Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Przechwytywanie zmian danych (CDC) to wzorzec integracji danych, który przechwytuje zmiany wprowadzone w systemie źródłowym, takie jak wstawianie, aktualizacje i usuwanie. Te zmiany, reprezentowane jako lista, są często określane jako kanału informacyjnego CDC. Dane można przetwarzać znacznie szybciej, jeśli pracujesz na kanale informacyjnym CDC, zamiast odczytywać cały źródłowy zestaw danych. Transakcyjne bazy danych, takie jak SQL Server, MySQL i Oracle, generują źródła danych CDC. Tabele Delta generują własne źródło danych CDC, znane jako strumień danych o zmianach (CDF).
Na poniższym diagramie pokazano, że gdy wiersz w tabeli źródłowej zawierającej dane pracownika zostanie zaktualizowany, wygeneruje nowy zestaw wierszy w kanale informacyjnym CDC zawierającym tylko zmian. Każdy wiersz kanału informacyjnego CDC zwykle zawiera dodatkowe metadane, w tym operację, taką jak UPDATE i kolumnę, która może służyć do określania kolejności każdego wiersza w kanale informacyjnym CDC, dzięki czemu można obsługiwać aktualizacje poza kolejnością. Na przykład kolumna sequenceNum na poniższym diagramie określa kolejność wierszy w kanale informacyjnym CDC:
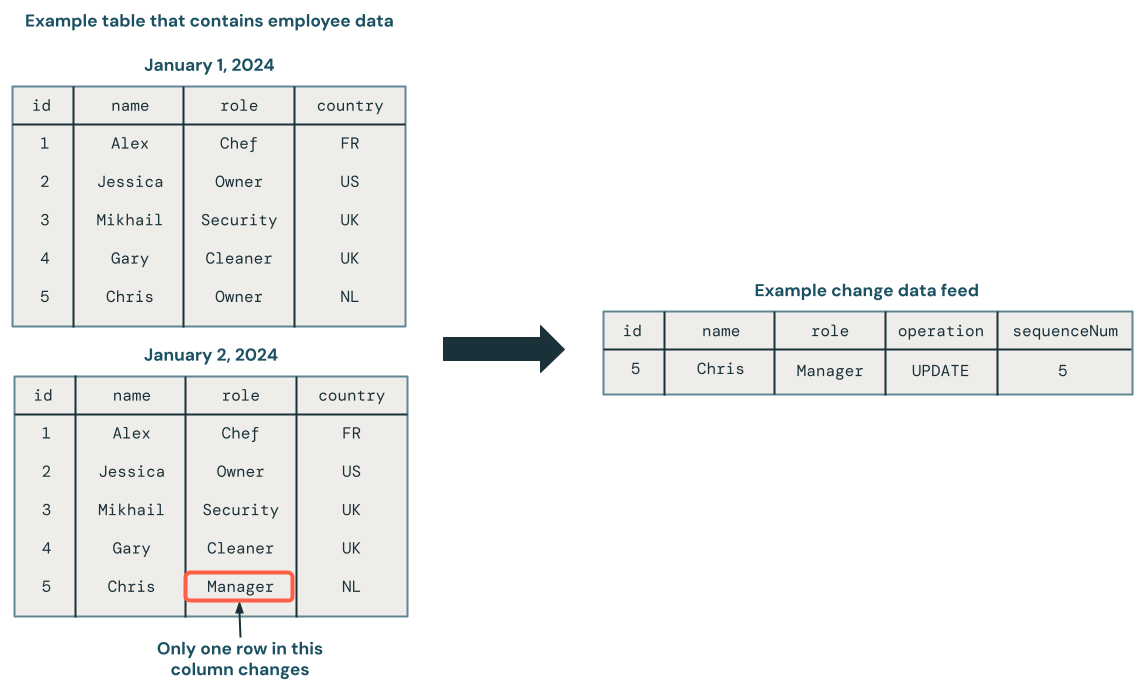
Przetwarzanie zestawienia danych zmian: zachowaj tylko najnowsze dane, a nie zachowaj historycznych wersji danych
Przetwarzanie zmienionego źródła danych nazywa się wolno zmieniające się wymiary (SCD). Podczas przetwarzania kopii zapasowej CDC musisz podjąć decyzję:
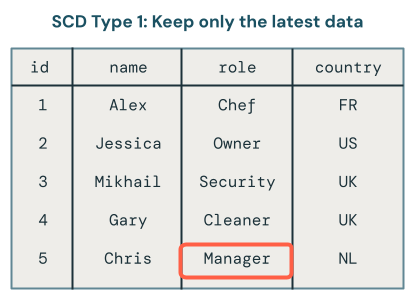
- Czy przechowujesz tylko najnowsze dane (czyli zastępowanie istniejących danych)? Jest to nazywane typem SCD 1.
