Zarządzanie skalowaniem w poziomie klastra (skalowanie w poziomie) w usłudze Azure Data Explorer w celu dostosowania się do zmieniających się wymagań
Odpowiednie określanie rozmiaru klastra ma kluczowe znaczenie dla wydajności usługi Azure Data Explorer. Rozmiar klastra statycznego może prowadzić do niedostatecznego lub nadmiernego wykorzystania, z których żaden nie jest idealny. Ponieważ zapotrzebowanie na klaster nie może być przewidywane z bezwzględną dokładnością, lepiej jest skalować klaster, dodając i usuwając pojemność i zasoby procesora CPU ze zmieniającym się zapotrzebowaniem.
Istnieją dwa przepływy pracy służące do skalowania klastra usługi Azure Data Explorer:
- Skalowanie w poziomie, nazywane również skalowaniem w poziomie i w poziomie.
- Skalowanie w pionie, nazywane również skalowaniem w górę i w dół. W tym artykule opisano przepływ pracy skalowania w poziomie.
Konfigurowanie skalowania w poziomie
Korzystając ze skalowania w poziomie, można automatycznie skalować liczbę wystąpień na podstawie wstępnie zdefiniowanych reguł i harmonogramów. Aby określić ustawienia autoskalowania dla klastra:
W Azure Portal przejdź do zasobu klastra usługi Azure Data Explorer. W obszarze Ustawienia wybierz pozycję Skaluj w poziomie.
W oknie Skalowanie w poziomie wybierz odpowiednią metodę autoskalowania: Skalowanie ręczne, Zoptymalizowane autoskalowanie lub Autoskalowanie niestandardowe.
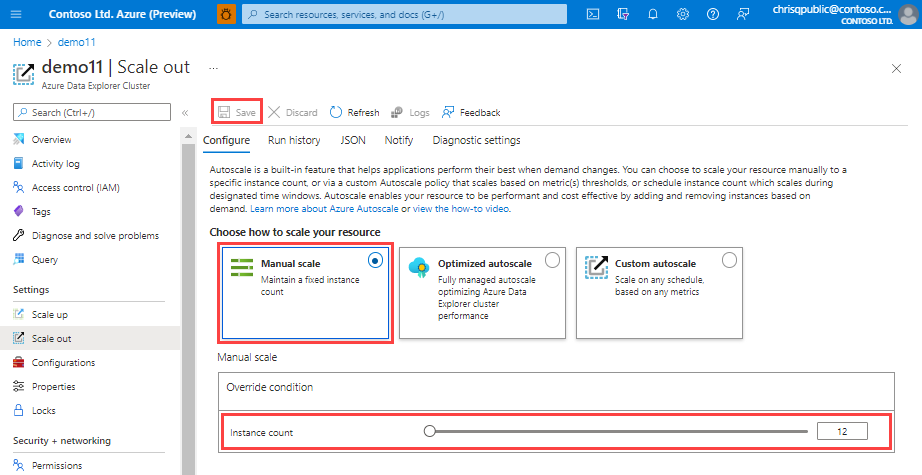
Skalowanie ręczne
W opcji skalowania ręcznego klaster ma pojemność statyczną, która nie zmienia się automatycznie. Wybierz pojemność statyczną przy użyciu paska liczba wystąpień . Skalowanie klastra pozostaje w wybranym ustawieniu do momentu zmiany.
Zoptymalizowane autoskalowanie (zalecana opcja)
Zoptymalizowane autoskalowanie jest ustawieniem domyślnym podczas tworzenia klastra i zalecaną metodą skalowania. Ta metoda optymalizuje wydajność i koszty klastra w następujący sposób:
- Jeśli klaster jest niedostatecznie wykorzystany, jest skalowany w poziomie w celu obniżenia kosztów bez wpływu na wymaganą wydajność.
- Jeśli klaster jest nadmiernie wykorzystany, jest skalowany w poziomie w celu zachowania optymalnej wydajności.
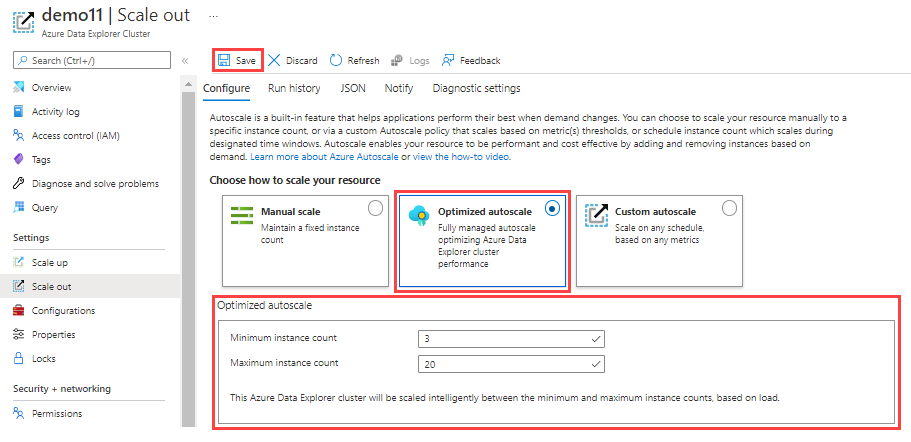
Aby skonfigurować zoptymalizowane autoskalowanie:
Wybierz pozycję Zoptymalizowane autoskalowanie.
Określ minimalną i maksymalną liczbę wystąpień. Skalowanie automatyczne klastra obejmuje zakresy między tymi wartościami na podstawie obciążenia.
Wybierz pozycję Zapisz.
Zoptymalizowane autoskalowanie zaczyna działać. Jego akcje można wyświetlić w dzienniku aktywności klastra na platformie Azure.
Logika zoptymalizowanego skalowania automatycznego
Zoptymalizowane autoskalowanie jest zarządzane przez logikę predykcyjną lub reaktywną. Logika predykcyjna śledzi wzorzec użycia klastra, a gdy identyfikuje sezonowość z dużą pewnością, zarządza skalowaniem klastra. W przeciwnym razie reaktywna logika, która śledzi rzeczywiste użycie klastra, służy do podejmowania decyzji dotyczących operacji skalowania klastra na podstawie bieżącego poziomu użycia zasobów.
Główne metryki dla przepływów predykcyjnych i reaktywnych to:
- Procesor CPU
- Współczynnik wykorzystania pamięci podręcznej
- Wykorzystanie pozyskiwania
Zarówno logika predykcyjna, jak i reaktywna są powiązane z granicami rozmiaru klastra, minimalną i maksymalną liczbą wystąpień zgodnie z definicją w zoptymalizowanej konfiguracji skalowania automatycznego. Częste skalowanie klastra w poziomie i skalowanie w operacjach jest niepożądane ze względu na wpływ na zasoby klastra i wymagany czas na dodawanie lub usuwanie wystąpień, a także ponowne równoważenie gorącej pamięci podręcznej we wszystkich węzłach.
Autoskaluj predykcyjne
Logika predykcyjna prognozuje użycie klastra następnego dnia na podstawie wzorca użycia w ciągu ostatnich kilku tygodni. Prognoza służy do tworzenia harmonogramu operacji skalowania w poziomie lub skalowania w poziomie w celu dostosowania rozmiaru klastra przed upływem czasu. Dzięki temu skalowanie klastra i ponowne równoważenie danych można ukończyć w czasie, gdy obciążenie się zmieni. Ta logika jest szczególnie skuteczna w przypadku wzorców sezonowych, takich jak dzienny lub tygodniowy wzrost użycia.
Jednak w scenariuszach, w których występuje unikatowy wzrost użycia, który przekracza prognozę, zoptymalizowane autoskalowanie powróci do logiki reaktywnej. W takim przypadku operacje skalowania wpoziomie lub skalowania w poziomie są wykonywane ad hoc na podstawie najnowszego poziomu użycia zasobów.
