Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure Cosmos DB używa partycjonowania do skalowania kontenerów w bazie danych w celu spełnienia wymagań dotyczących wydajności aplikacji. Elementy w kontenerze są podzielone na odrębne podzestawy nazywane partycjami logicznymi. Partycje logiczne tworzą się na podstawie wartości klucza partycji skojarzonego z każdym elementem w kontenerze. Wszystkie elementy w partycji logicznej mają tę samą wartość klucza partycji.
Na przykład kontener przechowuje elementy. Każdy element ma unikatową wartość właściwości UserID . Jeśli UserID służy jako klucz partycji dla elementów w kontenerze i istnieje 1000 unikatowych UserID wartości, dla kontenera są tworzone 1000 partycji logicznych.
Każdy element w kontenerze ma klucz partycji , który określa jego partycję logiczną i identyfikator elementu unikatowy w ramach tej partycji. Połączenie klucza partycji i identyfikatora elementu powoduje utworzenie indeksu elementu, który jednoznacznie identyfikuje element. Wybranie klucza partycji jest ważną decyzją, która wpływa na wydajność aplikacji.
Uwaga / Notatka
W niektórych rozproszonych systemach baz danych i materiałach szkoleniowych termin klucz fragmentu służy do opisywania właściwości określającej sposób dystrybucji danych między fragmentami. W usłudze Azure Cosmos DB ta sama koncepcja jest nazywana kluczem partycji.
Oba terminy odnoszą się do wartości używanej do dystrybucji i lokalizowania danych, ale klucz partycji jest oficjalnym i poprawnym terminem używanym w całej dokumentacji i interfejsach API usługi Azure Cosmos DB.
W tym artykule wyjaśniono relację między partycjami logicznymi i fizycznymi, omówiono najlepsze rozwiązania dotyczące partycjonowania i przedstawiono szczegółowy widok działania skalowania w poziomie w usłudze Azure Cosmos DB. Nie musisz rozumieć tych wewnętrznych szczegółów, aby wybrać klucz partycji, ale w tym artykule opisano je, aby wyjaśnić, jak działa usługa Azure Cosmos DB.
Partycje logiczne
Partycja logiczna to zestaw elementów współużytkujących ten sam klucz partycji. Na przykład w kontenerze zawierającym dane dotyczące żywienia żywności wszystkie elementy zawierają foodGroup właściwość. Użyj foodGroup jako klucza partycji dla kontenera. Grupy elementów, które mają określone wartości dla foodGroup, takich jak Beef Products, Baked Productsi Sausages and Luncheon Meats, tworzą odrębne partycje logiczne.
Partycja logiczna definiuje również zakres transakcji bazy danych. Elementy w logicznej partycji można aktualizować przy użyciu transakcji z izolacją migawki. Po dodaniu nowych elementów do kontenera system w przezroczysty sposób tworzy nowe partycje logiczne. Nie musisz martwić się o usunięcie partycji logicznej po usunięciu danych bazowych.
Nie ma limitu liczby partycji logicznych w kontenerze. Każda partycja logiczna może przechowywać do 20 GB danych. Obowiązujące klucze partycji mają szeroki zakres możliwych wartości. Na przykład w kontenerze, w którym wszystkie elementy zawierają foodGroup właściwość, dane w Beef Products partycji logicznej mogą rosnąć do 20 GB.
Wybranie klucza partycji z szerokim zakresem możliwych wartości gwarantuje możliwość skalowania kontenera.
Jeśli masz scenariusze, w których klucze partycji mogą przekraczać 20 GB danych, użycie hierarchicznych kluczy partycji może pomóc. Jeśli używasz tej funkcji, możesz skonfigurować maksymalnie trzy-poziomową hierarchię kluczy partycji w celu dalszej optymalizacji dystrybucji danych i wyższego poziomu skalowania. Zobaczhierarchiczne klucze partycji — omówienie.
Użyj alertów usługi Azure Monitor, aby monitorować, czy rozmiar partycji logicznej zbliża się do 20 GB.
Partycje fizyczne
Kontener jest skalowany przez dystrybucję danych i przepływności między partycjami fizycznymi. Wewnątrz jedna lub więcej partycji logicznych jest odwzorowana na jedną partycję fizyczną. Zazwyczaj mniejsze kontenery mają wiele partycji logicznych, ale wymagają tylko jednej partycji fizycznej. W przeciwieństwie do partycji logicznych partycje fizyczne są implementacją systemu wewnętrznego i Azure Cosmos DB w pełni nimi zarządza.
