Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Uwaga
Organizacja tego artykułu zakłada, że używasz prostego interfejsu użytkownika do obliczeń. Aby zapoznać się z omówieniem prostych aktualizacji formularzy, zobacz Zarządzanie obliczeniami przy użyciu prostego formularza.
W tym artykule opisano ustawienia konfiguracji dostępne podczas tworzenia nowego zasobu obliczeniowego ogólnego przeznaczenia lub zadania. Większość użytkowników tworzy zasoby obliczeniowe przy użyciu przypisanych zasad, co ogranicza konfigurowalne ustawienia. Jeśli w interfejsie użytkownika nie widzisz określonego ustawienia, to dlatego, że wybrane zasady nie umożliwiają skonfigurowania tego ustawienia.
Aby uzyskać zalecenia dotyczące konfigurowania zasobów obliczeniowych dla obciążenia, zobacz Najlepsze rozwiązania dotyczące konfiguracji klasycznych obliczeń.
Konfiguracje i narzędzia do zarządzania opisane w tym artykule dotyczą zarówno obliczeń ogólnego przeznaczenia, jak i obliczeń zadaniowych. Aby uzyskać więcej informacji na temat konfigurowania obliczeń zadań, zobacz Konfigurowanie zasobów obliczeniowych dla zadań.
Tworzenie nowego zasobu obliczeniowego ogólnego przeznaczenia
Aby utworzyć nowy zasób obliczeniowy ogólnego przeznaczenia:
- Na pasku bocznym obszaru roboczego kliknij pozycję Compute.
- Kliknij przycisk Utwórz obliczenia .
- Skonfiguruj zasób obliczeniowy.
- Kliknij pozycję Utwórz.
Nowy zasób obliczeniowy zostanie automatycznie uruchomiony i będzie gotowy do użycia wkrótce.
zasady obliczeniowe
Zasady to zestaw reguł używanych do ograniczania opcji konfiguracji dostępnych dla użytkowników podczas tworzenia zasobów obliczeniowych. Jeśli użytkownik nie ma nieograniczonego uprawnienia do tworzenia klastra , może tworzyć tylko zasoby obliczeniowe przy użyciu przyznanych zasad.
Aby utworzyć zasoby obliczeniowe zgodnie z zasadami, wybierz zasady z menu rozwijanego Zasady .
Domyślnie wszyscy użytkownicy mają dostęp do zasad osobistych obliczeń , umożliwiając im tworzenie zasobów obliczeniowych z jedną maszyną. Jeśli potrzebujesz dostępu do zasobów obliczeniowych osobistych lub innych zasad, skontaktuj się z administratorem obszaru roboczego.
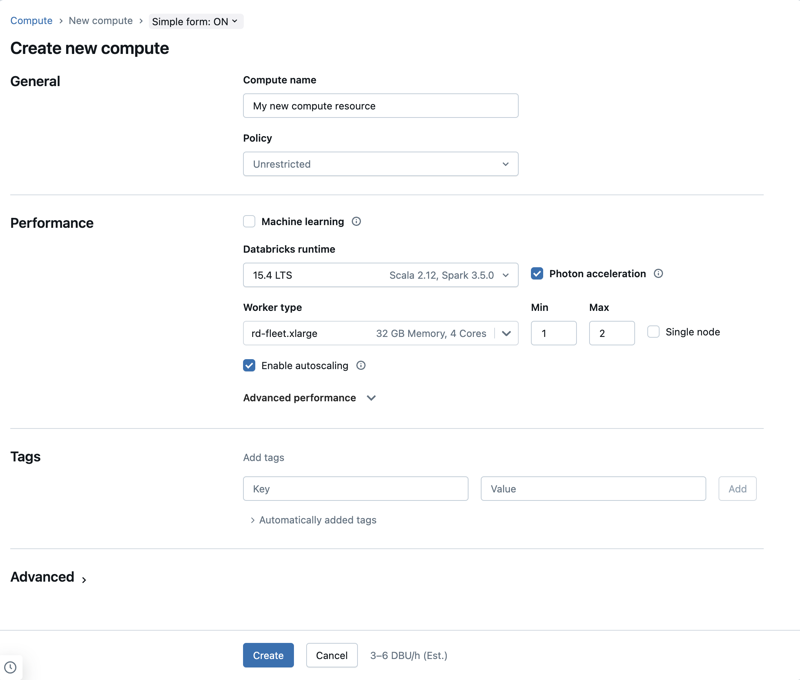
Ustawienia wydajności
Następujące ustawienia są wyświetlane w sekcji Wydajność prostego interfejsu użytkownika obliczeniowego formularza:
- Wersje środowiska Uruchomieniowego usługi Databricks
- Użyj przyspieszenia Photon
- typ węzła roboczego
- Pojedynczy węzeł obliczeniowy
- Włączanie skalowania automatycznego
- Zaawansowane ustawienia wydajności
Wersje Uruchomieniowe usługi Databricks
Databricks Runtime to zestaw podstawowych składników uruchamianych na zasobach obliczeniowych. Wybierz środowisko uruchomieniowe przy użyciu menu rozwijanego Wersja środowiska uruchomieniowego usługi Databricks . Aby uzyskać szczegółowe informacje na temat określonych wersji środowiska Databricks Runtime, zobacz Databricks Runtime release notes versions and compatibility (Wersje i zgodność środowiska Databricks Runtime). Wszystkie wersje obejmują platformę Apache Spark. Usługa Databricks zaleca następujące kwestie:
- W przypadku obliczeń wszystkich celów użyj najnowszej wersji, aby upewnić się, że masz najnowsze optymalizacje i najbardziej aktualną zgodność między kodem i wstępnie załadowanych pakietów.
