Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważna
Usługa Azure Cosmos DB for PostgreSQL znajduje się na ścieżce wycofania i nie jest już zalecana w przypadku nowych projektów. Zamiast tego użyj jednej z tych dwóch usług:
W przypadku obciążeń PostgreSQL: użyj funkcji klastrowania elastycznego (Elastic Clusters) usługi Azure Database for PostgreSQL, w celu wykorzystania funkcji skalowania w poziomie i rozproszonych baz danych PostgreSQL zawartych w open-source'owym rozszerzeniu Citus. Aby uzyskać wskazówki dotyczące migracji, zobacz migrate to Azure Database for PostgreSQL with Elastic Cluster.
W przypadku obciążeń NoSQL użyj usługi Azure Cosmos DB for NoSQL dla rozproszonego rozwiązania bazy danych, które obejmuje umowę serwisową o dostępności na poziomie 99,999% (SLA), natychmiastowe automatyczne skalowanie i automatyczne przełączanie awaryjne w wielu regionach.
W tym samouczku użyjesz usługi Azure Cosmos DB for PostgreSQL, aby nauczyć się, jak:
- Tworzenie klastra
- Tworzenie schematu za pomocą narzędzia psql
- Fragmentacja tabel po węzłach
- Importowanie przykładowych danych
- Zapytać o dane najemcy
- Udostępnianie danych między najemcami
- Dostosuj schemat dla każdego najemcy
Prerequisites
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Tworzenie klastra
Zaloguj się do witryny Azure Portal i wykonaj następujące kroki, aby utworzyć klaster usługi Azure Cosmos DB for PostgreSQL:
Przejdź do Utwórz klaster Azure Cosmos DB dla PostgreSQL w portalu Azure.
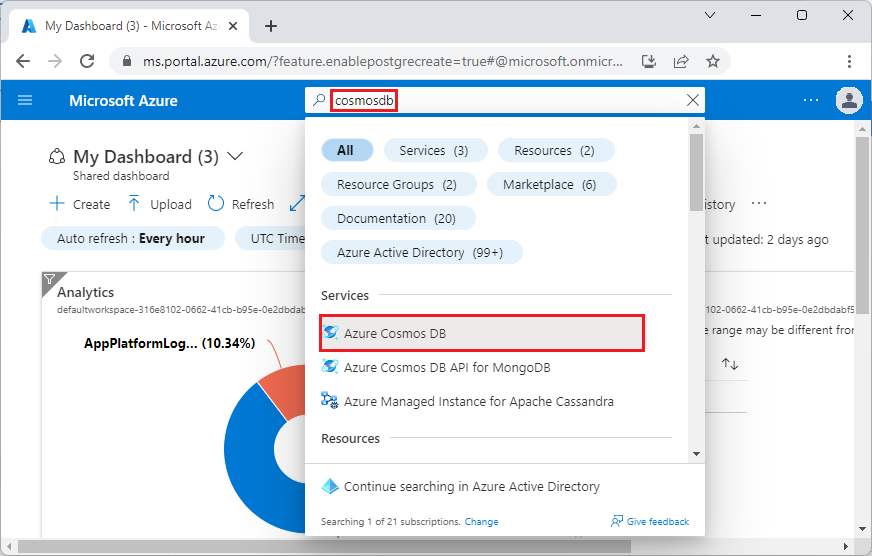
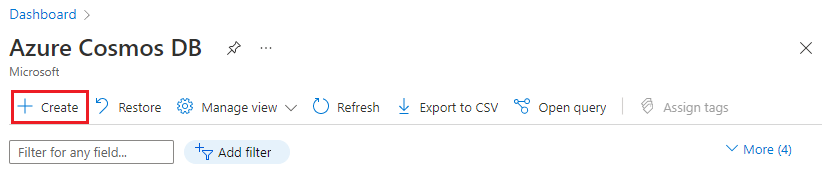
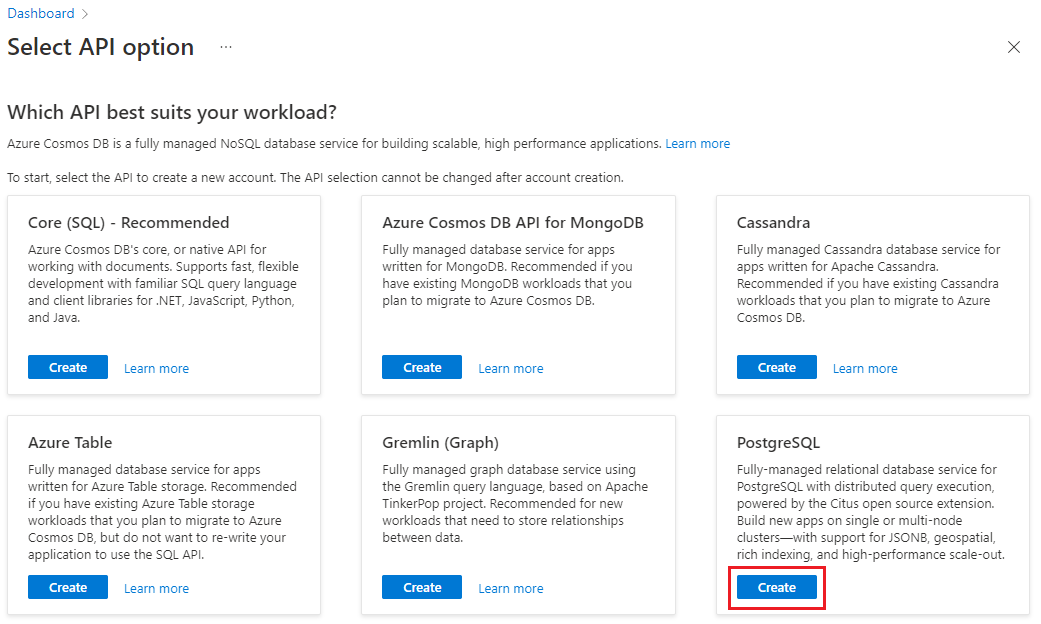
W formularzu Tworzenie klastra usługi Azure Cosmos DB for PostgreSQL:
Wypełnij informacje na karcie Podstawowe informacje.
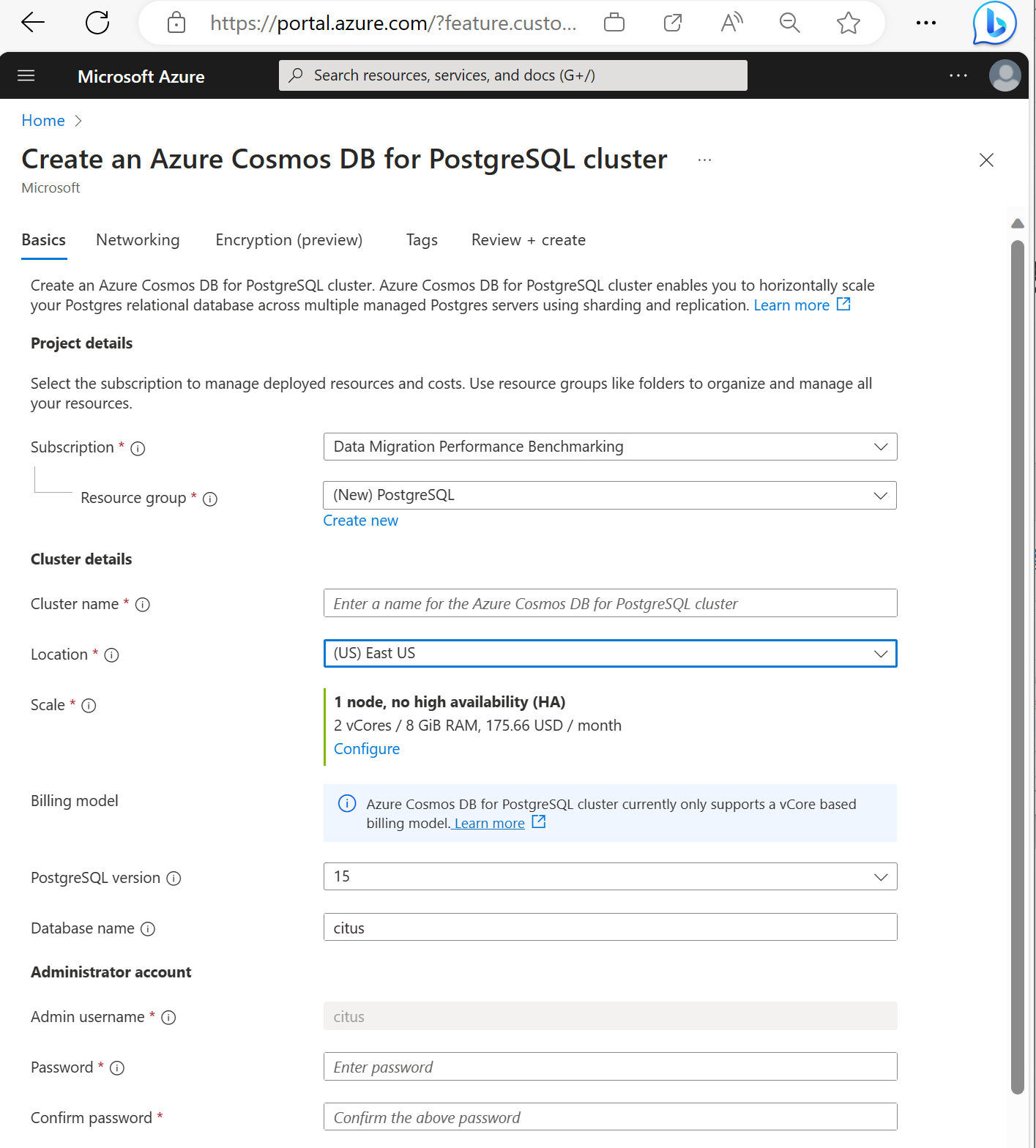
Większość opcji nie wymaga wyjaśnień, ale należy pamiętać o następujących kwestiach:
- Nazwa klastra określa nazwę DNS używaną przez aplikacje do nawiązywania połączenia w postaci
<node-qualifier>-<clustername>.<uniqueID>.postgres.cosmos.azure.com. - Możesz wybrać główną wersję bazy danych PostgreSQL, taką jak 15. Usługa Azure Cosmos DB for PostgreSQL zawsze obsługuje najnowszą wersję citus dla wybranej głównej wersji bazy danych Postgres.
