Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Użyj wyszukiwania wektorów w Azure Cosmos DB z biblioteką klienta Python. Wydajne przechowywanie danych wektorów i wykonywanie zapytań w aplikacjach.
W tym przewodniku szybkiego startu użyto przykładowego hotelowego zestawu danych zawartego w pliku JSON z wektorami z modelu text-embedding-3-small. Zestaw danych zawiera nazwy hoteli, lokalizacje, opisy i osadzanie wektorów.
Znajdź przykładowy kod z aprowizowaniem zasobów w GitHub.
Wymagania wstępne
Subskrypcja Azure
- Jeśli nie masz subskrypcji Azure, utwórz konto free
Istniejący dostęp do płaszczyzny danych zasobów Azure Cosmos DB
- Jeśli nie masz zasobu, utwórz zasób nowy zasób
- Zapora skonfigurowana do zezwalania na dostęp do adresu IP klienta
- Przypisane role kontroli dostępu opartej na rolach (RBAC):
- Wbudowany współautor danych w usłudze Cosmos DB (płaszczyzna danych)
- Identyfikator roli:
00000000-0000-0000-0000-000000000002
-
- Skonfigurowano domenę niestandardową
- Przypisano rolę kontroli dostępu opartej na rolach (RBAC):
- Użytkownik usług Cognitive Services OpenAI
- Identyfikator roli:
5e0bd9bd-7b93-4f28-af87-19fc36ad61bd
-
text-embedding-3-smallwdrożony model
Tworzenie pliku danych z wektorami
Utwórz nowy katalog danych dla pliku danych hoteli:
mkdir dataPobierz plik danych raw z wektorami do katalogu
data:curl -o data/HotelsData_toCosmosDB_Vector.json https://raw.githubusercontent.com/Azure-Samples/cosmos-db-vector-samples/refs/heads/main/data/HotelsData_toCosmosDB_Vector.json
Tworzenie projektu Python
Utwórz nowy katalog równorzędny dla projektu na tym samym poziomie co katalog danych i otwórz go w Visual Studio Code:
mkdir vector-search-quickstart code vector-search-quickstartW terminalu utwórz i aktywuj środowisko wirtualne Python:
python -m venv .venvsource .venv/bin/activaterequirements.txtUtwórz plik w katalogu głównym projektu z następującą zawartością:azure-cosmos>=4.7.0 azure-identity>=1.18.0 openai>=1.57.0 python-dotenv>=1.0.1Zainstaluj wymagane pakiety:
pip install -r requirements.txt- azure-cosmos — biblioteka klienta Azure Cosmos DB dla operacji bazy danych
- azure-identity — biblioteka uwierzytelniania Azure dla połączeń bez hasła (tożsamości zarządzanej)
- openai — Zestaw SDK openAI do generowania osadzania za pomocą Azure OpenAI
-
python-dotenv — ładuje zmienne środowiskowe z
.envpliku
.envUtwórz plik w katalogu głównym projektu dla zmiennych środowiskowych:# Identity for local developer authentication with Azure CLI AZURE_TOKEN_CREDENTIALS=AzureCliCredential # Azure OpenAI Embedding Settings AZURE_OPENAI_EMBEDDING_MODEL=text-embedding-3-small AZURE_OPENAI_EMBEDDING_API_VERSION=2024-08-01-preview AZURE_OPENAI_EMBEDDING_ENDPOINT= # Cosmos DB configuration AZURE_COSMOSDB_ENDPOINT= # Data file DATA_FILE_WITH_VECTORS=../data/HotelsData_toCosmosDB_Vector.json FIELD_TO_EMBED=Description EMBEDDED_FIELD=DescriptionVector EMBEDDING_DIMENSIONS=1536Zastąp wartości znaczników zastępczych w pliku
.envwłasnymi informacjami:-
AZURE_OPENAI_EMBEDDING_ENDPOINT: Adres URL punktu końcowego zasobu Azure OpenAI -
AZURE_COSMOSDB_ENDPOINT: Adres URL punktu końcowego Azure Cosmos DB
-
Omówienie schematu dokumentu
Przed utworzeniem aplikacji dowiedz się, jak wektory są przechowywane w dokumentach Azure Cosmos DB. Każdy dokument hotelowy zawiera:
-
Pola standardowe:
HotelId,HotelName,Description,Category, itp. -
Pole wektorowe:
DescriptionVector— tablica 1536 liczb zmiennoprzecinkowych reprezentujących semantyczne znaczenie opisu hotelu
Oto uproszczony przykład struktury dokumentów hotelowych:
{
"HotelId": "1",
"HotelName": "Stay-Kay City Hotel",
"Description": "This classic hotel is fully-refurbished...",
"Rating": 3.6,
"DescriptionVector": [
-0.04886505,
-0.02030743,
0.01763356,
...
// 1536 dimensions total
]
}
Najważniejsze kwestie dotyczące przechowywania osadzania:
- Tablice wektorowe są przechowywane jako standardowe tablice JSON w dokumentach
-
Zasady wektorów definiują ścieżkę (), typ danych (
/DescriptionVectorfloat32), wymiary (1536) i funkcję odległości (cosinus) - Zasady indeksowania tworzą indeks wektorowy w polu wektora w celu wydajnego wyszukiwania podobieństwa
- Pole wektorowe powinno zostać wykluczone ze standardowego indeksowania w celu zoptymalizowania wydajności wstawiania
Te zasady są definiowane w szablonach Bicep dla metryk odległości dla tego przykładowego projektu. Aby uzyskać więcej informacji na temat polityk wektorowych i indeksowania, zobacz Wyszukiwanie wektorowe w Azure Cosmos DB.
Tworzenie plików kodu na potrzeby wyszukiwania wektorowego
Utwórz katalog src dla plików Python. Dodaj dwa pliki: vector_search.py i utils.py dla implementacji wyszukiwania wektorowego:
mkdir src
touch src/__init__.py
touch src/vector_search.py
touch src/utils.py
Tworzenie kodu na potrzeby wyszukiwania wektorów
Wklej następujący kod do vector_search.py pliku.
"""Azure Cosmos DB NoSQL Vector Search — main entry point.
Loads hotel data, bulk-inserts into the selected container (DiskANN or
QuantizedFlat), generates a query embedding via Azure OpenAI, and
executes a VectorDistance() similarity search.
"""
import os
import sys
from pathlib import Path
from dotenv import load_dotenv
sys.path.insert(0, str(Path(__file__).parent))
from utils import (
get_clients_passwordless,
get_clients,
insert_data,
print_search_results,
read_file_return_json,
validate_field_name,
get_query_activity_id,
)
# ---------------------------------------------------------------------------
# Load environment
# ---------------------------------------------------------------------------
load_dotenv()
ALGORITHM_CONFIGS: dict[str, dict[str, str]] = {
"diskann": {
"container_name": "hotels_diskann",
"algorithm_name": "DiskANN",
},
"quantizedflat": {
"container_name": "hotels_quantizedflat",
"algorithm_name": "QuantizedFlat",
},
}
def _build_config() -> dict[str, str | int]:
"""Build runtime configuration from environment variables."""
return {
"query": "quintessential lodging near running trails, eateries, retail",
"db_name": os.getenv("AZURE_COSMOSDB_DATABASENAME", "Hotels"),
"algorithm": os.getenv("VECTOR_ALGORITHM", "diskann").strip().lower(),
"data_file": os.getenv("DATA_FILE_WITH_VECTORS", "../data/HotelsData_toCosmosDB_Vector.json"),
"embedded_field": os.getenv("EMBEDDED_FIELD", "DescriptionVector"),
"embedding_dimensions": int(os.getenv("EMBEDDING_DIMENSIONS", "1536")),
"deployment": os.getenv("AZURE_OPENAI_EMBEDDING_MODEL", "text-embedding-3-small"),
"distance_function": os.getenv("VECTOR_DISTANCE_FUNCTION", "cosine"),
}
def main() -> None:
"""Run the vector search demonstration."""
config = _build_config()
# Try passwordless auth first, fall back to key-based
clients = get_clients_passwordless()
if not clients["ai_client"] or not clients["db_client"]:
clients = get_clients()
ai_client = clients["ai_client"]
db_client = clients["db_client"]
try:
algorithm = config["algorithm"]
if algorithm not in ALGORITHM_CONFIGS:
valid = ", ".join(ALGORITHM_CONFIGS)
raise ValueError(
f"Invalid algorithm '{algorithm}'. Must be one of: {valid}"
)
if not ai_client:
raise RuntimeError(
"Azure OpenAI client is not configured. "
"Please check your environment variables."
)
if not db_client:
raise RuntimeError(
"Cosmos DB client is not configured. "
"Please check your environment variables."
