Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważna
Usługa Azure Cosmos DB for PostgreSQL znajduje się na ścieżce wycofania i nie jest już zalecana w przypadku nowych projektów. Zamiast tego użyj jednej z tych dwóch usług:
W przypadku obciążeń PostgreSQL: użyj funkcji klastrowania elastycznego (Elastic Clusters) usługi Azure Database for PostgreSQL, w celu wykorzystania funkcji skalowania w poziomie i rozproszonych baz danych PostgreSQL zawartych w open-source'owym rozszerzeniu Citus. Aby uzyskać wskazówki dotyczące migracji, zobacz migrate to Azure Database for PostgreSQL with Elastic Cluster.
W przypadku obciążeń NoSQL użyj usługi Azure Cosmos DB for NoSQL dla rozproszonego rozwiązania bazy danych, które obejmuje umowę serwisową o dostępności na poziomie 99,999% (SLA), natychmiastowe automatyczne skalowanie i automatyczne przełączanie awaryjne w wielu regionach.
W tym samouczku korzystasz z Azure Cosmos DB for PostgreSQL jako zaplecza pamięci masowej dla wielu mikrousług, demonstrując przykładową konfigurację i podstawowe działanie takiego klastra. Dowiedz się, jak:
- Tworzenie klastra
- Tworzenie ról dla mikrousług
- Tworzenie ról i schematów rozproszonych za pomocą narzędzia psql
- Tworzenie tabel dla przykładowych usług
- Konfigurowanie usług
- Uruchamianie usług
- Eksplorowanie bazy danych
Prerequisites
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Tworzenie klastra
Zaloguj się do witryny Azure Portal i wykonaj następujące kroki, aby utworzyć klaster usługi Azure Cosmos DB for PostgreSQL:
