Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Omówienie
Azure Data Factory i tryb debugowania przepływu mapowania danych usługi Synapse Analytics umożliwia interaktywne obserwowanie transformacji kształtu danych podczas kompilowania i debugowania przepływów danych. Sesja debugowania może być używana zarówno w sesjach projektowania przepływów danych, jak i podczas debugowania wykonywanego w potoku przepływów danych. Aby włączyć tryb debugowania, użyj przycisku Data Flow Debug na górnym pasku kanwy przepływu danych lub kanwie potoku, gdy masz zadania związane z przepływem danych.

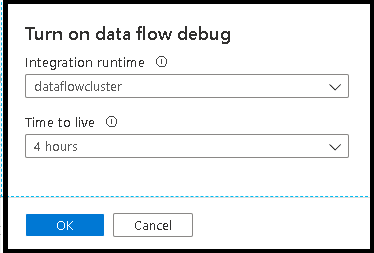
Po włączeniu suwaka zostanie wyświetlony monit o wybranie konfiguracji środowiska Integration Runtime, której chcesz użyć. Jeśli zostanie wybrana opcja AutoResolveIntegrationRuntime, klaster z ośmioma rdzeniami ogólnych obliczeń z domyślnym czasem życia wynoszącym 60 minut zostanie uruchomiony. Jeśli chcesz pozwolić na dłuższy okres bezczynności przed zakończeniem sesji, możesz wybrać wyższe ustawienie czasu wygaśnięcia sesji. Aby uzyskać więcej informacji na temat środowisk uruchomienia integracji przepływu danych, zobacz wydajność środowisk uruchomienia integracji.
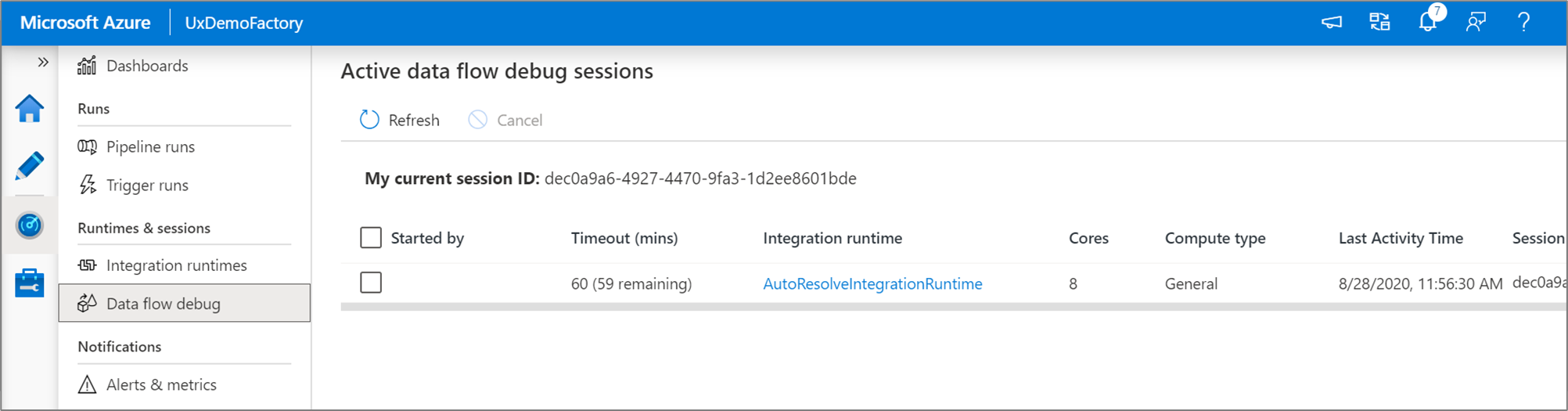
Gdy tryb debugowania jest włączony, możesz interaktywnie skompilować przepływ danych za pomocą aktywnego klastra Spark. Sesja zostanie zamknięta po wyłączeniu debugowania. Należy pamiętać o opłatach godzinowych naliczanych przez usługę Data Factory w czasie włączenia sesji debugowania.
