Monitorowanie przepływu danych
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Po zakończeniu kompilowania i debugowania przepływu danych chcesz zaplanować wykonywanie przepływu danych zgodnie z harmonogramem w kontekście potoku. Potok można zaplanować przy użyciu wyzwalaczy. Aby przetestować i debugować przepływ danych z potoku, możesz użyć przycisku Debuguj na wstążce paska narzędzi lub opcji Wyzwól teraz z narzędzia Pipeline Builder, aby wykonać wykonanie pojedynczego uruchomienia w celu przetestowania przepływu danych w kontekście potoku.
Podczas wykonywania potoku można monitorować potok i wszystkie działania zawarte w potoku, w tym działanie Przepływ danych. Wybierz ikonę monitora w panelu interfejsu użytkownika po lewej stronie. Możesz zobaczyć ekran podobny do poniższego. Wyróżnione ikony umożliwiają przechodzenie do szczegółów działań w potoku, w tym działanie Przepływ danych.
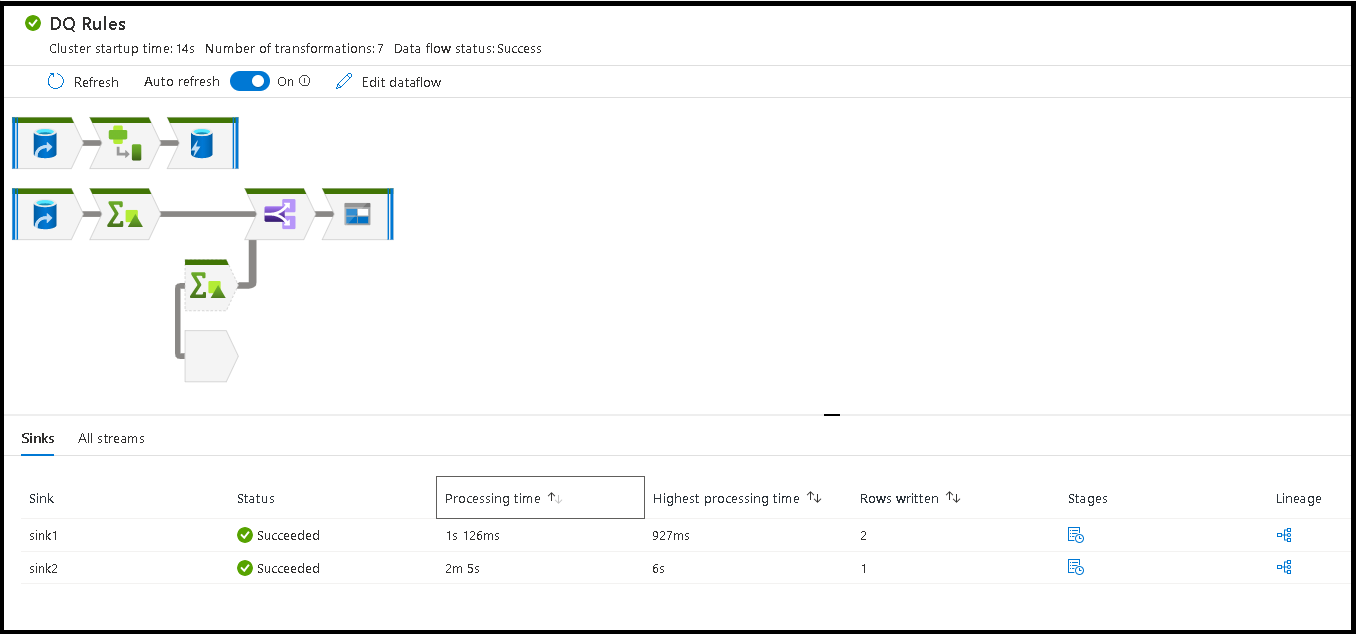
Statystyki są widoczne na tym poziomie, w tym czasy uruchamiania i stan. Identyfikator przebiegu na poziomie działania różni się od identyfikatora przebiegu na poziomie potoku. Identyfikator przebiegu na poprzednim poziomie jest przeznaczony dla potoku. Wybranie okularów zapewnia szczegółowe informacje na temat wykonywania przepływu danych.