- W przypadku obliczeń zadań z obciążeniami operacyjnymi w toku, rozważ użycie wersji Long Term Support (LTS) środowiska Databricks Runtime. Użycie wersji LTS zapewni, że nie wystąpią problemy ze zgodnością i można dokładnie przetestować Twoje obciążenie przed uaktualnieniem.
- W przypadku zastosowań nauki o danych i uczenia maszynowego, należy wziąć pod uwagę środowisko Databricks Runtime ML.
Użyj przyspieszania Photon
Funkcja Photon jest domyślnie włączona na obliczeniach działających w środowisku Databricks Runtime 9.1 LTS i nowszych.
Aby włączyć lub wyłączyć przyspieszenie Photon, zaznacz pole wyboru Użyj przyspieszenia Photon. Aby dowiedzieć się więcej na temat Photon, zobacz Co to jest Photon?.
typ węzła roboczego
Zasób obliczeniowy składa się z jednego węzła sterownika i zera lub większej liczby węzłów roboczych. Można wybrać oddzielne typy wystąpień dostawcy usług w chmurze dla węzłów sterowników i procesów roboczych, chociaż domyślnie węzeł sterownika używa tego samego typu wystąpienia co węzeł roboczy. Ustawienie węzła sterownika znajduje się w sekcji Zaawansowanej wydajności.
Różne rodziny typów wystąpień pasują do różnych przypadków użycia, takich jak obciążenia intensywnie korzystające z pamięci lub intensywnie korzystające z obliczeń. Możesz również wybrać pulę do użycia jako węzeł roboczy lub węzeł sterowniczy.
Ważne
Nie używaj puli z wystąpieniami typu spot jako typ sterownika. Wybierz typ sterownika na żądanie, aby uniemożliwić odzyskanie sterownika. Zobacz Łączenie z pulami.
W przypadku obliczeń wielowęzłowych węzły robocze uruchamiają funkcje wykonawcze platformy Spark i inne usługi wymagane do prawidłowego działania zasobu obliczeniowego. Podczas dystrybucji obciążenia za pomocą platformy Spark całe rozproszone przetwarzanie odbywa się w węzłach roboczych. Azure Databricks uruchamia jednego wykonawcę na każdym węźle roboczym. W związku z tym terminy wykonawcze i proces roboczy są używane zamiennie w kontekście architektury usługi Databricks.
Napiwek
Aby uruchomić zadanie platformy Spark, potrzebujesz co najmniej jednego węzła roboczego. Jeśli zasób obliczeniowy ma zero procesów roboczych, możesz uruchamiać polecenia niebędące poleceniami Spark w węźle sterownika, ale polecenia Spark zakończą się niepowodzeniem.
Elastyczne typy węzłów
Jeśli obszar roboczy ma włączone elastyczne typy węzłów, możesz użyć elastycznych typów węzłów dla zasobu obliczeniowego. Elastyczne typy węzłów umożliwiają zasobowi obliczeniowemu powrót do alternatywnych, zgodnych typów wystąpień, gdy określony typ wystąpienia jest niedostępny. To zachowanie zwiększa niezawodność uruchamiania zasobów obliczeniowych przez zmniejszenie liczby awarii pojemności podczas uruchamiania obliczeń. Zobacz Zwiększanie niezawodności uruchamiania obliczeń przy użyciu elastycznych typów węzłów.
