Ustawianie wartości zwracanej potoku w usługach Azure Data Factory i Azure Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
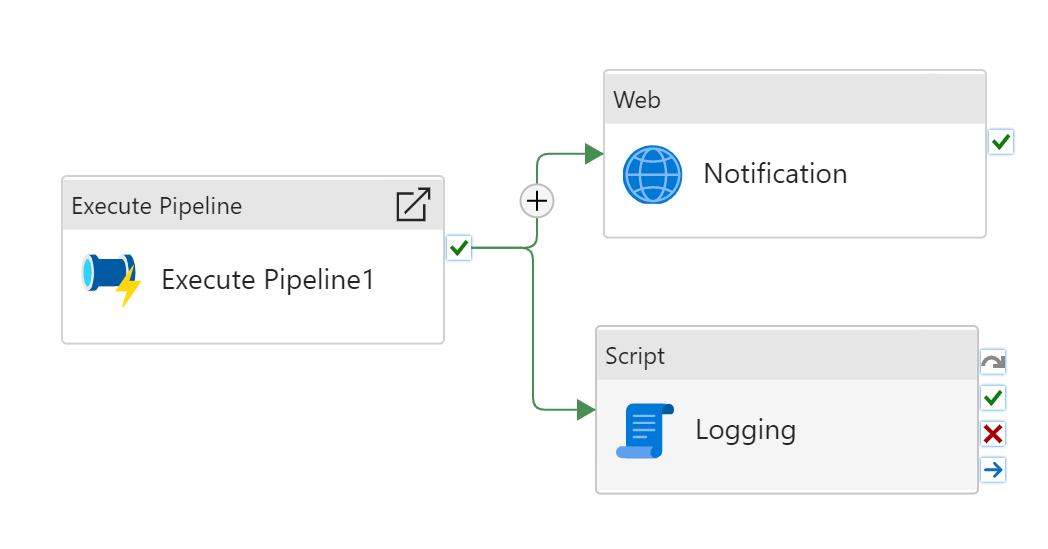
W modelu wywoływania potoku podrzędnego potoku można użyć działania Ustaw zmienną, aby zwrócić wartości z potoku podrzędnego do potoku wywołującego. W poniższym scenariuszu mamy potok podrzędny za pomocą działania wykonywania potoku. Chcemy również pobrać informacje z potoku podrzędnego, które będą następnie używane w potoku wywołującym.
Wprowadź wartość zwracaną potoku, słownik par klucz-wartość, który umożliwia komunikację między potokami podrzędnymi i potokiem nadrzędnym.
Wymaganie wstępne — wywoływanie potoku podrzędnego
Zgodnie z wymaganiami wstępnymi projekt wymaga działania execute pipeline wywołującego potok podrzędny z włączoną funkcją Wait on Completion (Oczekiwanie po zakończeniu ) w działaniu.

Konfigurowanie wartości zwracanej potoku w potoku podrzędnym
Rozszerzyliśmy działanie Ustaw zmienną, aby uwzględnić zmienne systemowe Wartość zwracana potoku. Nie musisz definiować ich na poziomie potoku (w przeciwieństwie do innych zmiennych używanych w potoku).
- Wyszukaj pozycję Ustaw zmienną w okienku Działania potoku i przeciągnij działanie Ustaw zmienną na kanwę potoku.
- Wybierz działanie Ustaw zmienną na kanwie, jeśli nie zostało jeszcze wybrane, a następnie kartę Zmienne , aby edytować jego szczegóły.
- Wybierz wartość zwracaną potoku dla typu zmiennej.
- Wybierz pozycję Nowy , aby dodać nową parę wartości klucza.
- Liczba par klucz-wartość, które można dodać, jest ograniczona tylko przez limit rozmiaru zwracanego kodu JSON (4 MB).

Istnieje kilka opcji dla typów wartości, w tym
| Nazwa typu | opis |
|---|---|
| String | Stała wartość ciągu. na przykład: "Usługa ADF jest niesamowita" |
| Wyrażenie | Umożliwia odwołuje się do danych wyjściowych z poprzednich działań. W tym miejscu możesz użyć interpolacji ciągów, aby uwzględnić wartości wyrażeń w wierszu, takie jak "The value is @{guid()}". |
| Tablica | Oczekuje tablicy wartości ciągów. Naciśnij "Enter", aby oddzielić wartości w tablicy |
| Wartość logiczna | True lub False |
| Null (zero) | Status posiadacza miejsca sygnału; wartość jest stała null |
| Int | Wartość liczbowa typu całkowitego. Na przykład: 42 |
| Liczba zmiennoprzecinkowa | Wartość liczbowa typu zmiennoprzecinkowego. Na przykład: 2.71828 |
| Objekt | Ostrzeżenie tylko o skomplikowanych przypadkach użycia. Umożliwia ona osadzanie listy par klucz-wartość typu dla wartości |
Wartość typu obiektu jest definiowana w następujący sposób:
[{"key": "myKey1", "value": {"type": "String", "content": "hello world"}},
{"key": "myKey2", "value": {"type": "String", "content": "hi"}}
]
Pobieranie wartości w potoku wywołującym
Wartość zwracana potoku podrzędnego staje się danymi wyjściowymi działania działania Działania wykonywania potoku. Informacje można pobrać za pomocą polecenia @activity('Execute Pipeline1').output.pipelineReturnValue.keyName. Przypadek użycia jest nieograniczony. Można na przykład użyć polecenia
- Wartość int z potoku podrzędnego w celu zdefiniowania okresu oczekiwania dla działania oczekiwania
- Wartość ciągu definiująca adres URL działania sieci Web
- Ładunek wartości wyrażenia dla działania skryptu na potrzeby rejestrowania.

Istnieją dwa zauważalne objaśnienia dotyczące zwracanych wartości potoku.
- Za pomocą typu obiektu można dodatkowo rozwinąć zagnieżdżony obiekt json, taki jak @activity('Execute Pipeline1').output.pipelineReturnValue.keyName.nextLevelKey
- Za pomocą typu tablicy można określić indeks na liście z @activity('Execute Pipeline1').output.pipelineReturnValue.keyName[0]. Liczba jest zero indeksowana, co oznacza, że zaczyna się od 0.
Uwaga
Upewnij się, że nazwa klucza , do którego odwołujesz się, istnieje w potoku podrzędnym. Konstruktor wyrażeń usługi ADF nie może potwierdzić sprawdzania odwołań. Potok zakończy się niepowodzeniem, jeśli brakuje klucza, do którego odwołuje się ładunek
Kwestie szczególne
Chociaż w potoku można uwzględnić wiele działań Ustaw wartość zwracaną potoku, ważne jest, aby upewnić się, że w potoku jest wykonywany tylko jeden z nich.

Aby uniknąć opisanego wcześniej problemu z brakiem klucza podczas wywoływania potoku, zachęcamy do utworzenia tej samej listy kluczy dla wszystkich gałęzi w potoku podrzędnym. Rozważ użycie typów null dla kluczy, które nie mają wartości w określonej gałęzi.
Powiązana zawartość
Dowiedz się więcej o innym powiązanym działaniu przepływu sterowania: