Wytyczne dotyczące jeziora
Wytyczne to reguły na poziomie zerowym, które definiują architekturę i wpływają na twoją architekturę. Aby utworzyć usługę data lakehouse, która pomaga firmie odnieść sukces teraz i w przyszłości, konsensus między uczestnikami projektu w organizacji ma kluczowe znaczenie.
Curate data and offer trusted data-as-products (Curate data and offer trusted data-as-products)
Curating data is essential to creating a high-value data lake for BI and ML/AI (Tworzenie bazy danych typu data lake o wysokiej wartości dla analizy biznesowej i uczenia maszynowego/sztucznej inteligencji). Traktuj dane takie jak produkt z przejrzystą definicją, schematem i cyklem życia. Upewnij się, że spójność semantyczna i jakość danych poprawia się od warstwy do warstwy, dzięki czemu użytkownicy biznesowi mogą w pełni ufać danym.
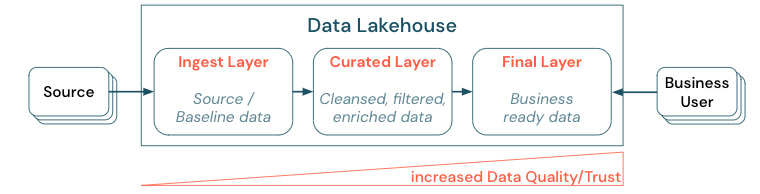
Curating data by establishing a layered (or multi-hop) architecture is a critical best practice for the lakehouse, ponieważ umożliwia zespołom danych struktury danych zgodnie z poziomami jakości i definiowanie ról i obowiązków na warstwę. Typowym podejściem do warstw jest:
- Warstwa pozyskiwania: dane źródłowe są pozyskiwane do magazynu lakehouse w pierwszej warstwie i powinny być tam utrwalane. Jeśli wszystkie dane podrzędne są tworzone na podstawie warstwy pozyskiwania, można w razie potrzeby ponownie skompilować kolejne warstwy z tej warstwy.
- Wyselekcjonowana warstwa: drugim celem warstwy jest utrzymywanie oczyszczonych, uściślionych, przefiltrowanych i zagregowanych danych. Celem tej warstwy jest zapewnienie solidnej, niezawodnej podstawy do analiz i raportów we wszystkich rolach i funkcjach.
- Warstwa końcowa: Trzecia warstwa jest tworzona wokół potrzeb biznesowych lub projektowych. Zapewnia inny widok jako produkty danych dla innych jednostek biznesowych lub projektów, przygotowywanie danych dotyczących potrzeb związanych z zabezpieczeniami (na przykład zanonimizowane dane) lub optymalizację pod kątem wydajności (ze wstępnie zagregowanymi widokami). Produkty danych w tej warstwie są postrzegane jako prawda dla firmy.
Potoki we wszystkich warstwach muszą mieć pewność, że są spełnione ograniczenia dotyczące jakości danych, co oznacza, że dane są dokładne, kompletne, dostępne i spójne przez cały czas, nawet podczas współbieżnych operacji odczytu i zapisu. Walidacja nowych danych odbywa się w momencie wprowadzania danych do wyselekcjonowanych warstw, a następujące kroki ETL działają w celu poprawy jakości tych danych. Jakość danych musi się poprawić w miarę postępu danych przez warstwy, a w związku z tym zaufanie do danych zwiększa się z punktu widzenia firmy.
Eliminowanie silosów danych i minimalizowanie przenoszenia danych
Nie twórz kopii zestawu danych z procesami biznesowymi opartymi na tych różnych kopiach. Kopie mogą stać się silosami danych, które nie są zsynchronizowane, co prowadzi do niższej jakości usługi Data Lake, a na koniec do nieaktualnych lub nieprawidłowych szczegółowych informacji. Ponadto w celu udostępniania danych partnerom zewnętrznym należy użyć mechanizmu udostępniania przedsiębiorstwa, który umożliwia bezpieczny bezpośredni dostęp do danych.