Adresy IP węzłów roboczych
Azure Databricks uruchamia węzły robocze z dwoma prywatnymi adresami IP. Podstawowy prywatny adres IP węzła obsługuje wewnętrzny ruch w Azure Databricks. Pomocniczy prywatny adres IP jest używany przez kontener Spark do komunikacji wewnątrz klastra. Ten model umożliwia Azure Databricks zapewnienie izolacji między wieloma zasobami obliczeniowymi w tym samym obszarze roboczym.
Typy wystąpień procesora GPU
W przypadku zadań wymagających obliczeń wymagających wysokiej wydajności, takich jak związane z uczeniem głębokim, Azure Databricks obsługuje zasoby obliczeniowe przyspieszane za pomocą jednostek przetwarzania grafiki (GPU). Aby uzyskać więcej informacji, zobacz Obliczenia z obsługą procesora GPU.
Azure wirtualne maszyny obliczeniowe do poufnych obliczeń
Azure poufne typy maszyn wirtualnych przetwarzania uniemożliwiają nieautoryzowany dostęp do danych, w tym z operatora chmury. Ten typ maszyny wirtualnej jest korzystny dla wysoce regulowanych branż i regionów, a także firm z poufnymi danymi w chmurze. Aby uzyskać więcej informacji na temat poufnego przetwarzania Azure, zobacz Azure poufne przetwarzanie.
Aby uruchamiać obciążenia przy użyciu maszyn wirtualnych Azure do przetwarzania poufnego, wybierz typy maszyn wirtualnych serii DC lub EC z list rozwijanych dla węzłów procesu roboczego i węzłów sterujących. Zobacz opcje poufnych maszyn wirtualnych Azure.
obliczenia jednowęzłowe
Pole wyboru Pojedynczy węzeł umożliwia utworzenie pojedynczego zasobu obliczeniowego węzła.
Obliczenia z jednym węzłem są przeznaczone dla zadań korzystających z małych ilości danych lub obciążeń nieprostrybucyjnych, takich jak biblioteki uczenia maszynowego z jednym węzłem. Obliczenia z wieloma węzłami powinny być używane w przypadku większych zadań z obciążeniami rozproszonymi.
Właściwości pojedynczego węzła
Zasób obliczeniowy z jednym węzłem ma następujące właściwości:
- Uruchamia platformę Spark lokalnie.
- Sterownik działa zarówno jako główny, jak i pracownik, bez węzłów roboczych.
- Tworzy jeden wątek wykonawczy na każdy rdzeń logiczny w zasobie obliczeniowym, z wyjątkiem 1 rdzenia dla sterownika.
- Zapisuje wszystkie
stderr,stdoutilog4jwyjścia logów w dzienniku sterownika. - Nie można przekonwertować na zasób obliczeniowy z wieloma węzłami.
Wybieranie pojedynczego lub wielowęzłowego
Podczas podejmowania decyzji o obliczeniach z jednym lub wieloma węzłami należy wziąć pod uwagę przypadek użycia:
Przetwarzanie danych na dużą skalę spowoduje wyczerpanie zasobów w zasobie obliczeniowym pojedynczego węzła. W przypadku tych obciążeń usługa Databricks zaleca korzystanie z obliczeń wielowęźleowych.
Nie można skalować zasobu obliczeniowego z wieloma węzłami do 0 pracowników. Zamiast tego użyj systemu obliczeniowego z jednym węzłem.
Planowanie GPU nie jest włączone w obliczeniach jednowęzłowych.
W przypadku obliczeń na pojedynczym węźle Spark nie może odczytać plików Parquet z kolumną UDT. Pojawia się następujący komunikat o błędzie:
The Spark driver has stopped unexpectedly and is restarting. Your notebook will be automatically reattached.Aby obejść ten problem, wyłącz natywny czytnik Parquet:
spark.conf.set("spark.databricks.io.parquet.nativeReader.enabled", False)
Włączanie skalowania automatycznego
Po zaznaczeniu opcji Włącz skalowanie automatyczne można podać minimalną i maksymalną liczbę procesów roboczych dla zasobu obliczeniowego. Następnie Databricks decyduje się na odpowiednią liczbę pracowników wymaganych do uruchomienia zadania.
Aby ustawić minimalną i maksymalną liczbę pracowników, pomiędzy którymi zasób obliczeniowy będzie się automatycznie skalować, użyj pól Minimalna i Maksymalna obok listy rozwijanej Typ procesów pracowniczych.
Jeśli nie włączysz skalowania automatycznego, musisz wprowadzić stałą liczbę pracowników w polu Pracownicy obok listy rozwijanej Typ pracownika.
Uwaga
Gdy zasób obliczeniowy działa, na stronie szczegółów zasobu obliczeniowego wyświetlana jest liczba przydzielonych pracowników. Liczbę przydzielonych pracowników można porównać z konfiguracją pracowników i wprowadzić korekty zgodnie z potrzebami.
