Przeprowadzanie testów porównawczych punktów końcowych usługi LLM
Ten artykuł zawiera przykład zalecany notes usługi Databricks na potrzeby testów porównawczych punktu końcowego llM. Zawiera również krótkie wprowadzenie do sposobu, w jaki usługa Databricks wykonuje wnioskowanie llM i oblicza opóźnienie i przepływność jako metryki wydajności punktu końcowego.
Wnioskowanie LLM w usłudze Databricks mierzy tokeny na sekundę dla trybu aprowizowanej przepływności dla interfejsów API modelu foundation. Zobacz Co oznaczają tokeny na sekundę w aprowizowanej przepływności?
Przykładowy notes testów porównawczych
Poniższy notes można zaimportować do środowiska usługi Databricks i określić nazwę punktu końcowego LLM, aby uruchomić test obciążeniowy.
Testowanie porównawcze punktu końcowego usługi LLM
Wprowadzenie do wnioskowania w usłudze LLM
Moduły LLM wykonują wnioskowanie w procesie dwuetapowym:
- Wstępne wypełnianie, gdzie tokeny w wierszu polecenia wejściowego są przetwarzane równolegle.
- Dekodowanie, gdzie tekst jest generowany jeden token naraz w sposób automatyczny regresji. Każdy wygenerowany token jest dołączany do danych wejściowych i przekazywane z powrotem do modelu w celu wygenerowania następnego tokenu. Generowanie zatrzymuje się, gdy usługa LLM wyprowadza specjalny token zatrzymania lub gdy jest spełniony warunek zdefiniowany przez użytkownika.
Większość aplikacji produkcyjnych ma budżet opóźnienia, a usługa Databricks zaleca zmaksymalizowanie przepływności, biorąc pod uwagę, że budżet opóźnienia.
- Liczba tokenów wejściowych ma znaczący wpływ na wymaganą pamięć do przetwarzania żądań.
- Liczba tokenów wyjściowych dominuje w ogólnym opóźnieniu odpowiedzi.
Usługa Databricks dzieli wnioskowanie LLM na następujące metryki podrzędne:
- Czas pierwszego tokenu (TTFT): jak szybko użytkownicy zaczynają widzieć dane wyjściowe modelu po wprowadzeniu zapytania. Niskie czasy oczekiwania na odpowiedź są niezbędne w interakcjach w czasie rzeczywistym, ale mniej ważne w obciążeniach w trybie offline. Ta metryka jest oparta na czasie wymaganym do przetworzenia monitu, a następnie wygenerowaniu pierwszego tokenu wyjściowego.
- Czas na token wyjściowy (TPOT): czas generowania tokenu wyjściowego dla każdego użytkownika, który wykonuje zapytanie dotyczące systemu. Ta metryka odpowiada temu, jak każdy użytkownik postrzega "szybkość" modelu. Na przykład TPOT 100 milisekund na token będzie wynosić 10 tokenów na sekundę lub ok. 450 słów na minutę, co jest szybsze niż typowy użytkownik może odczytać.
Na podstawie tych metryk można zdefiniować łączne opóźnienie i przepływność w następujący sposób:
- Opóźnienie = TTFT + (TPOT) * (liczba tokenów do wygenerowania)
- Przepływność = liczba tokenów wyjściowych na sekundę we wszystkich żądaniach współbieżności
W usłudze Databricks punkty końcowe obsługujące usługę LLM mogą być skalowane w celu dopasowania obciążenia wysyłanego przez klientów z wieloma współbieżnymi żądaniami. Istnieje kompromis między opóźnieniami a przepływnością. Dzieje się tak, ponieważ w przypadku punktów końcowych obsługujących usługę LLM współbieżne żądania mogą być przetwarzane i przetwarzane w tym samym czasie. Przy niskich obciążeniach żądań współbieżnych opóźnienie jest najmniejsze. Jeśli jednak zwiększysz obciążenie żądania, opóźnienie może wzrosnąć, ale przepływność prawdopodobnie również wzrośnie. Dzieje się tak, ponieważ dwa żądania o wartości tokenów na sekundę mogą być przetwarzane w czasie krótszym niż dwukrotnie.
W związku z tym kontrolowanie liczby żądań równoległych do systemu jest rdzeniem równoważenia opóźnienia przy użyciu przepływności. Jeśli masz przypadek użycia o małych opóźnieniach, chcesz wysłać mniej równoczesnych żądań do punktu końcowego, aby zachować małe opóźnienie. Jeśli masz przypadek użycia wysokiej przepływności, chcesz usycić punkt końcowy z dużą częścią żądań współbieżności, ponieważ większa przepływność jest warta nawet kosztem opóźnienia.
Wykorzystanie testów porównawczych usługi Databricks
Wcześniej udostępniony przykład testów porównawczych to wykorzystanie testów porównawczych usługi Databricks. W notesie są wyświetlane metryki opóźnienia i przepływności oraz wykresy krzywej przepływności i opóźnienia w różnych liczbach żądań równoległych. Automatyczne skalowanie punktów końcowych usługi Databricks jest oparte na strategii "zrównoważonej" między opóźnieniami a przepływnością. W notesie zauważasz, że w miarę jak bardziej współbieżni użytkownicy wysyłają zapytania do punktu końcowego w tym samym czasie, gdy opóźnienie wzrasta, a także przepływność.
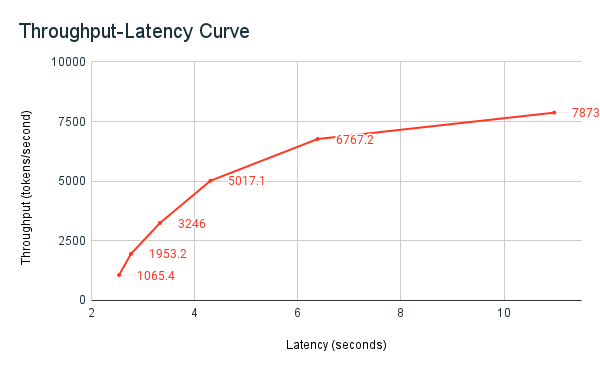
Więcej szczegółów na temat filozofii usługi Databricks na temat testów porównawczych wydajności usługi LLM opisano w blogu LlM Inference Performance Engineering: Best Practices (Wnioskowanie o wydajności: najlepsze rozwiązania w usłudze LLM).