Zarządzanie indeksowaniem w usłudze Azure Cosmos DB dla bazy danych MongoDB
DOTYCZY: ![]() MongoDB
MongoDB
Usługa Azure Cosmos DB dla bazy danych MongoDB korzysta z podstawowych funkcji zarządzania indeksami w usłudze Azure Cosmos DB. W tym artykule opisano sposób dodawania indeksów przy użyciu usługi Azure Cosmos DB dla bazy danych MongoDB. Indeksy to wyspecjalizowane struktury danych, które sprawiają, że wykonywanie zapytań o dane jest mniej więcej o wiele większe.
Indeksowanie dla serwera MongoDB w wersji 3.6 lub nowszej
Serwer usługi Azure Cosmos DB dla bazy danych MongoDB w wersji 3.6 lub nowszej automatycznie indeksuje _id pole i klucz fragmentu (tylko w kolekcjach podzielonych na fragmenty). Interfejs API automatycznie wymusza unikatowość _id pola na klucz fragmentu.
Interfejs API dla bazy danych MongoDB działa inaczej niż usługa Azure Cosmos DB for NoSQL, która domyślnie indeksuje wszystkie pola.
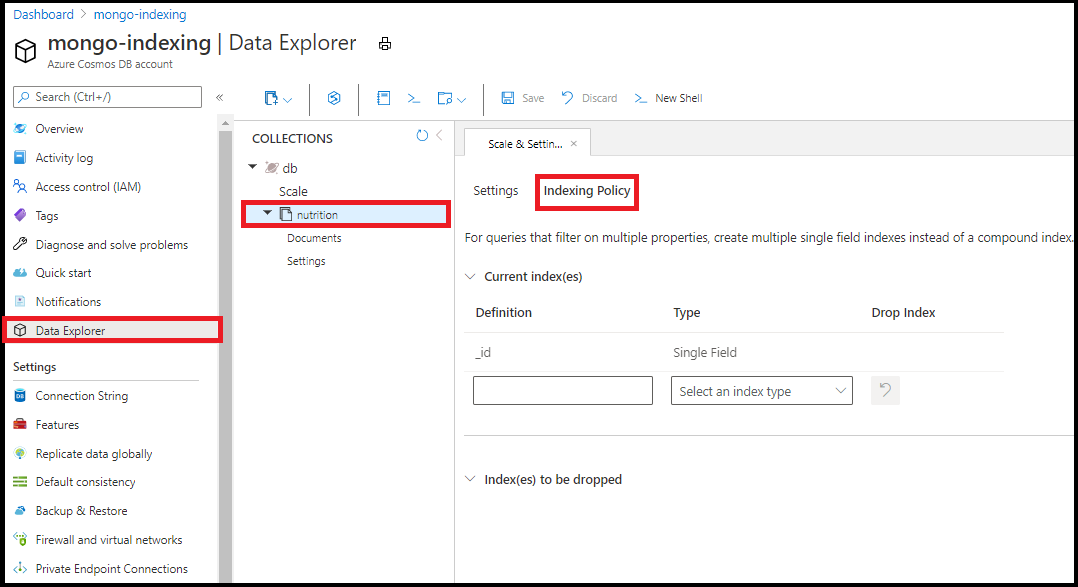
Edytowanie zasad indeksowania
Zalecamy edytowanie zasad indeksowania w Eksploratorze danych w witrynie Azure Portal. Możesz dodać pojedyncze pole i indeksy wieloznaczne z edytora zasad indeksowania w Eksploratorze danych:
Uwaga
Nie można tworzyć indeksów złożonych przy użyciu edytora zasad indeksowania w Eksploratorze danych.