- Nazwa użytkownika administratora musi być wartością
citus. - Nazwę bazy danych można pozostawić na wartości domyślnej "citus" lub zdefiniować tylko nazwę bazy danych. Nie można zmienić nazwy bazy danych po aprowizacji klastra.
- Nazwa klastra określa nazwę DNS używaną przez aplikacje do nawiązywania połączenia w postaci
Wybierz pozycję Dalej: Sieć w dolnej części ekranu.
Na ekranie Sieć wybierz pozycję Zezwalaj na dostęp publiczny z usług i zasobów platformy Azure w ramach platformy Azure do tego klastra.
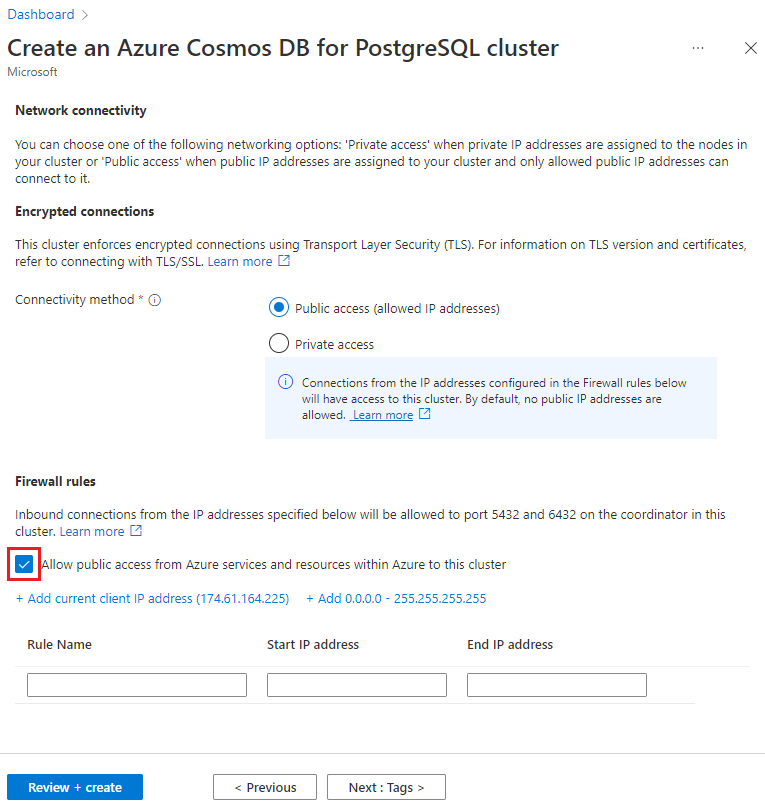
Wybierz pozycję Przeglądanie i tworzenie, a po zakończeniu walidacji wybierz pozycję Utwórz, aby utworzyć klaster.
Proces provisioningu trwa kilka minut. Strona przekierowuje do monitorowania wdrożenia. Gdy stan zmieni się z Wdrażanie jest w toku na Wdrożenie zostało ukończone, wybierz pozycję Przejdź do zasobu.
Tworzenie schematu za pomocą narzędzia psql
Po nawiązaniu połączenia z usługą Azure Cosmos DB for PostgreSQL przy użyciu narzędzia psql możesz wykonać kilka podstawowych zadań. Ten samouczek przeprowadzi Cię przez proces tworzenia aplikacji internetowej, która umożliwia reklamodawcom śledzenie ich kampanii.
