Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ciągłość działalności biznesowej i odzyskiwanie po awarii w Azure Data Explorer umożliwia firmie kontynuowanie działania w obliczu zakłóceń. W tym artykule szczegółowo przedstawiono wiele konfiguracji odzyskiwania po awarii w zależności od wymagań dotyczących możliwości odzyskiwania (RPO i RTO), wymaganych wysiłków i kosztów.
Aby uzyskać więcej informacji na temat opcji niezawodności dostępnych dla Azure Data Explorer, w tym obsługi dostępnej strefy dostępności, tworzenia kopii zapasowych i ochrony przed niektórymi typami błędów ludzkich, zobacz Reliability in Azure Data Explorer .
Konfiguracje odzyskiwania po awarii
Cel czasu odzyskiwania (RTO) odnosi się do czasu potrzebnego na odzyskanie po przerwie. Na przykład, RTO wynoszący 2 godziny oznacza, że aplikacja musi być uruchomiona w ciągu dwóch godzin od momentu wystąpienia zakłócenia. Cel punktu odzyskiwania (RPO) odnosi się do interwału czasu, który może upłynąć podczas zakłóceń, zanim ilość utraconych danych w tym okresie jest większa niż dozwolony próg. Jeśli na przykład cel punktu odzyskiwania wynosi 24 godziny, a aplikacja ma dane począwszy od 15 lat temu, nadal mieści się w parametrach uzgodnionego celu punktu odzyskiwania.
Procesy pozyskiwania, przetwarzania i zarządzania danymi wymagają starannego zaplanowania wcześniej, podczas planowania odzyskiwania po awarii. Pozyskiwanie odnosi się do danych zintegrowanych z Azure Data Explorer z różnych źródeł; przetwarzanie odnosi się do przekształceń i podobnych działań; curation odnosi się do zmaterializowanych widoków, eksportów do usługi Data Lake itd.
Poniżej przedstawiono popularne konfiguracje odzyskiwania po awarii:
- Konfiguracja Active-Active-Active (zawsze włączona)
- Konfiguracja Active-Active
- Konfiguracja rezerwy aktywnej na gorąco
- Konfiguracja klastra odzyskiwania danych na żądanie
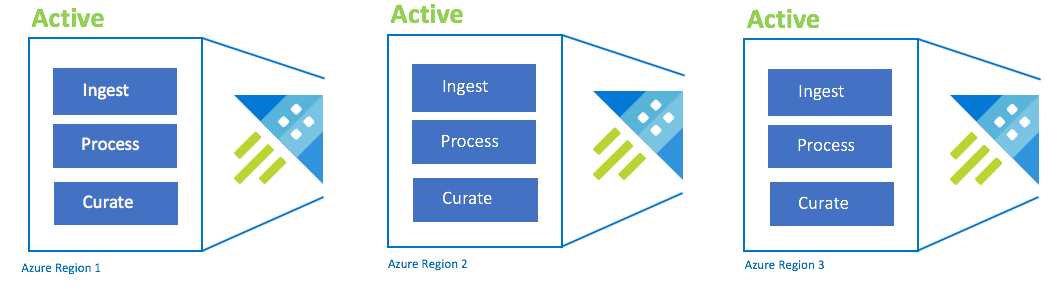
Konfiguracja aktywne-aktywne-aktywne
Ta konfiguracja jest również nazywana zawsze włączoną. W przypadku krytycznych wdrożeń aplikacji bez tolerancji dla awarii należy użyć wielu klastrów Azure Data Explorer w Azure sparowanych regionach. Skonfiguruj pozyskiwanie, przetwarzanie i kurację dla wszystkich klastrów równolegle. Jednostka SKU klastra musi być taka sama w różnych regionach. Azure zapewnia, że aktualizacje są wdrażane i rozłożone w sparowanych regionach Azure. Awaria regionu Azure nie powoduje awarii aplikacji. Może wystąpić pewne opóźnienie lub obniżenie wydajności.
| Konfiguracja | RPO | RTO | Wysiłek | Koszty |
|---|---|---|---|---|
| Active-Active-Active-n | 0 godzin | 0 godzin | Niższy | Najwyższa |
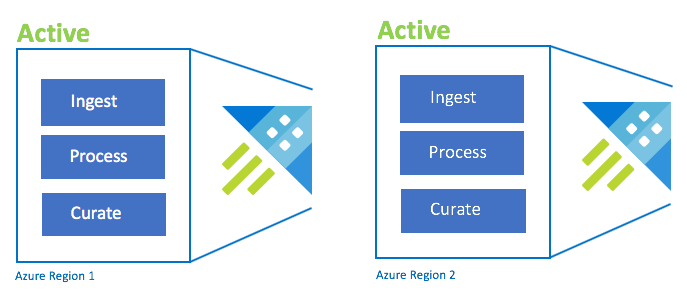
Konfiguracja Active-Active
Ta konfiguracja jest identyczna z konfiguracją active-active-active, ale obejmuje tylko dwa regiony sparowane w Azure. Skonfiguruj podwójne pozyskiwanie, przetwarzanie i kuratowanie. Użytkownicy są kierowani do najbliższego regionu. Jednostka SKU klastra musi być taka sama w różnych regionach.