Typy indeksów
Jedno pole
Indeksy można tworzyć w dowolnym pojedynczym polu. Kolejność sortowania indeksu pojedynczego pola nie ma znaczenia. Następujące polecenie tworzy indeks w polu name:
db.coll.createIndex({name:1})
Możesz utworzyć ten sam indeks name pojedynczego pola w witrynie Azure Portal:
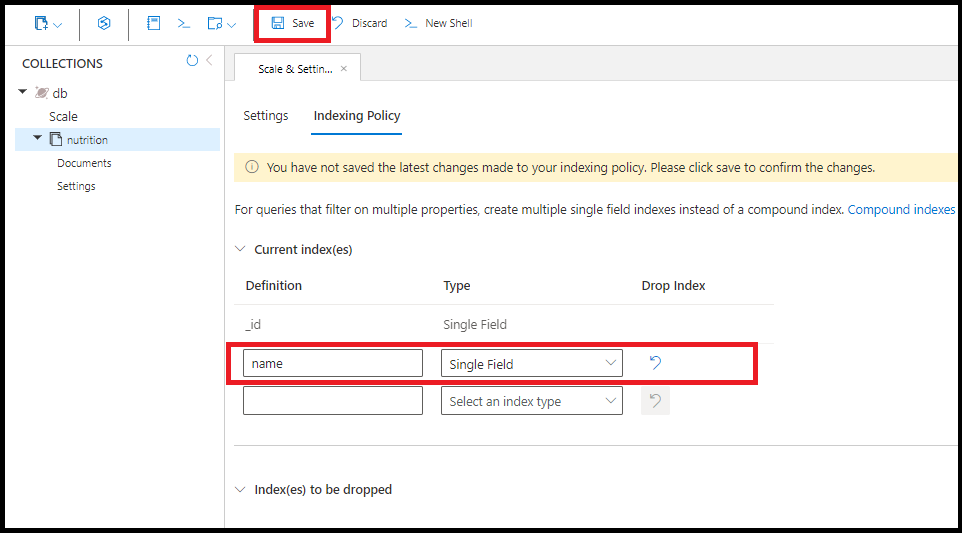
Jedno zapytanie używa wielu pojedynczych indeksów pól, jeśli są dostępne. Można utworzyć maksymalnie 500 indeksów pojedynczego pola na kolekcję.
Indeksy złożone (serwer MongoDB w wersji 3.6 lub nowszej)
W interfejsie API dla bazy danych MongoDB indeksy złożone są wymagane , jeśli zapytanie wymaga możliwości sortowania na wielu polach jednocześnie. W przypadku zapytań z wieloma filtrami, które nie muszą sortować, utwórz wiele indeksów z jednym polem zamiast indeksu złożonego, aby zaoszczędzić na kosztach indeksowania.
Indeks złożony lub indeksy pojedynczego pola dla każdego pola w indeksie złożonym powoduje taką samą wydajność filtrowania w zapytaniach.
Indeksy złożone w polach zagnieżdżonych nie są domyślnie obsługiwane ze względu na ograniczenia dotyczące tablic. Jeśli zagnieżdżone pole nie zawiera tablicy, indeks działa zgodnie z oczekiwaniami. Jeśli zagnieżdżone pole zawiera tablicę (w dowolnym miejscu na ścieżce), ta wartość jest ignorowana w indeksie.
Na przykład indeks złożony zawierający people.dylan.age działa w tym przypadku, ponieważ w ścieżce nie ma tablicy:
{
"people": {
"dylan": {
"name": "Dylan",
"age": "25"
},
"reed": {
"name": "Reed",
"age": "30"
}
}
}
Ten sam indeks złożony nie działa w tym przypadku, ponieważ w ścieżce znajduje się tablica:
{
"people": [
{
"name": "Dylan",
"age": "25"
},
{
"name": "Reed",
"age": "30"
}
]
}
Tę funkcję można włączyć dla konta bazy danych, włączając funkcję "EnableUniqueCompoundNestedDocs".
Uwaga
Nie można tworzyć indeksów złożonych w tablicach.
Następujące polecenie tworzy indeks złożony w polach name i age:
db.coll.createIndex({name:1,age:1})
Indeksy złożone umożliwiają efektywne sortowanie wielu pól jednocześnie, jak pokazano w poniższym przykładzie:
db.coll.find().sort({name:1,age:1})
Możesz również użyć powyższego indeksu złożonego, aby efektywnie sortować zapytanie z przeciwną kolejnością sortowania we wszystkich polach. Oto przykład:
db.coll.find().sort({name:-1,age:-1})
Jednak sekwencja ścieżek w indeksie złożonym musi dokładnie odpowiadać zapytaniu. Oto przykład zapytania, które wymagałoby dodatkowego indeksu złożonego:
db.coll.find().sort({age:1,name:1})
Indeksy wieloklucze
Usługa Azure Cosmos DB tworzy indeksy wieloklucze w celu indeksowania zawartości przechowywanej w tablicach. Jeśli indeksujesz pole z wartością tablicy, usługa Azure Cosmos DB automatycznie indeksuje każdy element w tablicy.