Zalety skalowania automatycznego
Dzięki skalowaniu automatycznemu Azure Databricks dynamicznie przydziela zasoby, aby uwzględnić charakterystykę twojego zadania. Niektóre części potoku mogą być bardziej obciążające obliczeniowo niż inne, a usługa Databricks automatycznie dodaje dodatkowych pracowników w tych fazach pracy (i usuwa ich, gdy nie są już potrzebni).
Skalowanie automatyczne ułatwia osiągnięcie wysokiego wykorzystania, ponieważ nie trzeba aprowizować zasobów obliczeniowych w celu dopasowania ich do obciążenia. Dotyczy to szczególnie obciążeń, których wymagania zmieniają się w czasie (na przykład eksplorowanie zestawu danych w ciągu dnia), ale może również mieć zastosowanie do jednorazowego krótszego obciążenia, którego wymagania dotyczące aprowizacji są nieznane. Skalowanie automatyczne oferuje zatem dwie zalety:
- Obciążenia mogą działać szybciej w porównaniu z nieodpowiednio przydzielonym zasobem obliczeniowym o stałym rozmiarze.
- Skalowanie automatyczne może zmniejszyć całościowe koszty w porównaniu z zasobem obliczeniowym o statycznie określonej wielkości.
W zależności od stałego rozmiaru zasobu obliczeniowego i obciążenia skalowanie automatyczne daje jedną lub obie te korzyści w tym samym czasie. Rozmiar obliczeniowy może spaść poniżej minimalnej liczby jednostek roboczych wybranych, gdy dostawca usług w chmurze kończy wystąpienia. W takim przypadku Azure Databricks stale ponawia próbę ponownego aprowizowania wystąpień w celu zachowania minimalnej liczby procesów roboczych.
Uwaga
Skalowanie automatyczne nie jest dostępne w przypadku zadań spark-submit.
Uwaga
Automatyczne skalowanie zasobów obliczeniowych ma ograniczenia dotyczące zmniejszania rozmiaru klastra dla obciążeń przetwarzania strumieniowego ze zdefiniowaną strukturą. Usługa Databricks zaleca używanie potoków deklaratywnych platformy Spark w usłudze Lakeflow z rozszerzonym skalowaniem automatycznym na potrzeby obciążeń przesyłania strumieniowego. Zobacz Optymalizowanie wykorzystania klastra pipeline’u Lakeflow za pomocą automatycznego skalowania.
How autoscaling behaves (Jak działa skalowanie automatyczne)
Obszary robocze na planie Premium używają zoptymalizowanego skalowania automatycznego. Obszary robocze w standardowym planie cenowym korzystają ze standardowego skalowania automatycznego.
Zoptymalizowane skalowanie automatyczne ma następujące cechy:
- Skaluje się w górę od minimum do maksimum w najwyżej 2 zdarzeniach skalowania.
- Można skalować w dół, nawet jeśli zasób obliczeniowy nie jest bezczynny, sprawdzając stan pliku shuffle.
- Skaluje w dół na podstawie procenta aktualnych węzłów.
- W przypadku wykonywania zadań obliczeniowych następuje automatyczne zmniejszanie zasobów, jeśli zasoby obliczeniowe są niedostatecznie wykorzystane przez ostatnie 40 sekund.
- W przypadku zasobów obliczeniowych ogólnego przeznaczenia skaluje się w dół, jeśli zasób obliczeniowy jest niedostatecznie wykorzystany w ciągu ostatnich 150 sekund.
-
spark.databricks.aggressiveWindowDownSWłaściwość konfiguracji platformy Spark określa w sekundach, jak często obliczenia podejmują decyzje dotyczące skalowania w dół. Zwiększenie wartości powoduje, że obliczenia będą skalowane w dół wolniej. Maksymalna wartość to 600.
Skalowanie automatyczne typu standardowego jest używane w obszarach roboczych planu standardowego. Skalowanie w wersji Standard ma następujące cechy:
- Rozpoczyna się od dodania 8 węzłów. Następnie skaluje w górę wykładniczo, wykonując tyle kroków, ile jest wymaganych do osiągnięcia maksymalnej wartości.
- Skaluje w dół, gdy 90% węzłów nie jest zajęte przez 10 minut, a obliczenia były bezczynne przez co najmniej 30 sekund.
- Skaluje w dół wykładniczo, począwszy od 1 węzła.