Liczba partycji fizycznych w kontenerze zależy od następujących cech:
Ilość aprowizowanej przepływności (każda pojedyncza fizyczna partycja może zapewnić przepływność do 10 000 jednostek żądań na sekundę). Limit 10 000 RU/s dla partycji fizycznych oznacza, że partycje logiczne mają również limit 10 000 RU/s, ponieważ każda partycja logiczna jest mapowana tylko na jedną partycję fizyczną.
Łączny magazyn danych (każda partycja fizyczna może przechowywać do 50 gigabajtów danych).
Uwaga / Notatka
Partycje fizyczne to wewnętrzna implementacja systemu, w pełni zarządzana przez Azure Cosmos DB. Podczas opracowywania rozwiązań nie skupiaj się na partycjach fizycznych, ponieważ nie można ich kontrolować. Zamiast tego skoncentruj się na kluczach partycji. Wybranie klucza partycji, który równomiernie rozdziela zużycie przepływności między partycjami logicznymi zapewnia zrównoważone użycie przepływności w partycjach fizycznych.
Nie ma limitu całkowitej liczby partycji fizycznych w kontenerze. W miarę wzrostu aprowizowanej przepływności lub rozmiaru danych usługa Azure Cosmos DB automatycznie tworzy nowe partycje fizyczne, dzieląc istniejące. Podziały partycji fizycznej nie wpływają na dostępność aplikacji. Po podzieleniu partycji fizycznej wszystkie dane w ramach jednej partycji logicznej będą nadal przechowywane na tej samej partycji fizycznej. Podział partycji fizycznej po prostu tworzy nowe mapowanie partycji logicznych na partycje fizyczne.
Aprowizowana przepływność dla kontenera dzieli się równomiernie między partycje fizyczne. Projekt klucza partycji, który nie dystrybuuje żądań równomiernie, może spowodować zbyt wiele żądań skierowanych do małego podzbioru partycji, które stają się "gorące". Gorące partycje powodują nieefektywne użycie aprowizowanej przepływności, co może spowodować ograniczenie szybkości i wyższe koszty.
Rozważmy na przykład kontener ze ścieżką /foodGroup określoną jako klucz partycji. Kontener może mieć dowolną liczbę partycji fizycznych, ale w tym przykładzie przyjęto założenie, że ma trzy partycje. Pojedyncza partycja fizyczna może zawierać wiele kluczy partycji. Na przykład największa partycja fizyczna może zawierać trzy najważniejsze partycje logiczne o największym rozmiarze: Beef Products, Vegetable and Vegetable Productsi Soups, Sauces, and Gravies.
W przypadku przypisania przepływności 18 000 jednostek żądań na sekundę (RU/s), każda z trzech partycji fizycznych używa jednej trzeciej całkowitej aprowizowanej przepływności. W ramach wybranej partycji fizycznej, klucze partycji logicznej Beef Products, Vegetable and Vegetable Products i Soups, Sauces, and Gravies mogą łącznie korzystać z 6000 jednostek RU/s aprowizowanych dla partycji fizycznej. Ponieważ aprowizowana przepływność jest równomiernie podzielona na partycje fizyczne kontenera, ważne jest, aby wybrać klucz partycji, który równomiernie rozdziela zużycie przepływności. Aby uzyskać więcej informacji, zobacz Wybieranie odpowiedniego klucza partycji logicznej.
Zarządzanie partycjami logicznymi
Azure Cosmos DB automatycznie zarządza umieszczaniem partycji logicznych na partycjach fizycznych w celu spełnienia wymagań dotyczących skalowalności i wydajności kontenera. Gdy wymagania dotyczące przepływności i magazynowania aplikacji wzrosną, Azure Cosmos DB przenosi partycje logiczne, aby rozłożyć obciążenie na więcej partycji fizycznych. Dowiedz się więcej o partycjach fizycznych.
Azure Cosmos DB używa partycjonowania opartego na skrótach do dystrybucji partycji logicznych między partycjami fizycznymi. Azure Cosmos DB haszuje wartość klucza partycji elementu. Wynik skrótu określa partycję logiczną. Następnie Azure Cosmos DB równomiernie przydziela przestrzeń dla skrótów klucza partycji między partycje fizyczne.
Transakcje w procedurach składowanych lub wyzwalaczach są dozwolone tylko dla elementów w jednej partycji logicznej.