Gdy jesteś w widoku monitorowania węzłów graficznych, możesz zobaczyć uproszczoną wersję widoku tylko dla wykresu przepływu danych. Aby wyświetlić widok szczegółów z większymi węzłami grafu zawierającymi etykiety etapu przekształcania, użyj suwaka powiększenia po prawej stronie kanwy. Możesz również użyć przycisku wyszukiwania po prawej stronie, aby znaleźć części logiki przepływu danych na wykresie.
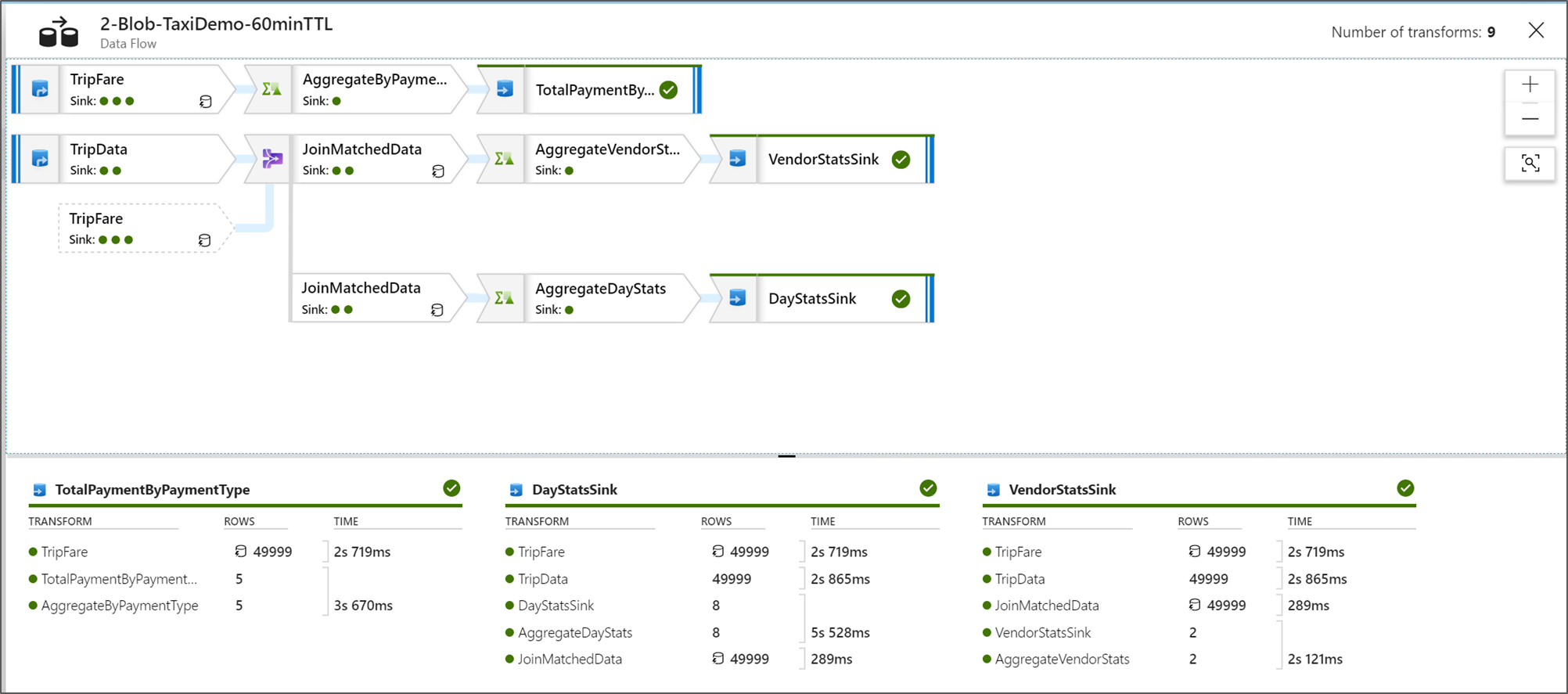
Wyświetlanie planów wykonywania Przepływ danych
Po wykonaniu Przepływ danych na platformie Spark usługa określa optymalne ścieżki kodu na podstawie całego przepływu danych. Ponadto ścieżki wykonywania mogą występować w różnych węzłach skalowania w poziomie i partycjach danych. W związku z tym wykres monitorowania reprezentuje projekt przepływu, biorąc pod uwagę ścieżkę wykonywania przekształceń. Po wybraniu poszczególnych węzłów zobaczysz "etapy", które reprezentują kod, który został wykonany razem w klastrze. Wyświetlane chronometraż i liczniki reprezentują te grupy lub etapy, w przeciwieństwie do poszczególnych kroków w projekcie.
