Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Na tej stronie wyjaśniono, jak skonfigurować środowisko bezserwerowe dla notatników i zadań. W przypadku notesów użyj okienka bocznego Środowisko , aby wybrać środowisko podstawowe, zainstalować zależności, skonfigurować pamięć i zastosować zasady użycia. W przypadku zadań skonfiguruj środowisko podczas tworzenia lub edytowania zadania.
Aby rozwinąć panel boczny Środowisko, kliknij przycisk ![]() po prawej stronie notatnika.
po prawej stronie notatnika.
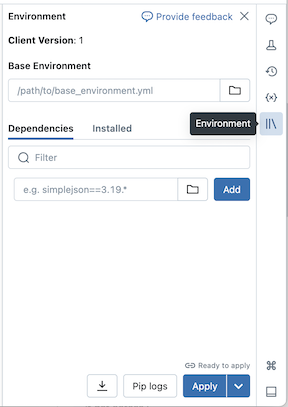
Wybieranie środowiska podstawowego
Środowisko podstawowe określa wstępnie zainstalowane biblioteki i wersję środowiska dostępną dla notesu bezserwerowego. Selektor środowiska podstawowego w okienku po stronie środowiska to miejsce, w którym wybierasz środowisko. Aby wyświetlić szczegółowe informacje na temat każdej wersji środowiska, zobacz Wersje środowiska bezserwerowego. Usługa Databricks zaleca korzystanie z najnowszej wersji, aby uzyskać najnowsze funkcje notesu.
Selektor środowiska podstawowego obejmuje następujące opcje:
- Standardowa: domyślne środowisko podstawowe bezserwerowe z bibliotekami udostępnianymi przez usługę Databricks.
- ML: To podstawowe środowisko z pakietami Python i pakietami systemowymi z Databricks Runtime for Machine Learning, które są preinstalowane. To środowisko służy do migrowania klasycznego środowiska Databricks Runtime na potrzeby obciążeń Machine Learning do bezserwerowych zasobów obliczeniowych. Zobacz Środowisko podstawowe uczenia maszynowego.
- Sztuczna inteligencja: zoptymalizowane pod kątem sztucznej inteligencji środowisko podstawowe ze wstępnie zainstalowanymi bibliotekami uczenia maszynowego (ML). Ta opcja jest wyświetlana tylko w przypadku wybrania akceleratora (GPU).
-
Więcej: Rozwija się, aby wyświetlić dodatkowe opcje:
- Poprzednie wersje środowisk Standard, ML i AI.
- Niestandardowe: określ środowisko niestandardowe przy użyciu pliku YAML.
- Środowiska obszarów roboczych: wyświetla listę wszystkich zgodnych środowisk podstawowych skonfigurowanych dla obszaru roboczego przez administratora.
Aby wybrać środowisko podstawowe:
- W interfejsie notesu kliknij panel boczny Środowisko
 .
. - W obszarze Środowisko podstawowe wybierz środowisko z menu rozwijanego.
- Kliknij przycisk Zastosuj.
Dodaj zależności do notebooka
Ponieważ bezserwerowe nie obsługuje zasad obliczeniowych ani skryptów inicjowania, należy zainstalować niestandardowe zależności przy użyciu okienka bocznego Środowisko . Zależności można instalować pojedynczo lub użyć współużytkowalnego środowiska podstawowego, aby zainstalować wiele zależności.
Azure Databricks buforuje środowisko wirtualne notesu, dlatego zależności nie są ponownie instalowane za każdym razem, gdy ponownie otworzysz notes lub wznowisz działanie po braku aktywności. Zadania, które współdzielą ten sam zestaw zależności, również korzystają z tej pamięci podręcznej w ramach jednego uruchomienia.
