operator podsumowania
Tworzy tabelę, która agreguje zawartość tabeli wejściowej.
Składnia
T | summarize [ SummarizeParameters ] [[Kolumna =] Agregacja [, ...]] [by [Kolumna =] GroupExpression [, ...]]
Dowiedz się więcej na temat konwencji składni.
Parametry
| Nazwisko | Type | Wymagania | opis |
|---|---|---|---|
| Kolumna | string |
Nazwa kolumny wyników. Domyślnie nazwa pochodzi z wyrażenia . | |
| Agregacja | string |
✔️ | Wywołanie funkcji agregacji, takiej jak count() lub avg(), z nazwami kolumn jako argumentami. |
| GroupExpression | skalar | ✔️ | Wyrażenie skalarne, które może odwoływać się do danych wejściowych. Dane wyjściowe będą miały tyle rekordów, ile jest unikatowych wartości wszystkich wyrażeń grupy. |
| SummarizeParameters | string |
Zero lub więcej parametrów rozdzielonych spacjami w postaci wartości nazwy = , która kontroluje zachowanie. Zobacz obsługiwane parametry. |
Uwaga
Gdy tabela wejściowa jest pusta, dane wyjściowe zależą od tego, czy jest używana funkcja GroupExpression :
- Jeśli parametr GroupExpression nie zostanie podany, dane wyjściowe będą pojedynczym (pustym) wierszem.
- Jeśli zostanie podana wartość GroupExpression , dane wyjściowe nie będą miały wierszy.
Obsługiwane parametry
| Nazwa/nazwisko | opis |
|---|---|
hint.num_partitions |
Określa liczbę partycji używanych do współużytkowania obciążenia zapytania w węzłach klastra. Zobacz zapytanie mieszania |
hint.shufflekey=<key> |
Zapytanie shufflekey współudzieli obciążenie zapytania w węzłach klastra przy użyciu klucza do partycjonowania danych. Zobacz zapytanie mieszania |
hint.strategy=shuffle |
shuffle Zapytanie strategii współudzieli obciążenie zapytania w węzłach klastra, w których każdy węzeł będzie przetwarzać jedną partycję danych. Zobacz zapytanie mieszania |
Zwraca
Wiersze wejściowe są rozmieszczane w grupach o tych samych wartościach by wyrażeń. Następnie określone funkcje agregacji są obliczane dla każdej grupy, tworząc wiersz dla każdej grupy. Wynik zawiera by kolumny, a także co najmniej jedną kolumnę dla każdej obliczonej agregacji. (Niektóre funkcje agregacji zwracają wiele kolumn).
Wynik zawiera tyle wierszy, ile istnieje różnych kombinacji by wartości (które mogą być zerowe). Jeśli nie podano kluczy grupy, wynik ma jeden rekord.
Aby podsumować zakresy wartości liczbowych, użyj polecenia bin() , aby zmniejszyć zakresy do wartości dyskretnych.
Uwaga
- Mimo że można podać dowolne wyrażenia zarówno dla wyrażeń agregacji, jak i grupowania, bardziej wydajne jest użycie prostych nazw kolumn lub zastosowanie
bin()do kolumny liczbowej. - Automatyczne przedziały godzinowe dla kolumn daty/godziny nie są już obsługiwane. Zamiast tego użyj jawnego kwantowania. Na przykład
summarize by bin(timestamp, 1h).
Domyślne wartości agregacji
Poniższa tabela zawiera podsumowanie wartości domyślnych agregacji:
| Operator | Domyślna wartość |
|---|---|
count(), countif(), , , count_distinct()variance()stdev()dcountif()sum()sumif()varianceif()dcount()stdevif() |
0 |
make_bag(), , make_bag_if(), make_list(), make_list_if(), , make_set()make_set_if() |
pusta tablica dynamiczna ([]) |
| Wszystkie inne | null |
Uwaga
Podczas stosowania tych agregacji do jednostek, które zawierają wartości null, wartości null są ignorowane i nie są uwzględniane w obliczeniach. Aby zapoznać się z przykładami, zobacz Agregowanie wartości domyślnych.