)
algo_cfg = ALGORITHM_CONFIGS[algorithm]
container_name = algo_cfg["container_name"]
database = db_client.get_database_client(config["db_name"])
print(f"Connected to database: {config['db_name']}")
container = database.get_container_client(container_name)
print(f"Connected to container: {container_name}")
print(f"\n📊 Vector Search Algorithm: {algo_cfg['algorithm_name']}")
print(f"📏 Distance Function: {config['distance_function']}")
# Verify the container exists
try:
container.read()
except Exception as e:
status_code = getattr(e, "status_code", None)
if status_code == 404:
raise RuntimeError(
f"Container or database not found. Ensure database "
f"'{config['db_name']}' and container '{container_name}' "
f"exist before running this script."
) from e
raise
data_path = Path(__file__).parent.parent / config["data_file"]
data = read_file_return_json(str(data_path))
insert_data(container, data)
embedding_response = ai_client.embeddings.create(
model=config["deployment"],
input=[config["query"]],
)
query_embedding = embedding_response.data[0].embedding
safe_field = validate_field_name(config["embedded_field"])
query_text = (
f"SELECT TOP 5 c.HotelName, c.Description, c.Rating, "
f"VectorDistance(c.{safe_field}, @embedding) AS SimilarityScore "
f"FROM c "
f"ORDER BY VectorDistance(c.{safe_field}, @embedding)"
)
print("\n--- Executing Vector Search Query ---")
print(f"Query: {query_text}")
print(
f"Parameters: @embedding (vector with {len(query_embedding)} dimensions)"
)
print("--------------------------------------\n")
results = list(
container.query_items(
query=query_text,
parameters=[{"name": "@embedding", "value": query_embedding}],
enable_cross_partition_query=True,
)
)
# Extract diagnostics
response_headers = container.client_connection.last_response_headers
activity_id = get_query_activity_id(response_headers)
if activity_id:
print(f"Query activity ID: {activity_id}")
request_charge_raw = response_headers.get("x-ms-request-charge", "0") if response_headers else "0"
try:
request_charge = float(request_charge_raw)
except (ValueError, TypeError):
request_charge = 0.0
print_search_results(results, request_charge)
except Exception as error:
print(f"App failed: {error}", file=sys.stderr)
sys.exit(1)
if __name__ == "__main__":
main()
Ten kod:
- Konfiguruje algorytm wektora
DiskANNlubquantizedFlatze zmiennych środowiskowych. - Nawiązuje połączenie z Azure OpenAI i Azure Cosmos DB poprzez uwierzytelnianie bezhasłowe.
- Ładuje wstępnie wektoryzowane dane hotelowe z pliku JSON.
- Wstawia dane do odpowiedniego kontenera.
- Generuje osadzanie dla zapytania w języku naturalnym (
quintessential lodging near running trails, eateries, retail). - Wykonuje zapytanie SQL,
VectorDistanceaby pobrać 5 najbardziej semantycznie podobnych hoteli sklasyfikowanych według wyniku podobieństwa. - Obsługuje błędy brakujących klientów, wybór nieprawidłowego algorytmu i nieistniejące kontenery/bazy danych.
Omówienie kodu: Generowanie osadzania za pomocą Azure OpenAI
Kod tworzy osadzanie dla tekstu zapytania:
embedding_response = ai_client.embeddings.create(
model=config["deployment"], # OpenAI embedding model, e.g. "text-embedding-3-small"
input=[config["query"]], # List of description strings to embed
)
query_embedding = embedding_response.data[0].embedding
To wywołanie interfejsu API OpenAI dla client.embeddings.create konwertuje tekst, taki jak "charakterystyczne zakwaterowanie w pobliżu szlaków biegowych," na 1536-wymiarowy wektor, który oddaje jego znaczenie semantyczne. Aby uzyskać więcej informacji na temat generowania wektorów osadzających, zobacz dokumentację wektorów osadzających Azure OpenAI.
Opis kodu: Przechowywanie wektorów w Azure Cosmos DB
Wszystkie dokumenty z tablicami wektorowymi są wstawiane przy użyciu upsert_item funkcji :
for item in data:
doc = {"id": item["HotelId"], **item}
response = container.upsert_item(body=doc)
Spowoduje to wstawienie dokumentów hotelowych, w tym wstępnie wygenerowanych DescriptionVector tablic do kontenera. Każdy dokument otrzymuje pole id mapowane z HotelId elementu, a funkcja obsługuje operacje typu upsert, dzięki czemu dokumenty można bezpiecznie ponownie wprowadzać.