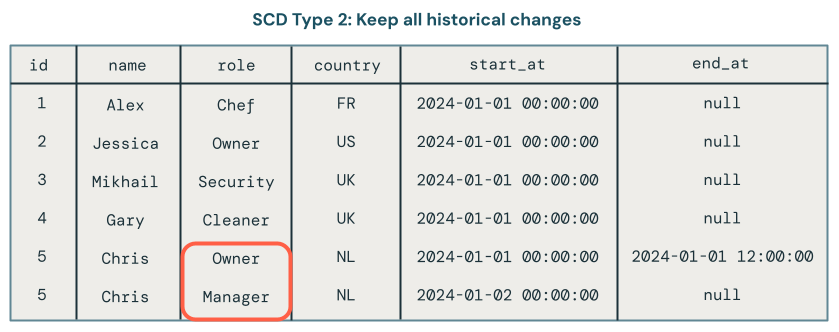
- Czy też zachowasz historię zmian danych? Jest to nazywane typem SCD 2.
Przetwarzanie typu 1 protokołu SCD obejmuje zastępowanie starych danych nowymi danymi za każdym razem, gdy nastąpi zmiana. Oznacza to, że nie jest przechowywana żadna historia zmian. Dostępna jest tylko najnowsza wersja danych. Jest to proste podejście i jest często używane, gdy historia zmian nie jest ważna, takich jak poprawianie błędów lub aktualizowanie pól niekrytycznych, takich jak adresy e-mail klientów.
Przetwarzanie typu 2 protokołu SCD utrzymuje historyczny rekord zmian danych przez utworzenie dodatkowych rekordów w celu przechwycenia różnych wersji danych w czasie. Każda wersja danych jest oznaczona znacznikiem czasu lub oznakowana metadanymi, które umożliwiają użytkownikom śledzenie, kiedy nastąpiła zmiana. Jest to przydatne, gdy ważne jest śledzenie ewolucji danych, takich jak śledzenie zmian adresów klientów w czasie na potrzeby analizy.
Przykłady przetwarzania typu 1 i typu 2 SCD przy użyciu deklaratywnych potoków Lakeflow
W przykładach w tej sekcji pokazano, jak używać typu SCD 1 i typu 2.
Krok 1. Przygotowywanie przykładowych danych
W tym przykładzie wygenerujesz przykładowy strumień danych CDC. Najpierw utwórz notes i wklej do niego następujący kod. Zaktualizuj zmienne na początku bloku kodu do katalogu i schematu, w którym masz uprawnienia do tworzenia tabel i widoków.
Ten kod tworzy nową tabelę delty zawierającą kilka rekordów zmian. Schemat jest następujący:
-
id— liczba całkowita, unikatowy identyfikator dla tego pracownika -
name— string, imię pracownika -
age— wiek pracownika jako liczba całkowita -
operation— typ zmiany (na przykładINSERT,UPDATElubDELETE) -
sequenceNum— liczba całkowita identyfikuje logiczną kolejność zdarzeń CDC w danych źródłowych. Deklaratywne potoki Lakeflow używają tego sekwencjonowania do obsługi zdarzeń zmiany, które docierają w nieodpowiedniej kolejności.
# update these to the catalog and schema where you have permissions
# to create tables and views.
catalog = "mycatalog"
schema = "myschema"
employees_cdf_table = "employees_cdf"
def write_employees_cdf_to_delta():
data = [
(1, "Alex", "chef", "FR", "INSERT", 1),
(2, "Jessica", "owner", "US", "INSERT", 2),
(3, "Mikhail", "security", "UK", "INSERT", 3),
(4, "Gary", "cleaner", "UK", "INSERT", 4),
(5, "Chris", "owner", "NL", "INSERT", 6),
# out of order update, this should be dropped from SCD Type 1
(5, "Chris", "manager", "NL", "UPDATE", 5)
(6, "Pat", "mechanic", "NL", "DELETE", 8),
(6, "Pat", "mechanic", "NL", "INSERT", 7)
]
columns = ["id", "name", "role", "country", "operation", "sequenceNum"]
df = spark.createDataFrame(data, columns)
df.write.format("delta").mode("overwrite").saveAsTable(f"{catalog}.{schema}.{employees_cdf_table}")
write_employees_cdf_to_delta()
Możesz wyświetlić podgląd tych danych przy użyciu następującego polecenia SQL:
SELECT *
FROM mycatalog.myschema.employees_cdf
Krok 2. Użyj typu SCD 1, aby zachować tylko najnowsze dane
Zalecamy używanie interfejsu AUTO CDC API w potokach deklaratywnych Lakeflow do przetwarzania strumienia zmian danych w tabeli typu 1 SCD.