Reaktywne autoskalu
Skalowanie w poziomie
Gdy klaster zbliża się do stanu nadmiernego wykorzystania, operacja skalowania w poziomie zostanie przeprowadzona w celu utrzymania optymalnej wydajności. Operacja skalowania w poziomie jest wykonywana, gdy wystąpi co najmniej jeden z następujących warunków:
- Wykorzystanie pamięci podręcznej jest wysokie przez ponad godzinę
- Procesor CPU jest wysoki przez ponad godzinę
- Wykorzystanie pozyskiwania danych jest duże przez ponad godzinę.
Skalowanie w pionie
Gdy klaster jest niedostatecznie wykorzystany, skalowanie w operacji będzie odbywać się w celu obniżenia kosztów przy zachowaniu optymalnej wydajności. Wiele metryk służy do sprawdzania, czy można bezpiecznie skalować w klastrze.
Aby upewnić się, że nie ma przeciążenia zasobów, przed wykonaniem skalowania są oceniane następujące metryki:
- Wykorzystanie pamięci podręcznej nie jest duże.
- Wykorzystanie procesora jest poniżej średniej.
- Wykorzystanie pozyskiwania danych jest poniżej średniej.
- Jeśli jest używane pozyskiwanie strumieniowe, wykorzystanie pozyskiwania strumieniowego nie jest wysokie
- Zachowaj żywą metrykę przekracza zdefiniowaną minimalną, przetworzoną prawidłowo i na czas wskazującą, że klaster odpowiada
- Brak ograniczania zapytań
- Liczba zakończonych niepowodzeniem zapytań jest niższa niż zdefiniowana minimalna
Uwaga
Skala w logice wymaga 1-dniowej oceny przed wdrożeniem zoptymalizowanej skali. Ta ocena odbywa się co godzinę. Jeśli wymagana jest natychmiastowa zmiana, użyj skalowania ręcznego.
Autoskaluj niestandardowe
Chociaż zoptymalizowane autoskalowanie jest zalecaną opcją skalowania, niestandardowe autoskalowanie platformy Azure jest również obsługiwane. Korzystając z niestandardowego autoskalowania, można dynamicznie skalować klaster na podstawie podanych metryk. Wykonaj poniższe kroki, aby skonfigurować niestandardowe autoskalowania.
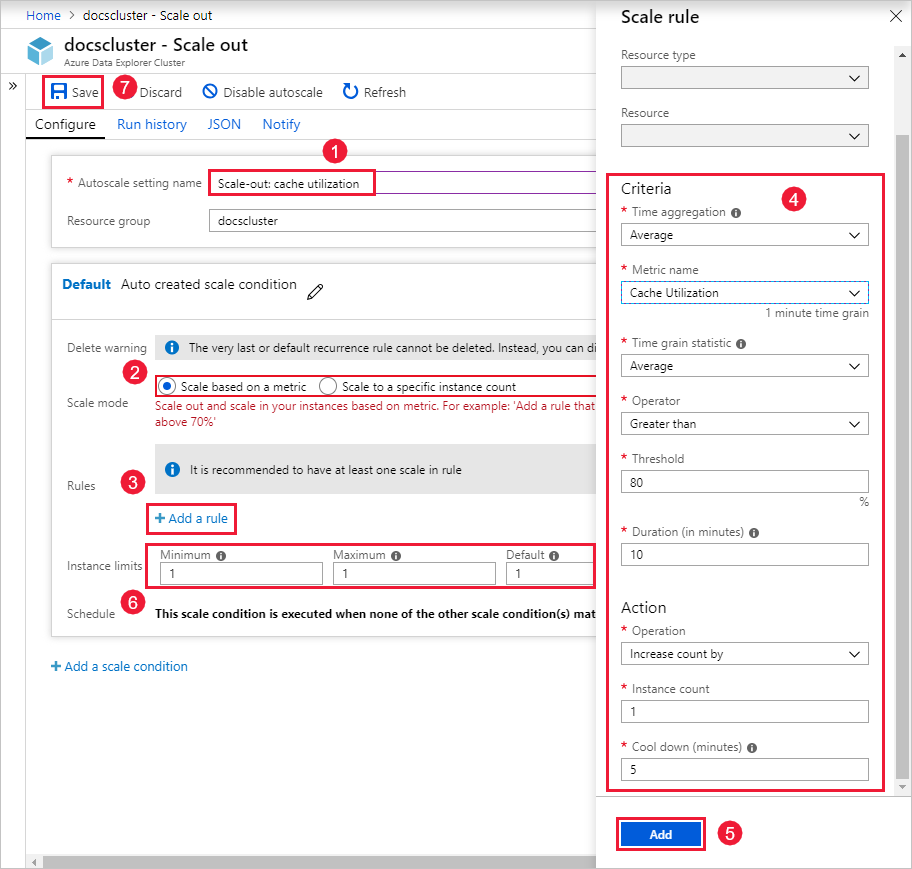
W polu Nazwa ustawienia Autoskalowanie wprowadź nazwę, taką jak Skalowanie w poziomie: wykorzystanie pamięci podręcznej.
W obszarze Tryb skalowania wybierz pozycję Skaluj na podstawie metryki. Ten tryb zapewnia dynamiczne skalowanie. Możesz również wybrać pozycję Skaluj do określonej liczby wystąpień.