Opis kodu: Uruchamianie wyszukiwania podobieństwa wektorów
Kod wykonuje wyszukiwanie wektorów przy użyciu VectorDistance funkcji :
query_text = (
f"SELECT TOP 5 c.HotelName, c.Description, c.Rating, "
f"VectorDistance(c.{safe_field}, @embedding) AS SimilarityScore "
f"FROM c "
f"ORDER BY VectorDistance(c.{safe_field}, @embedding)"
)
results = list(
container.query_items(
query=query_text,
parameters=[{"name": "@embedding", "value": query_embedding}],
enable_cross_partition_query=True,
)
)
Ten kod tworzy sparametryzowane zapytanie SQL, które używa funkcji VectorDistance do porównywania wektora osadzania zapytania (@embedding) względem pola wektora składowanego każdego dokumentu (DescriptionVector), zwracając 5 najlepszych hoteli z ich nazwą i wynikiem podobieństwa, uporządkowanym z najbardziej podobnych do najmniej podobnych. Osadzenie zapytania jest przekazywane jako parametr, aby uniknąć iniekcji, i pochodzi z wcześniejszego wywołania funkcji Azure OpenAI embeddings.create.
Co zwraca to zapytanie:
- 5 najbardziej podobnych hoteli w oparciu o odległość wektora
- Właściwości hoteli:
HotelName,Description,Rating -
SimilarityScore: wartość liczbowa wskazująca, jak podobny jest każdy hotel do zapytania - Wyniki uporządkowane z najbardziej podobnych do najmniej podobnych
Aby uzyskać więcej informacji na VectorDistance temat funkcji, zobacz dokumentację vectorDistance.
Tworzenie funkcji narzędziowych
Wklej następujący kod do utils.pypliku :
"""Shared utilities for Azure Cosmos DB NoSQL vector search.
Provides client initialization (passwordless and key-based), JSON I/O,
bulk insert with RU tracking, field validation, and result formatting.
"""
import json
import os
import re
import time
from typing import Any, Optional
def get_clients() -> dict[str, Any]:
"""Get Azure OpenAI and Cosmos DB clients using key-based authentication.
Returns dict with 'ai_client' and 'db_client' (either may be None if
the required environment variables are missing).
"""
from azure.cosmos import CosmosClient
from openai import AzureOpenAI
ai_client = None
db_client = None
api_key = os.getenv("AZURE_OPENAI_EMBEDDING_KEY", "")
api_version = os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION", "")
endpoint = os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT", "")
deployment = os.getenv("AZURE_OPENAI_EMBEDDING_MODEL", "")
if api_key and api_version and endpoint and deployment:
ai_client = AzureOpenAI(
api_key=api_key,
api_version=api_version,
azure_endpoint=endpoint,
azure_deployment=deployment,
)
cosmos_endpoint = os.getenv("AZURE_COSMOSDB_ENDPOINT", "")
cosmos_key = os.getenv("AZURE_COSMOSDB_KEY", "")
if cosmos_endpoint and cosmos_key:
db_client = CosmosClient(url=cosmos_endpoint, credential=cosmos_key)
return {"ai_client": ai_client, "db_client": db_client}
def get_clients_passwordless() -> dict[str, Any]:
"""Get Azure OpenAI and Cosmos DB clients using DefaultAzureCredential.
Uses managed identity / Azure CLI credentials for passwordless auth.
Returns dict with 'ai_client' and 'db_client' (either may be None).
"""
from azure.cosmos import CosmosClient
from azure.identity import DefaultAzureCredential, get_bearer_token_provider
from openai import AzureOpenAI
ai_client = None
db_client = None
api_version = os.getenv("AZURE_OPENAI_EMBEDDING_API_VERSION", "")
endpoint = os.getenv("AZURE_OPENAI_EMBEDDING_ENDPOINT", "")
deployment = os.getenv("AZURE_OPENAI_EMBEDDING_MODEL", "")
if api_version and endpoint and deployment:
credential = DefaultAzureCredential()
token_provider = get_bearer_token_provider(
credential, "https://cognitiveservices.azure.com/.default"
)
ai_client = AzureOpenAI(
api_version=api_version,
azure_endpoint=endpoint,
azure_deployment=deployment,
azure_ad_token_provider=token_provider,
)
cosmos_endpoint = os.getenv("AZURE_COSMOSDB_ENDPOINT", "")
if cosmos_endpoint:
credential = DefaultAzureCredential()
db_client = CosmosClient(url=cosmos_endpoint, credential=credential)
return {"ai_client": ai_client, "db_client": db_client}
def read_file_return_json(file_path: str) -> list[dict[str, Any]]:
"""Read a JSON file and return its parsed contents."""
