Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Usługa Azure Cosmos DB for PostgreSQL nie jest już obsługiwana w przypadku nowych projektów. Nie używaj tej usługi dla nowych projektów. Zamiast tego użyj jednej z tych dwóch usług:
Użyj usługi Azure Cosmos DB for NoSQL dla rozproszonego rozwiązania bazy danych przeznaczonego dla scenariuszy o dużej skali z umową dotyczącą poziomu usług dostępności 99,999% (SLA), natychmiastowym skalowaniem automatycznym i automatycznym przejściem w tryb failover w wielu regionach.
Użyj funkcji Elastic Clusters usługi Azure Database for PostgreSQL na potrzeby fragmentowanej bazy danych PostgreSQL przy użyciu rozszerzenia Citus typu open source.
Zanim zbadamy kroki tworzenia nowej aplikacji, warto zapoznać się z szybkim omówieniem terminów i pojęć.
Omówienie architektury
Usługa Azure Cosmos DB for PostgreSQL umożliwia dystrybuowanie tabel i/lub schematów na wielu maszynach w klastrze i przezroczyste wykonywanie zapytań o nie w taki sam sposób, jak w przypadku zwykłego bazy danych PostgreSQL:
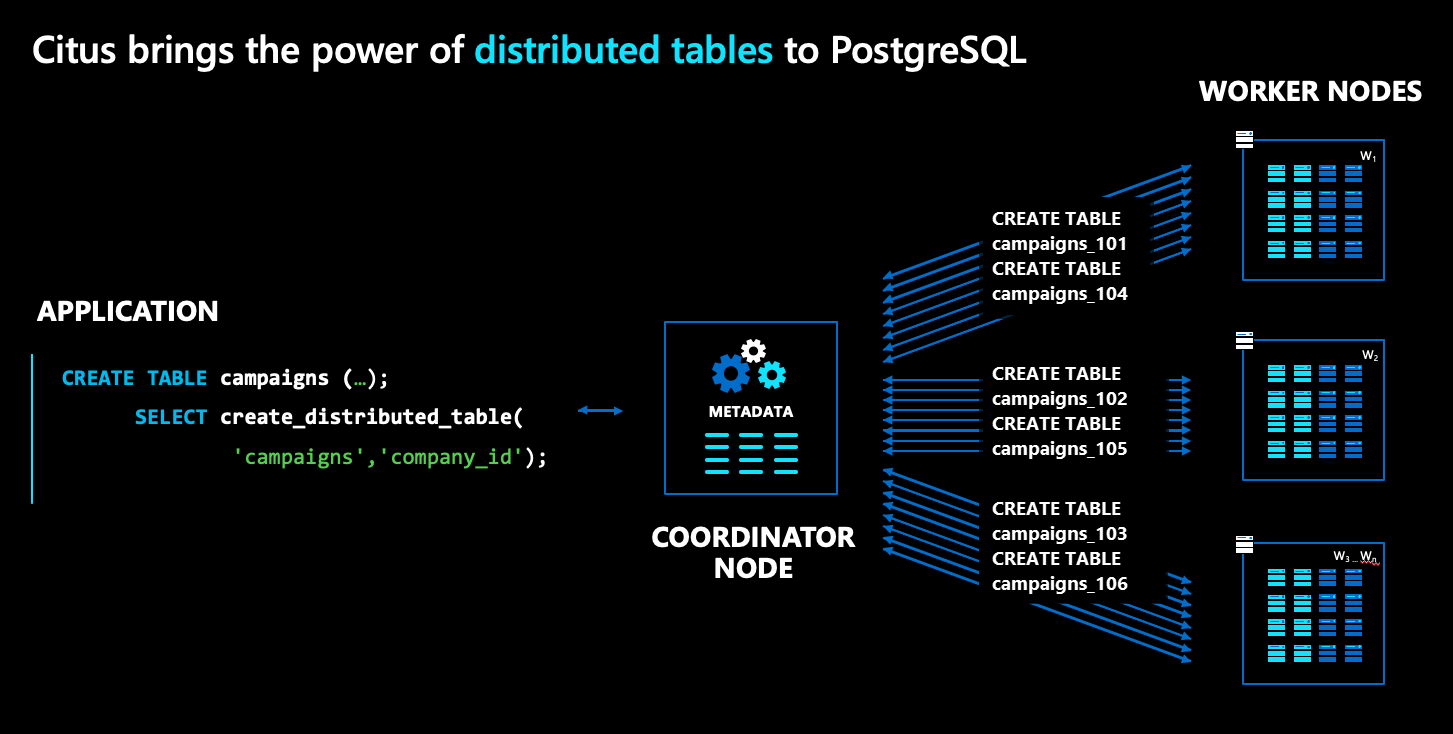
W architekturze usługi Azure Cosmos DB for PostgreSQL istnieje wiele rodzajów węzłów:
- Węzeł koordynacji przechowuje rozproszone metadane tabeli i jest odpowiedzialny za planowanie rozproszone.
- Natomiast węzły procesu roboczego przechowują rzeczywiste dane, metadane i wykonują obliczenia.
- Zarówno koordynator, jak i pracownicy są zwykłymi bazami danych PostgreSQL z
cituszaładowanym rozszerzeniem.