Przejdź do Utwórz klaster Azure Cosmos DB dla PostgreSQL w portalu Azure.
W formularzu Tworzenie klastra usługi Azure Cosmos DB for PostgreSQL:
Wypełnij informacje na karcie Podstawowe informacje.
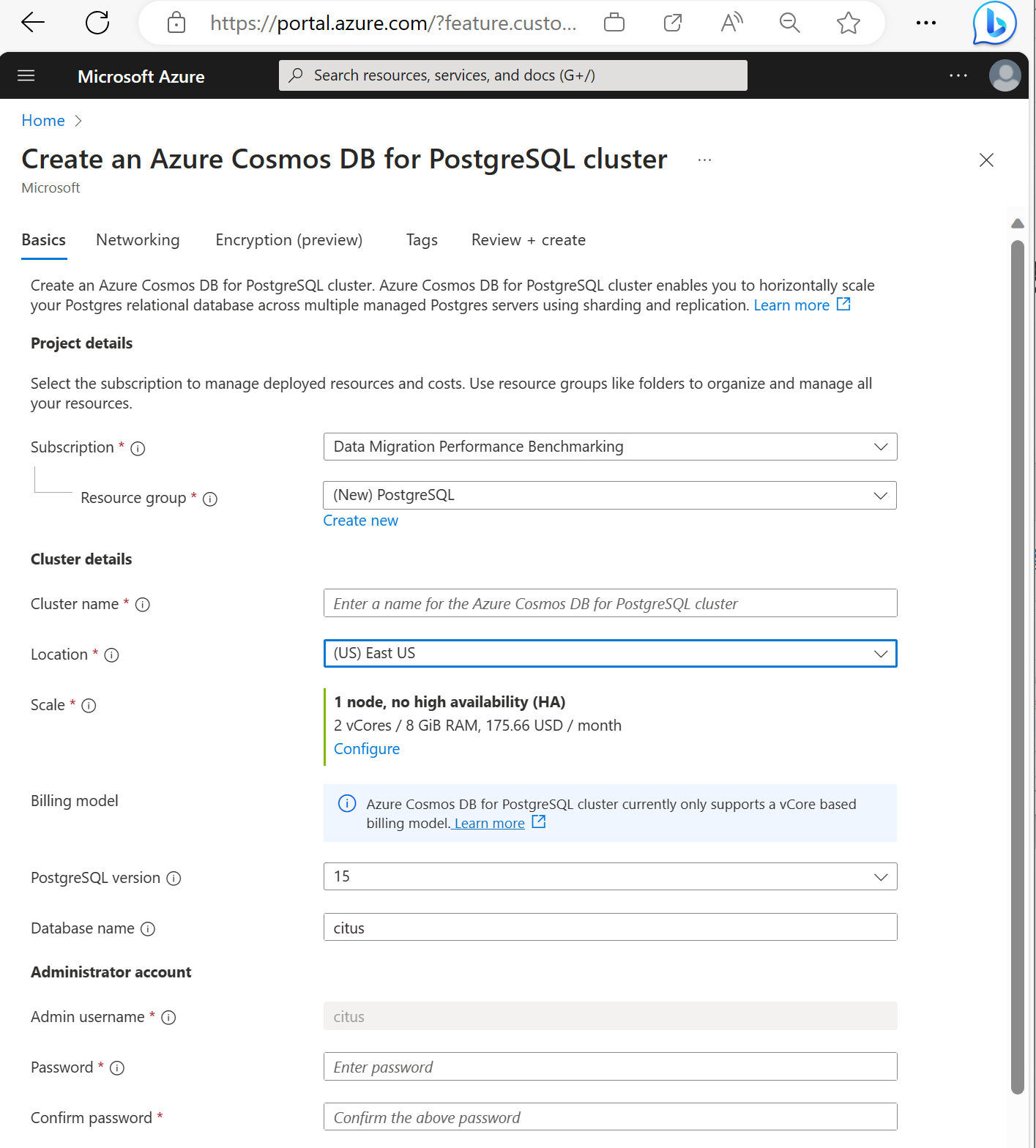
Większość opcji nie wymaga wyjaśnień, ale należy pamiętać o następujących kwestiach:
- Nazwa klastra określa nazwę DNS używaną przez aplikacje do nawiązywania połączenia w postaci
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Możesz wybrać główną wersję bazy danych PostgreSQL, taką jak 15. Usługa Azure Cosmos DB for PostgreSQL zawsze obsługuje najnowszą wersję citus dla wybranej głównej wersji bazy danych Postgres.
- Nazwa użytkownika administratora musi być wartością
citus. - Nazwę bazy danych można pozostawić na wartości domyślnej "citus" lub zdefiniować tylko nazwę bazy danych. Nie można zmienić nazwy bazy danych po aprowizacji klastra.
- Nazwa klastra określa nazwę DNS używaną przez aplikacje do nawiązywania połączenia w postaci
Wybierz pozycję Dalej: Sieć w dolnej części ekranu.
Na ekranie Sieć wybierz pozycję Zezwalaj na dostęp publiczny z usług i zasobów platformy Azure w ramach platformy Azure do tego klastra.
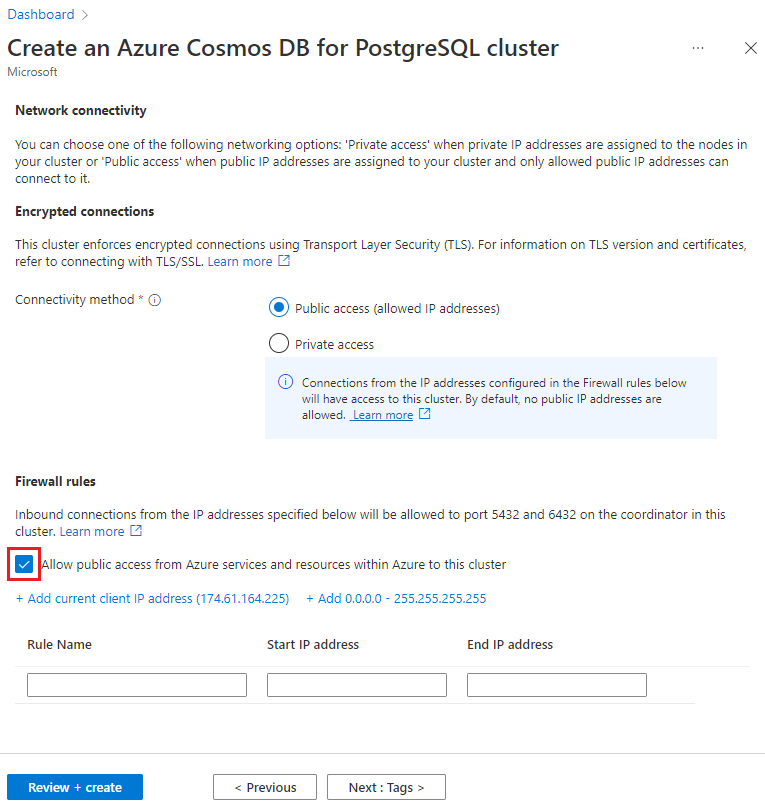
Wybierz pozycję Przeglądanie i tworzenie, a po zakończeniu walidacji wybierz pozycję Utwórz, aby utworzyć klaster.
Proces provisioningu trwa kilka minut. Strona przekierowuje do monitorowania wdrożenia. Gdy stan zmieni się z Wdrażanie jest w toku na Wdrożenie zostało ukończone, wybierz pozycję Przejdź do zasobu.
Tworzenie ról dla mikrousług
Schematy rozproszone można przenosić w klastrze usługi Azure Cosmos DB for PostgreSQL. System może je ponownie zrównoważyć jako całość w dostępnych węzłach, co pozwala wydajnie udostępniać zasoby bez ręcznej alokacji.
Zgodnie z projektem mikrousługi są właścicielami warstwy magazynowania, nie przyjmujemy żadnych założeń dotyczących typu tabel i danych, które tworzą i przechowują. Udostępniamy schemat dla każdej usługi i zakładamy, że używają odrębnej roli do nawiązywania połączenia z bazą danych. Gdy użytkownik nawiązuje połączenie, jego nazwa roli jest umieszczana na początku search_path, więc jeśli rola jest zgodna z nazwą schematu, nie potrzebujesz żadnych zmian aplikacji, aby ustawić poprawną search_path.
W naszym przykładzie używamy trzech usług:
- użytkownik
- time
- ping
Wykonaj kroki opisujące sposób tworzenia ról użytkownika i tworzenia następujących ról dla każdej usługi:
userservicetimeservicepingservice
Tworzenie schematów rozproszonych za pomocą narzędzia psql
Po nawiązaniu połączenia z usługą Azure Cosmos DB for PostgreSQL przy użyciu narzędzia psql możesz wykonać kilka podstawowych zadań.
Istnieją dwa sposoby dystrybucji schematu w usłudze Azure Cosmos DB for PostgreSQL:
Ręcznie, wywołując funkcję citus_schema_distribute(schema_name):
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
SELECT citus_schema_distribute('userservice');
SELECT citus_schema_distribute('timeservice');
SELECT citus_schema_distribute('pingservice');
Ta metoda umożliwia również konwertowanie istniejących schematów regularnych na schematy rozproszone.
Uwaga / Notatka
Można dystrybuować tylko schematy, które nie zawierają tabel rozproszonych i referencyjnych.
Alternatywną metodą jest włączenie zmiennej konfiguracji citus.enable_schema_based_sharding:
SET citus.enable_schema_based_sharding TO ON;
CREATE SCHEMA AUTHORIZATION userservice;
CREATE SCHEMA AUTHORIZATION timeservice;
CREATE SCHEMA AUTHORIZATION pingservice;
Zmienną można zmienić dla bieżącej sesji lub trwale w parametrach węzła koordynatora. Gdy parametr jest ustawiony na WŁ., wszystkie utworzone schematy są domyślnie dystrybuowane.
Możesz wyświetlić listę aktualnie rozproszonych schematów, uruchamiając polecenie:
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 5 | 0 bytes | userservice
timeservice | 6 | 0 bytes | timeservice
pingservice | 7 | 0 bytes | pingservice
(3 rows)
Tworzenie tabel dla przykładowych usług
Teraz musisz nawiązać połączenie z usługą Azure Cosmos DB for PostgreSQL dla każdej mikrousługi. Aby zamienić użytkownika w istniejącym wystąpieniu psql, możesz użyć polecenia \c.
\c citus userservice
CREATE TABLE users (
id SERIAL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
email VARCHAR(255) NOT NULL
);
\c citus timeservice
CREATE TABLE query_details (
id SERIAL PRIMARY KEY,
ip_address INET NOT NULL,
query_time TIMESTAMP NOT NULL
);
\c citus pingservice
CREATE TABLE ping_results (
id SERIAL PRIMARY KEY,
host VARCHAR(255) NOT NULL,
result TEXT NOT NULL
);
Konfigurowanie usług
W tym samouczku używamy prostego zestawu usług. Można je uzyskać, klonując to repozytorium publiczne:
git clone https://github.com/citusdata/citus-example-microservices.git
$ tree
.
├── LICENSE
├── README.md
├── ping
│ ├── app.py
│ ├── ping.sql
│ └── requirements.txt
├── time
│ ├── app.py
│ ├── requirements.txt
│ └── time.sql
└── user
├── app.py
├── requirements.txt
└── user.sql
Przed uruchomieniem usług zmodyfikuj user/app.pyping/app.py jednak pliki i time/app.py udostępniając konfigurację połączenia dla klastra usługi Azure Cosmos DB for PostgreSQL:
# Database configuration
db_config = {
'host': 'c-EXAMPLE.EXAMPLE.postgres.cosmos.azure.com',
'database': 'citus',
'password': 'SECRET',
'user': 'pingservice',
'port': 5432
}
Po wprowadzeniu zmian zapisz wszystkie zmodyfikowane pliki i przejdź do następnego kroku uruchamiania usług.