Aby zainstalować zależność pojedynczo:
W interfejsie notesu kliknij panel boczny Środowisko
.W sekcji Zależności kliknij pozycję Dodaj zależność i wprowadź ścieżkę zależności w polu . Zależność można określić w dowolnym formacie prawidłowym w pliku requirements.txt . Pliki koła Python lub projekty Python (na przykład katalog zawierający
pyproject.tomllubsetup.py) mogą znajdować się w plikach obszaru roboczego lub woluminach Katalogu Unity.- Jeśli używasz pliku obszaru roboczego, ścieżka powinna być bezwzględna i zaczynać się od
/Workspace/. - Jeśli używasz pliku w woluminie Unity Catalog, ścieżka powinna mieć następujący format:
/Volumes/<catalog>/<schema>/<volume>/<path>.whl.
- Jeśli używasz pliku obszaru roboczego, ścieżka powinna być bezwzględna i zaczynać się od
Kliknij Apply aby zainstalować zależności i ponownie uruchomić proces Python.
Important
Nie należy instalować PySpark ani żadnej biblioteki, która instaluje PySpark jako zależność na bezserwerowych notatnikach. Spowoduje to zatrzymanie sesji i wystąpienie błędu. W takim przypadku usuń bibliotekę i zresetuj środowisko.
Aby wyświetlić zainstalowane zależności, kliknij kartę Zainstalowane w okienku bocznym Środowiska . Otwórz dzienniki instalacji pip dla środowiska notatnika, klikając pip logs u dołu panelu.
Note
Administratorzy przestrzeni roboczej mogą skonfigurować prywatne lub wymagające uwierzytelnienia repozytoria pakietów jako domyślne źródło pakietów pip dla bezserwerowych notatników i zadań. Dzięki temu użytkownicy mogą instalować pakiety z repozytoriów wewnętrznych bez określania index-url lub extra-index-url. Zobacz Konfiguruj domyślne repozytoria pakietów Python.
Tworzenie niestandardowej specyfikacji środowiska
Można tworzyć i ponownie używać niestandardowych specyfikacji środowiska.
- W notesie bezserwerowym wybierz środowisko podstawowe i zainstaluj dowolne zależności.
- Kliknij przycisk menu
 u dołu panelu środowiska, a następnie kliknij pozycję Eksportuj środowisko.
u dołu panelu środowiska, a następnie kliknij pozycję Eksportuj środowisko. - Zapisz specyfikację jako plik obraz roboczy lub w woluminie Unity Catalog. Upewnij się, że masz uprawnienia do zapisu w miejscu docelowym lub eksport kończy się niepowodzeniem z powodu błędu
Forbidden.
Aby użyć niestandardowej specyfikacji środowiska w notatniku, wybierz pozycję Niestandardowy z menu rozwijanego Środowisko podstawowe, a następnie użyj ![]() , aby wybrać plik YAML.
, aby wybrać plik YAML.
Tworzenie typowych narzędzi do udostępniania w obszarze roboczym
W tym przykładzie narzędzie jest zapisywane w pliku w obszarze roboczym i instalowane jako zależność notesu bezserwerowego:
Utwórz folder z następującą strukturą. Upewnij się, że inni użytkownicy mają uprawnienia do odczytu tej ścieżki:
helper_utils/ ├── helpers/ │ └── __init__.py # your common functions live here ├── pyproject.tomlWypełnij
pyproject.tomlw następujący sposób:[project] name = "common_utils" version = "0.1.0"Dodaj funkcję do
init.pypliku. Przykład:def greet(name: str) -> str: return f"Hello, {name}!"W interfejsie użytkownika notatnika kliknij panel boczny Środowisko, ikonę

W sekcji Zależności kliknij pozycję Dodaj zależność , a następnie wprowadź ścieżkę pliku util. Na przykład:
/Workspace/helper_utils.Kliknij przycisk Zastosuj.
Teraz możesz użyć funkcji w notesie:
from helpers import greet
print(greet('world'))
Ten wynik to:
Hello, world!
Korzystanie ze środowiska uruchomieniowego AI (bezserwerowego procesora GPU)
Important
Środowisko uruchomieniowe sztucznej inteligencji jest w publicznej wersji zapoznawczej.