W większości przypadków dobrą praktyką jest utworzenie Przepływów danych w trybie debugowania, dzięki czemu można zweryfikować logikę biznesową i wyświetlić przekształcenia danych przed opublikowaniem Twojej pracy. Użyj przycisku "Debug" na panelu rurociągu, aby przetestować przepływ danych w rurociągu.
Uwaga
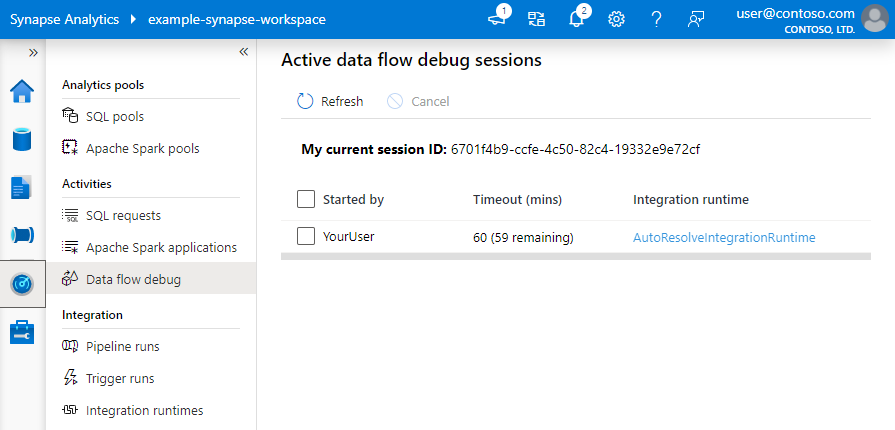
Każda sesja debugowania, którą użytkownik uruchamia za pośrednictwem interfejsu użytkownika przeglądarki, to nowa sesja z własnym klastrem Spark. Możesz użyć widoku monitorowania dla sesji debugowania pokazanych na poprzednich obrazach, aby wyświetlić sesje debugowania i zarządzać nimi. Opłaty są naliczane za każdą godzinę wykonywania każdej sesji debugowania, w tym czas życia (TTL).
W tym klipie wideo omówiono porady, wskazówki i dobre rozwiązania dotyczące trybu debugowania przepływu danych.
Stan klastra
Wskaźnik stanu klastra w górnej części powierzchni projektowej zmieni kolor na zielony, gdy klaster jest gotowy do debugowania. Jeśli klaster jest już ciepły, wskaźnik zielony pojawia się niemal natychmiast. Jeśli klaster nie był jeszcze uruchomiony podczas wprowadzania trybu debugowania, klaster Spark wykonuje zimny rozruch. Wskaźnik obraca się do momentu, aż środowisko będzie gotowe do interaktywnego debugowania.
Po zakończeniu debugowania wyłącz wyłączenie debugowania, aby klaster Spark mógł zakończyć działanie i nie będą już naliczane opłaty za działanie debugowania.
Ustawienia debugowania
Po włączeniu trybu debugowania możesz edytować sposób wyświetlania podglądu danych przez przepływ danych. Ustawienia debugowania można edytować, klikając pozycję "Ustawienia debugowania" na pasku narzędzi kanwy Data Flow. W tym miejscu możesz wybrać limit wierszy lub źródło plików, które ma być używane dla każdego przekształcenia źródła. Limity wierszy w tym ustawieniu dotyczą tylko bieżącej sesji debugowania. Możesz również wybrać tymczasową połączoną usługę, która ma być używana dla źródła Azure Synapse Analytics.
