Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Na tej stronie wyjaśniono, jak usługa Azure Databricks używa usługi Lakeguard do wymuszania izolacji użytkowników w udostępnionych środowiskach obliczeniowych i szczegółowej kontroli dostępu w dedykowanych obliczeniach.
Co to jest Lakeguard?
Lakeguard to zestaw technologii usługi Databricks, które wymuszają izolację kodu i filtrowanie danych, dzięki czemu wielu użytkowników może bezpiecznie i efektywnie korzystać z tych samych zasobów obliczeniowych, a także uzyskiwać dostęp do danych z precyzyjnymi mechanizmami kontroli dostępu do zasobów obliczeniowych oferujących uprzywilejowany dostęp do maszyn.
Jak działa lakeguard?
W udostępnionych środowiskach obliczeniowych, takich jak standardowe klasyczne obliczenia, bezserwerowe obliczenia i magazyny SQL, usługa Lakeguard izoluje kod użytkownika od aparatu Spark i innych użytkowników. Ten projekt umożliwia wielu użytkownikom współdzielenie tych samych zasobów obliczeniowych przy zachowaniu ścisłych granic między użytkownikami, sterownikiem platformy Spark i funkcjami wykonawczych.
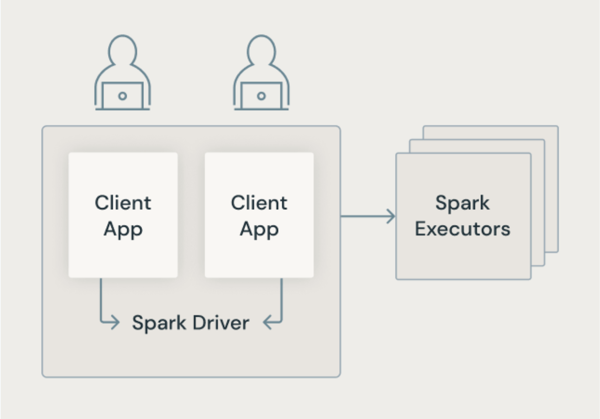
Klasyczna architektura platformy Spark
Na poniższej ilustracji pokazano, jak w tradycyjnej architekturze Spark aplikacje użytkowników współdzielą maszynę wirtualną JVM z uprzywilejowanym dostępem do podstawowej maszyny.
Architektura lakeguard
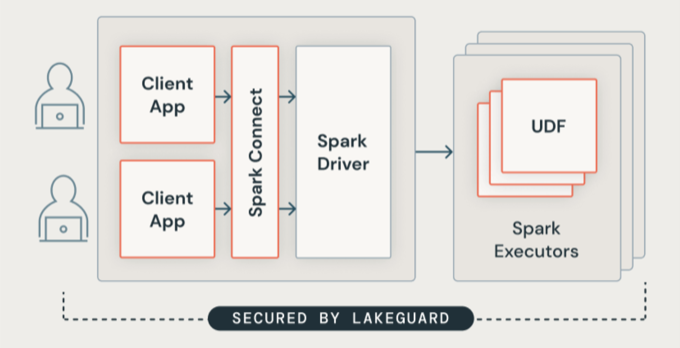
Usługa Lakeguard izoluje cały kod użytkownika przy użyciu bezpiecznych kontenerów. Umożliwia to uruchamianie wielu obciążeń na tym samym zasobie obliczeniowym przy zachowaniu ścisłej izolacji między użytkownikami.
Izolacja klienta platformy Spark
Usługa Lakeguard izoluje aplikacje klienckie od sterownika Spark i od siebie przy użyciu dwóch kluczowych składników:
Spark Connect: usługa Lakeguard używa programu Spark Connect (wprowadzonego z platformą Apache Spark 3.4) w celu oddzielenia aplikacji klienckich od sterownika. Aplikacje klienckie i sterowniki nie współużytkuje już tej samej maszyny JVM ani ścieżki klas. Ta separacja uniemożliwia nieautoryzowany dostęp do danych. Ten projekt uniemożliwia również użytkownikom uzyskiwanie dostępu do danych wynikających z nadmiernego pobierania, gdy zapytania obejmują filtry na poziomie wiersza lub kolumny.
Uwaga / Notatka
Spark Connect odracza analizę i rozpoznawanie nazw do czasu kompilacji, co może wpłynąć na sposób działania twojego kodu. Zobacz Porównanie programu Spark Connect z modelem klasycznym platformy Spark.
Piaskownica kontenerów: każda aplikacja kliencka działa we własnym izolowanym środowisku kontenera. Zapobiega to dostępowi kodu użytkownika do danych innych użytkowników lub maszyny źródłowej. Piaskownica używa technik izolacji opartej na kontenerach do tworzenia bezpiecznych granic między użytkownikami.
Izolacja funkcji zdefiniowanej przez użytkownika
Domyślnie funkcje wykonawcze platformy Spark nie izolują funkcji zdefiniowanych przez użytkownika. Brak izolacji może zezwalać na zapisywanie plików przez użytkownika lub uzyskiwanie dostępu do maszyny źródłowej.
Usługa Lakeguard izoluje kod zdefiniowany przez użytkownika, w tym funkcje zdefiniowane przez użytkownika, w funkcjach wykonawczych platformy Spark przez:
- Piaskownica środowiska wykonawczego w funkcjach wykonawczych platformy Spark.
- Izolowanie ruchu sieciowego ruchu wychodzącego z funkcji zdefiniowanych przez użytkownika, aby zapobiec nieautoryzowanemu dostępowi zewnętrznemu.
- Replikowanie środowiska klienta do piaskownicy funkcji zdefiniowanej przez użytkownika, aby użytkownicy mogli uzyskiwać dostęp do wymaganych bibliotek.
Ta izolacja ma zastosowanie do funkcji zdefiniowanych przez użytkownika w przypadku standardowych funkcji obliczeniowych i zdefiniowanych przez użytkownika języka Python w przypadku bezserwerowych zasobów obliczeniowych i magazynów SQL.