Zestawy replik
Każda partycja fizyczna składa się z zestawu replik, nazywanych również zestawem replik. Każda replika hostuje instancję silnika bazy danych. Zestaw replik sprawia, że magazyn danych w partycji fizycznej jest trwały, wysoce dostępny i spójny. Każda replika w partycji fizycznej dziedziczy kwotę pamięci przypisaną do partycji. Wszystkie repliki partycji fizycznej łącznie obsługują przepływność przydzieloną do tej partycji fizycznej. Usługa Azure Cosmos DB automatycznie zarządza zestawami replik.
Mniejsze kontenery zwykle wymagają jednej partycji fizycznej, ale nadal mają co najmniej cztery repliki.
Na tym obrazie przedstawiono sposób mapowania partycji logicznych na partycje fizyczne dystrybuowane globalnie. Zestaw partycji na obrazie odnosi się do grupy partycji fizycznych, które zarządzają tymi samymi kluczami partycji logicznych w wielu regionach:
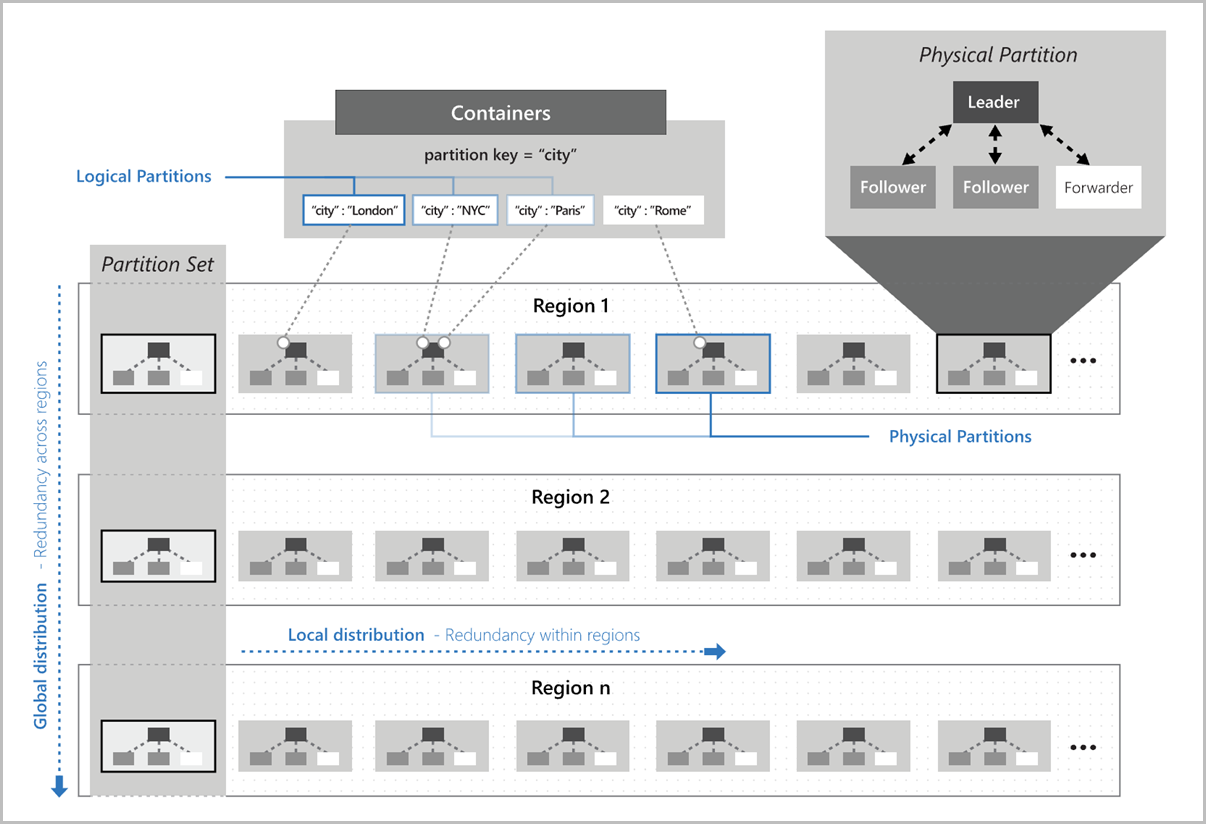
Wybieranie klucza partycji
Klucz partycji ma dwa składniki: ścieżkęklucza partycji i wartość klucza partycji. Rozważmy na przykład element { "userId" : "Andrew", "worksFor": "Microsoft" } , jeśli jako klucz partycji wybierzesz wartość "userId", oto dwa kluczowe składniki partycji:
Ścieżka klucza partycji (np. "/userId"). Ścieżka klucza partycji akceptuje znaki alfanumeryczne i podkreślenia (_). Można również używać obiektów zagnieżdżonych przy użyciu standardowej notacji ścieżki(/).