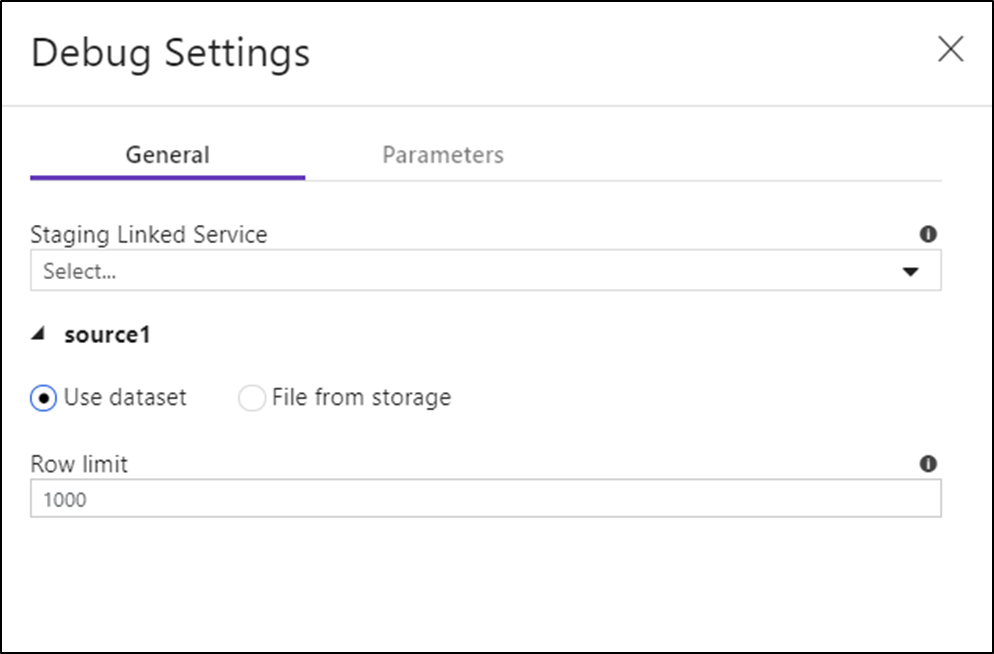
Jeśli masz parametry w Data Flow lub dowolnym z odwołanych zestawów danych, możesz określić, jakie wartości mają być używane podczas debugowania, wybierając kartę Parameters.
Użyj tutaj ustawień próbkowania, aby wskazać przykładowe pliki lub przykładowe tabele danych, aby nie trzeba było zmieniać źródłowych zestawów danych. Korzystając z przykładowego pliku lub tabeli w tym miejscu, można zachować te same ustawienia logiki i właściwości w przepływie danych podczas testowania podzestawu danych.
Domyślnym środowiskiem IR używanym do trybu debugowania w przepływach danych jest mały 4-rdzeniowy pojedynczy węzeł roboczy z 4-rdzeniowym węzłem sterownika. Działa to dobrze w przypadku mniejszych próbek danych podczas testowania logiki przepływu danych. Jeśli rozszerzysz limity wierszy w ustawieniach debugowania podczas podglądu danych lub ustawisz większą liczbę przykładowych wierszy w źródle podczas debugowania potoku, warto rozważyć ustawienie większego środowiska obliczeniowego w nowym Azure Integration Runtime. Następnie możesz ponownie uruchomić sesję debugowania przy użyciu większego środowiska obliczeniowego.
Podgląd danych
Gdy debugowanie jest włączone, karta Podgląd danych w dolnym panelu rozświetla się. Gdy tryb debugowania nie jest włączony, Data Flow pokazuje jedynie bieżące metadane wejściowe i wyjściowe każdej transformacji w zakładce Inspekcja. Podgląd danych będzie zapytuje tylko o liczbę wierszy, którą ustawiłeś jako limit w ustawieniach debugowania. Wybierz pozycję Odśwież , aby zaktualizować podgląd danych na podstawie bieżących przekształceń. Jeśli dane źródłowe uległy zmianie, wybierz pozycję Odśwież > Pobierz ponownie ze źródła.