Przykłady
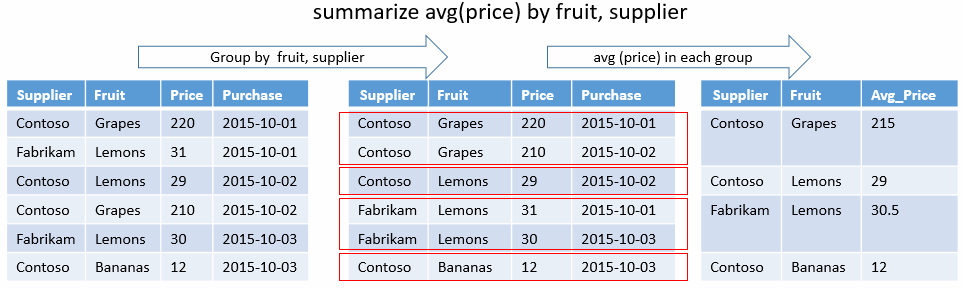
Unikatowa kombinacja
Poniższe zapytanie określa, jakie unikatowe kombinacje State i EventType istnieją dla burz, które spowodowały bezpośrednie szkody. Brak funkcji agregacji— po prostu grupowanie według kluczy. W danych wyjściowych zostaną wyświetlone tylko kolumny dla tych wyników.
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
Wyjście
W poniższej tabeli przedstawiono tylko pierwsze 5 wierszy. Aby wyświetlić pełne dane wyjściowe, uruchom zapytanie.
| Stan | EventType |
|---|---|
| TEKSAS | Wiatr i burza |
| TEKSAS | Powodzia błyskawiczna |
| TEKSAS | Zimowa pogoda |
| TEKSAS | Silny wiatr |
| TEKSAS | Powódź |
| ... | ... |
Minimalny i maksymalny znacznik czasu
Znajduje minimalne i maksymalne ulewne burze deszczu na Hawajach. Nie ma klauzuli group-by, więc w danych wyjściowych znajduje się tylko jeden wiersz.
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
Wyjście
| Min | Max |
|---|---|
| 01:08:00 | 11:55:00 |
Zliczenie
Utwórz wiersz dla każdego kontynentu z liczbą miast, w których występują działania. Ponieważ istnieje kilka wartości dla "kontynentu", w klauzuli "by" nie jest wymagana żadna funkcja grupowania:
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
Wyjście
W poniższej tabeli przedstawiono tylko pierwsze 5 wierszy. Aby wyświetlić pełne dane wyjściowe, uruchom zapytanie.
| Stan | TypesOfStorms |
|---|---|
| TEKSAS | 27 |
| KALIFORNIA | 26 |
| PENNSYLVANIA | 25 |
| GEORGIA | 24 |
| ILLINOIS | 23 |
| ... | ... |
Histogram
Poniższy przykład oblicza typy zdarzeń burzy histogramu, które miały burze trwające dłużej niż 1 dzień. Ponieważ Duration ma wiele wartości, użyj polecenia bin() , aby pogrupować swoje wartości w interwały 1-dniowe.
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
Wyjście
| EventType | Długość | EventCount |
|---|---|---|
| Susza | 30.00:00:00 | 1646 |
| Pożary lasów | 30.00:00:00 | 11 |
| Ciepło | 30.00:00:00 | 14 |
| Powódź | 30.00:00:00 | 20 |
| Ulewny deszcz | 29.00:00:00 | 42 |
| ... | ... | ... |
Agreguje wartości domyślne
Jeśli dane wejściowe summarize operatora mają co najmniej jeden pusty klucz grupowania według, jego wynik jest również pusty.
Jeśli dane wejściowe summarize operatora nie mają pustego klucza grupowania, wynikiem są wartości domyślne agregacji używanych w sekcji summarize Aby uzyskać więcej informacji, zobacz Domyślne wartości agregacji.
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
Wyjście
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | max_x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NaN | 0 | 0 | 0 | 0 |
Wynik jest avg_x(x) NaN spowodowany podziałem przez 0.
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
Wyjście
| count_x | countif_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
Wyjście
| set_x | list_x |
|---|---|
| [] | [] |
Zagregowana średnia sumuje wszystkie wartości inne niż null i zlicza tylko te, które uczestniczyły w obliczeniach (nie uwzględniają wartości null).
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
Wyjście
| sum_y | avg_y |
|---|---|
| 15 | 5 |
Liczba regularna będzie zliczać wartości null:
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
Wyjście
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
Wyjście
| set_y | set_y1 |
|---|---|
| [5.0] | [5.0] |
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla