Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ewolucja schematu odnosi się do zdolności systemu do dostosowywania się do zmian w strukturze danych w czasie. Te zmiany są powszechne podczas pracy z półustrukturyzowanymi danymi, strumieniami zdarzeń lub źródłami zewnętrznymi, w których dodawane są nowe pola, przy przesunięciach typów danych lub ewoluowaniu struktur zagnieżdżonych.
Typowe zmiany obejmują:
- Nowe kolumny: Dodatkowe pola, które nie zostały wcześniej zdefiniowane, czasami z niestandardową wartością wypełniania.
-
Zmiana nazwy kolumny: zmiana nazwy kolumny, na przykład z
namenafull_name. - Porzucone kolumny: usuwanie kolumn ze schematu tabeli.
-
Rozszerzanie typu: zmiana typu kolumny na szerszą. Na przykład
INTpole staje sięDOUBLE. -
Inne zmiany typu: zmiana typu kolumny. Na przykład
INTpole staje sięSTRING.
Obsługa ewolucji schematu ma kluczowe znaczenie dla tworzenia odpornych, długotrwałych potoków, które mogą pomieścić zmieniające się dane bez częstych aktualizacji ręcznych.
Components
Ewolucja schematu usługi Azure Databricks obejmuje cztery główne kategorie składników, z których każda obsługuje zmiany schematu niezależnie:
- Łączniki: składniki, które pozyskiwają dane ze źródeł zewnętrznych. Należą do nich łączniki Auto Loader, Kafka, Kinesis i Lakeflow.
-
Analizatory formatów: funkcje dekodujące nieprzetworzone formaty, w tym
from_json,from_avro,from_xmlifrom_protobuf. - Silniki: Silniki przetwarzania, które wykonują zapytania, w tym przetwarzanie strumieniowe danych.
- Zestawy danych: tabele przesyłania strumieniowego, zmaterializowane widoki, tabele delty i widoki, które utrwalają i obsługują dane.
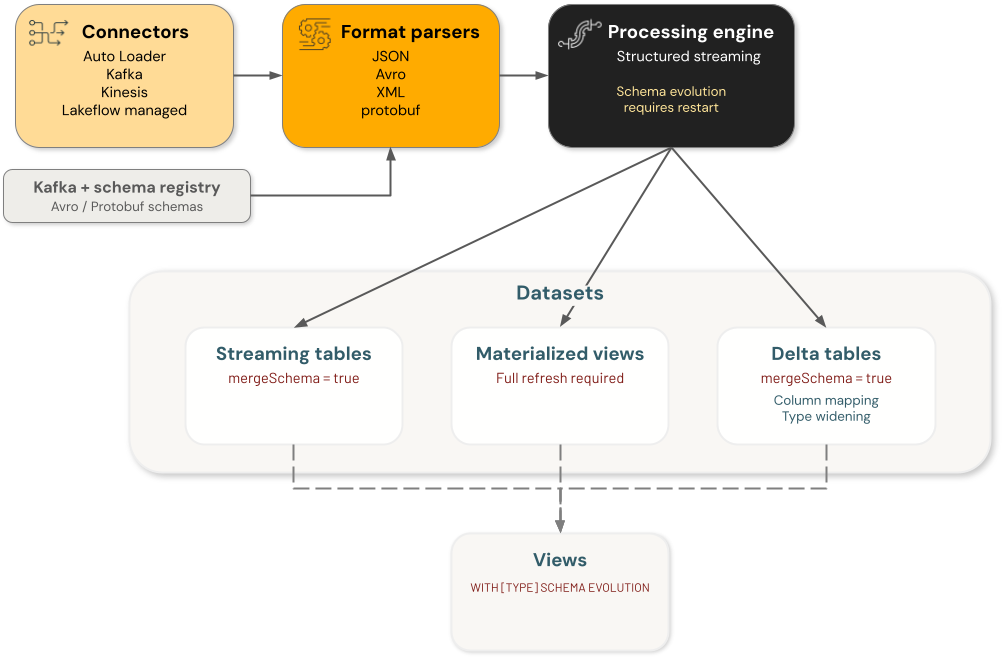
Każdy składnik ewolucji schematu architektury danych jest niezależny. Odpowiadasz za skonfigurowanie ewolucji schematu w poszczególnych składnikach w celu osiągnięcia żądanego zachowania w przepływie przetwarzania danych.
Na przykład w przypadku używania automatycznego modułu ładującego do pozyskiwania danych do tabeli delty istnieją dwa utrwalone schematy — jeden jest zarządzany przez moduł automatycznego ładowania w swojej lokalizacji schematu, a drugi jest schematem docelowej tabeli delty. W stabilnym stanie te dwa są takie same. Gdy moduł automatycznego ładowania ewoluuje swój schemat na podstawie danych przychodzących, tabela delty musi również ewoluować jego schemat lub zapytanie kończy się niepowodzeniem. W takim przypadku można (a) zaktualizować docelowy schemat tabeli delty, włączając ewolucję schematu lub używając bezpośredniego polecenia DDL lub (b) wykonaj pełne ponowne zapisywanie docelowej tabeli delty.
Obsługa ewolucji schematu przez łącznik
W poniższych sekcjach opisano, jak każdy składnik usługi Azure Databricks obsługuje różne typy zmian schematu.
Automatyczny ładownik
Moduł automatycznego ładowania obsługuje zmiany kolumn i rozszerzanie typu. Skonfiguruj automatyczną ewolucję schematu za pomocą polecenia cloudFiles.schemaEvolutionMode i rescuedDataColumn. Można ręcznie ustawić schemaHints lub niezmienny schema. Gdy automatycznie ewoluuje się schemat, strumień początkowo zawodzi. Po ponownym uruchomieniu jest używany schemat ewoluowany. Zobacz Jak działa ewolucja schematu modułu automatycznego ładowania?.
-
Nowe kolumny: Obsługiwane w zależności od wyboru
schemaEvolutionMode. Wystąpiło niepowodzenie wymagające ręcznego ponownego uruchomienia, aby dodać nowe kolumny do schematu. -
Zmiana nazwy kolumny: Obsługiwane, w zależności od wybranego elementu
schemaEvolutionMode. Przemianowana kolumna jest traktowana jako nowo dodana kolumna, a stara kolumna jest wypełniana symbolemNULLdla nowych wierszy. Niepowodzenie z ręcznym ponownym uruchomieniem wymaganym do zaktualizowania schematu. -
Usunięte kolumny: obsługiwane. Traktowane jako usuwanie nietrwałe, gdzie nowe wiersze usuniętej kolumny są ustawione na
NULL. -
Rozszerzanie typu: Jest obsługiwane w środowisku Databricks Runtime 16.4 lub nowszym przy ustawionej wartości
schemaEvolutionModeaddNewColumnsWithTypeWidening. Obsługiwane zmiany typu danych są automatycznie rozszerzane. Zmiany nieobsługiwanych typów są rejestrowane w elemencierescuedDataColumn. Zobacz Automatyczne rozszerzanie typu za pomocą "Auto Loader". -
Inne zmiany typu: nieobsługiwane. Zmiany typu są przechwytywane w
rescuedDataColumnobiekcie, jeślirescueDataColumnzostał ustawiony ischemaEvolutionModeustawiony narescue. W przeciwnym razie wymaga ręcznej zmiany schematu.
Łącznik delta
Łącznik delta może obsługiwać ewolucję schematu. W przypadku odczytywania z tabeli delty z włączonym mapowaniem kolumn i elementem schemaTrackingLocation obsługuje ewolucję schematu na potrzeby zmiany nazw kolumn i porzuconych kolumn. Należy ustawić poprawną konfigurację platformy Spark dla każdej z tych odpowiednich zmian, aby rozwijać schemat bez zatrzymywania strumienia. W przeciwnym razie strumień ewoluuje w śledzonym schemacie za każdym razem, gdy zostanie wykryta zmiana, a następnie zatrzyma się. Następnie należy ręcznie zrestartować zapytanie strumieniowe, aby wznowić przetwarzanie.