Indeksy geoprzestrzenne
Wiele operatorów geoprzestrzennych skorzysta z indeksów geoprzestrzennych. Obecnie usługa Azure Cosmos DB dla bazy danych MongoDB obsługuje 2dsphere indeksy. Interfejs API nie obsługuje 2d jeszcze indeksów.
Oto przykład tworzenia indeksu geoprzestrzennego w location polu:
db.coll.createIndex({ location : "2dsphere" })
Indeksy tekstowe
Usługa Azure Cosmos DB dla bazy danych MongoDB nie obsługuje obecnie indeksów tekstowych. W przypadku zapytań wyszukiwania tekstu w ciągach należy użyć integracji usługi Azure AI Search z usługą Azure Cosmos DB.
Indeksy wieloznaczne
Do obsługi zapytań dotyczących nieznanych pól można użyć indeksów wieloznacznych. Wyobraźmy sobie, że masz kolekcję zawierającą dane dotyczące rodzin.
Oto część przykładowego dokumentu w tej kolekcji:
"children": [
{
"firstName": "Henriette Thaulow",
"grade": "5"
}
]
Oto kolejny przykład, tym razem z nieco innym zestawem właściwości w pliku children:
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"pets": [
{ "givenName": "Goofy" },
{ "givenName": "Shadow" }
]
},
{
"familyName": "Merriam",
"givenName": "John",
}
]
W tej kolekcji dokumenty mogą mieć wiele różnych możliwych właściwości. Jeśli chcesz zaindeksować wszystkie dane w children tablicy, masz dwie opcje: utwórz oddzielne indeksy dla każdej właściwości lub utwórz jeden indeks wieloznaczny dla całej children tablicy.
Tworzenie indeksu wieloznacznych
Następujące polecenie tworzy indeks wieloznaczny we wszystkich właściwościach w programie children:
db.coll.createIndex({"children.$**" : 1})
W przeciwieństwie do bazy danych MongoDB indeksy wieloznaczne mogą obsługiwać wiele pól w predykatach zapytań. Nie będzie różnicy w wydajności zapytań, jeśli używasz jednego indeksu wieloznacznych zamiast tworzenia oddzielnego indeksu dla każdej właściwości.