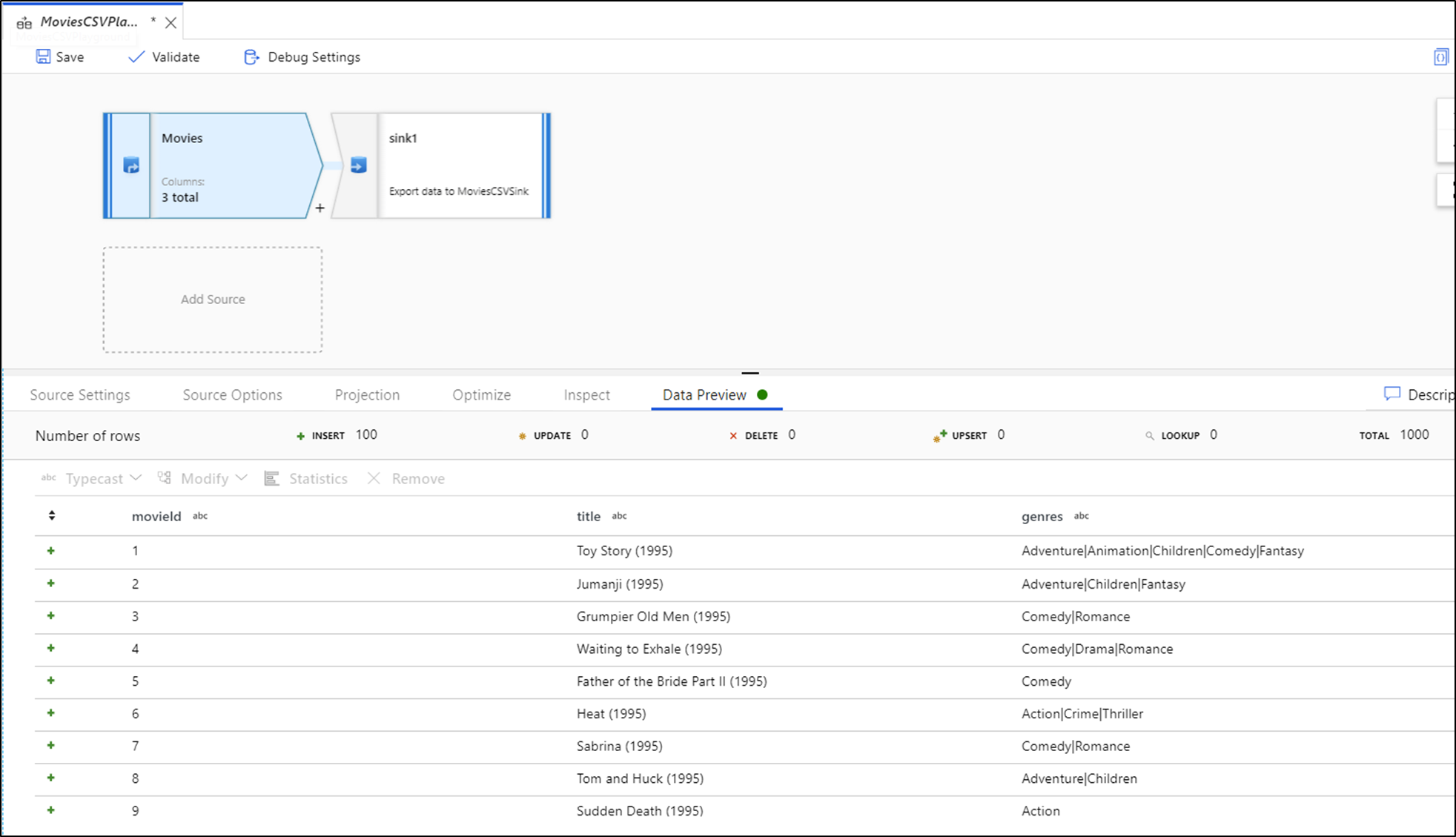
Kolumny można sortować w podglądzie danych i rozmieszczać kolumny przy użyciu przeciągania i upuszczania. Ponadto w górnej części panelu podglądu danych znajduje się przycisk eksportu, którego można użyć do wyeksportowania danych podglądu do pliku CSV na potrzeby eksploracji danych w trybie offline. Ta funkcja umożliwia eksportowanie do 1000 wierszy danych podglądu.