print(f"Reading JSON file from {file_path}")
try:
with open(file_path, "r", encoding="utf-8") as f:
return json.load(f)
except FileNotFoundError:
print(f"Error: File '{file_path}' not found")
raise
except json.JSONDecodeError as e:
print(f"Error: Invalid JSON in file '{file_path}': {e}")
raise
def write_file_json(file_path: str, json_data: Any) -> None:
"""Serialize data to a JSON file."""
try:
with open(file_path, "w", encoding="utf-8") as f:
json.dump(json_data, f, indent=2, ensure_ascii=False)
print(f"Wrote JSON file to {file_path}")
except IOError as e:
print(f"Error writing to file '{file_path}': {e}")
raise
def _get_document_count(container: Any) -> int:
"""Return the number of documents in a Cosmos DB container."""
query = "SELECT VALUE COUNT(1) FROM c"
results = list(container.query_items(query=query, enable_cross_partition_query=True))
return results[0] if results else 0
def insert_data(
container: Any, data: list[dict[str, Any]]
) -> dict[str, Any]:
"""Bulk-insert documents into a Cosmos DB container.
Skips insertion if the container already has documents.
Each item gets an 'id' field mapped from 'HotelId'.
Returns a dict with total, inserted, failed, skipped, and requestCharge.
"""
existing_count = _get_document_count(container)
if existing_count > 0:
print(f"Container already has {existing_count} documents. Skipping insert.")
return {
"total": 0,
"inserted": 0,
"failed": 0,
"skipped": existing_count,
"requestCharge": 0.0,
}
print(f"Inserting {len(data)} items...")
inserted = 0
failed = 0
total_request_charge = 0.0
start_time = time.time()
for item in data:
doc = {"id": item["HotelId"], **item}
try:
response = container.upsert_item(body=doc)
inserted += 1
ru = _extract_ru_from_headers(container.client_connection.last_response_headers)
total_request_charge += ru
except Exception as e:
status_code = getattr(e, "status_code", None)
if status_code == 409:
inserted += 1
else:
failed += 1
print(f" Insert failed for item {item.get('HotelId', '?')}: {e}")
duration = time.time() - start_time
print(f"Bulk insert completed in {duration:.2f}s")
print(f"\nInsert Request Charge: {total_request_charge:.2f} RUs\n")
return {
"total": len(data),
"inserted": inserted,
"failed": failed,
"skipped": 0,
"requestCharge": total_request_charge,
}
def _extract_ru_from_headers(headers: Optional[dict[str, str]]) -> float:
"""Extract the request charge (RU) from Cosmos DB response headers."""
if not headers:
return 0.0
raw = headers.get("x-ms-request-charge", "0")
try:
return float(raw)
except (ValueError, TypeError):
return 0.0
def validate_field_name(field_name: str) -> str:
"""Validate a field name is a safe SQL identifier.
Prevents NoSQL injection when interpolating field names into queries.
Allows only letters, digits, and underscores; must start with a letter
or underscore.
Raises ValueError if the field name is invalid.
"""
pattern = re.compile(r"^[A-Za-z_][A-Za-z0-9_]*$")
if not pattern.match(field_name):
raise ValueError(
f'Invalid field name: "{field_name}". '
"Field names must start with a letter or underscore and "
"contain only letters, numbers, and underscores."
)
return field_name
def print_search_results(
search_results: list[dict[str, Any]],
request_charge: Optional[float] = None,
) -> None:
"""Print vector search results in a consistent format."""
print("\n--- Search Results ---")
if not search_results:
print("No results found.")
return
for i, result in enumerate(search_results, 1):
score = result.get("SimilarityScore", 0.0)
name = result.get("HotelName", "Unknown")
print(f"{i}. {name}, Score: {score:.4f}")
if request_charge is not None:
print(f"\nVector Search Request Charge: {request_charge:.2f} RUs")
print("")
def get_query_activity_id(response_headers: Optional[dict[str, str]]) -> Optional[str]:
"""Extract the activity ID from Cosmos DB query response headers."""
if not response_headers:
return None
return response_headers.get("x-ms-activity-id")
def get_bulk_operation_rus(headers: Optional[dict[str, str]]) -> float:
"""Extract total RU cost from Cosmos DB response headers."""
return _extract_ru_from_headers(headers)
Ten moduł narzędziowy udostępnia następujące kluczowe funkcje:
-
get_clients_passwordless: tworzy i zwraca klientów dla Azure OpenAI i Azure Cosmos DB przy użyciu uwierzytelniania bez hasła. Włącz kontrolę dostępu opartą na rolach dla obu zasobów i zaloguj się do Azure CLI -
insert_data: Wstawia dane do kontenera Azure Cosmos DB i śledzi jednostki żądań (RU) dla każdej operacji -
print_search_results: Wyświetla wyniki wyszukiwania wektorowego, w tym wynik i nazwę hotelu -
validate_field_name: sprawdza, czy nazwa pola istnieje w danych -
get_bulk_operation_rus: wyodrębnia całkowity koszt jednostek zapytań z nagłówków odpowiedzi Azure Cosmos DB
Uwierzytelnianie przy użyciu Azure CLI
Zaloguj się do Azure CLI przed uruchomieniem aplikacji, aby aplikacja mogła bezpiecznie uzyskiwać dostęp do Azure zasobów.
az login
Kod używa lokalnego uwierzytelniania dewelopera do uzyskiwania dostępu do Azure Cosmos DB i Azure OpenAI za pomocą funkcji get_clients_passwordless z utils.py. Po ustawieniu AZURE_TOKEN_CREDENTIALS=AzureCliCredential, wybierasz w sposób deterministyczny, które poświadczenie DefaultAzureCredential używa w swoim łańcuchu poświadczeń. Funkcja opiera się na DefaultAzureCredential z azure-identity, która przeprowadza uporządkowany łańcuch dostawców poświadczeń, ale honoruje zmienną środowiskową, aby najpierw rozpoznać Azure CLI poświadczenia. Dowiedz się więcej o sposobie uwierzytelniania aplikacji Python do usług Azure przy użyciu biblioteki Azure Identity.
Uruchamianie aplikacji
Użyj zmiennej środowiskowej, aby wybrać implementację indeksu VECTOR_ALGORITHM wektorowego do uruchomienia. Zmienna kontroluje, z którym kontenerem Azure Cosmos DB nawiązuje połączenie aplikacja.
Linux/macOS:
VECTOR_ALGORITHM=diskann python -m src.vector_search
Windows:
$env:VECTOR_ALGORITHM="diskann"; python -m src.vector_search
Rejestrowanie i dane wyjściowe aplikacji pokazują:
- Stan połączenia kontenera
- Stan wstawiania danych
- Wyniki wyszukiwania z nazwami hoteli i wynikami podobieństwa
Connected to database: Hotels
Connected to container: hotels_diskann
📊 Vector Search Algorithm: DiskANN
📏 Distance Function: cosine
Reading JSON file from ..\data\HotelsData_toCosmosDB_Vector.json
Container already has 50 documents. Skipping insert.
--- Executing Vector Search Query ---
Query: SELECT TOP 5 c.HotelName, c.Description, c.Rating, VectorDistance(c.DescriptionVector, @embedding) AS SimilarityScore FROM c ORDER BY VectorDistance(c.DescriptionVector, @embedding)
Parameters: @embedding (vector with 1536 dimensions)
--------------------------------------
Query activity ID: <ACTIVITY_ID>
--- Search Results ---
1. Royal Cottage Resort, Score: 0.4991
2. Country Comfort Inn, Score: 0.4786
3. Nordick's Valley Motel, Score: 0.4635
4. Economy Universe Motel, Score: 0.4461
5. Roach Motel, Score: 0.4388
Vector Search Request Charge: 5.33 RUs
Metryki odległości
Azure Cosmos DB obsługuje trzy funkcje odległości dla podobieństwa wektorów:
| Funkcja odległości | Zakres wyników | Interpretacja | Najlepsze dla |
|---|---|---|---|
| Cosinus (ustawienie domyślne) | Od 0.0 do 1.0 | Wyższe wyniki (bliżej 1,0) wskazują na większe podobieństwo | Ogólne podobieństwo tekstu, osadzenia Azure OpenAI (używane w tym szybkim starcie) |
| Euklidesan (L2) | Od 0,0 do ∞ | Dolna = bardziej podobna | Dane przestrzenne, gdy wielkość ma znaczenie |
| Kropka produktu | -∞ do +∞ | Wyższe = bardziej podobne | Gdy wielkości wektorów są znormalizowane |
Funkcja distance jest ustawiana w zasadach osadzania wektorów podczas tworzenia kontenera. Jest to dostępne w infrastrukturze w przykładowym repozytorium. Jest on definiowany jako część definicji kontenera.