- Utwórz nowy notatnik.
- Wklej do niego następujący kod.
- Utwórz i połącz się z potokiem danych.
Funkcja employees_cdf odczytuje tabelę, którą właśnie utworzyliśmy powyżej jako strumień, ponieważ interfejs API create_auto_cdc_flow, który będziesz używać do przetwarzania przechwytywania zmian danych, oczekuje danych wejściowych w formie strumienia zmian. Zawijasz go za pomocą decorator @dlt.view, ponieważ nie chcesz materializować tego strumienia w tabeli.
Następnie użyjesz dlt.create_target_table, aby utworzyć tabelę strumieniową zawierającą wynik przetwarzania tego strumienia danych zmiany.
Na koniec używasz dlt.create_auto_cdc_flow do przetworzenia strumienia danych o zmianach. Przyjrzyjmy się każdemu argumentowi:
-
target— docelowa tabela przesyłania strumieniowego, która została wcześniej zdefiniowana. -
source— widok strumienia rekordów zmian zdefiniowanych wcześniej. -
keys— Identyfikuje unikatowe wiersze w strumieniu zmian. Ponieważ używaszidjako unikatowego identyfikatora, wystarczy podaćidjako jedyną kolumnę identyfikującą. -
sequence_by— nazwa kolumny określająca logiczną kolejność zdarzeń CDC w danych źródłowych. Sekwencjonowanie jest potrzebne do obsługi zdarzeń zmiany, które docierają w niewłaściwej kolejności. PodajsequenceNumjako kolumnę sekwencjonowania. -
apply_as_deletes— ponieważ przykładowe dane zawierają operacje usuwania, należy użyćapply_as_deletes, aby wskazać, kiedy zdarzenie CDC powinno być traktowane jakoDELETE, a nie upsert. -
except_column_list— Zawiera listę kolumn, które nie mają być uwzględniane w tabeli docelowej. W tym przykładzie użyjesz tego argumentu do wykluczeniasequenceNumioperation. -
stored_as_scd_type— wskazuje typ SCD, którego chcesz użyć.
import dlt
from pyspark.sql.functions import col, expr, lit, when
from pyspark.sql.types import StringType, ArrayType
catalog = "mycatalog"
schema = "myschema"
employees_cdf_table = "employees_cdf"
employees_table_current = "employees_current"
employees_table_historical = "employees_historical"
@dlt.view
def employees_cdf():
return spark.readStream.format("delta").table(f"{catalog}.{schema}.{employees_cdf_table}")
dlt.create_target_table(f"{catalog}.{schema}.{employees_table_current}")
dlt.create_auto_cdc_flow(
target=f"{catalog}.{schema}.{employees_table_current}",
source=employees_cdf_table,
keys=["id"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 1
)
Uruchom ten potok, klikając przycisk Uruchom.
Następnie uruchom następujące zapytanie w edytorze SQL, aby sprawdzić, czy rekordy zmian zostały prawidłowo przetworzone:
SELECT *
FROM mycatalog.myschema.employees_current
Notatka
Aktualizacja "out-of-order" dla pracownika Chrisa została poprawnie odrzucona, ponieważ jego rola pozostaje ustawiona na Właściciela zamiast Menedżera.
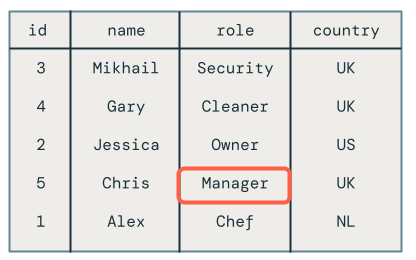
Krok 3. Przechowywanie danych historycznych przy użyciu typu SCD 2
W tym przykładzie utworzysz drugą tabelę docelową o nazwie employees_historical, która zawiera pełną historię zmian w rekordach pracowników.