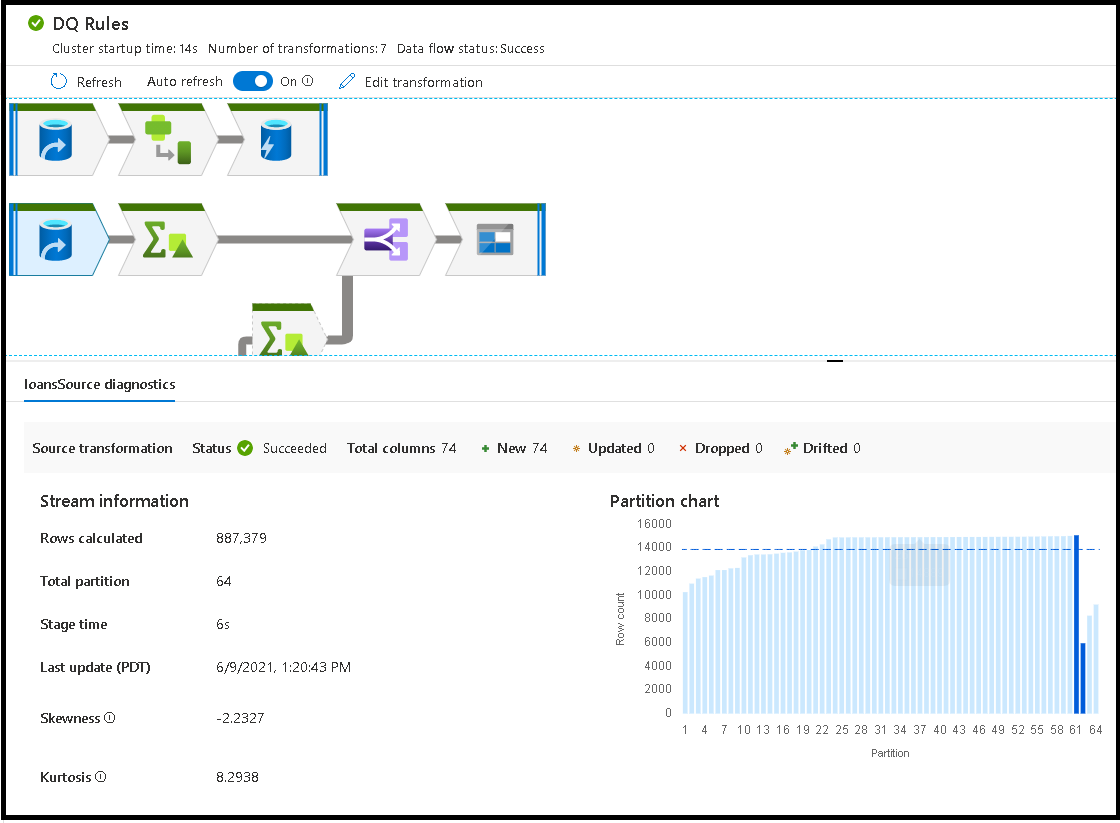
Po wybraniu otwartej przestrzeni w oknie monitorowania statystyki w dolnym okienku wyświetlają chronometraż i liczbę wierszy dla każdego ujścia oraz przekształcenia, które doprowadziły do danych ujścia dla pochodzenia transformacji.