Ostrzeżenie
Nie należy włączać dynamicznej alokacji platformy Apache Spark (spark.dynamicAllocation.enabled) w zasobach obliczeniowych korzystających z skalowania automatycznego usługi Databricks. Skalowanie automatyczne usługi Databricks zarządza węzłami roboczymi i cyklem życia instancji wykonawczej na poziomie platformy. Włączenie dynamicznej alokacji Spark równolegle może prowadzić do konfliktowych decyzji dotyczących skalowania, co skutkuje częstą rotacją zasobów wykonawczych, NODES_LOST błędami i zadaniami, które nigdy nie są przejmowane.
Skalowanie automatyczne za pomocą pul
Jeśli dołączasz zasób obliczeniowy do puli, rozważ następujące kwestie:
- Upewnij się, że żądany rozmiar obliczeniowy jest mniejszy lub równy minimalnej liczbie bezczynnych wystąpień w puli. Jeśli jest większy, czas uruchamiania obliczeń będzie odpowiednikiem obliczeń, które nie korzystają z puli.
- Upewnij się, że maksymalny rozmiar obliczeniowy jest mniejszy lub równy maksymalnej pojemności puli. Jeśli jest on większy, tworzenie zasobów obliczeniowych zakończy się niepowodzeniem.
Przykład skalowania automatycznego
Jeśli ponownie skonfigurujesz statyczny zasób obliczeniowy do automatycznego skalowania, Azure Databricks natychmiast zmienia rozmiar zasobu obliczeniowego w granicach minimalnych i maksymalnych, a następnie uruchamia skalowanie automatyczne. Na przykład w poniższej tabeli przedstawiono, co dzieje się z zasobem obliczeniowym o określonym rozmiarze początkowym, jeśli ponownie skonfigurujesz zasób obliczeniowy do automatycznego skalowania między 5 i 10 węzłami.
| Rozmiar początkowy | Rozmiar po rekonfiguracji |
|---|---|
| 6 | 6 |
| 12 | 10 |
| 3 | 5 |
Zaawansowane ustawienia wydajności
Poniższe ustawienia są wyświetlane w sekcji Zaawansowana wydajność w prostym interfejsie użytkownika formularza obliczeń.
instancje typu Spot
Aby zaoszczędzić koszty, możesz użyć instancji spot, znanych również jako maszyny wirtualne Azure Spot, zaznaczając pole wyboru Spot instances.

Pierwsze wystąpienie zawsze będzie na żądanie (węzeł sterujący jest zawsze na żądanie), a kolejne wystąpienia będą wystąpieniami typu spot.
Jeśli instancje są usuwane z powodu niedostępności, Azure Databricks spróbuje uzyskać nowe instancje typu spot w celu zastąpienia usuniętych instancji. Jeśli nie można uzyskać wystąpień typu spot, wystąpienia na żądanie są stosowane w celu zastąpienia usuniętych wystąpień. Ten powrót po awarii na żądanie jest obsługiwany tylko w przypadku wystąpień typu spot, które zostały w pełni pozyskane i są uruchomione. Wystąpienia typu spot, które kończą się niepowodzeniem podczas konfiguracji, nie są automatycznie zastępowane.
Ponadto, gdy do istniejących zasobów obliczeniowych dodawane są nowe węzły, Azure Databricks próbuje uzyskać dla nich wystąpienia typu spot.
Automatyczne zakończenie
Automatyczne kończenie obliczeń można ustawić w sekcji Wydajność formularza tworzenia obliczeń. Podczas tworzenia zasobów obliczeniowych określ okres braku aktywności w minutach, po którym ma zostać zakończony zasób obliczeniowy.
Jeśli różnica między bieżącym czasem a ostatnim uruchomieniem polecenia w zasobie obliczeniowym przekracza określony okres braku aktywności, Azure Databricks automatycznie kończy ten zasób obliczeniowy. Aby uzyskać więcej informacji na temat kończenia obliczeń, zobacz Kończenie obliczeń.
Typ sterownika
Typ sterownika można wybrać w sekcji Zaawansowana wydajność. Węzeł sterownika przechowuje informacje o stanie wszystkich notesów dołączonych do zasobu obliczeniowego. Węzeł sterownika obsługuje również SparkContext, interpretuje wszystkie polecenia uruchamiane z notesu lub biblioteki na zasobie obliczeniowym i uruchamia węzeł główny Apache Spark, który koordynuje się z wykonawcami Spark.
Wartość domyślna typu węzła sterownika jest taka sama jak typ węzła roboczego. Możesz wybrać większy typ węzła sterownika z większą ilością pamięci, jeśli planujesz collect() wiele danych z procesów roboczych platformy Spark i analizować je w notesie.