Dodaj ten kod do pipeline. Jedyną różnicą jest to, że stored_as_scd_type jest ustawiona na 2 zamiast 1.
dlt.create_target_table(f"{catalog}.{schema}.{employees_table_historical}")
dlt.create_auto_cdc_flow(
target=f"{catalog}.{schema}.{employees_table_historical}",
source=employees_cdf_table,
keys=["id"],
sequence_by=col("sequenceNum"),
apply_as_deletes=expr("operation = 'DELETE'"),
except_column_list = ["operation", "sequenceNum"],
stored_as_scd_type = 2
)
Uruchom ten potok, klikając przycisk Uruchom.
Następnie uruchom następujące zapytanie w edytorze SQL, aby sprawdzić, czy rekordy zmian zostały prawidłowo przetworzone:
SELECT *
FROM mycatalog.myschema.employees_historical
Zobaczysz wszystkie zmiany pracowników, w tym tych pracowników, którzy zostali usunięci, takich jak Pat.
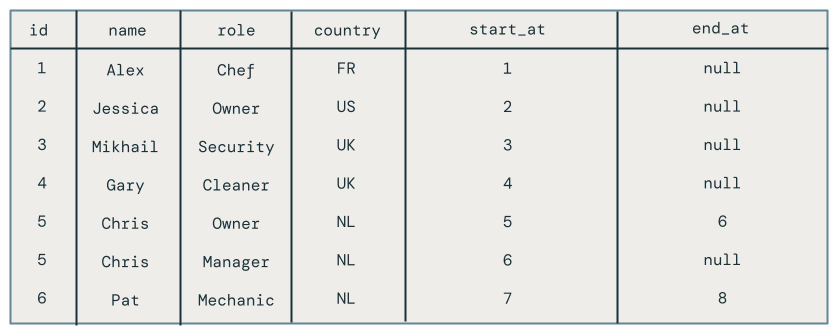
Krok 4. Czyszczenie zasobów
Po zakończeniu wyczyść zasoby, wykonując następujące kroki:
Usuń rurociąg
Notatka
Usunięcie potoku danych powoduje automatyczne usunięcie tabel
employeesiemployees_historical.- Kliknij pozycję Zadania i potoki, a następnie znajdź nazwę potoku do usunięcia.
- Kliknij
 W tym samym wierszu znajduje się następująca nazwa potoku, a następnie kliknij przycisk Usuń.
W tym samym wierszu znajduje się następująca nazwa potoku, a następnie kliknij przycisk Usuń.
Usuń notatnik.
Usuń tabelę zawierającą zestawienie danych zmian:
- Kliknij pozycję Nowe zapytanie >.
- Wklej i uruchom następujący kod SQL, dostosowując katalog i schemat odpowiednio:
DROP TABLE mycatalog.myschema.employees_cdf
Wady używania MERGE INTO i foreachBatch do przechwytywania danych zmian
Usługa Databricks udostępnia polecenie SQL MERGE INTO, którego można użyć z interfejsem API foreachBatch do aktualizowania i wstawiania wierszy w tabeli Delta. W tej sekcji opisano, jak ta technika może być używana w prostych przypadkach użycia, ale ta metoda staje się coraz bardziej złożona i krucha w przypadku zastosowania do rzeczywistych scenariuszy.
W tym przykładzie użyjesz tego samego przykładowego zestawienia danych zmian używanego w poprzednich przykładach.
Naiwna implementacja z MERGE INTO i foreachBatch
Utwórz notes i skopiuj do niego następujący kod. Zmień odpowiednio zmienne catalog, schemai employees_table. Zmienne catalog i schema powinny być ustawione na lokalizacje w Unity Catalog, gdzie można tworzyć tabele.
Po uruchomieniu notatnika wykonuje on następujące czynności:
- Tworzy tabelę docelową w
create_table. W przeciwieństwie docreate_auto_cdc_flow, który automatycznie obsługuje ten krok, należy określić schemat. - Odczytuje zestawienie danych zmian jako strumień. Każdy mikrobatch jest przetwarzany przy użyciu metody
upsertToDelta, która uruchamia polecenieMERGE INTO.