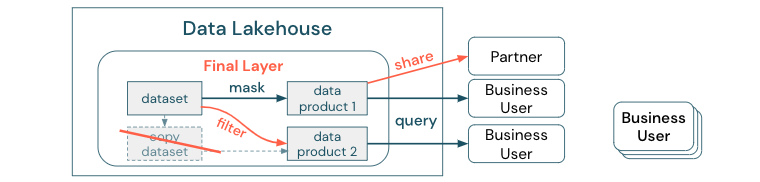
Aby wyjaśnić różnicę między kopią danych a silosem danych: autonomiczna lub wyrzucona kopia danych nie jest szkodliwa samodzielnie. Czasami konieczne jest zwiększenie elastyczności, eksperymentowania i innowacji. Jeśli jednak kopie te staną się operacyjne z produktami danych biznesowych podrzędnych zależnych od nich, stają się silosami danych.
Aby zapobiec silosom danych, zespoły danych zwykle próbują utworzyć mechanizm lub potok danych, aby zachować wszystkie kopie zsynchronizowane z oryginałem. Ponieważ jest to mało prawdopodobne, aby stało się to spójnie, jakość danych ostatecznie spada. Może to również prowadzić do wyższych kosztów i znacznej utraty zaufania przez użytkowników. Z drugiej strony kilka przypadków użycia biznesowych wymaga udostępniania danych partnerom lub dostawcom.
Ważnym aspektem jest bezpieczne i niezawodne udostępnianie najnowszej wersji zestawu danych. Kopie zestawu danych często nie są wystarczające, ponieważ mogą szybko wyjść z synchronizacji. Zamiast tego dane powinny być udostępniane za pośrednictwem narzędzi do udostępniania danych przedsiębiorstwa.
Demokratyzowanie tworzenia wartości za pomocą samoobsługi
Najlepsze rozwiązanie data lake nie może zapewnić wystarczającej wartości, jeśli użytkownicy nie mogą łatwo uzyskać dostępu do platformy lub danych dla swoich zadań analizy biznesowej i uczenia maszynowego/sztucznej inteligencji. Obniż bariery dostępu do danych i platform dla wszystkich jednostek biznesowych. Rozważ chude procesy zarządzania danymi i zapewnij samoobsługowy dostęp do platformy i danych bazowych.
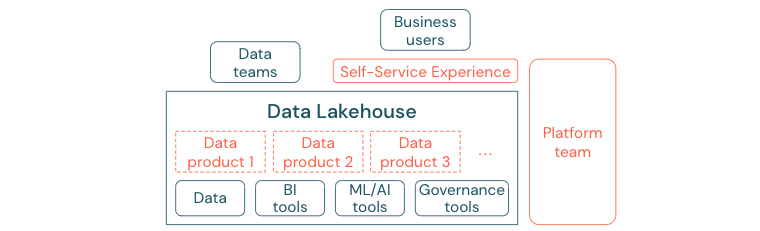
Firmy, które pomyślnie przeniosły się do kultury opartej na danych, będą się rozwijać. Oznacza to, że każda jednostka biznesowa uzyskuje decyzje od modeli analitycznych lub od analizowania własnych lub centralnie dostarczonych danych. W przypadku konsumentów dane muszą być łatwo odnajdywalne i bezpiecznie dostępne.
Dobrą koncepcją dla producentów danych jest "dane jako produkt": dane są oferowane i utrzymywane przez jedną jednostkę biznesową lub partnera biznesowego, takiego jak produkt i używane przez inne strony z odpowiednią kontrolą uprawnień. Zamiast polegać na centralnym zespole i potencjalnie powolnych procesach żądań, te produkty danych muszą zostać utworzone, oferowane, odnalezione i zużyte w środowisku samoobsługowym.
Jednak to nie tylko dane, które mają znaczenie. Demokratyzacja danych wymaga właściwych narzędzi, aby umożliwić wszystkim tworzenie lub używanie i zrozumienie danych. W tym celu usługa Data Lakehouse musi być nowoczesną platformą danych i sztucznej inteligencji, która zapewnia infrastrukturę i narzędzia do tworzenia produktów danych bez duplikowania nakładu pracy nad skonfigurowaniem innego stosu narzędzi.
Wdrażanie strategii zapewniania ładu danych w całej organizacji
Dane są krytycznym elementem zawartości każdej organizacji, ale nie można zapewnić wszystkim dostępu do wszystkich danych. Dostęp do danych musi być aktywnie zarządzany. Kontrola dostępu, inspekcja i śledzenie pochodzenia są kluczem do poprawnego i bezpiecznego użycia danych.
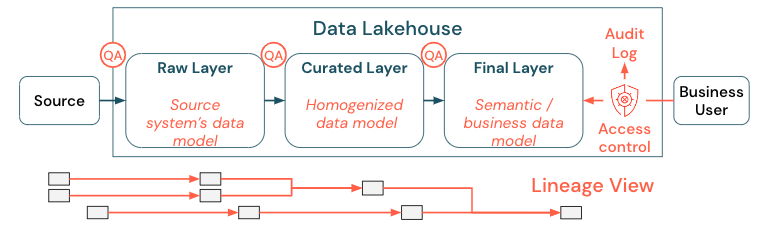
Nadzór nad danymi to szeroki temat. Jezioro obejmuje następujące wymiary:
Jakość danych
Najważniejszym wymaganiem wstępnym dla prawidłowych i znaczących raportów, wyników analizy i modeli jest wysoka jakość danych. Kontrola jakości (QA) musi istnieć wokół wszystkich kroków potoku. Przykłady implementacji tego rozwiązania obejmują kontrakty danych, spełnianie umów SLA, utrzymywanie stabilnych schematów i rozwijanie ich w kontrolowany sposób.
Wykaz danych
Innym ważnym aspektem jest odnajdywanie danych: użytkownicy wszystkich obszarów biznesowych, zwłaszcza w modelu samoobsługowym, muszą mieć możliwość łatwego odnajdywania odpowiednich danych. W związku z tym usługa Lakehouse potrzebuje wykazu danych, który obejmuje wszystkie dane związane z działalnością biznesową. Podstawowe cele wykazu danych są następujące:
- Upewnij się, że ta sama koncepcja biznesowa jest jednolicie wywoływana i zadeklarowana w całej firmie. Możesz traktować go jako model semantyczny w wyselekcjonowanych i końcowych warstwach.
- Dokładnie śledź pochodzenie danych, aby użytkownicy mogli wyjaśnić, jak te dane dotarły do ich bieżącego kształtu i formularza.
- Zachowaj metadane wysokiej jakości, które są równie ważne, jak same dane w celu odpowiedniego wykorzystania danych.
Kontrola dostępu
Ponieważ tworzenie wartości z danych w lakehouse odbywa się we wszystkich obszarach biznesowych, jezioro musi być zbudowane z zabezpieczeniami jako obywatel pierwszej klasy. Firmy mogą mieć bardziej otwarte zasady dostępu do danych lub ściśle przestrzegać zasady najniższych uprawnień. Niezależnie od tego kontrola dostępu do danych musi znajdować się w każdej warstwie. Ważne jest zaimplementowanie schematów uprawnień klasy precyzyjnej od samego początku (kontrola dostępu na poziomie kolumny i wiersza, kontrola dostępu oparta na rolach lub atrybutach). Firmy mogą zacząć od mniej rygorystycznych zasad. Jednak wraz ze wzrostem platformy lakehouse wszystkie mechanizmy i procesy dla bardziej zaawansowanego systemu bezpieczeństwa powinny już istnieć. Ponadto cały dostęp do danych w lakehouse musi być zarządzany przez dzienniki inspekcji z get-go.
Zachęcanie do otwartych interfejsów i otwartych formatów
Otwarte interfejsy i formaty danych mają kluczowe znaczenie dla współdziałania między usługą Lakehouse i innymi narzędziami. Upraszcza integrację z istniejącymi systemami, a także otwiera ekosystem partnerów, którzy zintegrowali swoje narzędzia z platformą.