Wykonaj następujące kroki, aby skonfigurować środowisko uruchomieniowe AI obsługiwane przez przetwarzanie bezserwerowe procesora GPU w notesie Azure Databricks:
- W notesie kliknij menu rozwijane obliczeniowe u góry i wybierz pozycję Bezserwerowy procesor GPU.
- Kliknij Aby otworzyć okienko boczne Środowisko .
- Wybierz pozycję A10 z pola Akcelerator .
- W obszarze Środowisko podstawowe wybierz pozycję Standardowa dla domyślnego środowiska lub sztucznej inteligencji dla środowiska zoptymalizowanego pod kątem sztucznej inteligencji ze wstępnie zainstalowanymi bibliotekami uczenia maszynowego.
- Kliknij przycisk Zastosuj , a następnie potwierdź , że chcesz zastosować środowisko uruchomieniowe sztucznej inteligencji do środowiska notesu.
Aby uzyskać więcej informacji, zobacz AI Środowisko uruchomieniowe.
Korzystanie z obliczeń bezserwerowych z dużą ilością pamięci
Important
Ta funkcja jest dostępna w publicznej wersji testowej.
Jeśli w notatniku wystąpią błędy związane z brakiem pamięci, skonfiguruj go tak, aby korzystał z większej ilości pamięci. To ustawienie rozmiaru pamięci zwiększa rozmiar pamięci REPL używanej podczas uruchamiania kodu w notesie. Nie ma to wpływu na rozmiar pamięci sesji platformy Spark. Użycie bezserwerowe z wysoką ilością pamięci ma wyższy współczynnik emisji jednostek DBU niż standardowa pamięć.
Dostępne opcje pamięci to:
- Standardowa: łączna ilość pamięci wynosząca 16 GB.
- Wysoka: łączna ilość pamięci 32 GB.
Aby skonfigurować ustawienia pamięci laptopa:
- W interfejsie notesu kliknij panel boczny Środowisko.
- W obszarze Pamięćwybierz pozycję Duża pamięć.
- Kliknij przycisk Zastosuj.
To ustawienie pamięci dotyczy również zadań notatnika uruchamianych z użyciem preferencji pamięci notatnika. Aktualizowanie preferencji pamięci w notesie ma wpływ na następne uruchomienie zadania.
Wybieranie zasad użycia bezserwerowego
Important
Ta funkcja jest dostępna w publicznej wersji testowej.
Zasady użycia bezserwerowego umożliwiają organizacji stosowanie tagów niestandardowych w przypadku użycia bezserwerowego na potrzeby szczegółowego przypisywania rozliczeń.
Jeśli obszar roboczy korzysta z zasad użycia bezserwerowego, wybierz zasady, które chcesz zastosować do notesu. Jeśli użytkownik jest przypisany tylko do jednej zasady użycia bezserwerowego, te zasady są domyślnie stosowane.
Po nawiązaniu połączenia z bezserwerowym środowiskiem obliczeniowym wybierz zasady w okienku po stronie środowisko :
- W interfejsie notesu kliknij panel boczny Środowisko.
- W obszarze Zasady użycia bezserwerowego wybierz zasady użycia bezserwerowego, które chcesz zastosować do notesu.
- Kliknij przycisk Zastosuj.
Po zastosowaniu całe użycie notesu dziedziczy niestandardowe tagi zasady.
Note
Jeśli notes pochodzi z repozytorium Git lub nie ma przypisanych zasad użycia bezserwerowego, domyślnie zostanie przypisana ostatnio wybrana polityka użycia bezserwerowego podczas jego następnego podłączenia do bezserwerowych zasobów obliczeniowych.
Uwzględnij środowisko w eksportach plików źródłowych
W przypadku notatników języka Python w konfiguracji środowiska można włączyć lub wyłączyć opcję Uwzględnij w eksportach do plików źródłowych. Po włączeniu podstawowe środowisko i zależności są przechowywane w formacie PEP 723 w eksportach plików źródłowych. Pomaga to zachować konfigurację środowiska, gdy notesy są przechowywane w folderach Git lub pobierane jako pliki źródłowe.