| Konfiguracja | RPO | RTO | Wysiłek | Koszty |
|---|---|---|---|---|
| Aktywne-aktywne | 0 godzin | 0 godzin | Niższy | Wysoki |
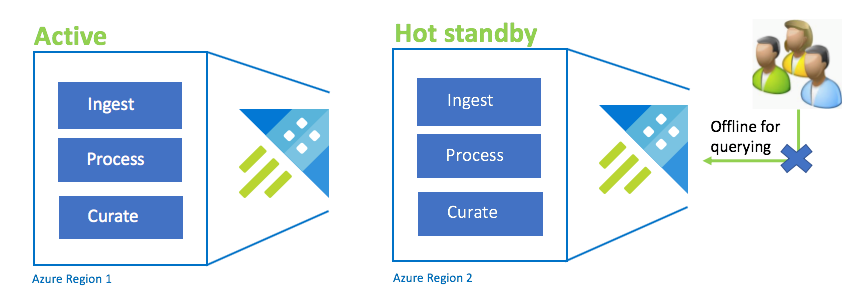
Konfiguracja rezerwy aktywnej na gorąco
Konfiguracja Active-Hot jest podobna do konfiguracji Active-Active w podwójnym pozyskiwaniu, przetwarzaniu i kuracji. Klaster rezerwowy jest w trybie online na potrzeby pozyskiwania, przetwarzania, i zarządzania danymi, ale nie jest dostępny do wykonywania zapytań. Klaster rezerwowy nie musi znajdować się w tej samej jednostce SKU co klaster podstawowy. Może to być mniejszy SKU i mniejsza skala, co może spowodować, że będzie mniej wydajny. W scenariuszu awarii użytkownicy są przekierowywani do klastra rezerwowego, co można opcjonalnie skalować w górę, aby zwiększyć wydajność.
| Konfiguracja | RPO | RTO | Wysiłek | Koszty |
|---|---|---|---|---|
| Rezerwa aktywna-gorąca | 0 godzin | Niski | Średni | Średni |
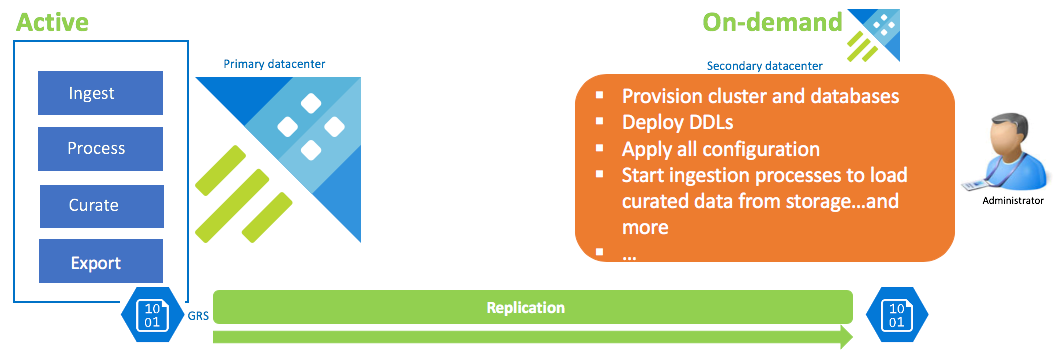
Konfiguracja odzyskiwania danych na żądanie
To rozwiązanie oferuje najmniejszą zdolność do odzyskiwania (najwyższy RPO i RTO), jest najtańsze kosztowo, ale wymaga największego nakładu pracy. W tej konfiguracji nie ma klastra odzyskiwania danych. Skonfiguruj ciągły eksport danych nadzorowanych (chyba że wymagane są również dane surowe i pośrednie) do konta przechowywania skonfigurowanego z użyciem magazynu GRS (Magazyn Geograficznie Nadmiarowy). Klaster odzyskiwania danych jest uruchamiany w przypadku scenariusza odzyskiwania po awarii. W tym momencie są stosowane języki definicji danych, konfiguracja, polityki i procesy. Dane są pobierane z magazynu z właściwością kustoCreationTime, aby zastąpić czas pobierania, który domyślnie odpowiada czasowi systemowemu.
| Konfiguracja | RPO | RTO | Wysiłek | Koszty |
|---|---|---|---|---|
| Klaster odzyskiwania danych na żądanie | Najwyższa | Najwyższa | Najwyższa | Najniższe |
Podsumowanie opcji konfiguracji odzyskiwania po awarii
| Konfiguracja | Odzyskanie | RPO | RTO | Wysiłek | Koszty |
|---|---|---|---|---|---|
| Active-Active-Active-n | Najwyższa | 0 godzin | 0 godzin | Niższy | Najwyższa |
| Aktywne-aktywne | Wysoki | 0 godzin | 0 godzin | Niższy | Wysoki |
| Rezerwa aktywna-gorąca | Średni | 0 godzin | Niski | Średni | Średni |
| Klaster odzyskiwania danych na żądanie | Najniższe | Najwyższa | Najwyższa | Najwyższa | Najniższe |
Najlepsze rozwiązania
Niezależnie od wybranej konfiguracji odzyskiwania po awarii, wykonaj następujące najlepsze praktyki:
- Wszystkie obiekty, zasady i konfiguracje bazy danych powinny być przechowywane w systemie kontroli wersji, aby można je było zwolnić do klastra za pomocą narzędzia do automatyzacji wydań. Aby uzyskać więcej informacji, zobacz obsługę Azure DevOps dla Azure Data Explorer.
- Projektowanie, opracowywanie i implementowanie procedur walidacji w celu zapewnienia synchronizacji wszystkich klastrów z perspektywy danych. Azure Data Explorer obsługuje łączenia między klastrami. Prosta liczba lub wiersze między tabelami mogą pomóc w zweryfikowaniu.
- Procedury wydania powinny obejmować mechanizmy nadzoru i równowagi, które zapewniają odzwierciedlenie klastrów.
- Bądź w pełni świadomy tego, co potrzeba do utworzenia klastra od podstaw.
- Utwórz listę kontrolną jednostek wdrażania. Twoja lista jest unikatowa dla Twoich potrzeb, ale powinna zawierać: skrypty wdrażania, połączenia do pobierania danych, narzędzia analiz biznesowych i inne ważne konfiguracje.