Po wybraniu poszczególnych przekształceń otrzymasz dodatkową opinię na panelu po prawej stronie, w którym są wyświetlane statystyki partycji, liczby kolumn, niesymetryczność (jak równomiernie dane są dystrybuowane między partycjami) i kurtosis (jak kolczaste są dane).
Sortowanie według czasu przetwarzania pomaga określić, które etapy przepływu danych zajęły najwięcej czasu.
Aby dowiedzieć się, które przekształcenia wewnątrz każdego etapu zajęły najwięcej czasu, posortuj według najwyższego czasu przetwarzania.
Zapisane *wiersze są również sortowane jako sposób identyfikowania strumieni wewnątrz przepływu danych, które zapisują najwięcej danych.
Po wybraniu ujścia w widoku węzła można zobaczyć pochodzenie kolumn. Istnieją trzy różne metody gromadzenia kolumn w całym przepływie danych, aby wylądować w ujściu. Są to:
- Obliczane: kolumna jest używana do przetwarzania warunkowego lub wyrażenia w przepływie danych, ale nie ląduje w ujściu
- Pochodne: kolumna jest nową kolumną wygenerowaną w przepływie, czyli nie była obecna w źródle
- Mapowane: kolumna pochodzi ze źródła i mapujesz ją na pole ujścia
- Stan przepływu danych: bieżący stan wykonania
- Czas uruchamiania klastra: ilość czasu na uzyskanie środowiska obliczeniowego JIT Spark na potrzeby wykonywania przepływu danych
- Liczba przekształceń: ile kroków transformacji jest wykonywanych w przepływie

Porównanie całkowitego czasu przetwarzania ujścia z czasem przetwarzania transformacji
Każdy etap transformacji zawiera łączny czas ukończenia tego etapu wraz z łącznym czasem wykonywania partycji. Po wybraniu ujścia zostanie wyświetlony komunikat "Czas przetwarzania ujścia". Ten czas obejmuje łączny czas transformacji oraz czas we/wy, który zajęło zapisanie danych w magazynie docelowym. Różnica między czasem przetwarzania ujścia a sumą transformacji jest czas we/wy do zapisania danych.
Możesz również zobaczyć szczegółowy czas dla każdego kroku przekształcania partycji, jeśli otworzysz dane wyjściowe JSON z działania przepływu danych w widoku monitorowania potoku. Kod JSON zawiera milisekundowy czas dla każdej partycji, natomiast widok monitorowania środowiska użytkownika jest agregowanym czasem partycji dodanych razem:
{
"stage": 4,
"partitionTimes": [
14353,
14914,
14246,
14912,
...
]
}
Czas przetwarzania ujścia
Po wybraniu ikony przekształcenia ujścia na mapie panel slajdów po prawej stronie pokazuje dodatkowy punkt danych o nazwie "czas przetwarzania końcowego" u dołu. Jest to ilość czasu poświęcanego na wykonywanie zadania w klastrze Spark po załadowaniu, przekształceniu i zapisaniu danych. Tym razem może obejmować zamykanie pul połączeń, zamykanie sterowników, usuwanie plików, łączenie plików itp. W przypadku wykonywania akcji w przepływie, takich jak "przenoszenie plików" i "dane wyjściowe do pojedynczego pliku", prawdopodobnie zobaczysz wzrost wartości czasu przetwarzania końcowego.
- Czas trwania zapisu: czas zapisywania danych w lokalizacji przejściowej dla usługi Synapse SQL
- Czas trwania operacji tabeli SQL: czas potrzebny na przenoszenie danych z tabel tymczasowych do tabeli docelowej
- Czas trwania przed sql i czas trwania postu SQL: czas spędzony na uruchamianiu poleceń pre/post sql
- Czas trwania i publikowanie poleceń wstępnych: czas spędzony na uruchamianiu dowolnych operacji przed/post dla źródła/ujścia opartego na plikach. Na przykład przenieś lub usuń pliki po przetworzeniu.
