym znajduje się baza danych usługi Azure Cosmos DB. Te maszyny wirtualne należy przygotować za pomocą narzędzia do migracji i jego pliku ustawień.
Uruchom krok kolejki na jednej z maszyn wirtualnych klienta. Ten krok tworzy kolekcję śledzenia, która skanuje kontener usługi ADLS i tworzy dokument śledzenia postępu dla każdego z plików partycji zestawu danych źródłowych.
Następnie uruchom krok importowania na wszystkich maszynach wirtualnych klienta. Każdy z klientów może przejąć własność na partycji źródłowej i pozyskiwać dane do usługi Azure Cosmos DB. Po zakończeniu i zaktualizowaniu stanu w kolekcji śledzenia klienci mogą następnie wykonywać zapytania dotyczące następnej dostępnej partycji źródłowej w kolekcji śledzenia.
Ten proces będzie kontynuowany do momentu pozyskiwania całego zestawu partycji źródłowych. Po przetworzeniu wszystkich partycji źródłowych narzędzie powinno zostać uruchomione ponownie w trybie korekty błędów w tej samej kolekcji śledzenia. Ten krok jest wymagany do zidentyfikowania partycji źródłowych, które powinny zostać ponownie przetworzone z powodu błędów.
Niektóre z tych błędów mogą być spowodowane nieprawidłowymi dokumentami w danych źródłowych. Należy je zidentyfikować i naprawić. Następnie należy ponownie uruchomić krok importowania na partycjach, które zakończyły się niepowodzeniem, aby je ponownie pozyskać.
Po zakończeniu migracji można sprawdzić, czy liczba dokumentów w usłudze Azure Cosmos DB jest taka sama jak liczba dokumentów w źródłowej bazie danych. W tym przykładzie łączny rozmiar w usłudze Azure Cosmos DB okazał się wynosić 65 terabajtów. Po migracji indeksowanie może być selektywnie włączone, a jednostki RU można obniżyć do poziomu wymaganego przez operacje obciążenia.
Następne kroki
- Dowiedz się więcej, wypróbowywanie przykładowych aplikacji używających biblioteki funkcji wykonawczej zbiorczej na platformie .NET i w języku Java.
- Biblioteka funkcji wykonawczej zbiorczej jest zintegrowana z łącznikiem platformy Spark usługi Azure Cosmos DB, aby dowiedzieć się więcej, zobacz artykuł Dotyczący łącznika spark usługi Azure Cosmos DB.
- Skontaktuj się z zespołem produktu usługi Azure Cosmos DB, otwierając bilet pomocy technicznej pod typem problemu "Ogólne porady" i podtypem problemu "Duże (TB+), aby uzyskać dodatkową pomoc dotyczącą migracji na dużą skalę.
- Próbujesz zaplanować pojemność migracji do usługi Azure Cosmos DB? Informacje o istniejącym klastrze bazy danych można użyć do planowania pojemności.
- Jeśli wiesz, ile rdzeni wirtualnych i serwerów znajduje się w istniejącym klastrze bazy danych, przeczytaj o szacowaniu jednostek żądań przy użyciu rdzeni wirtualnych lub procesorów wirtualnych
- Jeśli znasz typowe stawki żądań dla bieżącego obciążenia bazy danych, przeczytaj o szacowaniu jednostek żądań przy użyciu planisty pojemności usługi Azure Cosmos DB