Na przykład notatnik używający Standard v5 eksportuje konfigurację swojego środowiska jako wbudowane metadane na początku pliku:
# Databricks notebook source
# /// script
# [tool.databricks.environment]
# environment_version = "5"
# ///
print("Hello World!")
Resetowanie zależności środowiska
Jeśli notes jest połączony z obliczeniami bezserwerowymi, usługa Databricks automatycznie buforuje zawartość środowiska wirtualnego notesu. Oznacza to, że przy otwieraniu istniejącego notesu zazwyczaj nie trzeba ponownie instalować zależności języka Python określonych w panelu bocznym Environment, nawet jeśli notes utracił połączenie z powodu braku aktywności.
Buforowanie środowisk wirtualnych w Pythonie stosuje się również do zadań. Gdy zadanie jest uruchamiane, każde zadanie, które współdzieli ten sam zestaw zależności co zadanie ukończone w ramach tego samego przebiegu, kończy się szybciej, ponieważ pamięć podręczna zawiera już wymagane zależności.
Note
Jeśli zmienisz implementację niestandardowego pakietu Python używanego w zadaniu bezserwerowym, musisz również zaktualizować jego numer wersji, aby zadania mogły pobrać najnowszą implementację.
Aby wyczyścić pamięć podręczną środowiska i przeprowadzić nową instalację zależności określonych w okienku po stronie środowisko notesu dołączonego do obliczeń bezserwerowych, kliknij strzałkę obok pozycji Zastosuj , a następnie kliknij przycisk Resetuj do wartości domyślnych.
Jeśli zainstalujesz pakiety powodujące przerwanie lub zmianę podstawowego zeszytu lub środowiska Apache Spark, usuń problematyczne pakiety, a następnie zresetuj środowisko aplikacyjne. Uruchomienie nowej sesji nie powoduje wyczyszczenia całej pamięci podręcznej środowiska.
Konfigurowanie środowiska pod kątem zadań roboczych
Każde zadanie działa w izolowanym środowisku, które obejmuje środowisko bazowe oraz wszelkie dodatkowe biblioteki, które określisz. Środowisko podstawowe ustawia wersję środowiska uruchomieniowego Python i środowisko uruchomieniowe Języka Scala oraz wstępnie zainstalowane biblioteki. Zadania dziedziczą domyślny zestaw zainstalowanych bibliotek z wersji środowiska. Aby sprawdzić, co wchodzi w skład, zobacz sekcję Installed Python libraries lub Installed Java and Scala libraries w używanej environment version.
Biblioteki wstępnie zainstalowane można uzupełnić o biblioteki z plików obszaru roboczego, wolumenów Unity Catalog lub publicznych repozytoriów pakietów. Tylko zależności wymagane dla zadania są instalowane w czasie wykonywania.
Important
Używanie przetwarzania bezserwerowego dla zadań JAR jest w publicznej wersji zapoznawczej.
Important
Wybór zarządzanego środowiska podstawowego jest w fazie beta. Lista rozwijana Środowisko podstawowe w oknie dialogowym Konfigurowanie środowiska umożliwia wybranie środowisk udostępnianych przez usługę Databricks (takich jak Standardowa i ML) lub środowisk skonfigurowanych w obszarze roboczym. Bez tej funkcji okno dialogowe wyświetla zamiast tego listę rozwijaną Wersja środowiska. Administratorzy obszaru roboczego mogą włączyć tę funkcję na stronie Podglądy .