Napiwek
Ponieważ węzeł sterownika przechowuje wszystkie informacje o stanie dołączonych notesów, pamiętaj, aby odłączyć nieużywane notesy z węzła sterownika.
Tagi
Tagi umożliwiają łatwe monitorowanie kosztów zasobów obliczeniowych używanych przez różne grupy w organizacji. Określ tagi jako pary klucz-wartość podczas tworzenia zasobów obliczeniowych, a Azure Databricks stosuje te tagi do zasobów w chmurze, takich jak maszyny wirtualne i woluminy dysków, a także dzienniki użycia usługi Databricks.
W przypadku obliczeń uruchamianych z pul tagi niestandardowe są stosowane tylko do raportów użycia DBU i nie są propagowane do zasobów chmury.
Aby uzyskać szczegółowe informacje na temat współdziałania typów tagów puli i obliczeń, zobacz Użyj tagów do przypisywania i śledzenia użycia
Aby dodać tagi do zasobu obliczeniowego:
- W sekcji Tagi dodaj parę klucz-wartość dla każdego tagu niestandardowego.
- Kliknij przycisk Dodaj.
Ustawienia zaawansowane
Następujące ustawienia są wyświetlane w sekcji Zaawansowane prostego interfejsu użytkownika obliczeniowego formularza:
- Tryby dostępu
- Włączanie automatycznego skalowania magazynu lokalnego
- Szyfrowanie dysku lokalnego
- Konfiguracja platformy Spark
- Dostarczanie dzienników obliczeniowych
- Dostęp SSH do obliczeń
- Zmienne środowiskowe
Tryby dostępu
Tryb dostępu to funkcja zabezpieczeń, która określa, kto może używać zasobu obliczeniowego i danych, do których mogą uzyskiwać dostęp przy użyciu zasobu obliczeniowego. Każdy zasób obliczeniowy w Azure Databricks ma tryb dostępu. Ustawienia trybu dostępu znajdują się w sekcji Zaawansowane prostego interfejsu użytkownika obliczeniowego formularza.
Wybór trybu dostępu jest domyślnie automatyczny , co oznacza, że tryb dostępu jest automatycznie wybierany na podstawie wybranego środowiska Databricks Runtime. Opcja Auto jest domyślnie ustawiona na Standard, chyba że wybrano środowisko uruchomieniowe uczenia maszynowego, typ instancji GPU lub Databricks Runtime w wersji niższej niż 14.3; w takim przypadku używane jest ustawienie Dedykowane.
Usługa Databricks zaleca korzystanie ze standardowego trybu dostępu, chyba że wymagane funkcje nie są obsługiwane.
| Tryb dostępu | Description | Obsługiwane języki |
|---|---|---|
| Standard | Może być używany przez wielu użytkowników z izolacją danych wśród użytkowników. | Python, SQL, Scala |
| Dedykowana | Może być przypisany i używany przez pojedynczego użytkownika lub grupę. | Python, SQL, Scala, R |
Aby uzyskać szczegółowe informacje na temat obsługi funkcji dla każdego z tych trybów dostępu, zobacz Standardowe wymagania i ograniczenia dotyczące obliczeń orazDedykowane wymagania i ograniczenia obliczeniowe.
Uwaga
W środowisku Databricks Runtime 13.3 LTS i nowszym skrypty inicjowania i biblioteki są obsługiwane przez wszystkie tryby dostępu. Wymagania i poziomy obsługi różnią się. Zobacz Gdzie można zainstalować skrypty inicjalizujące? i Biblioteki dla obliczeń.
Włączanie automatycznego skalowania magazynu lokalnego
Często trudno jest oszacować ilość miejsca na dysku potrzebnego do wykonania określonego zadania. Aby oszczędzić konieczność oszacowania, ile gigabajtów dysku zarządzanego ma zostać dołączonych do zasobów obliczeniowych Azure Databricks w momencie tworzenia, Azure Databricks automatycznie włącza funkcję autoskalowania magazynu lokalnego na wszystkich obliczeniach Azure Databricks.
Dzięki automatycznemu skalowaniu magazynu lokalnego, Azure Databricks monitoruje ilość wolnego miejsca na dysku dostępnego na pracownikach Spark w środowisku obliczeniowym. Jeśli pracownik zaczyna mieć mało dostępnego miejsca na dysku, usługa Databricks automatycznie dołącza nowy zarządzany dysk do pracownika, zanim zabraknie mu przestrzeni dyskowej. Dyski można dołączyć, aż do osiągnięcia limitu 5 TB całkowitej pamięci dyskowej na maszynę wirtualną (w tym początkowej lokalnej pamięci maszyny wirtualnej).