-
Nowe kolumny: obsługiwane. Po
mergeSchemawłączeniu nowe kolumny są dodawane automatycznie. W przeciwnym razie zapytanie kończy się niepowodzeniem i należy ponownie uruchomić strumień, aby dodać nowe kolumny do schematu, ale tabela delty nie wymaga ponownego zapisania. -
Zmiana nazwy kolumny: obsługiwane. Po
mergeSchemawłączeniu zmiana nazwy jest obsługiwana automatycznie. W przeciwnym razie można rozwijać schemat w zapytaniu przesyłanym strumieniowo przy użyciu konfiguracjispark.databricks.delta.streaming.allowSourceColumnRenameplatformy Spark. -
Usunięte kolumny: obsługiwane. Włączenie
mergeSchemasprawia, że porzucone kolumny są automatycznie obsługiwane. W przeciwnym razie można rozwijać schemat w zapytaniu przesyłanym strumieniowo przy użyciu konfiguracjispark.databricks.delta.streaming.allowSourceColumnDropplatformy Spark. -
Rozszerzanie typu: obsługiwane w środowisku Databricks Runtime 16.4 LTS lub nowszym. W przypadku włączenia
mergeSchemaoraz rozszerzenia typu w tabeli docelowej, zmiany typu są obsługiwane automatycznie. Można włączyć rozszerzanie typu za pomocą właściwości tabelitype widening. - Inne zmiany typu: nieobsługiwane.
Łączniki SaaS i CDC
Łączniki SaaS i CDC zmieniają schemat automatycznie po zmianie kolumn. Jest to obsługiwane za pośrednictwem automatycznego ponownego uruchamiania po wykryciu zmiany. Zmiany typu wymagają pełnego odświeżenia.
- Nowe kolumny: obsługiwane. Zapytanie jest automatycznie uruchamiane ponownie, aby rozwiązać niezgodność schematu.
- Zmiana nazwy kolumny: obsługiwane. Zapytanie jest automatycznie uruchamiane ponownie, aby rozwiązać niezgodność schematu. Zmieniona nazwa kolumny jest traktowana jako nowa kolumna dodana.
-
Usunięte kolumny: obsługiwane. Usunięte kolumny są traktowane jako miękkie usuwanie, gdzie nowe wiersze dla usuniętej kolumny są ustawione na
NULL. - Rozszerzanie typu: niewspierane. Aktualizacja schematu wymaga pełnego odświeżenia.
- Inne zmiany typu: nieobsługiwane. Aktualizacja schematu wymaga pełnego odświeżenia.
Łączniki Kinesis, Kafka, Pub/Sub i Pulsar
Nie jest obsługiwana żadna natywna ewolucja schematu. Każda funkcja łącznika zwraca obiekt binarny typu blob. Ewolucja schematu jest obsługiwana przez analizator formatu.
- Nowe kolumny: obsługiwane przez analizator formatu.
- Zmiana nazwy kolumny: obsługiwane przez analizator formatu.
- Porzucone kolumny: obsługiwane przez analizator formatu.
- Rozszerzenie typu: obsługiwane przez analizator formatu.
- Inne zmiany typu: obsługiwane przez analizator formatu.
Obsługa ewolucji schematu przez analizator formatów
from_json Parser
Analizator from_json nie obsługuje ewolucji schematu. Należy ręcznie zaktualizować schemat. W przypadku korzystania z from_json potoków deklaratywnych platformy Spark w usłudze Lakeflow można włączyć automatyczną ewolucję schematu za pomocą poleceń schemaLocationKey i schemaEvolutionMode.
- Nowe kolumny: po włączeniu automatycznej ewolucji schematu zachowuje się tak jak Auto Loader.
- Zmiana nazw kolumn: po włączeniu automatycznej ewolucji schematu zachowuje się tak, jak Auto Loader.
- Upuszczone kolumny: Gdy automatyczna ewolucja schematu jest włączona, zachowuje się tak jak Auto Loader.
- Rozszerzanie typu: Po włączeniu automatycznej ewolucji schematu zachowuje się tak jak Auto Loader.
- Inne zmiany typu: Gdy włączona jest automatyczna ewolucja schematu, działa to jak Auto Loader.
from_avroanalizatory i from_protobuf
Analizatory from_avro i from_protobuf zachowują się tak samo. Schemat można pobrać z rejestru schematów confluent lub użytkownik może podać schemat i ręcznie zaktualizować schemat. Nie istnieje pojęcie ewolucji schematu w obrębie from_avro lub from_protobuf funkcji; musi być obsługiwane przez silnik wykonawczy i rejestr schematów.
- Nowe kolumny: obsługiwane przez rejestr schematów Confluent. W przeciwnym razie użytkownik musi ręcznie zaktualizować schemat.
- Zmiana nazwy kolumny: obsługiwane w Confluent Schema Registry. W przeciwnym razie użytkownik musi ręcznie zaktualizować schemat.
- Usunięte kolumny: obsługiwane w rejestrze schematów Confluent. W przeciwnym razie użytkownik musi ręcznie zaktualizować schemat.
- Rozszerzanie typu: obsługiwane w Rejestrze Schematów Confluent. W przeciwnym razie użytkownik musi ręcznie zaktualizować schemat.
- Inne zmiany typu: obsługiwane w Rejestrze Schematów Confluent. W przeciwnym razie użytkownik musi ręcznie zaktualizować schemat.
from_csvanalizatory i from_xml
Analizatory from_csv i from_xml nie obsługują ewolucji schematu.
- Nowe kolumny: nieobsługiwane
- Zmiana nazwy kolumny: nieobsługiwane
- Usunięte kolumny: nieobsługiwane
- Rozszerzanie typu: nieobsługiwane
- Inne zmiany typu: nieobsługiwane
Obsługa zmiany schematu przez silnik
Przesyłanie strumieniowe ze strukturą
Schemat zapytania strumieniowego jest zablokowany w fazie planowania, a wszystkie mikropartie używają tego planu bez ponownego planowania. Jeśli schemat źródłowy zmieni się w połowie wykonywania, zapytanie zakończy się niepowodzeniem, a użytkownik musi ponownie uruchomić zapytanie przesyłane strumieniowo, aby platforma Spark mogła ponownie zaplanować nowy schemat.
Zestaw danych, do którego zapisuje strumień, musi również obsługiwać ewolucję schematu.
- Nowe kolumny: obsługiwane. Zapytanie kończy się niepowodzeniem i należy ponownie uruchomić strumień, aby rozwiązać niezgodność schematu.
- Zmiana nazwy kolumny: obsługiwane. Zapytanie kończy się niepowodzeniem i należy ponownie uruchomić strumień, aby rozwiązać niezgodność schematu.
- Usunięte kolumny: obsługiwane. Zapytanie kończy się niepowodzeniem i należy ponownie uruchomić strumień, aby rozwiązać niezgodność schematu.
- Rozszerzanie typu: obsługiwane. Zapytanie kończy się niepowodzeniem i należy ponownie uruchomić strumień, aby rozwiązać niezgodność schematu.
- Inne zmiany typu: obsługiwane. Zapytanie kończy się niepowodzeniem i należy ponownie uruchomić strumień, aby rozwiązać niezgodność schematu.
Ewolucja schematu według zestawu danych
Streamingowe tabele
Tabele strumieniowe domyślnie obsługują zachowanie ewolucji schematu łączenia. Aktualizacja schematu nie wymaga ręcznego ponownego uruchamiania, ale dowolne zmiany schematu wymagają pełnego odświeżenia.
- Nowe kolumny: obsługiwane. Zapytanie jest automatycznie uruchamiane ponownie, aby rozwiązać niezgodność schematu.
- Zmiana nazwy kolumny: obsługiwane. Zapytanie jest uruchamiane ponownie, aby rozwiązać niezgodność schematu. Zmieniona nazwa kolumny jest traktowana jako nowa kolumna dodana.
- Usunięte kolumny: obsługiwane. Usunięte kolumny są traktowane jako miękkie usuwanie, gdzie nowe wiersze dla usuniętej kolumny przyjmują wartość NULL.
- Rozszerzanie typu: obsługiwane. Rozszerzenie typu musi być włączone na poziomie potoku lub bezpośrednio w tabeli. Zobacz poszerzanie typu w deklaratywnych potokach Lakeflow Spark.
- Inne zmiany typu: nieobsługiwane. Aktualizacja schematu wymaga pełnego odświeżenia.
Zmaterializowane widoki
Każda aktualizacja schematu lub definiującego zapytania wyzwala pełną ponowną kompilację zmaterializowanego widoku.
- Nowe kolumny: wywołane pełne przeliczenie.
- Zmiana nazwy kolumny: wyzwolono pełną ponowną kompilację.
- Porzucone kolumny: wyzwolono pełną ponowną kompilację.
- Rozszerzenie typu: zainicjowane pełne przeliczenie.
- Inne zmiany typu: Wyzwolono pełne przeliczenie.
Tabele Delta
Delta tables obsługują różne konfiguracje do aktualizowania schematu tabeli, w tym zmianę nazw, usuwanie i zmianę typu kolumn bez ponownego zapisywania danych tabeli. Obsługiwane konfiguracje obejmują ewolucję schematu łączenia, mapowanie kolumn, rozszerzanie typu i zastępowanie schematu.
- Nowe kolumny: obsługiwane. Automatycznie ewoluuje po włączeniu ewolucji schematu scalania bez konieczności ponownego zapisywania tabeli delty. Jeśli ewolucja schematu scalania nie jest włączona, aktualizacje kończą się niepowodzeniem.
-
Zmiana nazwy kolumny: obsługiwane. Można zmienić nazwę za pomocą poleceń ręcznych
ALTER TABLE DDLz włączonym mapowaniem kolumn. Nie wymaga ponownego zapisywania tabeli delty. -
Usunięte kolumny: obsługiwane. Może usuwać kolumny za pomocą poleceń ręcznych
ALTER TABLE DDLz włączonym mapowaniem kolumn. Nie wymaga ponownego zapisywania tabeli delty. -
Rozszerzanie typu: obsługiwane. Automatycznie stosuje zmianę typu po włączeniu rozszerzania typu i ewolucji schematu scalania. Kolumny można rozszerzać za pomocą ręcznych poleceń
ALTER TABLE DDL, gdy jest włączone rozszerzanie typu. Bez skonfigurowania dowolnego z elementów operacje kończą się niepowodzeniem. Zobacz Rozszerzenie typów z automatyczną ewolucją schematu. -
Inne zmiany typu: obsługiwane, ale wymaga pełnego ponownego zapisywania tabeli delty. Należy włączyć funkcję
overwriteSchema, która umożliwia pełne ponowne zapisywanie tabeli delty. W przeciwnym razie operacje kończą się niepowodzeniem.
Views
Jeśli widok ma column_list element, który nie jest zgodny z nowym schematem lub ma zapytanie, którego nie można przeanalizować, widok staje się nieprawidłowy. Jeśli tak nie jest, możesz włączyć ewolucję schematu z SCHEMA TYPE EVOLUTION dla zmian typu oraz dla nowych, zmienionych i porzuconych kolumn z SCHEMA EVOLUTION (co jest nadzbiorem ewolucji typu).
-
Nowe kolumny: obsługiwane. W
SCHEMA EVOLUTIONtrybie widok automatycznie ewoluuje bez żadnej interwencji ręcznej, jeśli nie ma jawnegocolumn_list. W przeciwnym razie widok może stać się nieprawidłowy i użytkownik nie może go wysłać do niego zapytania. -
Zmiana nazw kolumn: obsługiwane. W
SCHEMA EVOLUTIONtrybie widok automatycznie ewoluuje bez żadnej interwencji ręcznej, jeśli nie ma jawnegocolumn_list. W przeciwnym razie widok może stać się nieprawidłowy. -
Usunięte kolumny: obsługiwane. W
SCHEMA EVOLUTIONtrybie widok automatycznie ewoluuje bez żadnej interwencji ręcznej, jeśli nie ma jawnegocolumn_list. W przeciwnym razie widok może stać się nieprawidłowy. -
Rozszerzanie typu: obsługiwane. W
SCHEMA TYPE EVOLUTIONtrybie widok automatycznie ewoluuje pod kątem zmian typu. WSCHEMA EVOLUTIONtrybie widok automatycznie ewoluuje bez żadnej interwencji ręcznej, jeśli nie ma jawnegocolumn_list. W przeciwnym razie widok może stać się nieprawidłowy. -
Inne zmiany typu: obsługiwane. W
SCHEMA TYPE EVOLUTIONtrybie widok automatycznie ewoluuje pod kątem zmian typu. WSCHEMA EVOLUTIONtrybie widok automatycznie ewoluuje bez żadnej interwencji ręcznej, jeśli nie ma jawnegocolumn_list. W przeciwnym razie widok może stać się nieprawidłowy.
Example
W poniższym przykładzie pokazano, jak pozyskiwać temat Kafka z ładunkami zakodowanymi w formacie Avro zarejestrowanymi w rejestrze schematów Confluent i zapisywać je w zarządzanej tabeli Delta z włączoną ewolucją schematu.
Pokazano kluczowe kwestie:
- Integracja z łącznikiem platformy Kafka.
- Dekoduj rekordy Avro przy użyciu from_avro z Rejestrem Schematów Kafka.
- Zarządzaj ewolucją schematu przez ustawienie
avroSchemaEvolutionMode. - Zapisywanie w tabeli delty z włączoną
mergeSchemaobsługą zezwalania na zmiany addytywne.
W kodzie przyjęto założenie, że masz temat Kafka korzystający z rejestru schematów Confluent, wyprowadzający dane zakodowane w formacie Avro.
# ----- CONFIG: fill these in -----
# Catalog and schema:
CATALOG = "<catalog_name>"
SCHEMA = "<schema_name>"
# Schema Registry:
# (This is where the producer evolves the schema)
SCHEMA_REG = "<schema registry endpoint>"
SR_USER = "<api key>"
SR_PASS = "<api secret>"
# Confluent Cloud: SASL_SSL broker:
BOOTSTRAP = "<server:ip>"
# Kafka topic:
TOPIC = "<topic>"
# ----- end: config -----
BRONZE_TABLE = f"{CATALOG}.{SCHEMA}.bronze_users"
CHECKPOINT = f"/Volumes/{CATALOG}/{SCHEMA}/checkpoints/bronze_users"
# Kafka auth (example for Confluent Cloud SASL/PLAIN over SSL)
KAFKA_OPTS = {
"kafka.security.protocol": "SASL_SSL",
"kafka.sasl.mechanism": "PLAIN",
"kafka.sasl.jaas.config": f"kafkashaded.org.apache.kafka.common.security.plain.PlainLoginModule required username='{SR_USER}' password='{SR_PASS}';"
}
# ----- Evolution knobs -----
# spark.conf.set("spark.databricks.delta.schema.autoMerge.enabled", value = True)
from pyspark.sql.functions import col
from pyspark.sql.avro.functions import from_avro
# Build reader
reader = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", BOOTSTRAP)
.option("subscribe", TOPIC)
.option("startingOffsets", "earliest")
)
# Attach Kafka auth options
for k, v in KAFKA_OPTS.items():
reader = reader.option(k, v)
# --- No native schema evolution supported. Returns a binary blob. ---
raw_df = reader.load()
# Decode Avro with Schema Registry
# --- The format parser handles updating the schema using the schema registry ---
decoded = from_avro(
data=col("value"),
jsonFormatSchema=None, # using SR
subject=f"{TOPIC}-value",
schemaRegistryAddress=SCHEMA_REG,
options={
"confluent.schema.registry.basic.auth.credentials.source": "USER_INFO",
"confluent.schema.registry.basic.auth.user.info": f"{SR_USER}:{SR_PASS}",
# Behavior on schema changes:
"avroSchemaEvolutionMode": "restart", # fail-fast so you can restart and adopt new fields
"mode": "FAILFAST"
}
).alias("payload")
bronze_df = raw_df.select(decoded, "timestamp").select("payload.*", "timestamp")
# Write to a managed Delta table as a STREAM
# --- Need to enable schema evolution separately for streaming to a Delta separately with mergeSchema --
(bronze_df.writeStream
.format("delta")
.option("checkpointLocation", CHECKPOINT)
.option("ignoreChanges", "true")
.outputMode("append")
.option("mergeSchema", "true") # only supports adding new columns. Renaming, dropping, and type changes need to be handled separately.
.trigger(availableNow=True) # Use availableNow trigger for Databricks SQL/Unity Catalog
.toTable(BRONZE_TABLE)
)