Wybierz pozycję + Dodaj regułę.
W sekcji Reguła skalowania po prawej stronie wprowadź wartości dla każdego ustawienia.
Kryteria
Ustawienie Opis i wartość Agregacja czasu Wybierz kryteria agregacji, takie jak Średnia. Nazwa metryki Wybierz metryki, na której ma być oparta operacja skalowania, na przykład Wykorzystanie pamięci podręcznej. Statystyka ziarna czasu Wybierz jedną z opcji Średnia, Minimalna, Maksymalna i Suma. Operator Wybierz odpowiednią opcję, taką jak Większe niż lub równe. Próg Wybierz odpowiednią wartość. Na przykład w przypadku wykorzystania pamięci podręcznej 80 procent jest dobrym punktem wyjścia. Czas trwania (w minutach) Wybierz odpowiednią ilość czasu dla systemu, aby spojrzeć wstecz podczas obliczania metryk. Rozpocznij od wartości domyślnej 10 minut. Akcja
Ustawienie Opis i wartość Operacja Wybierz odpowiednią opcję skalowania w poziomie lub skalowania w poziomie. Liczba wystąpień Wybierz liczbę węzłów lub wystąpień, które chcesz dodać lub usunąć po spełnieniu warunku metryki. Czas schładzania (minuty) Wybierz odpowiedni interwał czasu oczekiwania między operacjami skalowania. Rozpocznij od wartości domyślnej pięciu minut. Wybierz pozycję Dodaj.
W sekcji Limity wystąpień po lewej stronie wprowadź wartości dla każdego ustawienia.
Ustawienie Opis i wartość Minimalne Liczba wystąpień, których klaster nie będzie skalować poniżej, niezależnie od użycia. Maksimum Liczba wystąpień, których klaster nie będzie skalować powyżej, niezależnie od użycia. Default Domyślna liczba wystąpień. To ustawienie jest używane, jeśli występują problemy z odczytywaniem metryk zasobów. Wybierz pozycję Zapisz.
Skonfigurowano skalowanie w poziomie dla klastra usługi Azure Data Explorer. Dodaj kolejną regułę skalowania w pionie. Jeśli potrzebujesz pomocy dotyczącej problemów ze skalowaniem klastra, otwórz wniosek o pomoc techniczną w Azure Portal.
Zawartość pokrewna
- Monitorowanie wydajności, kondycji i użycia platformy Azure Data Explorer za pomocą metryk
- Zarządzanie skalowaniem w pionie klastra w celu odpowiedniego określania rozmiaru klastra.