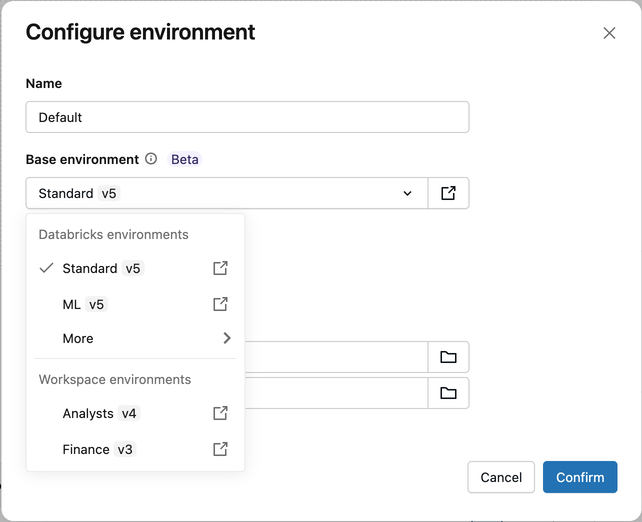
Konfigurowanie środowiska według typu zadania
Sposób konfigurowania środowisk w zadaniu zależy od typu zadania:
Zadania notatnika
Zadania notesu są domyślne dla środowiska notesu, które korzysta z własnego skonfigurowanego środowiska podstawowego i zależności notesu. Można to nadpisać ustawieniem środowiska na poziomie zadania.
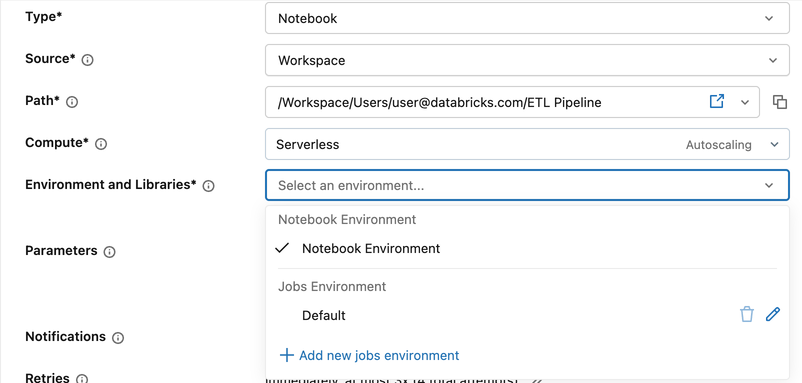
Aby skonfigurować środowisko na poziomie zadania:
- W konfiguracji zadania kliknij menu rozwijane Środowisko i biblioteki .
- W obszarze Środowisko zadań kliknij ikonę ołówka obok pozycji Domyślne lub kliknij pozycję + Dodaj nowe środowisko zadań.
- W oknie dialogowym Konfigurowanie środowiska wybierz z menu rozwijanego Środowisko podstawowe :
- środowiska Databricks: dostępne opcje Azure Databricks, takie jak Standard i ML.
- Środowiska obszarów roboczych: środowiska niestandardowe skonfigurowane przez administratora obszaru roboczego. Zobacz Zarządzanie środowiskami podstawowymi obszaru roboczego.
- Więcej: Poprzednie wersje i niestandardowe (określ plik YAML).
- W obszarze Zależności dodaj wszelkie dodatkowe biblioteki. Bibliotekę można określić w dowolnym formacie poprawnym dla pliku requirements.txt lub użyć ścieżki bezwzględnej do pliku w obszarze roboczym albo woluminu Unity Catalog.
- Kliknij przycisk Potwierdź.
Note
Jeśli w obszarze roboczym nie jest włączona funkcja wersji zapoznawczej podstawowego środowiska obszaru roboczego dla zadań, w oknie dialogowym Konfigurowanie środowiska zamiast opcji Środowisko podstawowe jest wyświetlana lista rozwijana Wersja środowiska.
Aby skonfigurować środowisko, wybierz wersję, a następnie kliknij pozycję + Dodaj bibliotekę. Możesz określić ścieżkę do pliku w obszarze roboczym (zaczynającą się od /Workspace/), ścieżkę woluminu w Unity Catalog (zaczynającą się od /Volumes/) lub odwołanie do pliku requirements (na przykład -r /Workspace/path/to/requirements.txt).
