Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Potoki Lakeflow wprowadzają kilka nowych konstrukcji w kodzie Python do definiowania zmaterializowanych widoków i tabel strumieniowych w ramach potoków. Wsparcie dla Pythona w opracowywaniu potoków opiera się na podstawach PySpark DataFrame i Structured Streaming APIs.
Dla użytkowników nieznających Python oraz DataFrames, Databricks zaleca użycie interfejsu SQL. Zobacz Develop Lakeflow pipelines code with SQL (Tworzenie kodu potoków usługi Lakeflow przy użyciu języka SQL). Aby uzyskać pomoc przy podejmowaniu decyzji między dwoma interfejsami, zobacz Wybieranie między programem SQL i Python.
Pełne informacje o składni języka Python dla potoków Lakeflow można znaleźć w sekcji Informacje referencyjne o języku Python dla potoków Lakeflow.
Podstawy języka Python w rozwoju potoków
Kod w języku Python, który tworzy zbiory danych potoku, musi zwracać obiekty DataFrame.
Wszystkie interfejsy API języka Python dla potoków Lakeflow są zaimplementowane w module pyspark.pipelines. Kod potokowy zaimplementowany w Pythonie musi jawnie zaimportować moduł pipelines na początku kodu źródłowego Pythona. W przykładach używamy następującego polecenia importu i stosujemy dp w celu odniesienia do pipelines.
from pyspark import pipelines as dp
Uwaga / Notatka
Platforma Apache Spark™ obejmuje potoki deklaratywne rozpoczynające się na platformie Spark 4.1 dostępne za pośrednictwem modułu pyspark.pipelines . Środowisko Databricks Runtime rozszerza te funkcje typu open source o dodatkowe interfejsy API i integracje na potrzeby zarządzanego użycia produkcyjnego.
Kod napisany za pomocą modułu open source pipelines jest uruchamiany bez modyfikacji w usłudze Azure Databricks. Następujące funkcje nie są częścią platformy Apache Spark:
dp.create_auto_cdc_flowdp.create_auto_cdc_from_snapshot_flow@dp.expect(...)
Potok odczytuje i zapisuje domyślnie katalog i schemat określony podczas konfiguracji potoku. Zobacz Ustaw katalog docelowy i schemat.
Kod Python specyficzny dla potoku różni się od innych typów kodu Python w jeden krytyczny sposób: kod potoku Python nie wywołuje bezpośrednio funkcji odpowiedzialnych za pozyskiwanie i przekształcanie danych w celu tworzenia zestawów danych. Zamiast tego potoki Lakeflow interpretują funkcje dekorujące z modułu dp we wszystkich plikach kodu źródłowego skonfigurowanych w potoku i tworzą graf przepływu danych.
Ważne
Aby uniknąć nieoczekiwanego zachowania podczas działania potoku, nie umieszczaj kodu, który może mieć efekty uboczne, w funkcjach definiujących zestawy danych. Aby dowiedzieć się więcej, zobacz odniesienie do Python.
Tworzenie zmaterializowanego widoku lub tabeli przesyłania strumieniowego przy użyciu języka Python
Użyj @dp.table, aby utworzyć tabelę przesyłania strumieniowego na podstawie wyników odczytu przesyłania strumieniowego. Użyj @dp.materialized_view polecenia, aby utworzyć zmaterializowany widok na podstawie wyników odczytu wsadowego.
Domyślnie nazwy zmaterializowanego widoku i tabeli strumieniowej są wnioskowane z nazw funkcji. Poniższy przykład kodu przedstawia podstawową składnię tworzenia zmaterializowanego widoku i tabeli strumieniowej:
Uwaga / Notatka
Obie funkcje odwołują się do tej samej tabeli w katalogu samples i używają tej samej funkcji dekoratora. Te przykłady podkreślają, że jedyną różnicą w podstawowej składni zmaterializowanych widoków i tabel przesyłania strumieniowego jest użycie spark.read versus spark.readStream.
Nie wszystkie źródła danych obsługują odczyty strumieniowe. Niektóre źródła danych powinny zawsze być przetwarzane z zastosowaniem semantyki strumieniowej.
from pyspark import pipelines as dp
@dp.materialized_view()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dp.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Opcjonalnie możesz określić nazwę tabeli przy użyciu argumentu name w dekoratorze @dp.table. W poniższym przykładzie pokazano ten wzorzec dla zmaterializowanego widoku i tabeli strumieniowej.
from pyspark import pipelines as dp
@dp.materialized_view(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dp.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Ładowanie danych z magazynu obiektów
Pipelines obsługują ładowanie danych ze wszystkich formatów obsługiwanych przez Azure Databricks. Zobacz Opcje formatu danych.
Uwaga / Notatka
W tych przykładach używane są dane dostępne w /databricks-datasets, które są automatycznie zamontowane w obszarze roboczym. Databricks zaleca używanie ścieżek woluminów lub identyfikatorów URI w chmurze do odwoływania się do danych przechowywanych w magazynie obiektów w chmurze. Zobacz Czym są wolumeny Unity Catalog?.
Databricks zaleca używanie funkcji Auto Loader i tabel strumieniowych przy konfigurowaniu zadań pozyskiwania przyrostowego z danych przechowywanych w chmurowym magazynie obiektów. Zobacz Co to jest moduł automatycznego ładowania?.
W poniższym przykładzie tworzona jest tabela strumieniowa z plików JSON przy użyciu Auto Loader.
from pyspark import pipelines as dp
@dp.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
W poniższym przykładzie użyto semantyki wsadowej do odczytania katalogu JSON i utworzenia zmaterializowanego widoku:
from pyspark import pipelines as dp
@dp.materialized_view()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
Walidacja danych względem oczekiwań
Możesz użyć oczekiwań, aby ustawić i wymusić ograniczenia dotyczące jakości danych. Zobacz Zarządzanie jakością danych przy użyciu oczekiwań dotyczących przepływu danych.
Następujący kod używa @dp.expect_or_drop do zdefiniowania oczekiwania o nazwie valid_data, które usuwa rekordy będące wartościami null podczas pobierania danych.
from pyspark import pipelines as dp
@dp.table()
@dp.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
Wykonywanie zapytań dotyczących zmaterializowanych widoków i tabel strumieniowych zdefiniowanych w potoku
W poniższym przykładzie zdefiniowano cztery zestawy danych:
- Tabela strumieniowa nazwana
orders, która ładuje dane JSON. - Zmaterializowany widok o nazwie
customers, który ładuje dane CSV. - Zmaterializowany widok o nazwie
customer_orders, łączący rekordy z zestawów danychordersicustomers, przekształca znacznik czasu zamówienia na datę oraz wybiera polacustomer_id,order_number,stateiorder_date. - Zmaterializowany widok o nazwie
daily_orders_by_state, który agreguje dzienną liczbę zamówień dla każdego stanu.
Uwaga / Notatka
Podczas zapytań dotyczących widoków lub tabel w potoku danych, można określić katalog i schemat bezpośrednio lub użyć wartości domyślnych skonfigurowanych w potoku danych. W tym przykładzie tabele orders, customers i customer_orders są zapisywane i odczytywane z domyślnego wykazu i schematu skonfigurowanego dla przepływu danych.
Tryb publikowania Legacy używa schematu LIVE do wykonywania zapytań dotyczących innych zmaterializowanych widoków i tabel przesyłania strumieniowego zdefiniowanych w potoku. W nowych potokach składnia schematu LIVE jest ignorowana w trybie dyskretnym. Zobacz LIVE schema (legacy).
from pyspark import pipelines as dp
from pyspark.sql.functions import col
@dp.table()
@dp.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dp.materialized_view()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dp.materialized_view()
def customer_orders():
return (spark.read.table("orders")
.join(spark.read.table("customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dp.materialized_view()
def daily_orders_by_state():
return (spark.read.table("customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
Tworzenie tabel w pętli for
Za pomocą pętli for języka Python można programowo tworzyć wiele tabel. Może to być przydatne, gdy masz wiele źródeł danych lub docelowych zestawów danych, które różnią się tylko o kilka parametrów, co zmniejsza ilość kodu do utrzymania i redukuje jego redundancję.
Pętla for ocenia logikę w kolejności szeregowej, ale gdy planowanie zestawów danych jest zakończone, potok wykonuje logikę równolegle.
Ważne
W przypadku używania tego wzorca do definiowania zestawów danych upewnij się, że lista wartości przekazanych do pętli for jest zawsze dodawalna. Jeśli zestaw danych zdefiniowany wcześniej w potoku zostanie pominięty w przyszłym uruchomieniu potoku, zostanie on usunięty automatycznie ze schematu docelowego.
Poniższy przykład tworzy pięć tabel filtrujących zamówienia klientów według regionów. W tym miejscu nazwa regionu służy do ustawiania nazwy zmaterializowanych widoków docelowych i filtrowania danych źródłowych. Widoki tymczasowe służą do definiowania sprzężeń z tabel źródłowych używanych w konstruowaniu końcowych zmaterializowanych widoków.
from pyspark import pipelines as dp
from pyspark.sql.functions import collect_list, col
@dp.temporary_view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dp.temporary_view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dp.materialized_view(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("customer_orders")
nation_region = spark.read.table("nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
Poniżej znajduje się przykład grafu przepływu danych dla tej rury:
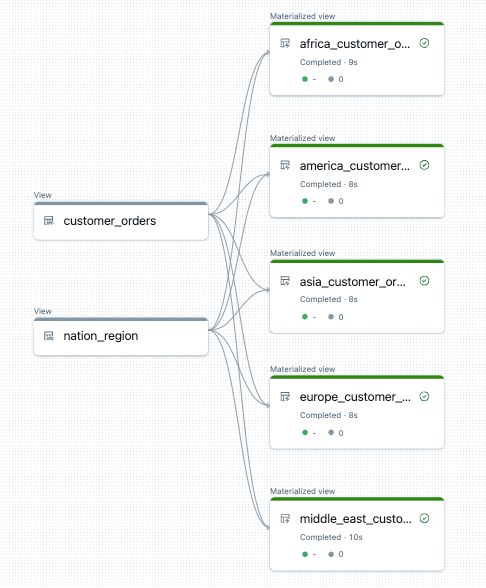
Rozwiązywanie problemów: pętla for tworzy wiele tabel z tymi samymi wartościami
Model leniwego wykonywania, którego potoki używają do oceny kodu Python, wymaga, aby Twoja logika bezpośrednio odnosiła się do poszczególnych wartości, gdy wywoływana jest funkcja udekorowana przez @dp.materialized_view().
W poniższym przykładzie pokazano dwa poprawne podejścia do definiowania tabel z pętlą for. W obu przykładach każda nazwa tabeli z listy tables jest jawnie przywołyowana w funkcji ozdobionej przez @dp.materialized_view().
from pyspark import pipelines as dp
# Create a parent function to set local variables
def create_table(table_name):
@dp.materialized_view(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dp.materialized_view()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dp.materialized_view(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
Następujący przykład nie odnosi się poprawnie do wartości. W tym przykładzie są tworzone tabele o różnych nazwach, ale wszystkie tabele ładują dane z ostatniej wartości w pętli for:
from pyspark import pipelines as dp
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dp.materialized(name=t_name)
def create_table():
return spark.read.table(t_name)
Trwale usuń rekordy z zmaterializowanego widoku lub tabeli strumieniowej
Aby trwale usunąć rekordy z zmaterializowanego widoku lub tabeli przesyłania strumieniowego z włączonymi wektorami usuwania, niezbędnymi na przykład dla zgodności z RODO, należy wykonać dodatkowe operacje na podstawowych tabelach Delta obiektu. Aby zapewnić usunięcie rekordów z zmaterializowanego widoku, zobacz Trwałe usuwanie rekordów z zmaterializowanego widoku z włączonymi wektorami usuwania. Aby zapewnić usunięcie rekordów z tabeli przesyłania strumieniowego, zobacz Trwałe usuwanie rekordów z tabeli przesyłania strumieniowego.