Wartość klucza partycji (na przykład: "Andrew"). Wartość klucza partycji może być typu ciągowego lub liczbowego.
Dowiedz się więcej o limitach przepustowości, przechowywania i długości klucza partycji w artykule kwoty usługi Azure Cosmos DB.
Wybór klucza partycji jest prostym, ale ważnym wyborem projektowym w usłudze Azure Cosmos DB. Po wybraniu klucza partycji nie można go zmienić. Jeśli musisz zmienić klucz partycji, przenieś dane do nowego kontenera przy użyciu odpowiedniego klucza partycji. Zadania kopiowania kontenerów pomagają w tym procesie. Alternatywnie można dodać globalne indeksy pomocnicze (wersja zapoznawcza), aby utworzyć kopie danych przy użyciu różnych kluczy partycji zoptymalizowanych pod kątem określonych wzorców zapytań.
W przypadku wszystkich kontenerów klucz partycji powinien:
Być właściwością, która ma wartość, która nie zmienia się. Jeśli właściwość jest kluczem partycji, nie można zaktualizować wartości tej właściwości.
Ważna
Wartości klucza partycji są niezmienne. Po utworzeniu elementu nie można zmienić jego wartości klucza partycji. Operacja zastępowania elementu wymaga, aby klucz partycji był zgodny z istniejącym elementem — nie można go użyć do przeniesienia elementu między partycjami. Aby "przenieść" element, musisz utworzyć nowy element z nową wartością klucza partycji i usunąć oryginalny element. Tych dwóch operacji nie można wykonać niepodziealnie w różnych partycjach logicznych.
Zawierać tylko
Stringwartości — lub konwertować liczby naString, jeśli mogą przekraczać zakres liczb o podwójnej precyzji zgodnie z Institute of Electrical and Electronics Engineers (IEEE) 754 binary64. Specyfikacja Json wyjaśnia, dlaczego używanie liczb poza tą granicą jest złą praktyką ze względu na problemy ze współdziałaniem. Te kwestie są szczególnie istotne dla kolumny klucza partycji, ponieważ jest ona niezmienna i wymaga migracji danych, aby później to zmienić.Ma wysoką kardynalność. Innymi słowy, właściwość powinna mieć szeroki zakres możliwych wartości.
Rozłóż równomiernie zużycie jednostek żądań (RU) i magazynowanie danych we wszystkich partycjach logicznych. Ten podział zapewnia równomierne zużycie RU i rozmieszczenie zasobów wśród twoich fizycznych partycji.
Mają wartości, które nie są zwykle większe niż 2048 bajtów lub 101 bajtów, jeśli duże klucze partycji nie są włączone. Aby uzyskać więcej informacji, zapoznaj się z obszernymi kluczami partycji
Jeśli potrzebujesz transakcji ACID dla wielu elementów w Azure Cosmos DB, musisz użyć przechowywanych procedur lub wyzwalaczy. Wszystkie procedury składowane i wyzwalacze oparte na języku JavaScript są ograniczone do jednej partycji logicznej.
Uwaga / Notatka
Jeśli masz tylko jedną partycję fizyczną lub liczba partycji jest mała, na przykład <= 5, wartość klucza partycji może nie być odpowiednia. W przypadku zapytań obciążenie związane z sprawdzaniem każdej dodatkowej partycji fizycznej, gdy klucz partycji nie jest uwzględniony, wynosi 2–3 RU na partycję fizyczną. Dowiedz się więcej o partycjach fizycznych.