Dyski zarządzane dołączone do maszyny wirtualnej są odłączane tylko wtedy, gdy maszyna wirtualna zostanie zwrócona do Azure. Oznacza to, że dyski zarządzane nigdy nie są odłączane od maszyny wirtualnej, o ile są one częścią działającego środowiska obliczeniowego. Aby skalować w dół użycie dysku zarządzanego, Azure Databricks zaleca użycie tej funkcji w obliczeniach skonfigurowanych przy użyciu autoskalowania dla obliczeń lub automatycznego zakończenia obliczeń.
Szyfrowanie dysku lokalnego
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
Niektóre typy wystąpień używane do uruchamiania obliczeń mogą mieć lokalnie dołączone dyski. Azure Databricks może przechowywać dane przetasowania lub efemeryczne dane na tych lokalnie podłączonych dyskach. Aby upewnić się, że wszystkie dane w stanie spoczynku są szyfrowane dla wszystkich typów magazynu, w tym dane tymczasowe przechowywane chwilowo na dyskach lokalnych zasobu obliczeniowego, można włączyć szyfrowanie dysku lokalnego.
Ważne
Obciążenia mogą działać wolniej ze względu na wpływ na wydajność odczytywania i zapisywania zaszyfrowanych danych do i z woluminów lokalnych.
Po włączeniu szyfrowania dysku lokalnego Azure Databricks generuje klucz szyfrowania lokalnie unikatowy dla każdego węzła obliczeniowego i służy do szyfrowania wszystkich danych przechowywanych na dyskach lokalnych. Zakres klucza jest lokalny dla każdego węzła obliczeniowego i jest niszczony wraz z samym węzłem obliczeniowym. W okresie jego istnienia klucz znajduje się w pamięci na potrzeby szyfrowania i odszyfrowywania i jest przechowywany zaszyfrowany na dysku.
Aby włączyć szyfrowanie dysków lokalnych, należy użyć interfejsu API klastrów. Podczas tworzenia lub edytowania zasobów obliczeniowych ustaw enable_local_disk_encryption na true.
Konfiguracja platformy Spark
Aby dostosować zadania platformy Spark, możesz podać niestandardowe właściwości konfiguracji platformy Spark.
Uwaga
W standardowym trybie dostępu w środowisku Databricks Runtime 19 lub nowszym niektóre właściwości konfiguracji platformy Spark są ograniczone. Tworzenie lub edytowanie klastra, który ustawia właściwość z ograniczeniami kończy się niepowodzeniem z powodu błędu. Zobacz Ograniczenia konfiguracji platformy Spark.
Na stronie konfiguracja obliczeniowa kliknij przełącznik Zaawansowany .
Kliknij kartę Spark .
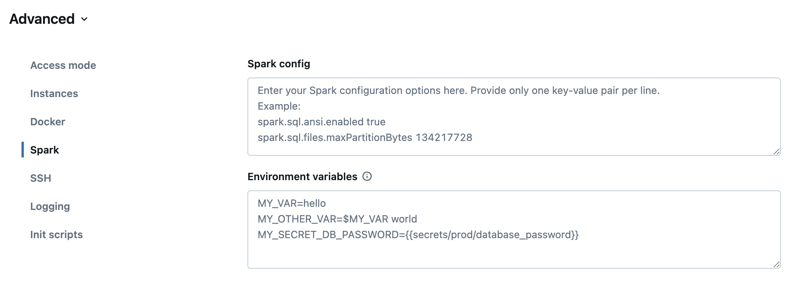
W konfiguracji platformy Spark wprowadź właściwości konfiguracji jako jedną parę klucz-wartość na wiersz.
Podczas konfigurowania obliczeń przy użyciu API klastrów ustaw właściwości Spark w polu spark_conf w API utwórz klaster lub API aktualizacji klastra.
Aby wymusić konfiguracje platformy Spark na obliczeniach, administratorzy obszaru roboczego mogą używać zasad obliczeniowych.
Pobierz właściwość konfiguracji Spark ze źródła tajnego
Databricks zaleca przechowywanie poufnych informacji, takich jak hasła, w sekrecie zamiast zwykłego tekstu. Aby odwołać się do wpisu tajnego w konfiguracji platformy Spark, użyj następującej składni:
spark.<property-name> {{secrets/<scope-name>/<secret-name>}}
Na przykład, aby ustawić właściwość konfiguracji Spark o nazwie password na wartość tajemnicy przechowywanej w pliku secrets/acme_app/password:
spark.password {{secrets/acme-app/password}}
Aby uzyskać więcej informacji, zobacz Zarządzanie tajemnicami.
