Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Wskazówka
Data Factory w usłudze Microsoft Fabric jest następną generacją Azure Data Factory z prostszą architekturą, wbudowaną sztuczną inteligencją i nowymi funkcjami. Jeśli dopiero zaczynasz integrować dane, zacznij od Fabric Data Factory. Istniejące obciążenia ADF można zaktualizować do Fabric, aby uzyskać dostęp do nowych możliwości w zakresie nauki o danych, analiz w czasie rzeczywistym oraz raportowania.
Działanie jar Azure Databricks w pipeline uruchamia plik Spark Jar w klastrze Azure Databricks. Ten artykuł opiera się na artykule dotyczącym działań przekształcania danych, który zawiera ogólne omówienie transformacji danych i obsługiwanych działań przekształcania. Azure Databricks to zarządzana platforma do uruchamiania platformy Apache Spark.
Poniższy klip wideo zawiera jedenastominutowe wprowadzenie i demonstrację tej funkcji:
Dodaj działanie Jar dla Azure Databricks do potoku za pomocą interfejsu użytkownika
Aby użyć działania typu Jar dla Azure Databricks w potoku danych, wykonaj następujące kroki:
Wyszukaj plik Jar w okienku Działania potoku i przeciągnij działanie Jar na kanwę potoku.
Wybierz nową aktywność Jar na płótnie, jeśli nie jest jeszcze wybrana.
Wybierz kartę Azure Databricks aby wybrać lub utworzyć nową połączoną usługę Azure Databricks, która wykona działanie Jar.
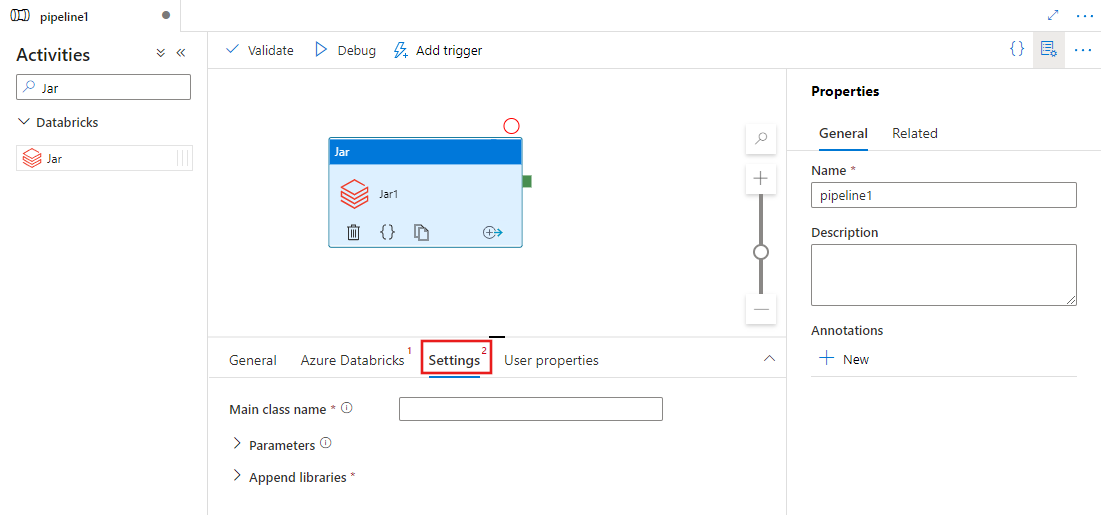
Wybierz kartę Settings i określ nazwę klasy, która ma zostać wykonana na Azure Databricks, opcjonalne parametry, które mają zostać przekazane do pliku Jar, i biblioteki do zainstalowania w klastrze w celu wykonania zadania.
Opis operacji pliku Jar Databricks
Oto przykładowa definicja JSON czynności Databricks Jar:
{
"name": "SparkJarActivity",
"type": "DatabricksSparkJar",
"linkedServiceName": {
"referenceName": "AzureDatabricks",
"type": "LinkedServiceReference"
},
"typeProperties": {
"mainClassName": "org.apache.spark.examples.SparkPi",
"parameters": [ "10" ],
"libraries": [
{
"jar": "dbfs:/docs/sparkpi.jar"
}
]
}
}
Właściwości aktywności JAR w Databricks
W poniższej tabeli opisano właściwości JSON używane w definicji JSON:
| Właściwości | Opis | Wymagane |
|---|---|---|
| nazwa | Nazwa działania w potoku. | Tak |
| opis | Tekst opisujący działanie. | Nie. |
| typ | W przypadku aktywności Databricks Jar, typ aktywności to DatabricksSparkJar. | Tak |
| linkedServiceName | Nazwa połączonej usługi Databricks, na której jest uruchamiana akcja Jar. Aby dowiedzieć się więcej o tej połączonej usłudze, zobacz artykuł Dotyczący połączonych usług obliczeniowych. | Tak |
| mainClassName | Pełna nazwa klasy zawierającej metodę main do wykonania. Ta klasa musi być zawarta w pliku JAR udostępnionym jako biblioteka. Plik JAR może zawierać wiele klas. Każda z klas może zawierać metodę main. | Tak |
| parametry | Parametry, które zostaną przekazane do metody main. Ta właściwość jest tablicą ciągów. | Nie. |
| biblioteki | Lista bibliotek, które mają być zainstalowane w klastrze, które będą wykonywać zadanie. Może to być tablica składająca się z ciągów < oraz obiektów>. | Tak (co najmniej jeden zawierający metodę mainClassName) |
Uwaga
Znany problem — podczas korzystania z tego samego klastra interaktywnego do uruchamiania równoległych działań typu Jar w Databricks (bez ponownego uruchamiania klastra) istnieje znany problem, gdzie parametry pierwszego działania są również wykorzystywane przez kolejne działania. W związku z tym dochodzi do przekazania nieprawidłowych parametrów do kolejnych zadań. Aby rozwiązać ten problem, należy zamiast tego użyć klastra zadań.
Obsługiwane biblioteki dla działań usługi Databricks
W poprzedniej definicji działania usługi Databricks określono następujące typy bibliotek: jar, , eggmaven, pypi, . cran
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Aby uzyskać więcej informacji, zobacz dokumentację usługi Databricks dotyczącą typów bibliotek.
Jak załadować bibliotekę w usłudze Databricks
Możesz użyć interfejsu użytkownika obszaru roboczego:
Korzystanie z interfejsu użytkownika obszaru roboczego usługi Databricks
Aby uzyskać ścieżkę dbfs biblioteki dodanej przy użyciu UI, możesz użyć Databricks CLI.
Zazwyczaj biblioteki Jar są przechowywane w obszarze dbfs:/FileStore/jars podczas korzystania z interfejsu użytkownika. Możesz wyświetlić listę przez CLI: databricks fs ls dbfs:/FileStore/job-jars
Możesz też użyć interfejsu wiersza polecenia usługi Databricks:
Postępuj zgodnie z instrukcjami kopiowania biblioteki przy użyciu interfejsu CLI usługi Databricks
Użyj interfejsu wiersza polecenia Databricks (kroki instalacji)
Aby na przykład skopiować plik JAR do dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar
Powiązana zawartość
Aby zapoznać się z jedenastominutowym wprowadzeniem i pokazem tej funkcji, obejrzyj wideo.