Niezawodność usługi Data Lakehouse
Zasady architektury filaru niezawodności dotyczą zdolności systemu do odzyskiwania po awarii i kontynuowania działania.
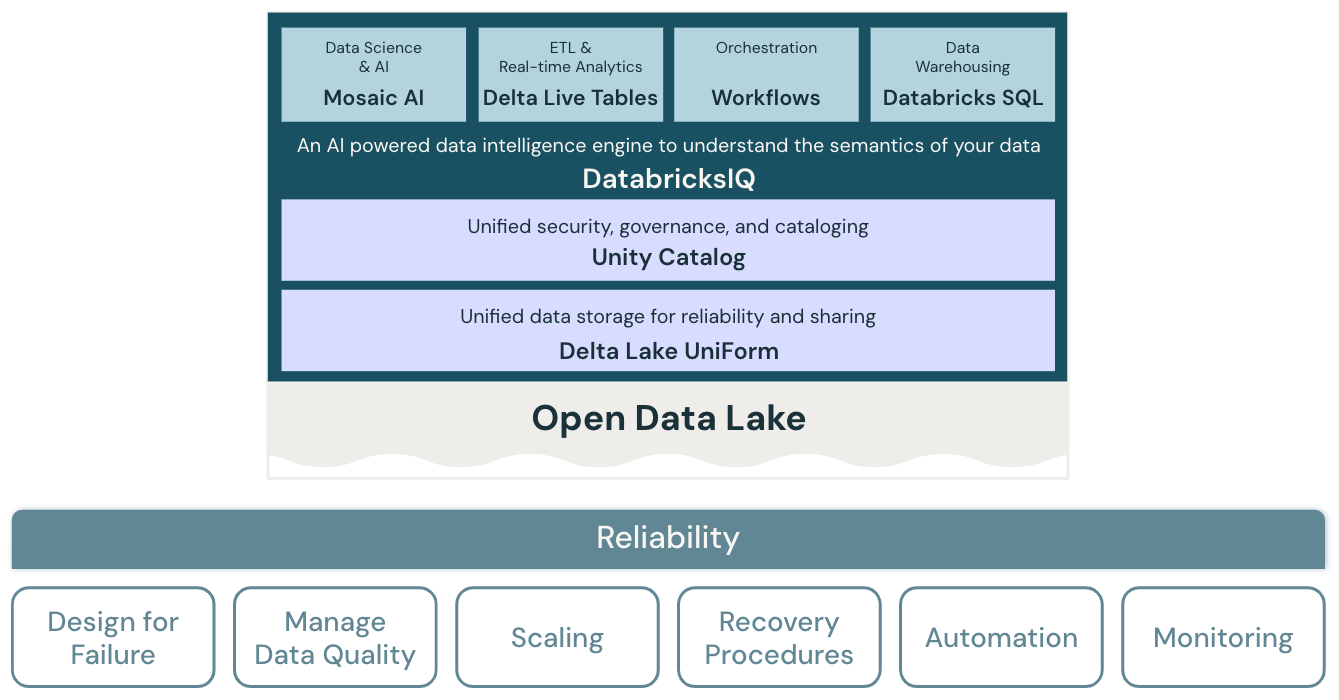
Zasady niezawodności
Projektowanie pod kątem awarii
W wysoce rozproszonym środowisku mogą wystąpić awarie. W przypadku platformy i różnych obciążeń — takich jak zadania przesyłania strumieniowego, zadania wsadowe, trenowanie modelu i zapytania analizy biznesowej — należy przewidzieć awarie i rozwiązania odporne na awarie, aby zwiększyć niezawodność. Koncentruje się na projektowaniu aplikacji w celu szybkiego odzyskiwania i, w najlepszym przypadku, automatycznie.
Zarządzanie jakością danych
Jakość danych ma podstawowe znaczenie dla uzyskiwania dokładnych i znaczących szczegółowych informacji z danych. Jakość danych ma wiele wymiarów, w tym kompletność, dokładność, ważność i spójność. Należy aktywnie zarządzać, aby poprawić jakość końcowych zestawów danych, aby dane służyły jako wiarygodne i wiarygodne informacje dla użytkowników biznesowych.
Projektowanie pod kątem skalowania automatycznego
Standardowe procesy ETL, raporty biznesowe i pulpity nawigacyjne często mają przewidywalne wymagania dotyczące zasobów pod względem pamięci i zasobów obliczeniowych. Jednak nowe projekty, zadania sezonowe lub zaawansowane podejścia, takie jak trenowanie modelu (w przypadku zmian, prognozowanie i konserwacja) tworzą skoki wymagań dotyczących zasobów. Aby organizacja obsługiwała wszystkie te obciążenia, potrzebuje skalowalnej platformy magazynowej i obliczeniowej. Dodawanie nowych zasobów w razie potrzeby musi być łatwe, a opłaty za rzeczywiste użycie powinny być naliczane tylko za. Gdy szczyt się skończy, zasoby można zwolnić i odpowiednio zmniejszyć koszty. Jest to często określane jako skalowanie w poziomie (liczba węzłów) i skalowanie w pionie (rozmiar węzłów).
Procedury odzyskiwania testów
Strategia odzyskiwania po awarii w całym przedsiębiorstwie dla większości aplikacji i systemów wymaga oceny priorytetów, możliwości, ograniczeń i kosztów. Niezawodne podejście do odzyskiwania po awarii regularnie sprawdza, jak obciążenia kończą się niepowodzeniem i weryfikują procedury odzyskiwania. Automatyzacja może służyć do symulowania różnych awarii lub ponownego tworzenia scenariuszy, które spowodowały błędy w przeszłości.
Automatyzowanie wdrożeń i obciążeń
Automatyzacja wdrożeń i obciążeń dla usługi Lakehouse pomaga w standaryzacji tych procesów, eliminowaniu błędów ludzkich, zwiększaniu produktywności i zapewnianiu większej powtarzalności. Obejmuje to użycie "konfiguracji jako kodu", aby uniknąć dryfu konfiguracji i "infrastruktury jako kodu", aby zautomatyzować aprowizację wszystkich wymaganych usług lakehouse i w chmurze.
Konfigurowanie monitorowania, alertów i rejestrowania
Obciążenia w usłudze Lakehouse zwykle integrują usługi platformy Databricks i zewnętrzne usługi w chmurze, na przykład jako źródła danych lub cele. Pomyślne wykonanie może wystąpić tylko wtedy, gdy każda usługa w łańcuchu wykonywania działa prawidłowo. Jeśli tak nie jest, monitorowanie, alerty i rejestrowanie są ważne w celu wykrywania i śledzenia problemów oraz zrozumienia zachowania systemu.