catalog = "jobs"
schema = "myschema"
employees_cdf_table = "employees_cdf"
employees_table = "employees_merge"
def upsertToDelta(microBatchDF, batchId):
microBatchDF.createOrReplaceTempView("updates")
microBatchDF.sparkSession.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
def create_table():
spark.sql(f"DROP TABLE IF EXISTS {catalog}.{schema}.{employees_table}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {catalog}.{schema}.{employees_table}
(id INT, name STRING, age INT, country STRING)
""")
create_table()
cdcData = spark.readStream.table(f"{catalog}.{schema}.{employees_cdf_table}")
cdcData.writeStream \
.foreachBatch(upsertToDelta) \
.outputMode("append") \
.start()
Aby wyświetlić wyniki, uruchom następujące zapytanie SQL:
SELECT *
FROM mycatalog.myschema.employees_merge
Niestety wyniki są niepoprawne, jak pokazano poniżej:
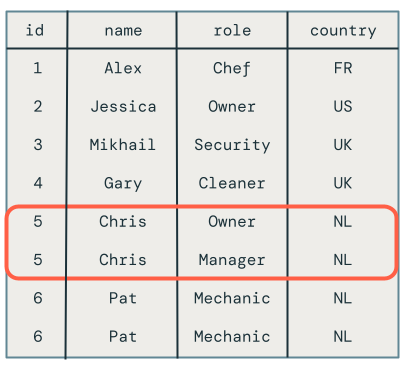
Wiele aktualizacji tego samego klucza w tej samej mikroparti
Pierwszym problemem jest to, że kod nie obsługuje wielu aktualizacji tego samego klucza w tej samej mikroserii. Na przykład użyjesz INSERT, aby wstawić pracownika Chrisa, a następnie zaktualizować jego rolę z właściciela na menedżera. Powinno to spowodować jeden wiersz, ale zamiast tego istnieją dwa wiersze.
Która zmiana wygrywa, gdy istnieje wiele aktualizacji tego samego klucza w mikropartii?
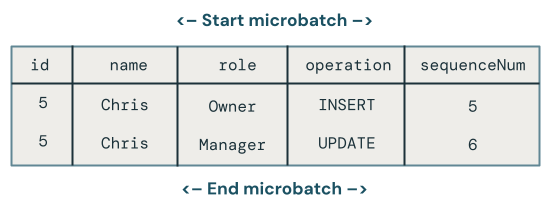
Logika staje się bardziej złożona. Poniższy przykład kodu pobiera najnowszy wiersz przez sequenceNum i łączy tylko te dane z tabelą docelową w następujący sposób:
- Grupuje według klucza podstawowego
id. - Pobiera wszystkie kolumny dla wiersza, który w partii dla tego klucza ma maksymalną liczbę
sequenceNum. - Eksploduje wiersz z powrotem.
Zaktualizuj metodę upsertToDelta, jak pokazano poniżej, a następnie uruchom kod:
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
Podczas wykonywania zapytania względem tabeli docelowej zobaczysz, że pracownik o nazwie Chris ma prawidłową rolę, ale nadal istnieją inne problemy do rozwiązania, ponieważ nadal usunięto rekordy wyświetlane w tabeli docelowej.
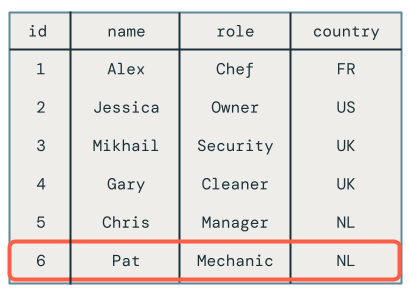
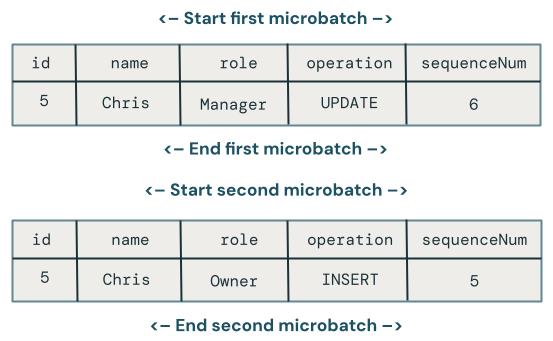
Aktualizacje nieuporządkowane w mikropartiach
W tej sekcji omówiono problem aktualizacji poza kolejnością w mikroseriach. Na poniższym diagramie przedstawiono problem: co, jeśli wiersz dla Chrisa ma operację UPDATE w pierwszej mikropartii, a potem INSERT w kolejnych mikropartiach? Kod nie obsługuje tego poprawnie.
Która zmiana wygrywa, gdy istnieją aktualizacje w niewłaściwej kolejności tego samego klucza w wielu mikropartiach?