{
name: 'hotels_diskann'
partitionKeyPaths: [
'/HotelId'
]
indexingPolicy: {
indexingMode: 'consistent'
automatic: true
includedPaths: [
{
path: '/*'
}
]
excludedPaths: [
{
path: '/_etag/?'
}
{
path: '/DescriptionVector/*'
}
]
vectorIndexes: [
{
path: '/DescriptionVector'
type: 'diskANN'
}
]
}
vectorEmbeddingPolicy: {
vectorEmbeddings: [
{
path: '/DescriptionVector'
dataType: 'float32'
dimensions: 1536
distanceFunction: 'cosine'
}
]
}
}
Ten kod Bicep definiuje konfigurację kontenera Azure Cosmos DB do przechowywania dokumentów hotelowych z funkcjami wyszukiwania wektorowego.
| Majątek | Opis |
|---|---|
partitionKeyPaths |
Partycjonuje dokumenty z użyciem HotelId dla rozproszonego przechowywania. |
indexingPolicy |
Konfiguruje automatyczne indeksowanie wszystkich właściwości dokumentu (/*) oprócz pola systemowego _etag i tablicy DescriptionVector w celu zoptymalizowania wydajności zapisu. Pola wektorowe nie wymagają indeksowania standardowego, ponieważ zamiast tego używają wyspecjalizowanej vectorIndexes konfiguracji. |
vectorIndexes |
Tworzy indeks DiskANN lub quantizedFlat na /DescriptionVector ścieżce w celu efektywnego wyszukiwania podobieństwa. |
vectorEmbeddingPolicy |
Definiuje cechy pola wektorowego: float32 typ danych o wymiarach 1536 (pasujących text-embedding-3-small do danych wyjściowych modelu) i cosinus jako funkcja odległości do mierzenia podobieństwa między wektorami podczas zapytań. |
Interpretowanie wyników podobieństwa
W przykładowych wynikach przy użyciu podobieństwa cosinus:
- 0.4991 (Royal Cottage Resort) - Najwyższa podobieństwo, najlepsze dopasowanie do "zakwaterowania w pobliżu tras biegowych, restauracji, handlu detalicznego"
- 0.4388 (Roach Motel) - Niższe podobieństwo, nadal istotne, ale mniej zgodne
- Wyniki bliżej 1,0 wskazują na silniejsze podobieństwo semantyczne
- Wyniki zbliżone do 0 wskazują na niewielkie podobieństwo
Ważne uwagi:
- Wartości wyników bezwzględnych zależą od modelu osadzania i danych
- Skup się na względnym rankingu , a nie na progach bezwzględnych
- Embeddingi Azure OpenAI najlepiej współpracują z podobieństwem cosinusowym.
Aby uzyskać szczegółowe informacje na temat funkcji odległości, zobacz Co to są funkcje odległości?
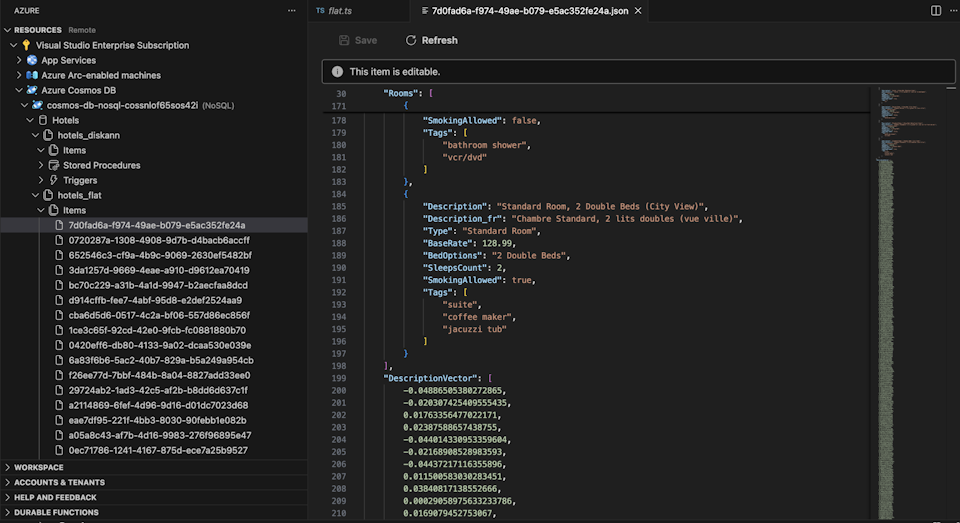
Wyświetlanie danych i zarządzanie nimi w Visual Studio Code
Wybierz rozszerzenie Cosmos DB w Visual Studio Code, aby nawiązać połączenie z kontem Azure Cosmos DB.