Uwaga
Źródła plików ograniczają tylko wyświetlane wiersze, a nie odczytywane wiersze. W przypadku bardzo dużych zestawów danych zaleca się wykonanie niewielkiej części tego pliku i użycie go do testowania. Możesz wybrać plik tymczasowy w obszarze Ustawienia debugowania dla każdego źródła, które jest typem zestawu danych pliku.
Podczas uruchamiania Data Flow w trybie debugowania dane nie będą zapisywane w przekształceniu ujścia. Sesja debugowania ma służyć jako środowisko testowe dla przekształceń. Ujścia nie są wymagane podczas debugowania i są ignorowane w przepływie danych. Jeśli chcesz przetestować zapisywanie danych w odbiorniku, wykonaj przepływ danych z potoku i użyj funkcji debugowania z poziomu potoku.
Podgląd danych to migawka przekształconych danych z wykorzystaniem limitów wierszy i próbkowania danych z ramek danych w pamięci Spark. W związku z tym sterowniki ujścia nie są używane ani testowane w tym scenariuszu.
Uwaga
Podgląd danych wyświetla czas zgodnie z ustawieniami regionalnymi przeglądarki.
Testowanie warunków sprzężenia
Podczas testowania jednostkowego łączeń, istnień lub transformacji wyszukiwania, upewnij się, że używasz małego zestawu znanych danych do testu. Możesz użyć opisanej wcześniej opcji Ustawienia debugowania, aby ustawić plik tymczasowy do użycia na potrzeby testowania. Jest to konieczne, ponieważ w przypadku ograniczania lub próbkowania wierszy z dużego zestawu danych nie można przewidzieć, które wiersze i które klucze są odczytywane do przepływu na potrzeby testowania. Wynik jest niedeterministyczny, co oznacza, że warunki łączenia mogą być niespełnione.
Szybkie akcje
Po wyświetleniu podglądu danych możesz wygenerować szybką transformację w celu rzutowania, usuwania lub modyfikowania kolumny. Wybierz nagłówek kolumny, a następnie wybierz jedną z opcji na pasku narzędzi podglądu danych.
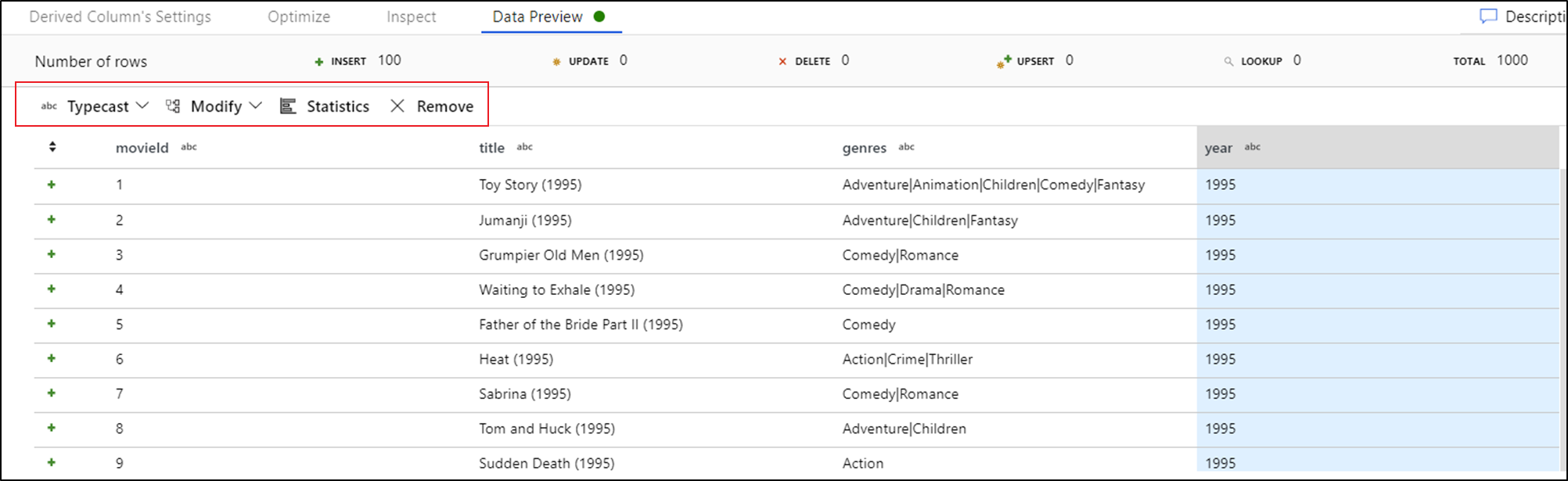
Po wybraniu modyfikacji podgląd danych zostanie natychmiast odświeżyny. Wybierz pozycję Potwierdź w prawym górnym rogu, aby wygenerować nową transformację.