Aby rozwiązać ten problem, rozwiń kod, aby przechowywać wersję w każdym wierszu w następujący sposób:
- Zapisz
sequenceNum, gdy wiersz został po raz ostatni zaktualizowany. - Dla każdego nowego wiersza sprawdź, czy znacznik czasu jest większy niż przechowywany, a następnie zastosuj następującą logikę:
- Jeśli wartość jest większa, użyj nowych danych z obiektu docelowego.
- W przeciwnym razie zachowaj dane w źródle.
Najpierw zaktualizuj metodę createTable do przechowywania sequenceNum , ponieważ użyjesz jej do obsługi wersji każdego wiersza:
def create_table():
spark.sql(f"DROP TABLE IF EXISTS {catalog}.{schema}.{employees_table}")
spark.sql(f"""
CREATE TABLE IF NOT EXISTS {catalog}.{schema}.{employees_table}
(id INT, name STRING, age INT, country STRING, sequenceNum INT)
""")
Następnie zaktualizuj upsertToDelta, aby obsługiwało wersje wierszy. Klauzula UPDATE SET w MERGE INTO musi obsługiwać każdą kolumnę oddzielnie.
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
Obsługa usuwania
Niestety kod nadal ma problem. Nie obsługuje ona operacji DELETE, co świadczy o tym, że pracownik Pat jest nadal w tabeli docelowej.
Załóżmy, że usunięcia docierają w tej samej mikropartii. Aby je obsłużyć, zaktualizuj ponownie metodę upsertToDelta, aby usunąć wiersz, gdy rekord zmiany danych wskazuje usunięcie, jak pokazano poniżej:
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED AND s.operation = 'DELETE' THEN DELETE
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
Obsługa aktualizacji przychodzących poza kolejność po usunięciach
Niestety, powyższy kod nadal nie jest do końca poprawny, ponieważ nie obsługuje przypadków, gdy DELETE jest poprzedzany przez nieuporządkowane UPDATE w mikropartycjach.
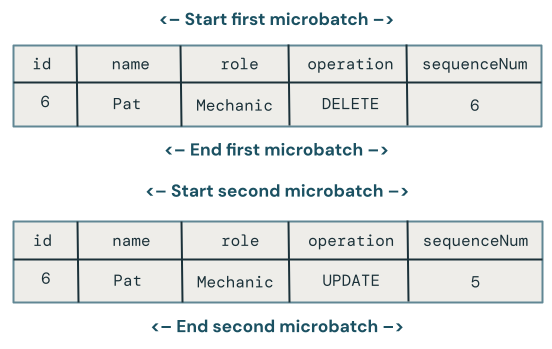
Algorytm do obsługi tego przypadku musi pamiętać usunięcia, aby mógł obsługiwać kolejne aktualizacje nie w kolejności. W tym celu:
- Zamiast natychmiast usuwać wiersze, usuń je logicznie ze znacznikiem czasu lub
sequenceNum. Wiersze usunięte nietrwale są oznaczone jako usunięte. - Przekieruj wszystkich użytkowników do widoku, który filtruje grobowce.
- Skompiluj zadanie oczyszczania, które usuwa grobowce w czasie.
Użyj następującego kodu:
def upsertToDelta(microBatchDF, batchId):
microBatchDF = microBatchDF.groupBy("id").agg(
max_by(struct("*"), "sequenceNum").alias("row")
).select("row.*").createOrReplaceTempView("updates")
spark.sql(f"""
MERGE INTO {catalog}.{schema}.{employees_table} t
USING updates s
ON s.id = t.id
WHEN MATCHED AND s.operation = 'DELETE' THEN UPDATE SET DELETED_AT=now()
WHEN MATCHED THEN UPDATE SET
name=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.name ELSE t.name END,
age=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.age ELSE t.age END,
country=CASE WHEN s.sequenceNum > t.sequenceNum THEN s.country ELSE t.country END
WHEN NOT MATCHED THEN INSERT *
""")
Użytkownicy nie mogą bezpośrednio używać tabeli docelowej, więc utwórz widok, który może wykonywać zapytania:
CREATE VIEW employees_v AS
SELECT * FROM employees_merge
WHERE DELETED_AT = NULL
Na koniec utwórz zadanie oczyszczania, które okresowo usuwa oznaczone jako usunięte wiersze.
DELETE FROM employees_merge
WHERE DELETED_AT < now() - INTERVAL 1 DAY