Obiekty danych w lakehouse usługi Databricks
Usługa Databricks Lakehouse organizuje dane przechowywane za pomocą usługi Delta Lake w magazynie obiektów w chmurze ze znanymi relacjami, takimi jak baza danych, tabele i widoki. Ten model łączy wiele zalet magazynu danych przedsiębiorstwa z skalowalnością i elastycznością magazynu danych typu data lake. Dowiedz się więcej o sposobie działania tego modelu oraz relacji między danymi obiektu i metadanymi, aby można było zastosować najlepsze rozwiązania podczas projektowania i implementowania usługi Databricks Lakehouse dla organizacji.
Jakie obiekty danych znajdują się w usłudze Databricks Lakehouse?
Architektura usługi Databricks lakehouse łączy dane przechowywane z protokołem Delta Lake w magazynie obiektów w chmurze z metadanymi zarejestrowanymi w magazynie metadanych. W lakehouse usługi Databricks znajduje się pięć obiektów podstawowych:
- Wykaz: grupowanie baz danych.
- Baza danych lub schemat: grupowanie obiektów w wykazie. Bazy danych zawierają tabele, widoki i funkcje.
- Tabela: kolekcja wierszy i kolumn przechowywanych jako pliki danych w magazynie obiektów.
- Widok: zapisane zapytanie zwykle względem co najmniej jednej tabeli lub źródeł danych.
- Funkcja: zapisana logika zwracająca wartość skalarną lub zestaw wierszy.
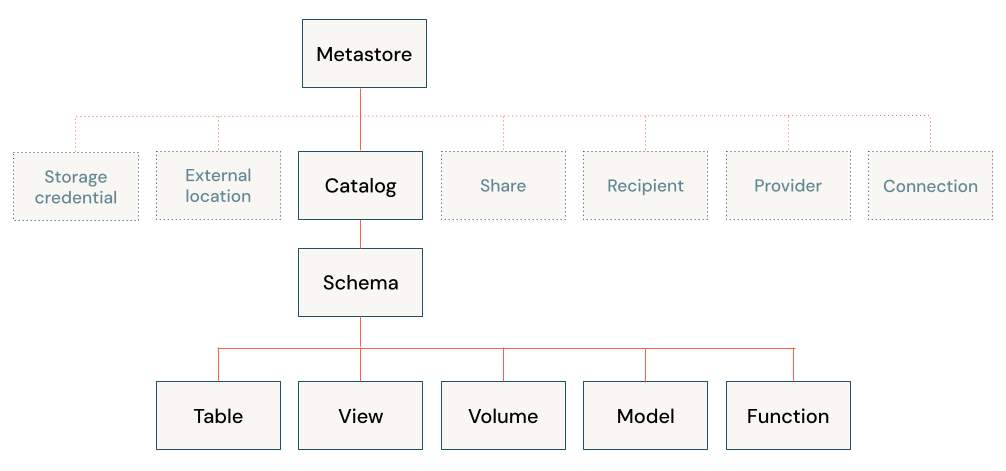
Aby uzyskać informacje na temat zabezpieczania obiektów za pomocą wykazu aparatu Unity, zobacz zabezpieczany model obiektów.
Co to jest magazyn metadanych?
Magazyn metadanych zawiera wszystkie metadane definiujące obiekty danych w lakehouse. Usługa Azure Databricks udostępnia następujące opcje magazynu metadanych:
Magazyn metadanych wykazu aparatu Unity: Wykaz aparatu Unity zapewnia scentralizowaną kontrolę dostępu, inspekcję, pochodzenie i możliwości odnajdywania danych. Magazyny metadanych wykazu aparatu Unity są tworzone na poziomie konta usługi Azure Databricks, a pojedynczy magazyn metadanych może być używany w wielu obszarach roboczych.
Każdy magazyn metadanych wykazu aparatu Unity jest skonfigurowany z lokalizacją magazynu głównego w kontenerze usługi Azure Data Lake Storage Gen2 na koncie platformy Azure. Ta lokalizacja magazynu jest domyślnie używana do przechowywania danych dla tabel zarządzanych.
W katalogu aparatu Unity dane są domyślnie bezpieczne. Początkowo użytkownicy nie mają dostępu do danych w magazynie metadanych. Dostęp można udzielić administratorowi magazynu metadanych lub właścicielowi obiektu. Zabezpieczane obiekty w rozwiązaniu Unity Catalog są hierarchiczne, a uprawnienia są dziedziczone w dół. Katalog aparatu Unity oferuje jedno miejsce do administrowania zasadami dostępu do danych. Użytkownicy mogą uzyskiwać dostęp do danych w wykazie aparatu Unity z dowolnego obszaru roboczego, do którego jest dołączony magazyn metadanych. Aby uzyskać więcej informacji, zobacz Zarządzanie uprawnieniami w wykazie aparatu Unity.
Wbudowany magazyn metadanych Hive (starsza wersja): każdy obszar roboczy usługi Azure Databricks zawiera wbudowany magazyn metadanych Hive jako usługę zarządzaną. Wystąpienie magazynu metadanych jest wdrażane w każdym klastrze i bezpiecznie uzyskuje dostęp do metadanych z centralnego repozytorium dla każdego obszaru roboczego klienta.
Magazyn metadanych Hive zapewnia mniej scentralizowany model zapewniania ładu danych niż wykaz aparatu Unity. Domyślnie klaster umożliwia wszystkim użytkownikom dostęp do wszystkich danych zarządzanych przez wbudowany magazyn metadanych Hive obszaru roboczego, chyba że dla tego klastra jest włączona kontrola dostępu do tabel. Aby uzyskać więcej informacji, zobacz Kontrola dostępu do tabel magazynu metadanych Hive (starsza wersja).
Mechanizmy kontroli dostępu do tabel nie są przechowywane na poziomie konta i dlatego muszą być konfigurowane oddzielnie dla każdego obszaru roboczego. Aby skorzystać ze scentralizowanego i usprawnionego modelu zapewniania ładu danych udostępnianego przez usługę Unity Catalog, usługa Databricks zaleca uaktualnienie tabel zarządzanych przez magazyn metadanych Hive obszaru roboczego do magazynu metadanych wykazu aparatu Unity.
Zewnętrzny magazyn metadanych Hive (starsza wersja): możesz również przenieść własny magazyn metadanych do usługi Azure Databricks. Klastry usługi Azure Databricks mogą łączyć się z istniejącymi zewnętrznymi magazynami metadanych Apache Hive. Kontrola dostępu do tabel umożliwia zarządzanie uprawnieniami w zewnętrznym magazynie metadanych. Kontrolki dostępu do tabel nie są przechowywane w zewnętrznym magazynie metadanych, dlatego należy je skonfigurować oddzielnie dla każdego obszaru roboczego. Usługa Databricks zaleca użycie wykazu aparatu Unity zamiast tego dla jego prostoty i modelu zapewniania ładu opartego na koncie.
Niezależnie od używanego magazynu metadanych usługa Azure Databricks przechowuje wszystkie dane tabeli w magazynie obiektów na koncie w chmurze.
Co to jest wykaz?
Wykaz to najwyższa abstrakcja (lub najcięższe ziarno) w modelu relacyjnym usługi Databricks Lakehouse. Każda baza danych zostanie skojarzona z wykazem. Wykazy istnieją jako obiekty w magazynie metadanych.
Przed wprowadzeniem wykazu aparatu Unity usługa Azure Databricks użyła dwuwarstwowej przestrzeni nazw. Wykazy są trzecią warstwą w modelu nazw wykazu aparatu UnityPacing:
catalog_name.database_name.table_name
Wbudowany magazyn metadanych Hive obsługuje tylko jeden wykaz. hive_metastore
Co to jest baza danych?
Baza danych to kolekcja obiektów danych, takich jak tabele lub widoki (nazywane również relacjami) i funkcje. W usłudze Azure Databricks terminy "schema" i "baza danych" są używane zamiennie (podczas gdy w wielu systemach relacyjnych baza danych jest kolekcją schematów).
Bazy danych będą zawsze skojarzone z lokalizacją w magazynie obiektów w chmurze. Opcjonalnie można określić LOCATION element podczas rejestrowania bazy danych, pamiętając, że:
- Skojarzona
LOCATIONz bazą danych jest zawsze uznawana za zarządzaną lokalizację. - Utworzenie bazy danych nie powoduje utworzenia żadnych plików w lokalizacji docelowej.
- Baza
LOCATIONdanych określi domyślną lokalizację danych wszystkich tabel zarejestrowanych w tej bazie danych. - Pomyślne usunięcie bazy danych spowoduje rekursywne usunięcie wszystkich danych i plików przechowywanych w lokalizacji zarządzanej.
Ta interakcja między lokalizacjami zarządzanymi przez bazę danych i pliki danych jest bardzo ważna. Aby uniknąć przypadkowego usunięcia danych:
- Nie udostępniaj lokalizacji bazy danych w wielu definicjach bazy danych.
- Nie rejestruj bazy danych w lokalizacji, która zawiera już dane.
- Aby zarządzać cyklem życia danych niezależnie od bazy danych, zapisz dane w lokalizacji, która nie jest zagnieżdżona w żadnej lokalizacji bazy danych.
Co to jest tabela?
Tabela usługi Azure Databricks to kolekcja danych ustrukturyzowanych. Tabela delty przechowuje dane jako katalog plików w magazynie obiektów w chmurze i rejestruje metadane tabeli w magazynie metadanych w katalogu i schemacie. Ponieważ usługa Delta Lake jest domyślnym dostawcą magazynu dla tabel utworzonych w usłudze Azure Databricks, wszystkie tabele utworzone w usłudze Databricks są domyślnie tabelami delty. Ponieważ tabele delty przechowują dane w magazynie obiektów w chmurze i dostarczają odwołania do danych za pośrednictwem magazynu metadanych, użytkownicy w organizacji mogą uzyskiwać dostęp do danych przy użyciu preferowanych interfejsów API; w usłudze Databricks obejmuje to języki SQL, Python, PySpark, Scala i R.
Pamiętaj, że istnieje możliwość utworzenia tabel w usłudze Databricks, które nie są tabelami delty. Te tabele nie są wspierane przez usługę Delta Lake i nie zapewnią transakcji ACID i zoptymalizowanej wydajności tabel delty. Tabele wchodzące w tę kategorię obejmują tabele zarejestrowane względem danych w systemach zewnętrznych i tabelach zarejestrowanych w innych formatach plików w usłudze Data Lake. Zobacz Połączenie do źródeł danych.
Istnieją dwa rodzaje tabel w usłudze Databricks, zarządzanych i niezarządzanych (lub zewnętrznych).
Uwaga
Różnice w tabelach na żywo między tabelami na żywo i tabelami transmisji strumieniowej na żywo nie są wymuszane z perspektywy tabeli.
Co to jest zarządzana tabela?
Usługa Azure Databricks zarządza zarówno metadanymi, jak i danymi dla zarządzanej tabeli; usunięcie tabeli spowoduje również usunięcie danych bazowych. Analitycy danych i inni użytkownicy, którzy pracują głównie w programie SQL, mogą preferować to zachowanie. Tabele zarządzane są domyślne podczas tworzenia tabeli. Dane zarządzanej tabeli znajdują się w LOCATION bazie danych, do których jest zarejestrowana. Ta zarządzana relacja między lokalizacją danych a bazą danych oznacza, że aby przenieść zarządzaną tabelę do nowej bazy danych, należy ponownie zapisać wszystkie dane w nowej lokalizacji.
Istnieje wiele sposobów tworzenia tabel zarządzanych, w tym:
CREATE TABLE table_name AS SELECT * FROM another_table
CREATE TABLE table_name (field_name1 INT, field_name2 STRING)
df.write.saveAsTable("table_name")
Co to jest tabela niezarządzana?
Usługa Azure Databricks zarządza tylko metadanymi dla tabel niezarządzanych (zewnętrznych). podczas porzucania tabeli nie ma to wpływu na dane bazowe. Tabele niezarządzane zawsze będą określać LOCATION podczas tworzenia tabeli. Można zarejestrować istniejący katalog plików danych jako tabelę lub podać ścieżkę, gdy tabela jest najpierw zdefiniowana. Ponieważ dane i metadane są zarządzane niezależnie, możesz zmienić nazwę tabeli lub zarejestrować ją w nowej bazie danych bez konieczności przenoszenia danych. Inżynierowie danych często preferują tabele niezarządzane i elastyczność, jaką zapewniają dla danych produkcyjnych.