Uruchamianie usług
Przejdź do każdego katalogu aplikacji i uruchom je we własnym środowisku python.
cd user
pipenv install
pipenv shell
python app.py
Powtórz polecenia dla czasu i usługi ping, po czym możesz użyć interfejsu API.
Utwórz niektórych użytkowników:
curl -X POST -H "Content-Type: application/json" -d '[
{"name": "John Doe", "email": "john@example.com"},
{"name": "Jane Smith", "email": "jane@example.com"},
{"name": "Mike Johnson", "email": "mike@example.com"},
{"name": "Emily Davis", "email": "emily@example.com"},
{"name": "David Wilson", "email": "david@example.com"},
{"name": "Sarah Thompson", "email": "sarah@example.com"},
{"name": "Alex Miller", "email": "alex@example.com"},
{"name": "Olivia Anderson", "email": "olivia@example.com"},
{"name": "Daniel Martin", "email": "daniel@example.com"},
{"name": "Sophia White", "email": "sophia@example.com"}
]' http://localhost:5000/users
Wyświetl listę utworzonych użytkowników:
curl http://localhost:5000/users
Pobierz bieżącą godzinę:
Get current time:
Uruchom polecenie ping względem example.com:
curl -X POST -H "Content-Type: application/json" -d '{"host": "example.com"}' http://localhost:5002/ping
Eksplorowanie bazy danych
Po wywołaniu niektórych funkcji interfejsu API dane zostały zapisane i możesz sprawdzić, czy citus_schemas odzwierciedla to, co jest oczekiwane:
select * from citus_schemas;
schema_name | colocation_id | schema_size | schema_owner
-------------+---------------+-------------+--------------
userservice | 1 | 112 kB | userservice
timeservice | 2 | 32 kB | timeservice
pingservice | 3 | 32 kB | pingservice
(3 rows)
Podczas tworzenia schematów nie poinformowaliśmy usługi Azure Cosmos DB for PostgreSQL o tym, na których maszynach utworzyć schematy. Zostało to zrobione automatycznie. Zobaczysz, gdzie znajduje się każdy schemat, korzystając z następującego zapytania:
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9702 | userservice.users | 112 kB
localhost | 9702 | pingservice.ping_results | 32 kB
Aby skrócić przykładowe dane wyjściowe na tej stronie, zamiast używać nodename tak jak w usłudze Azure Cosmos DB for PostgreSQL, zastępujemy go na hosta lokalnego. Załóżmy, że localhost:9701 jest to proces roboczy jeden i localhost:9702 jest procesem roboczym dwa. Nazwy węzłów w usłudze zarządzanej są dłuższe i zawierają losowe elementy.
Widać, że usługa czasowa wylądowała na węźle localhost:9701, podczas gdy usługa użytkownika i usługa ping współdzielą przestrzeń na drugim wątku localhost:9702. Przykładowe aplikacje są uproszczone, a rozmiary danych tutaj można zignorować, ale załóżmy, że przeszkadza ci nierówne wykorzystanie przestrzeni między węzłami. Bardziej sensowne byłoby, aby dwie mniejsze usługi czasu i usługi ping znajdowały się na jednej maszynie, podczas gdy duża usługa dla użytkowników znajduje się samodzielnie.
Można łatwo ponownie zrównoważyć klaster według rozmiaru dysku:
select citus_rebalance_start();
NOTICE: Scheduled 1 moves as job 1
DETAIL: Rebalance scheduled as background job
HINT: To monitor progress, run: SELECT * FROM citus_rebalance_status();
citus_rebalance_start
-----------------------
1
(1 row)
Po zakończeniu możesz sprawdzić, jak wygląda nasz nowy układ:
select nodename,nodeport, table_name, pg_size_pretty(sum(shard_size))
from citus_shards
group by nodename,nodeport, table_name;
nodename | nodeport | table_name | pg_size_pretty
-----------+----------+---------------------------+----------------
localhost | 9701 | timeservice.query_details | 32 kB
localhost | 9701 | pingservice.ping_results | 32 kB
localhost | 9702 | userservice.users | 112 kB
(3 rows)
Zgodnie z oczekiwaniami schematy zostały przeniesione i mamy bardziej zrównoważony klaster. Ta operacja była przejrzysta dla aplikacji. Nie trzeba ich nawet ponownie uruchamiać, kontynuują obsługę zapytań.
Następne kroki
W tym samouczku nauczyłeś się, jak tworzyć schematy rozproszone oraz uruchamiać mikrousługi wykorzystujące je jako pamięć. Nauczyłeś(-aś) się również, jak eksplorować oraz zarządzać usługi Azure Cosmos DB for PostgreSQL opartej na schemacie i podziale na shardy (fragmenty).