Typy kluczy partycji
| Strategia partycjonowania | Kiedy stosować | Zalety | Wady |
|---|---|---|---|
| Zwykły klucz partycji (na przykład CustomerId, OrderId) | Użyj, kiedy klucz partycji cechuje się wysoką kardynalnością i jest zgodny z wzorcami zapytań (na przykład filtrowaniem według identyfikatora klienta). Odpowiednie dla obciążeń, w których zapytania są przeznaczone głównie dla danych pojedynczego klienta (na przykład pobieranie wszystkich zamówień dla klienta). | Łatwo zarządzać. Wydajne zapytania, gdy wzorzec dostępu jest zgodny z kluczem partycji (na przykład wykonywanie zapytań dotyczących wszystkich zamówień według identyfikatora CustomerId). Uniemożliwia wykonywanie zapytań między partycjami, jeśli wzorce dostępu są spójne. | Ryzyko gorących partycji, jeśli niektóre wartości (na przykład kilku klientów o dużym natężeniu ruchu) generują więcej danych niż inne. Jeśli wolumin danych dla określonego klucza szybko wzrośnie, może przekroczyć limit 20 GB na partycję logiczną. |
| Syntetyczny klucz partycji (na przykład CustomerId + OrderDate) | Należy użyć, gdy żadne pojedyncze pole nie ma zarówno wysokiej kardynalności, jak i pasuje do wzorców zapytań. Dobrze sprawdza się w przypadku obciążeń z intensywnymi zapisami, gdzie dane muszą być równomiernie rozłożone na partycje fizyczne (na przykład wiele zamówień złożonych tego samego dnia). | Pomaga równomiernie dystrybuować dane między partycjami, zmniejszając liczbę gorących partycji (na przykład dystrybucję zamówień według identyfikatorów CustomerId i OrderDate). Rozkłada zapisy w wielu partycjach i poprawia przepływność. | Zapytania filtrujące tylko według jednego pola (na przykład tylko CustomerId) mogą powodować zapytania obejmujące wiele partycji. Zapytania obejmujące wiele partycji mogą prowadzić do większego zużycia jednostek RU (2–3 RU/s dodatkowej opłaty za każdą partycję fizyczną, która istnieje) i dodatkowego opóźnienia. |
| Hierarchiczny klucz partycji (HPK) ( na przykład CustomerId/OrderId, StoreId/ProductId) | Używaj, gdy potrzebujesz partycjonowania wielopoziomowego, aby obsługiwać zestawy danych na dużą skalę. Idealne rozwiązanie w przypadku filtrowania zapytań na pierwszych i drugich poziomach hierarchii. | Pomaga uniknąć limitu 20 GB, tworząc wiele poziomów partycjonowania. Wydajne wykonywanie zapytań na obu poziomach hierarchicznych (na przykład filtrowanie najpierw według identyfikatora klienta, a następnie według identyfikatora zamówienia). Minimalizuje zapytania obejmujące wiele partycji dla zapytań przeznaczonych dla najwyższego poziomu (na przykład pobieranie wszystkich danych z określonego identyfikatora CustomerID). | Wymaga starannego planowania, aby upewnić się, że klucz pierwszego poziomu ma wysoką kardynalność i jest uwzględniony w większości zapytań. Zarządzanie jest bardziej złożone niż przy użyciu zwykłego klucza partycji. Jeśli zapytania nie są zgodne z hierarchią (na przykład filtrowanie tylko według identyfikatora OrderID, gdy CustomerID jest pierwszym poziomem), wydajność zapytań może ulec pogorszeniu. |
| Globalny indeks pomocniczy (GSI) — wersja zapoznawcza ( na przykład źródło używa identyfikatora CustomerId, GSI używa identyfikatora OrderId) | Użyj, gdy nie można znaleźć pojedynczego klucza partycji, który działa dla wszystkich wzorców zapytań. Idealne rozwiązanie w przypadku obciążeń wymagających wydajnego wykonywania zapytań o wiele niezależnych właściwości i dużej liczby partycji fizycznych. | Eliminuje zapytania między partycjami podczas korzystania z klucza partycji GSI. Zezwala na wiele wzorców zapytań na tych samych danych z automatyczną synchronizacją z kontenera źródłowego. Izolacja wydajności między obciążeniami. | Każdy GSI niesie ze sobą dodatkowe koszty magazynowania oraz koszty jednostek zapytania (RU). Dane w GSI są w końcu zgodne z kontenerem źródłowym. |
Klucze partycji dla kontenerów z dużym obciążeniem do odczytu
W przypadku większości kontenerów te kryteria należy wziąć pod uwagę podczas wybierania klucza partycji. W przypadku dużych kontenerów z dużym obciążeniem do odczytu warto jednak wybrać klucz partycji, który jest często wyświetlany jako filtr w zapytaniach. Uwzględnienie klucza partycji w predykacie filtru umożliwia wydajne kierowanie zapytań tylko do odpowiednich partycji fizycznych.