Aby rozłożyć normalną tabelę PostgreSQL, na przykład campaigns na powyższym diagramie, uruchom polecenie o nazwie create_distributed_table(). Po uruchomieniu tego polecenia usługa Azure Cosmos DB for PostgreSQL w sposób przezroczysty tworzy fragmenty dla tabeli między węzłami procesu roboczego. Na diagramie fragmenty są reprezentowane jako niebieskie pola.
Aby rozpowszechnić normalny schemat postgreSQL, uruchom citus_schema_distribute() polecenie . Po uruchomieniu tego polecenia, usługa Azure Cosmos DB for PostgreSQL w sposób przezroczysty przekształca tabele w takich schematach w pojedyncze tabele fragmentowane i kolokowane, które można przenieść jako całość między węzłami klastra.
Uwaga
W klastrze bez węzłów roboczych fragmenty tabel rozproszonych znajdują się w węźle koordynacji.
Fragmenty są zwykłymi (mające specjalne nazwy) tabelami PostgreSQL, które przechowują fragmenty Twoich danych. W naszym przykładzie, ponieważ rozpowszechnialiśmy campaigns przez company_id, fragmenty przechowują kampanie, w których kampanie różnych firm są przydzielane do różnych fragmentów.
Kolumna dystrybucji (znana również jako klucz podziału)
create_distributed_table() to magiczna funkcja, którą usługa Azure Cosmos DB for PostgreSQL udostępnia, aby dystrybuować tabele i wykorzystywać zasoby na wielu maszynach.
SELECT create_distributed_table(
'table_name',
'distribution_column');
Drugi argument powyżej wybiera kolumnę z tabeli jako kolumnę dystrybucji. Może to być dowolna kolumna z natywnym typem postgreSQL (z liczbą całkowitą i tekstem najczęściej spotykanym). Wartość kolumny rozkładu określa, które wiersze należą do których fragmentów, dlatego kolumna rozkładu jest również nazywana kluczem fragmentu.
Usługa Azure Cosmos DB for PostgreSQL decyduje, jak uruchamiać zapytania na podstawie ich użycia klucza fragmentu:
| Zapytanie obejmuje | Gdzie działa |
|---|---|
| tylko jeden klucz fragmentu | w węźle roboczym, w którym znajduje się jego fragment |
| wiele kluczy podziału | równoległe między wieloma węzłami |
Wybór klucza fragmentu określa wydajność i skalowalność aplikacji.
- Nierównomierna dystrybucja danych na klucze fragmentów (znana również jako niesymetryczność danych) nie jest optymalna dla wydajności. Na przykład nie wybieraj kolumny, dla której pojedyncza wartość reprezentuje 50% danych.
- Klucze fragmentów o niskiej kardynalności mogą mieć wpływ na skalowalność. Można używać tylko tak wielu fragmentów, jak istnieją różne wartości klucza. Wybierz klucz, który ma kardynalność od kilkuset do kilku tysięcy.
- Łączenie dwóch dużych tabel z różnymi kluczami fragmentów może być powolne. Wybierz wspólny klucz podziału dla dużych tabel. Dowiedz się więcej o kolokacji.
Colocation (Kolokacja)
Inną koncepcją ściśle powiązaną z kluczem fragmentu jest kolokacja. Tabele podzielone na fragmenty według kolumn o tych samych wartościach rozkładu są kolokowane: fragmenty tabel kolokowanych przechowuje się razem na tych samych maszynach roboczych.
Poniżej znajdują się dwie tabele podzielone na fragmenty według tego samego klucza: site_id. Są one przeniesione.
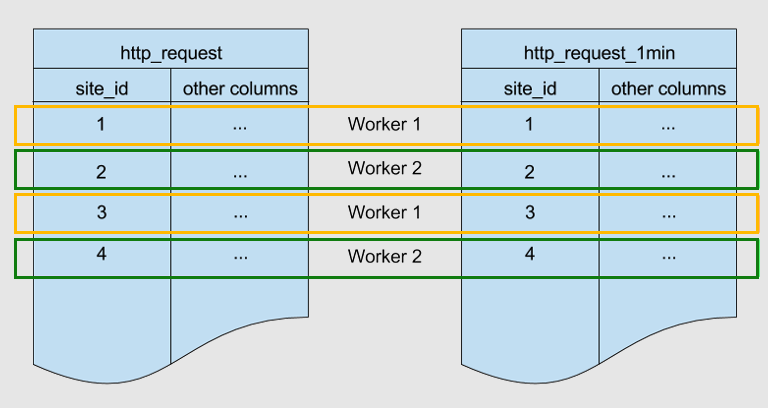
Usługa Azure Cosmos DB for PostgreSQL zapewnia, że wiersze z pasującą wartością site_id w obu tabelach są przechowywane na tym samym węźle roboczym. Zobaczysz, że w przypadku obu tabel wiersze z ciągiem site_id=1 są przechowywane w obszarze roboczym 1. Podobnie w przypadku innych identyfikatorów witryn.
Rozmieszczenie danych pomaga zoptymalizować operacje JOIN w tych tabelach. Jeśli połączysz dwie tabele na site_id, Azure Cosmos DB for PostgreSQL może wykonać łączenie lokalnie na węzłach roboczych bez przesyłania danych między węzłami.
Tabele w schemacie rozproszonym są zawsze współlokowane ze sobą.