Zadania skryptu Python i pakietu wheel języka Python
Skrypty języka Python i zadania pakietów wheel języka Python wymagają skonfigurowanego środowiska.
sekcja 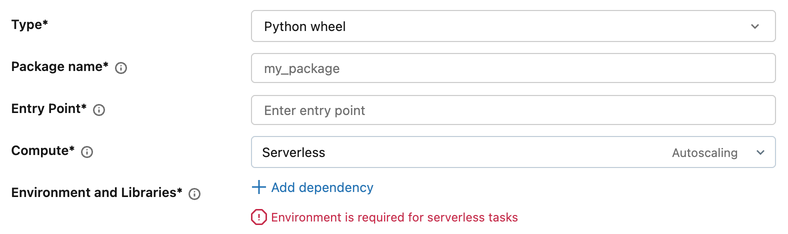
- W konfiguracji zadania w obszarze Środowisko i biblioteki kliknij pozycję + Dodaj zależność.
- W oknie dialogowym Konfigurowanie środowiska wybierz z menu rozwijanego Środowisko podstawowe :
- środowiska Databricks: dostępne opcje Azure Databricks, takie jak Standard i ML.
- Środowiska obszarów roboczych: środowiska niestandardowe skonfigurowane przez administratora obszaru roboczego. Zobacz Zarządzanie środowiskami podstawowymi obszaru roboczego.
- Więcej: Poprzednie wersje i niestandardowe (określ plik YAML).
- W obszarze Zależności dodaj wszelkie dodatkowe biblioteki.
- Kliknij przycisk Potwierdź.
Note
Jeśli w obszarze roboczym nie jest włączona funkcja wersji zapoznawczej podstawowego środowiska obszaru roboczego dla zadań, w oknie dialogowym Konfigurowanie środowiska zamiast opcji Środowisko podstawowe jest wyświetlana lista rozwijana Wersja środowiska.
Aby skonfigurować środowisko, wybierz wersję, a następnie kliknij pozycję + Dodaj bibliotekę. Możesz określić ścieżkę do pliku w obszarze roboczym (zaczynającą się od /Workspace/), ścieżkę woluminu w Unity Catalog (zaczynającą się od /Volumes/) lub odwołanie do pliku requirements (na przykład -r /Workspace/path/to/requirements.txt).
Zadania dbt
Zadania DBT używają środowiska na poziomie zadania na potrzeby konfiguracji biblioteki.
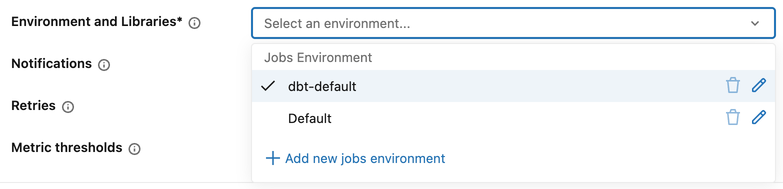
Aby skonfigurować środowisko na poziomie zadania:
- W konfiguracji zadania kliknij menu rozwijane Środowisko i biblioteki .
- W obszarze Środowisko zadań kliknij ikonę ołówka obok istniejącego środowiska lub kliknij pozycję + Dodaj nowe środowisko zadań.
- W oknie dialogowym Konfigurowanie środowiska wybierz z menu rozwijanego Środowisko podstawowe :
- środowiska Databricks: dostępne opcje Azure Databricks, takie jak Standard i ML.
- Środowiska obszarów roboczych: środowiska niestandardowe skonfigurowane przez administratora obszaru roboczego. Zobacz Zarządzanie środowiskami podstawowymi obszaru roboczego.
- Więcej: Poprzednie wersje i niestandardowe (określ plik YAML).
- W obszarze Zależności dodaj wszelkie dodatkowe biblioteki. Bibliotekę można określić w dowolnym formacie poprawnym dla pliku requirements.txt lub użyć ścieżki bezwzględnej do pliku w obszarze roboczym albo woluminu Unity Catalog.
- Kliknij przycisk Potwierdź.