Istnieje wiele sposobów tworzenia niezarządzanych tabel, w tym:
CREATE TABLE table_name
USING DELTA
LOCATION '/path/to/existing/data'
CREATE TABLE table_name
(field_name1 INT, field_name2 STRING)
LOCATION '/path/to/empty/directory'
df.write.option("path", "/path/to/empty/directory").saveAsTable("table_name")
Co to jest widok?
Widok przechowuje tekst zapytania w odniesieniu do co najmniej jednego źródła danych lub tabel w magazynie metadanych. W usłudze Databricks widok jest odpowiednikiem ramki danych Platformy Spark utrwalonej jako obiekt w bazie danych. W przeciwieństwie do ramek danych można wykonywać zapytania dotyczące widoków z dowolnej części produktu usługi Databricks, przy założeniu, że masz do tego uprawnienia. Tworzenie widoku nie przetwarza ani nie zapisuje żadnych danych; tylko tekst zapytania jest zarejestrowany w magazynie metadanych w skojarzonej bazie danych.
Co to jest widok tymczasowy?
Widok tymczasowy ma ograniczony zakres i trwałość i nie jest zarejestrowany w schemacie ani wykazie. Okres istnienia widoku tymczasowego różni się w zależności od używanego środowiska:
- W notesach i zadaniach widoki tymczasowe są ograniczone do poziomu notesu lub skryptu. Nie można odwoływać się do nich poza notesem, w którym są zadeklarowane, i nie będzie już istnieć, gdy notes odłącza się od klastra.
- W usłudze Databricks SQL widoki tymczasowe są ograniczone do poziomu zapytania. Wiele instrukcji w ramach tego samego zapytania może używać widoku tymczasowego, ale nie można odwoływać się do nich w innych zapytaniach, nawet w obrębie tego samego pulpitu nawigacyjnego.
- Globalne widoki tymczasowe są ograniczone do poziomu klastra i mogą być współużytkowane między notesami lub zadaniami, które współużytkują zasoby obliczeniowe. Usługa Databricks zaleca używanie widoków z odpowiednimi listami ACL tabel zamiast globalnych widoków tymczasowych.
Co to jest funkcja?
Funkcje umożliwiają kojarzenie logiki zdefiniowanej przez użytkownika z bazą danych. Funkcje mogą zwracać wartości skalarne lub zestawy wierszy. Funkcje są używane do agregowania danych. Usługa Azure Databricks umożliwia zapisywanie funkcji w różnych językach w zależności od kontekstu wykonywania, przy czym język SQL jest szeroko obsługiwany. Za pomocą funkcji można zapewnić zarządzany dostęp do logiki niestandardowej w różnych kontekstach produktu Databricks.
Jak działają obiekty relacyjne w tabelach delta live?
Funkcja Delta Live Tables używa składni deklaratywnej do definiowania języków DDL, DML i wdrażania infrastruktury oraz zarządzania nimi. Funkcja Delta Live Tables używa koncepcji "schematu wirtualnego" podczas planowania i wykonywania logiki. Tabele delta Live Tables mogą wchodzić w interakcje z innymi bazami danych w środowisku usługi Databricks, a tabele delta Live Tables mogą publikować i utrwalać tabele na potrzeby wykonywania zapytań w innym miejscu, określając docelową bazę danych w ustawieniach konfiguracji potoku.
Wszystkie tabele utworzone w tabelach delta live są tabelami delty. W przypadku korzystania z wykazu aparatu Unity z tabelami delta Live Tables wszystkie tabele są tabelami zarządzanymi w wykazie aparatu Unity. Jeśli wykaz aparatu Unity nie jest aktywny, tabele można zadeklarować jako tabele zarządzane lub niezarządzane.
Widoki można zadeklarować w tabelach delta live, ale powinny one być uważane za widoki tymczasowe ograniczone do potoku. Tabele tymczasowe w tabelach Delta Live Tables są unikatową koncepcją: te tabele utrwalają dane w magazynie, ale nie publikują danych w docelowej bazie danych.
Niektóre operacje, takie jak APPLY CHANGES INTO, będą rejestrować zarówno tabelę, jak i widok w bazie danych. Nazwa tabeli rozpocznie się od podkreślenia (_), a widok będzie miał nazwę tabeli zadeklarowaną jako element docelowy APPLY CHANGES INTO operacji. Widok wysyła zapytanie do odpowiedniej ukrytej tabeli, aby zmaterializować wyniki.