Dostarczanie logów obliczeń
Podczas tworzenia zasobów obliczeniowych typu all-purpose lub jobs można określić lokalizację dzienników klastra, w tym dzienniki ze sterownika Spark, węzłów procesu roboczego i zdarzeń. Dzienniki są dostarczane co pięć minut i archiwizowane co godzinę w wybranym miejscu docelowym. Usługa Databricks kontynuuje dostarczanie dzienników do momentu zakończenia zasobu obliczeniowego.
Dzienniki można przechowywać w jednej z następujących lokalizacji:
- Woluminy (zalecane): Przechowuje dzienniki w ścieżce woluminu Unity Catalog. Jest to zalecana i najbezpieczniejsza opcja przy korzystaniu z zasobów obliczeniowych obsługiwanych przez Unity Catalog.
- DBFS (starsza wersja): Przechowuje dzienniki w ścieżce systemu plików Databricks File System (DBFS). Ta opcja jest dostępna tylko wtedy, gdy katalog główny systemu plików DBFS i instalacji nie są wyłączone dla obszaru roboczego. Zobacz Wyłącz dostęp do katalogu głównego DBFS i montowania w istniejącym obszarze roboczym Azure Databricks.
Aby skonfigurować lokalizację dostarczania dziennika:
- Na stronie obliczeniowej kliknij przełącznik Zaawansowane .
- Kliknij kartę Rejestrowanie .
- Wybierz typ miejsca docelowego.
- Wprowadź ścieżkę logu .
Aby przechowywać dzienniki, usługa Databricks tworzy podfolder w wybranej ścieżce dziennika, który nosi nazwę pochodzącą od identyfikatora danego obliczenia cluster_id.
Jeśli na przykład określona ścieżka dziennika jest /Volumes/catalog/schema/volume, dzienniki dla 06308418893214 są dostarczane do /Volumes/catalog/schema/volume/06308418893214.
Uwaga
Dostarczanie dzienników do woluminu jest obsługiwane tylko w przypadku zasobów obliczeniowych z włączonym katalogiem Unity w trybie dostępu Standard lub Dedykowany przypisanym do użytkownika. Nie jest obsługiwany w trybie dedykowanego dostępu przypisanego do grupy. Jeśli wybierzesz wolumin jako ścieżkę, sprawdź, czy właściciel jednostki obliczeniowej lub przypisany do niej użytkownik ma uprawnienia READ VOLUME oraz WRITE VOLUME na woluminie. Zobacz Uprawnienia dla woluminów Unity Catalog.
Dostęp SSH do obliczeń
Ze względów bezpieczeństwa w Azure Databricks port SSH jest domyślnie zamykany. Jeśli chcesz włączyć dostęp SSH do klastrów Spark, zobacz Protokół SSH do węzła sterownika.
Uwaga
Protokół SSH można włączyć tylko wtedy, gdy obszar roboczy jest wdrożony we własnej wirtualnej sieci Azure.
Zmienne środowiskowe
Skonfiguruj niestandardowe zmienne środowiskowe, do których można uzyskać dostęp za pomocą skryptów inicjowania uruchomionych w zasobie obliczeniowym. Usługa Databricks udostępnia również wstępnie zdefiniowane zmienne środowiskowe , których można używać w skryptach inicjowania. Nie można zastąpić tych wstępnie zdefiniowanych zmiennych środowiskowych.
Uwaga
W standardowym trybie dostępu w Databricks Runtime 19 i nowszych tylko wstępnie zdefiniowany zestaw zmiennych środowiskowych jest dostępny dla silnika Spark i skryptów inicjalizacyjnych. Inne zmienne, które ustawisz w klastrze, są nadal dostępne w kodzie użytkownika, w tym w funkcjach UDF. Zobacz Ograniczenia zmiennych środowiskowych.
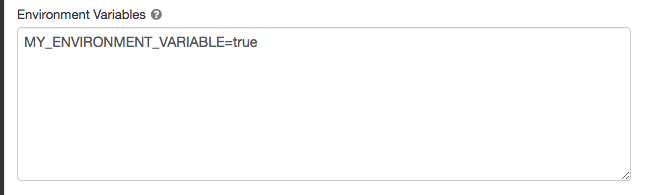
Na stronie Konfiguracja obliczeniowa kliknij pozycję Zaawansowane.
Kliknij kartę Spark .
Ustaw zmienne środowiskowe w polu Zmienne środowiskowe .
Zmienne środowiskowe można również ustawić przy użyciu pola spark_env_vars w interfejsie API tworzenia klastra lub interfejsie API aktualizowania klastra.