Następujące typy indeksów można utworzyć przy użyciu składni symboli wieloznacznych:
- Jedno pole
- Dane geoprzestrzenne
Indeksowanie wszystkich właściwości
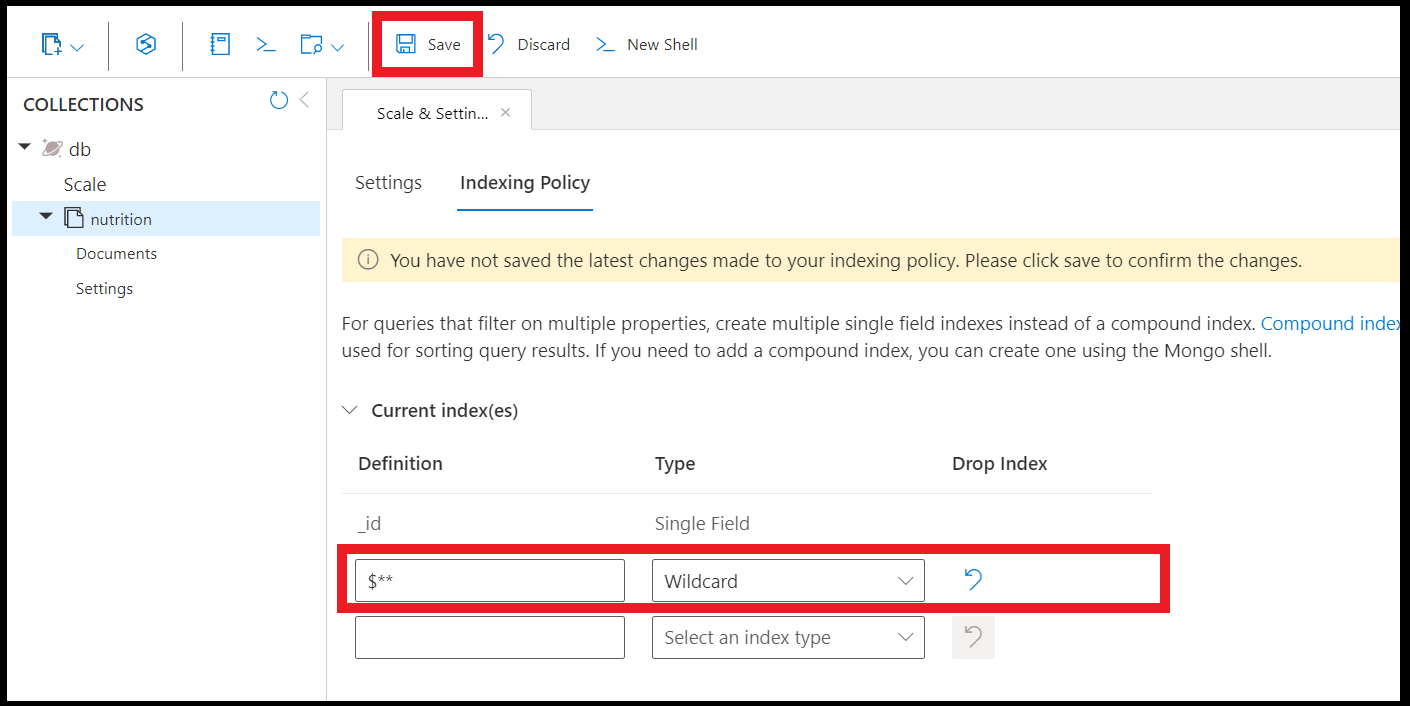
Oto jak utworzyć indeks wieloznaczny we wszystkich polach:
db.coll.createIndex( { "$**" : 1 } )
Możesz również utworzyć indeksy wieloznaczne przy użyciu Eksploratora danych w witrynie Azure Portal:
Uwaga
Jeśli dopiero zaczynasz programowanie, zdecydowanie zalecamy rozpoczęcie od indeksu z symbolami wieloznacznymi we wszystkich polach. Może to uprościć programowanie i ułatwić optymalizowanie zapytań.
W przypadku zapisów i aktualizacji dokumenty z wieloma polami mogą być naliczane wysokie opłaty za jednostkę żądania (RU). W związku z tym, jeśli masz duże obciążenie zapisu, należy wybrać pojedyncze ścieżki indeksów, w przeciwieństwie do używania indeksów wieloznacznych.
Uwaga
Obsługa unikatowego indeksu istniejących kolekcji z danymi jest dostępna w wersji zapoznawczej. Tę funkcję można włączyć dla konta bazy danych, włączając funkcję "EnableUniqueIndexReIndex".
Ograniczenia
Indeksy wieloznaczne nie obsługują żadnego z następujących typów indeksów ani właściwości:
- Złożony
- TTL
- Unikatowe
W przeciwieństwie do bazy danych MongoDB w usłudze Azure Cosmos DB dla bazy danych MongoDB nie można używać indeksów wieloznacznych dla:
Tworzenie indeksu wieloznacznego, który uwzględnia wiele konkretnych pól
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection " : { "children.givenName" : 1, "children.grade" : 1 } } )Tworzenie indeksu wieloznacznego, który wyklucza wiele konkretnych pól
db.coll.createIndex( { "$**" : 1 }, { "wildcardProjection" : { "children.givenName" : 0, "children.grade" : 0 } } )
Alternatywnie można utworzyć wiele indeksów wieloznacznych.