Note
Jeśli w obszarze roboczym nie jest włączona funkcja wersji zapoznawczej podstawowego środowiska obszaru roboczego dla zadań, w oknie dialogowym Konfigurowanie środowiska zamiast opcji Środowisko podstawowe jest wyświetlana lista rozwijana Wersja środowiska.
Aby skonfigurować środowisko, wybierz wersję, a następnie kliknij pozycję + Dodaj bibliotekę. Możesz określić ścieżkę do pliku w obszarze roboczym (zaczynającą się od /Workspace/), ścieżkę woluminu w Unity Catalog (zaczynającą się od /Volumes/) lub odwołanie do pliku requirements (na przykład -r /Workspace/path/to/requirements.txt).
Zadania JAR
Bazowe środowiska obszaru roboczego nie są obsługiwane dla zadań JAR. Aby skonfigurować środowisko dla zadania JAR:
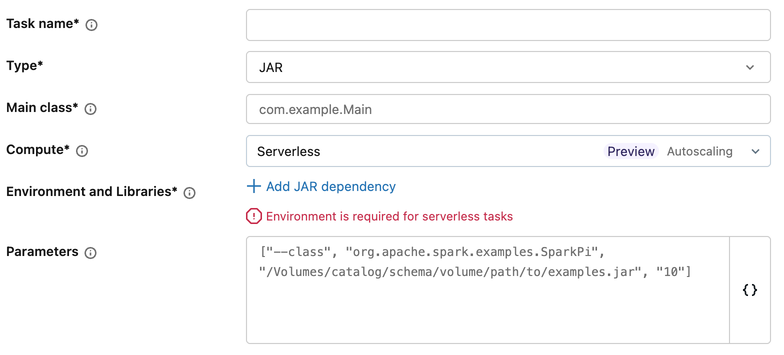
- W konfiguracji zadania w obszarze Środowisko i biblioteki kliknij pozycję + Dodaj zależność JAR.
- W oknie dialogowym Konfigurowanie środowiska :
- Opcjonalnie wprowadź ścieżkę do pliku YAML w polu Środowisko podstawowe .
- Wybierz wersję środowiska z menu rozwijanego Wersja środowiska .
- W sekcji JAR Dependencies dodaj ścieżki do plików JAR.
- Kliknij przycisk Potwierdź.
Aby utworzyć niestandardowe środowisko podstawowe oparte na języku YAML, zobacz Tworzenie niestandardowej specyfikacji środowiska.
Zgodność środowiska i obliczeń
Wybrane środowisko podstawowe musi być zgodne z typem obliczeniowym zadania. Na przykład środowisko utworzone na potrzeby obliczeń procesora GPU nie jest zgodne z obliczeniami procesora CPU. W interfejsie zadań niezgodne środowiska są niedostępne na liście rozwijanej środowiska bazowego.
Podczas konfigurowania zadania notatnika, typ obliczeń (CPU lub GPU) i środowisko podstawowe mogą pochodzić zarówno z ustawień zadania, jak i ustawień notatnika.
- W przypadku ustawienia akceleratora sprzętowego (GPU) na poziomie zadania należy również wybrać środowisko podstawowe na poziomie zadania. Nie można korzystać ze środowiska notatnika w połączeniu z akceleratorem przypisanym na poziomie zadania.
- Jeśli masz zadania odwołujące się do notatnika i zaktualizujesz typ zasobów obliczeniowych przywoływanego notatnika (na przykład z CPU na GPU), istniejące zadania mogą stać się niezgodne ze skonfigurowanym środowiskiem. Sprawdź ustawienia środowiska zadania po zmianie konfiguracji obliczeniowej notesu.
- Dla użytkowników interfejsu API: jeśli ustawisz środowisko bazowe na poziomie zadania, ale notatnik definiuje typ zasobów obliczeniowych, Azure Databricks weryfikuje zgodność w czasie wykonywania, a nie podczas tworzenia zadania. Jeśli konfiguracja jest niezgodna, uruchomienie kończy się niepowodzeniem z powodu błędu.