- Czas trwania scalania: czas spędzony na scalaniu pliku, scalanie plików jest używane do ujścia opartych na plikach podczas zapisywania do pojedynczego pliku lub gdy jest używana opcja "Nazwa pliku jako dane kolumny". Jeśli w tej metryce spędzisz dużo czasu, należy unikać korzystania z tych opcji.
- Czas etapu: łączna ilość czasu spędzonego wewnątrz platformy Spark w celu ukończenia operacji jako etapu.
- Tymczasowa stabilna tymczasowa: nazwa tabeli tymczasowej używanej przez przepływy danych do etapu danych w bazie danych.
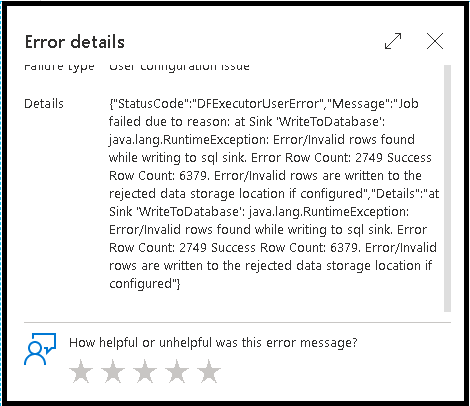
Wiersze błędów
Włączenie obsługi wierszy błędów w ujściu przepływu danych zostanie odzwierciedlone w danych wyjściowych monitorowania. Po ustawieniu ujścia na wartość "zgłoś powodzenie po błędzie", dane wyjściowe monitorowania pokazują liczbę wierszy zakończonych powodzeniem i niepowodzeniem po wybraniu węzła monitorowania ujścia.
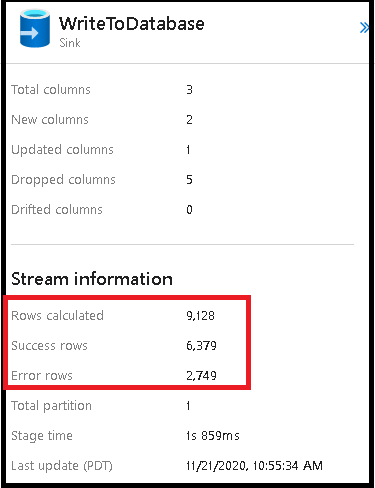
Po wybraniu pozycji "Zgłoś błąd po błędzie" te same dane wyjściowe są wyświetlane tylko w tekście wyjściowym monitorowania aktywności. Dzieje się tak, ponieważ działanie przepływu danych zwraca błąd wykonania, a szczegółowy widok monitorowania jest niedostępny.
Ikony monitora
Ta ikona oznacza, że dane przekształcenia zostały już zapisane w pamięci podręcznej w klastrze, więc chronometraż i ścieżka wykonywania uwzględniły następujące elementy:
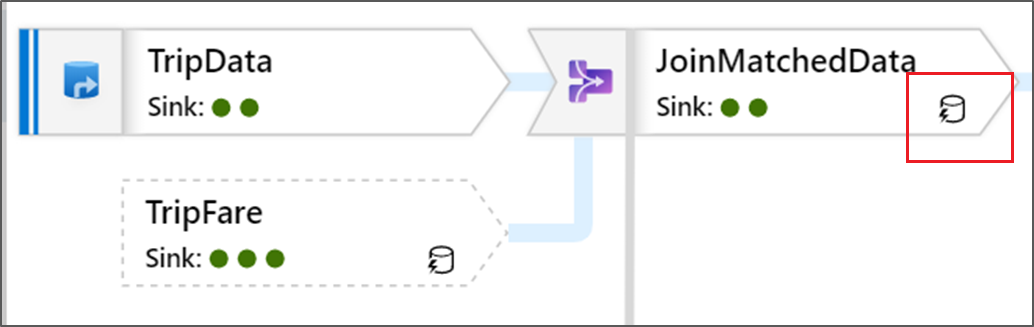
W transformacji są również widoczne ikony zielonego okręgu. Reprezentują one liczbę ujść, do których przepływają dane.