Właściwości indeksu
Następujące operacje są typowe dla kont obsługujących protokół przewodowy w wersji 4.0 i kont obsługujących wcześniejsze wersje. Możesz dowiedzieć się więcej o obsługiwanych indeksach i właściwościach indeksowanych.
Indeksy unikatowe
Indeksy unikatowe są przydatne do wymuszania, że co najmniej dwa dokumenty nie zawierają tej samej wartości dla indeksowanych pól.
Następujące polecenie tworzy unikatowy indeks w polu student_id:
globaldb:PRIMARY> db.coll.createIndex( { "student_id" : 1 }, {unique:true} )
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 4
}
W przypadku kolekcji podzielonych na fragmenty należy podać klucz fragmentu (partycji), aby utworzyć unikatowy indeks. Innymi słowy, wszystkie unikatowe indeksy w kolekcji podzielonej na fragmenty są indeksami złożonymi, w których jednym z pól jest klucz fragmentu. Pierwsze pole w kolejności powinno być kluczem fragmentu.
Następujące polecenia umożliwiają utworzenie kolekcji coll podzielonej na fragmenty (klucz fragmentu to university) z unikatowym indeksem w polach student_id i university:
globaldb:PRIMARY> db.runCommand({shardCollection: db.coll._fullName, key: { university: "hashed"}});
{
"_t" : "ShardCollectionResponse",
"ok" : 1,
"collectionsharded" : "test.coll"
}
globaldb:PRIMARY> db.coll.createIndex( { "university" : 1, "student_id" : 1 }, {unique:true});
{
"_t" : "CreateIndexesResponse",
"ok" : 1,
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 3,
"numIndexesAfter" : 4
}
W poprzednim przykładzie pominięcie klauzuli "university":1 zwraca błąd z następującym komunikatem:
cannot create unique index over {student_id : 1.0} with shard key pattern { university : 1.0 }
Ograniczenia
Należy utworzyć unikatowe indeksy, gdy kolekcja jest pusta.
Indeksy unikatowe w polach zagnieżdżonych nie są domyślnie obsługiwane ze względu na ograniczenia dotyczące tablic. Jeśli zagnieżdżone pole nie zawiera tablicy, indeks będzie działać zgodnie z oczekiwaniami. Jeśli zagnieżdżone pole zawiera tablicę (w dowolnym miejscu na ścieżce), ta wartość zostanie zignorowana w indeksie unikatowym, a unikatowość nie zostanie zachowana dla tej wartości.
Na przykład unikatowy indeks w pliku people.tom.age będzie działać w tym przypadku, ponieważ w ścieżce nie ma tablicy:
{ "people": { "tom": { "age": "25" }, "mark": { "age": "30" } } }
ale w tym przypadku nie będzie działać, ponieważ w ścieżce znajduje się tablica:
{ "people": { "tom": [ { "age": "25" } ], "mark": [ { "age": "30" } ] } }
Tę funkcję można włączyć dla konta bazy danych, włączając funkcję "EnableUniqueCompoundNestedDocs".
Indeksy czasu wygaśnięcia
Aby włączyć wygaśnięcie dokumentu w określonej kolekcji, należy utworzyć indeks czasu wygaśnięcia (TTL). Indeks czasu wygaśnięcia jest indeksem w _ts polu z wartością expireAfterSeconds .
Przykład:
globaldb:PRIMARY> db.coll.createIndex({"_ts":1}, {expireAfterSeconds: 10})
Poprzednie polecenie usuwa wszystkie dokumenty w db.coll kolekcji, które nie zostały zmodyfikowane w ciągu ostatnich 10 sekund.
Uwaga
Pole _ts jest specyficzne dla usługi Azure Cosmos DB i nie jest dostępne z klientów bazy danych MongoDB. Jest to właściwość zarezerwowana (systemowa), która zawiera sygnaturę czasową ostatniej modyfikacji dokumentu.
Śledzenie postępu indeksu
Wersja 3.6 lub nowsza usługi Azure Cosmos DB dla bazy danych MongoDB obsługuje currentOp() polecenie umożliwiające śledzenie postępu indeksowania w wystąpieniu bazy danych. To polecenie zwraca dokument zawierający informacje o operacjach w toku w wystąpieniu bazy danych. Polecenie służy currentOp do śledzenia wszystkich operacji w toku w natywnej bazie danych MongoDB. W usłudze Azure Cosmos DB dla bazy danych MongoDB to polecenie obsługuje tylko śledzenie operacji indeksowania.