Wiele firm może korzystać z aplikacji, więc utwórzmy jedną tabelę do przechowywania firm i inną dla ich kampanii. W konsoli programu psql uruchom następujące polecenia:
CREATE TABLE companies (
id bigserial PRIMARY KEY,
name text NOT NULL,
image_url text,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL
);
CREATE TABLE campaigns (
id bigserial,
company_id bigint REFERENCES companies (id),
name text NOT NULL,
cost_model text NOT NULL,
state text NOT NULL,
monthly_budget bigint,
blocked_site_urls text[],
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id)
);
Każda kampania będzie płacić za uruchamianie reklam. Dodaj też tabelę dla reklam, uruchamiając następujący kod w pliku psql po powyższym kodzie:
CREATE TABLE ads (
id bigserial,
company_id bigint,
campaign_id bigint,
name text NOT NULL,
image_url text,
target_url text,
impressions_count bigint DEFAULT 0,
clicks_count bigint DEFAULT 0,
created_at timestamp without time zone NOT NULL,
updated_at timestamp without time zone NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, campaign_id)
REFERENCES campaigns (company_id, id)
);
Na koniec prześledzimy statystyki dotyczące kliknięć i wyświetleń dla każdej reklamy:
CREATE TABLE clicks (
id bigserial,
company_id bigint,
ad_id bigint,
clicked_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_click_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
CREATE TABLE impressions (
id bigserial,
company_id bigint,
ad_id bigint,
seen_at timestamp without time zone NOT NULL,
site_url text NOT NULL,
cost_per_impression_usd numeric(20,10),
user_ip inet NOT NULL,
user_data jsonb NOT NULL,
PRIMARY KEY (company_id, id),
FOREIGN KEY (company_id, ad_id)
REFERENCES ads (company_id, id)
);
Nowo utworzone tabele można wyświetlić na liście tabel teraz w narzędziu psql, uruchamiając polecenie :
\dt
Aplikacje wielodostępne mogą egzekwować unikalność tylko dla każdego najemcy, dlatego wszystkie klucze główne i obce zawierają identyfikator najemcy.
Fragmentacja tabel po węzłach
Wdrożenie usługi Azure Cosmos DB for PostgreSQL przechowuje wiersze tabeli na różnych węzłach na podstawie wartości kolumny wyznaczonej przez użytkownika. Ta "kolumna dystrybucji" oznacza, który najemca posiada które wiersze.
Ustalmy kolumnę dystrybucji jako company_id, identyfikator najemcy. W narzędziu psql uruchom następujące funkcje:
SELECT create_distributed_table('companies', 'id');
SELECT create_distributed_table('campaigns', 'company_id');
SELECT create_distributed_table('ads', 'company_id');
SELECT create_distributed_table('clicks', 'company_id');
SELECT create_distributed_table('impressions', 'company_id');
Ważna
Rozpowszechnianie tabel lub używanie fragmentowania opartego na schemacie jest niezbędne do korzystania z funkcji wydajności usługi Azure Cosmos DB for PostgreSQL. Jeśli nie dystrybuujesz tabel ani schematów, węzły procesu roboczego nie mogą pomóc w uruchamianiu zapytań dotyczących ich danych.
Importowanie przykładowych danych
Poza narzędziem psql teraz w normalnym wierszu polecenia pobierz przykładowe zestawy danych:
for dataset in companies campaigns ads clicks impressions geo_ips; do
curl -O https://examples.citusdata.com/mt_ref_arch/${dataset}.csv
done
Wróć do narzędzia psql i wykonaj zbiorcze ładowanie danych. Pamiętaj, aby uruchomić narzędzie psql w tym samym katalogu, w którym pobrano pliki danych.
SET client_encoding TO 'UTF8';
\copy companies from 'companies.csv' with csv
\copy campaigns from 'campaigns.csv' with csv
\copy ads from 'ads.csv' with csv
\copy clicks from 'clicks.csv' with csv
\copy impressions from 'impressions.csv' with csv
Dane te będą teraz rozłożone na węzły robocze.
Zapytać o dane najemcy
Gdy aplikacja żąda danych dla jednego najemcy, baza danych może wykonać zapytanie na jednym węźle roboczym. Zapytania dotyczące jednego najemcy filtrują według jednego identyfikatora najemcy. Na przykład następujące filtry company_id = 5 zapytań dla reklam i wyświetleń. Spróbuj uruchomić go w narzędziu psql, aby wyświetlić wyniki.