Wyświetl dane i indeksy w bazie danych Hotels.

Uprzątnij zasoby
Jeśli nie potrzebujesz już interfejsu API dla konta NoSQL, możesz usunąć odpowiednią grupę zasobów.
Przejdź do grupy zasobów utworzonej wcześniej w portalu Azure.
Wskazówka
W tym przewodniku Szybki start zalecamy nazwę
msdocs-cosmos-quickstart-rg.Wybierz pozycję Usuń grupę zasobów.
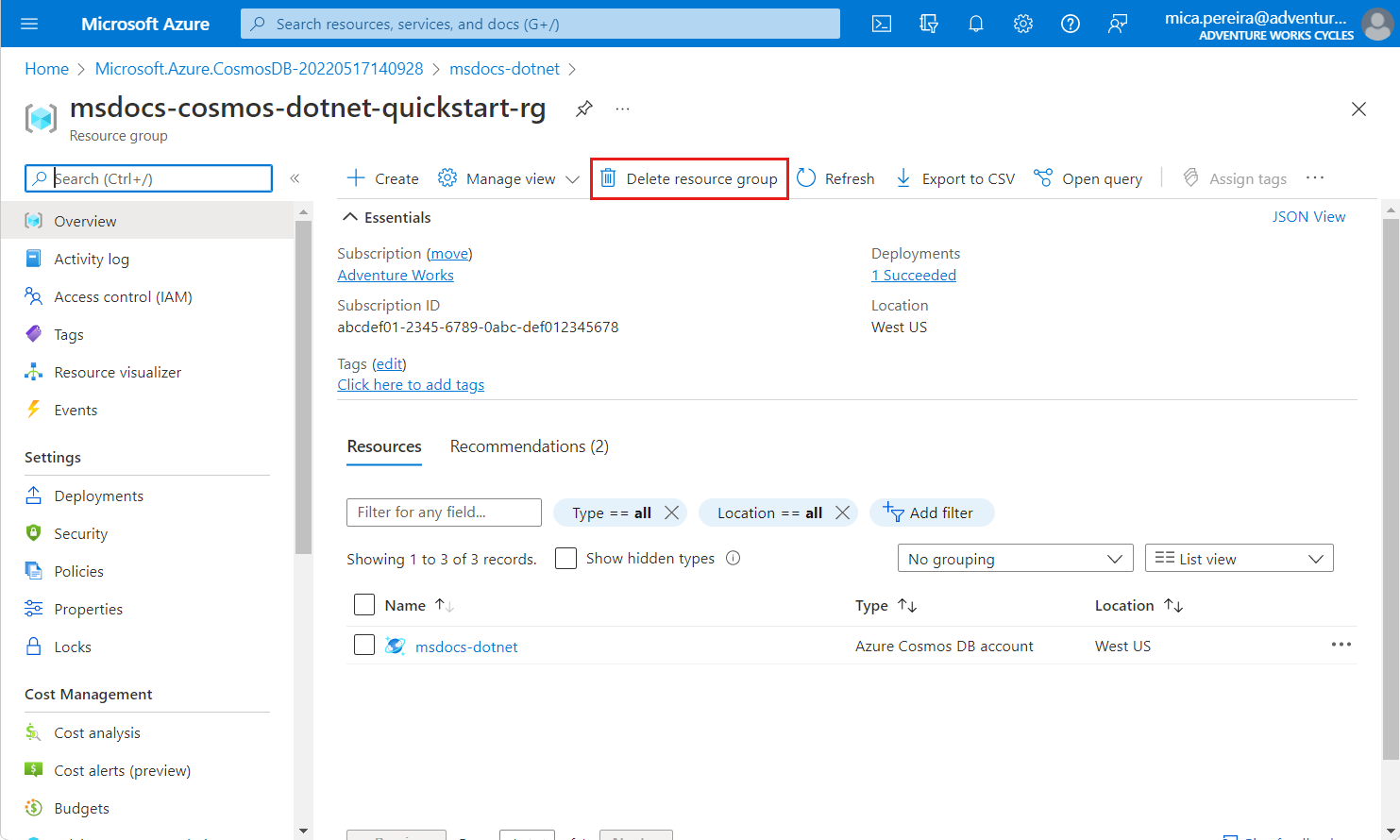
W oknie dialogowym Czy na pewno chcesz usunąć , wprowadź nazwę grupy zasobów, a następnie wybierz pozycję Usuń.