Poniżej przedstawiono kilka przykładów pokazujących, jak używać currentOp polecenia do śledzenia postępu indeksu:
Pobierz postęp indeksu dla kolekcji:
db.currentOp({"command.createIndexes": <collectionName>, "command.$db": <databaseName>})Pobierz postęp indeksu dla wszystkich kolekcji w bazie danych:
db.currentOp({"command.$db": <databaseName>})Uzyskaj postęp indeksu dla wszystkich baz danych i kolekcji na koncie usługi Azure Cosmos DB:
db.currentOp({"command.createIndexes": { $exists : true } })
Przykłady danych wyjściowych postępu indeksu
Szczegóły postępu indeksu pokazują procent postępu bieżącej operacji indeksu. Oto przykład pokazujący format dokumentu wyjściowego dla różnych etapów postępu indeksu:
Operacja indeksu w kolekcji "foo" i bazie danych "bar", która jest ukończona w 60 procentach, będzie zawierać następujący dokument wyjściowy. Pole
Inprog[0].progress.totalzawiera wartość 100 jako docelową wartość procentową ukończenia.{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 60 %", "progress" : { "done" : 60, "total" : 100 }, …………..….. } ], "ok" : 1 }Jeśli operacja indeksu właśnie rozpoczęła się w bazie danych kolekcji "foo" i "bar", dokument wyjściowy może pokazywać postęp 0 procent, dopóki nie osiągnie mierzalnego poziomu.
{ "inprog" : [ { ………………... "command" : { "createIndexes" : foo "indexes" :[ ], "$db" : bar }, "msg" : "Index Build (background) Index Build (background): 0 %", "progress" : { "done" : 0, "total" : 100 }, …………..….. } ], "ok" : 1 }Po zakończeniu operacji indeksowania w toku dokument wyjściowy wyświetla puste
inprogoperacje.{ "inprog" : [], "ok" : 1 }
Aktualizacje indeksu w tle
Niezależnie od wartości określonej dla właściwości indeksu w tle aktualizacje indeksu są zawsze wykonywane w tle. Ponieważ aktualizacje indeksu zużywają jednostki żądań (RU) o niższym priorytekcie niż inne operacje bazy danych, zmiany indeksu nie spowodują przestoju operacji zapisu, aktualizacji ani usunięcia.
Podczas dodawania nowego indeksu nie ma wpływu na dostępność odczytu. Zapytania będą używać nowych indeksów tylko po zakończeniu transformacji indeksu. Podczas przekształcania indeksu aparat zapytań będzie nadal używać istniejących indeksów, dlatego podczas transformacji indeksowania będzie obserwowana podobna wydajność odczytu przed zainicjowaniem zmiany indeksowania. Podczas dodawania nowych indeksów nie ma również ryzyka niekompletnych lub niespójnych wyników zapytania.
Podczas usuwania indeksów i natychmiastowego uruchamiania zapytań, które mają filtry w porzuconych indeksach, wyniki mogą być niespójne i niekompletne do momentu zakończenia transformacji indeksu. Jeśli usuniesz indeksy, aparat zapytań nie zapewnia spójnych lub kompletnych wyników podczas filtrowania zapytań dla tych nowo usuniętych indeksów. Większość deweloperów nie usuwa indeksów, a następnie natychmiast spróbuje je wykonać, więc w praktyce ta sytuacja jest mało prawdopodobna.
Polecenie ReIndex
Polecenie reIndex spowoduje ponowne utworzenie wszystkich indeksów w kolekcji. W niektórych rzadkich przypadkach wydajność zapytań lub inne problemy z indeksem w kolekcji mogą zostać rozwiązane przez uruchomienie reIndex polecenia . Jeśli występują problemy z indeksowaniem, ponowne utworzenie indeksów za reIndex pomocą polecenia jest zalecane.