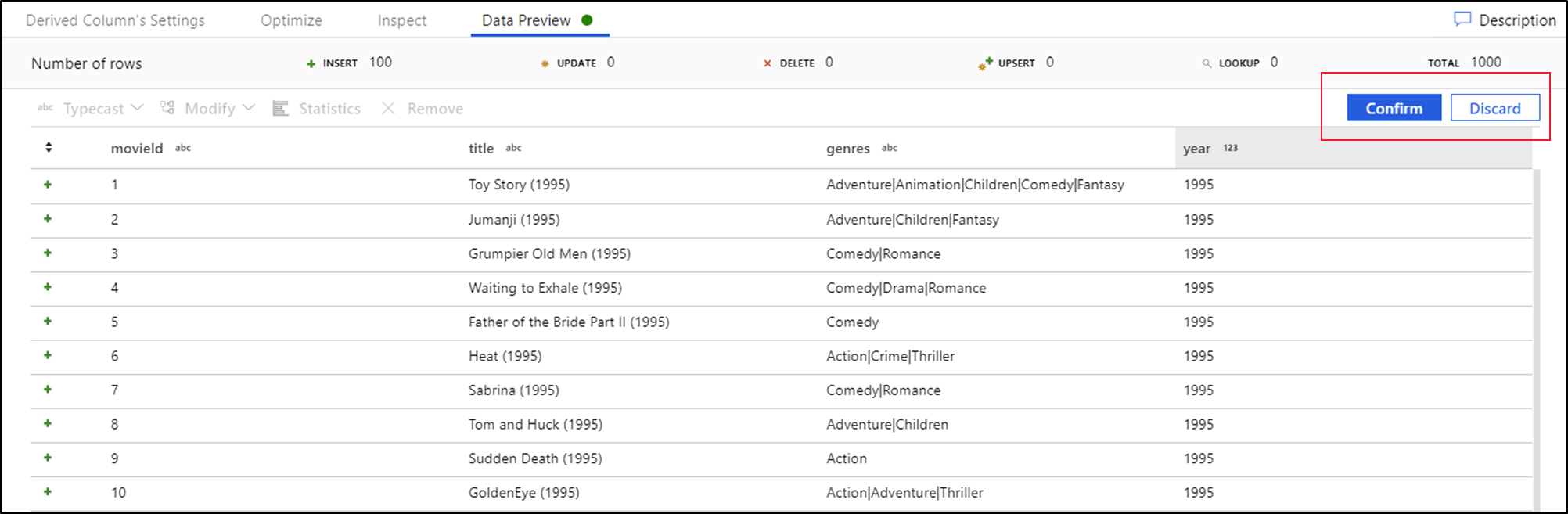
Typecast i Modify generują przekształcenie kolumny pochodnej, a Remove generuje przekształcenie Select.
Uwaga
Jeśli edytujesz przepływ danych, musisz ponownie pobrać podgląd danych przed dodaniem szybkiej transformacji.