SELECT a.campaign_id,
RANK() OVER (
PARTITION BY a.campaign_id
ORDER BY a.campaign_id, count(*) desc
), count(*) as n_impressions, a.id
FROM ads as a
JOIN impressions as i
ON i.company_id = a.company_id
AND i.ad_id = a.id
WHERE a.company_id = 5
GROUP BY a.campaign_id, a.id
ORDER BY a.campaign_id, n_impressions desc;
Udostępnianie danych między najemcami
Do tej pory wszystkie tabele były dystrybuowane przez company_id. Jednak niektóre dane nie należą naturalnie do żadnego lokatora, dlatego można je udostępniać. Na przykład wszystkie firmy na przykładowej platformie reklamowej mogą chcieć uzyskać informacje geograficzne dla swoich odbiorców na podstawie adresów IP.
Utwórz tabelę do przechowywania udostępnionych informacji geograficznych. Uruchom następujące polecenia w narzędziu psql:
CREATE TABLE geo_ips (
addrs cidr NOT NULL PRIMARY KEY,
latlon point NOT NULL
CHECK (-90 <= latlon[0] AND latlon[0] <= 90 AND
-180 <= latlon[1] AND latlon[1] <= 180)
);
CREATE INDEX ON geo_ips USING gist (addrs inet_ops);
Następnie utwórz geo_ips "tabelę referencyjną", aby przechowywać kopię tabeli w każdym węźle roboczym.
SELECT create_reference_table('geo_ips');
Załaduj je przy użyciu przykładowych danych. Pamiętaj, aby uruchomić to polecenie w narzędziu psql z poziomu katalogu, w którym pobrano zestaw danych.
\copy geo_ips from 'geo_ips.csv' with csv
Łączenie tabeli kliknięć z geo_ips jest wydajne na wszystkich węzłach. Oto połączenie, aby znaleźć lokalizacje wszystkich osób, które kliknęły reklamę 290. Spróbuj uruchomić zapytanie w psql.
SELECT c.id, clicked_at, latlon
FROM geo_ips, clicks c
WHERE addrs >> c.user_ip
AND c.company_id = 5
AND c.ad_id = 290;
Dostosuj schemat dla każdego najemcy
Każdy lokator może potrzebować przechowywać specjalne informacje, które nie są potrzebne innym. Jednak wszyscy dzierżawcy mają wspólną infrastrukturę z identycznym schematem bazy danych. Gdzie mogą trafić dodatkowe dane?
Jednym z trików jest użycie elastycznego typu kolumny, takiego jak JSONB bazy danych PostgreSQL. Nasz schemat zawiera pole JSONB w clicks, nazwane user_data.
Firma (np. pięć firm) może używać kolumny do śledzenia, czy użytkownik jest na urządzeniu przenośnym.
Oto zapytanie, aby dowiedzieć się, którzy odwiedzający klikają więcej: ci korzystający z urządzeń mobilnych czy tradycyjni.
SELECT
user_data->>'is_mobile' AS is_mobile,
count(*) AS count
FROM clicks
WHERE company_id = 5
GROUP BY user_data->>'is_mobile'
ORDER BY count DESC;
Możemy zoptymalizować to zapytanie dla jednej firmy, tworząc indeks częściowy.
CREATE INDEX click_user_data_is_mobile
ON clicks ((user_data->>'is_mobile'))
WHERE company_id = 5;
Ogólnie rzecz biorąc, możemy utworzyć indeksy GIN dla każdego klucza i wartości w kolumnie.
CREATE INDEX click_user_data
ON clicks USING gin (user_data);
-- this speeds up queries like, "which clicks have
-- the is_mobile key present in user_data?"
SELECT id
FROM clicks
WHERE user_data ? 'is_mobile'
AND company_id = 5;
Uprzątnij zasoby
W poprzednich krokach utworzono zasoby platformy Azure w klastrze. Jeśli nie spodziewasz się, że te zasoby będą potrzebne w przyszłości, usuń klaster. Wybierz przycisk Usuń na stronie Przegląd klastra. Po wyświetleniu monitu na wyskakującym okienku potwierdź nazwę klastra i wybierz końcowy przycisk Usuń .
Następne kroki
W tym samouczku nauczyłeś się, jak skonfigurować klaster. Podłączyłeś się do niego za pomocą narzędzia psql, utworzyłeś schemat i rozprowadziłeś dane. Wiesz już, jak wykonywać zapytania dotyczące danych zarówno w ramach dzierżaw, jak i między nimi, oraz dostosować schemat dla każdej dzierżawy.
- Dowiedz się więcej o typach węzłów klastra
- Określanie najlepszego rozmiaru początkowego klastra