Ta właściwość jest dobrym wyborem klucza partycji, jeśli zapytania stanowią większość żądań związanych z Twoim obciążeniem, a w większości tych zapytań używany jest filtr równości dla tej samej właściwości. Jeśli na przykład często uruchamiasz zapytanie, które filtruje UserID, wybranie UserID jako klucza partycji spowoduje zmniejszenie liczby zapytań krzyżujących partycje.
Jeśli kontener jest mały, prawdopodobnie nie masz wystarczającej liczby partycji fizycznych, aby martwić się o wydajność zapytań obejmujących wiele partycji. Większość małych kontenerów w Azure Cosmos DB wymaga tylko jednej lub dwóch partycji fizycznych.
Jeśli kontener może wzrosnąć do więcej niż kilku partycji fizycznych, upewnij się, że wybrano klucz partycji, który minimalizuje zapytania obejmujące wiele partycji. Jeśli spełniony jest którykolwiek z następujących scenariuszy, twój kontener wymaga więcej niż parę partycji fizycznych:
Kontener ma ponad 30 000 jednostek żądań przydzielonych
Kontener przechowuje ponad 100 GB danych
Globalne indeksy pomocnicze dla zapytań obejmujących wiele partycji
Jeśli aplikacja musi wydajnie wykonywać zapytania dotyczące danych przy użyciu wielu różnych właściwości, globalne indeksy pomocnicze (wersja zapoznawcza) stanowią alternatywę dla jednej strategii klucza partycji dla zestawu danych. Globalne indeksy pomocnicze to dodatkowe kontenery z różnymi kluczami partycji, które są automatycznie synchronizowane z danymi z kontenera źródłowego.
Rozważ globalne indeksy pomocnicze, gdy:
- Istnieje wiele wzorców zapytań, których nie można spełnić za pomocą jednej strategii klucza partycji
- Zmiana istniejącego klucza partycji byłaby destrukcyjna
- Należy odizolować obciążenia analityczne lub wyszukiwania od operacji transakcyjnych
Globalne indeksy pomocnicze pomagają uniknąć zapytań obejmujących wiele partycji, przechowując te same dane przy użyciu różnych kluczy partycji zoptymalizowanych pod kątem określonych wzorców zapytań. Takie podejście może znacznie zmniejszyć użycie jednostek RU i zwiększyć wydajność zapytań w scenariuszach, w których sama optymalizacja klucza partycji nie jest wystarczająca.
Użyj identyfikatora elementu jako klucza partycji
Uwaga / Notatka
Ta sekcja dotyczy głównie interfejsu API dla baz danych NoSQL. Inne interfejsy API, takie jak interfejs API dla języka Gremlin, nie obsługują unikatowego identyfikatora jako klucza partycji.
Jeśli Twój kontener ma właściwość z dużym zakresem możliwych wartości, prawdopodobnie będzie to doskonały wybór na klucz partycji. Przykładem takiej właściwości jest identyfikator elementu. W przypadku małych kontenerów z dużym obciążeniem do odczytu lub kontenerów o dużym rozmiarze identyfikator elementu (/id) jest w naturalny sposób doskonałym wyborem dla klucza partycji.
Właściwość systemowa identyfikator elementu jest obecna w każdym elemencie w kontenerze. Mogą istnieć inne właściwości reprezentujące logiczny identyfikator elementu. W wielu przypadkach te unikatowe identyfikatory są również doskonałymi opcjami klucza partycji z tych samych powodów co identyfikator elementu.
Identyfikator elementu jest doskonałym wyborem na klucz partycji z następujących powodów:
- Istnieje szeroki zakres możliwych wartości (jeden unikatowy identyfikator elementu na element).
- Ponieważ istnieje unikatowy identyfikator dla każdego elementu, identyfikator elementu doskonale sprawdza się podczas równomiernego zrównoważenia użycia jednostek RU i magazynu danych.
- Efektywne odczyty punktów można łatwo wykonać, ponieważ zawsze znasz klucz partycji elementu, jeśli znasz jego identyfikator elementu.
Podczas wybierania identyfikatora elementu jako klucza partycji należy wziąć pod uwagę następujące zastrzeżenia:
- Jeśli identyfikator elementu jest kluczem partycji, staje się unikatowym identyfikatorem całego kontenera. Nie można tworzyć elementów z zduplikowanymi identyfikatorami.
- Jeśli masz kontener z dużym obciążeniem do odczytu z wieloma partycjami fizycznymi, zapytania są bardziej wydajne, jeśli mają filtr równości z identyfikatorem elementu.
- Procedury składowane lub wyzwalacze nie mogą być przeznaczone dla wielu partycji logicznych.