Polecenie można uruchomić reIndex przy użyciu następującej składni:
db.runCommand({ reIndex: <collection> })
Poniższa składnia umożliwia sprawdzenie, czy uruchomienie reIndex polecenia poprawi wydajność zapytań w kolekcji:
db.runCommand({"customAction":"GetCollection",collection:<collection>, showIndexes:true})
Przykładowe dane wyjściowe:
{
"database" : "myDB",
"collection" : "myCollection",
"provisionedThroughput" : 400,
"indexes" : [
{
"v" : 1,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
},
{
"v" : 1,
"key" : {
"b.$**" : 1
},
"name" : "b.$**_1",
"ns" : "myDB.myCollection",
"requiresReIndex" : true
}
],
"ok" : 1
}
Jeśli reIndex poprawi wydajność zapytań, właściwość requiresReIndex będzie mieć wartość true. Jeśli reIndex nie poprawisz wydajności zapytań, ta właściwość zostanie pominięta.
Migrowanie kolekcji z indeksami
Obecnie można tworzyć unikatowe indeksy tylko wtedy, gdy kolekcja nie zawiera żadnych dokumentów. Popularne narzędzia migracji bazy danych MongoDB próbują utworzyć unikatowe indeksy po zaimportowaniu danych. Aby obejść ten problem, możesz ręcznie utworzyć odpowiednie kolekcje i unikatowe indeksy zamiast zezwalać narzędziu migracji na wypróbowanie. (To zachowanie mongorestore można osiągnąć za pomocą --noIndexRestore flagi w wierszu polecenia).
Indeksowanie bazy danych MongoDB w wersji 3.2
Dostępne funkcje indeksowania i wartości domyślne są różne dla kont usługi Azure Cosmos DB, które są zgodne z wersją 3.2 protokołu przewodowego bazy danych MongoDB. Możesz sprawdzić wersję konta i uaktualnić ją do wersji 3.6.
Jeśli używasz wersji 3.2, w tej sekcji opisano kluczowe różnice w wersjach 3.6 lub nowszych.
Usuwanie indeksów domyślnych (wersja 3.2)
W przeciwieństwie do wersji 3.6 lub nowszej usługi Azure Cosmos DB dla bazy danych MongoDB domyślnie indeksuje każdą właściwość w wersji 3.2. Możesz użyć następującego polecenia, aby usunąć te domyślne indeksy dla kolekcji (coll):
> db.coll.dropIndexes()
{ "_t" : "DropIndexesResponse", "ok" : 1, "nIndexesWas" : 3 }
Po usunięciu indeksów domyślnych można dodać więcej indeksów, tak jak w wersji 3.6 lub nowszej.
Indeksy złożone (wersja 3.2)
Indeksy złożone przechowują odwołania do wielu pól dokumentu. Jeśli chcesz utworzyć indeks złożony, przeprowadź uaktualnienie do wersji 3.6 lub 4.0.
Indeksy wieloznaczne (wersja 3.2)
Jeśli chcesz utworzyć indeks wieloznaczny, przeprowadź uaktualnienie do wersji 4.0 lub 3.6.
Następne kroki
- Indeksowanie w usłudze Azure Cosmos DB
- Expire data in Azure Cosmos DB automatically with time to live (Automatyczne wygasanie danych w usłudze Azure Cosmos DB przy użyciu czasu wygaśnięcia)
- Aby dowiedzieć się więcej o relacji między partycjonowaniem i indeksowaniem, zobacz artykuł Jak wykonywać zapytania dotyczące kontenera usługi Azure Cosmos DB.
- Próbujesz zaplanować pojemność migracji do usługi Azure Cosmos DB? Informacje o istniejącym klastrze bazy danych można użyć do planowania pojemności.
- Jeśli wszystko, co wiesz, to liczba rdzeni wirtualnych i serwerów w istniejącym klastrze bazy danych, przeczytaj o szacowaniu jednostek żądań przy użyciu rdzeni wirtualnych lub procesorów wirtualnych
- Jeśli znasz typowe stawki żądań dla bieżącego obciążenia bazy danych, przeczytaj o szacowaniu jednostek żądań przy użyciu planisty pojemności usługi Azure Cosmos DB