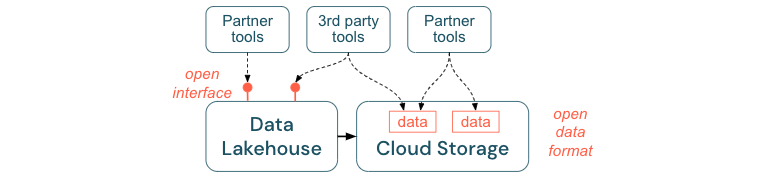
Otwarte interfejsy mają kluczowe znaczenie dla umożliwienia współdziałania i zapobiegania zależnościom od dowolnego pojedynczego dostawcy. Tradycyjnie dostawcy tworzyli zastrzeżone technologie i zamknięte interfejsy, które ograniczały przedsiębiorstwa w sposób, w jaki mogą przechowywać, przetwarzać i udostępniać dane.
Tworzenie otwartych interfejsów ułatwia tworzenie na przyszłość:
- Zwiększa to długowieczność i przenośność danych, dzięki czemu można ich używać z większą częścią aplikacji i w przypadku większej liczby przypadków użycia.
- Otwiera ekosystem partnerów, którzy mogą szybko wykorzystać otwarte interfejsy, aby zintegrować swoje narzędzia z platformą lakehouse.
Na koniec poprzez standaryzację otwartych formatów dla danych łączne koszty będą znacznie niższe; można uzyskać dostęp do danych bezpośrednio w magazynie w chmurze bez konieczności wprowadzania ich potoku za pośrednictwem zastrzeżonej platformy, która może spowodować wysokie koszty ruchu wychodzącego i obliczeń.
Kompilowanie w celu skalowania i optymalizowania pod kątem wydajności i kosztów
Dane nieuchronnie rosną i stają się coraz bardziej złożone. Aby wyposażyć organizację w przyszłe potrzeby, usługa Lakehouse powinna mieć możliwość skalowania. Na przykład powinno być możliwe łatwe dodawanie nowych zasobów na żądanie. Koszty powinny być ograniczone do rzeczywistego zużycia.
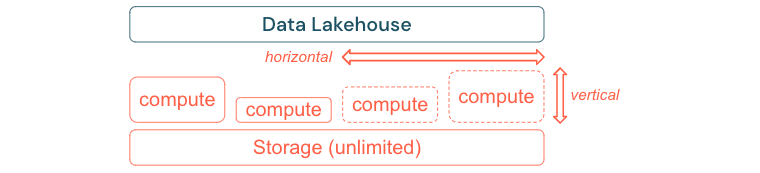
Standardowe procesy ETL, raporty biznesowe i pulpity nawigacyjne często mają przewidywalne zapotrzebowanie na zasoby z perspektywy pamięci i obliczeń. Jednak nowe projekty, zadania sezonowe lub nowoczesne podejścia, takie jak trenowanie modelu (rezygnacja, prognoza, konserwacja) generuje szczyty zapotrzebowania na zasoby. Aby umożliwić firmie wykonywanie wszystkich tych obciążeń, niezbędna jest skalowalna platforma do obsługi pamięci i obliczeń. Nowe zasoby muszą być łatwo dodawane na żądanie, a rzeczywiste zużycie powinno generować koszty. Gdy tylko szczyt się skończy, zasoby można zwolnić ponownie i odpowiednio zmniejszyć koszty. Często jest to określane jako skalowanie w poziomie (mniej lub więcej węzłów) i skalowanie w pionie (większe lub mniejsze węzły).
Skalowanie umożliwia również firmom zwiększenie wydajności zapytań przez wybranie węzłów z większą częścią zasobów lub klastrów z większą częścią węzłów. Jednak zamiast trwale dostarczać duże maszyny i klastry, można aprowizować je na żądanie tylko przez czas potrzebny do zoptymalizowania ogólnej wydajności do współczynnika kosztów. Innym aspektem optymalizacji jest magazyn a zasoby obliczeniowe. Ponieważ nie ma wyraźnej relacji między ilością danych i obciążeniami korzystającymi z tych danych (na przykład przy użyciu tylko części danych lub wykonywania intensywnych obliczeń na małych danych), dobrym rozwiązaniem jest rozliczanie się na platformie infrastruktury, która rozdziela magazyn i zasoby obliczeniowe.