Profilowanie danych
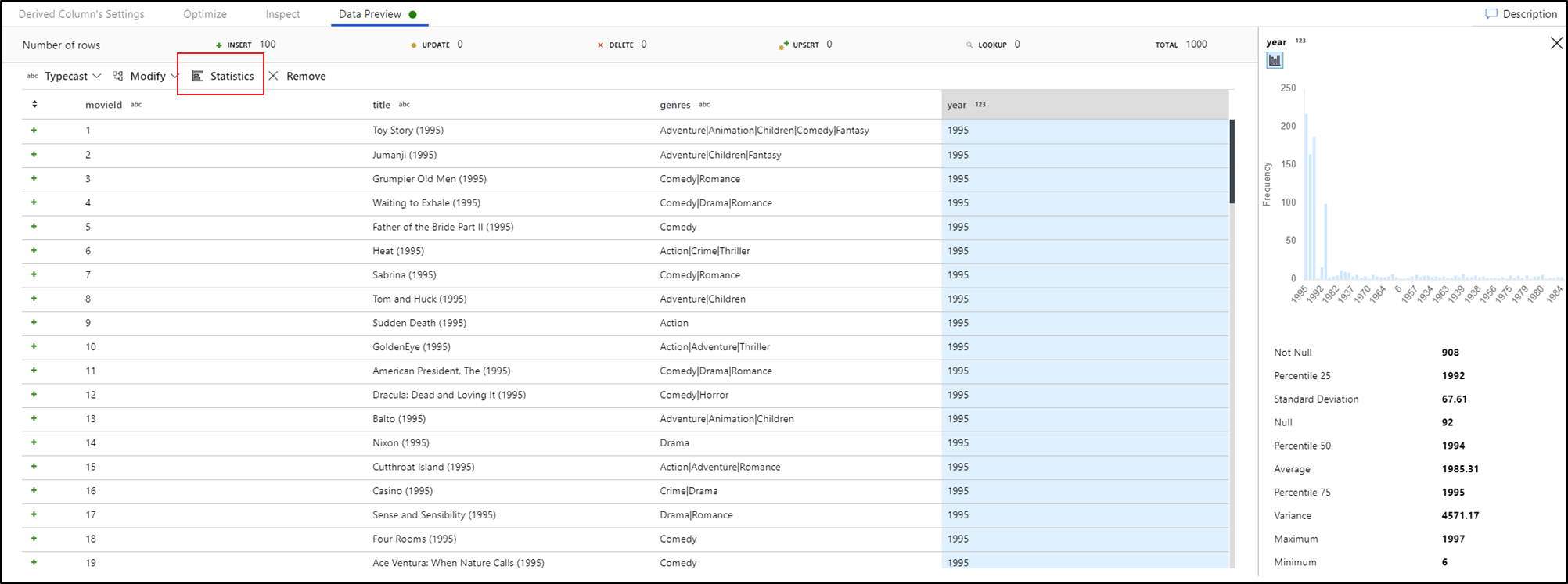
Wybranie kolumny na karcie podglądu danych i kliknięcie pozycji Statystyki na pasku narzędzi podglądu danych spowoduje wyświetlenie wykresu po prawej stronie siatki danych ze szczegółowymi statystykami dotyczącymi każdego pola. Usługa podejmuje decyzję na podstawie próbkowania danych, jaki typ wykresu wyświetlić. Pola o wysokiej kardynalności są domyślnie ustawione na NULL/NOT NULL, natomiast dane kategoryczne i liczbowe o niskiej kardynalności wyświetlają się na wykresach słupkowych pokazujących częstotliwość wartości danych. Zobaczysz również maksymalną/długość pól tekstowych, minimalną/maksymalną wartość w polach liczbowych, odchylenie standardowe, percentyle, liczność i średnią wartość.
Powiązana zawartość
- Po zakończeniu budowania i debugowania przepływu danych, uruchom go z poziomu potoku.
- Podczas testowania potoku za pomocą przepływu danych użyj opcji wykonania przebiegu debugowania potoku.