Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano dwa typowe wzorce przenoszenia artefaktów uczenia maszynowego przez fazy przejściowe i do środowiska produkcyjnego. Asynchroniczny charakter zmian w modelach i kodzie oznacza, że istnieje wiele możliwych wzorców, które mogą być zgodne z procesem programowania uczenia maszynowego.
Modele są tworzone przez kod, ale wynikowe artefakty modelu i kod, który je utworzył, mogą działać asynchronicznie. Oznacza to, że nowe wersje modelu i zmiany kodu mogą nie nastąpić w tym samym czasie. Na przykład rozważmy następujące scenariusze:
- Aby wykryć nieuczciwe transakcje, tworzysz pipeline uczenia maszynowego, który trenuje model ponownie co tydzień. Kod może się nie zmieniać bardzo często, ale model może być ponownie trenowany co tydzień w celu uwzględnienia nowych danych.
- Do klasyfikowania dokumentów można utworzyć dużą, głęboką sieć neuronową. W takim przypadku trenowanie modelu jest wymagające dużych zasobów obliczeniowych i czasochłonne, a ponowne trenowanie modelu będzie prawdopodobnie rzadkie. Jednak kod, który wdraża, obsługuje i monitoruje ten model, można zaktualizować bez ponownego trenowania modelu.
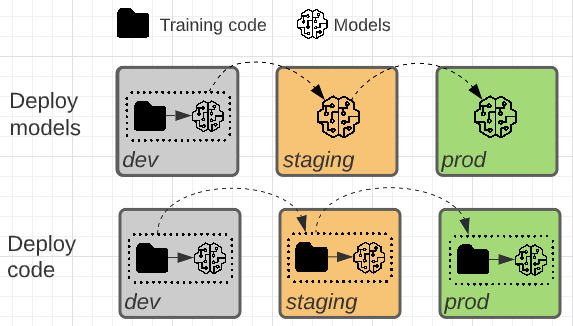
Te dwa wzorce różnią się tym, czy promowany do produkcji jest artefakt modelu, czy kod treningowy, który generuje artefakt modelu.
Wdrażanie kodu (zalecane)
W większości przypadków usługa Databricks zaleca podejście „wdrażania kodu”. Takie podejście jest uwzględniane w zalecanym przepływie pracy metodyki MLOps.
W tym wzorcu kod trenowania modeli jest opracowywany w środowisku projektowym. Ten sam kod przechodzi do etapu przejściowego, a następnie produkcyjnego. Model jest trenowany w każdym środowisku: początkowo w środowisku deweloperskim w ramach tworzenia modelu, w środowisku przejściowym (w ograniczonym podzestawie danych) w ramach testów integracji i w środowisku produkcyjnym (na pełnych danych produkcyjnych) w celu utworzenia końcowego modelu.
Zalety:
- W organizacjach, w których dostęp do danych produkcyjnych jest ograniczony, ten wzorzec umożliwia trenowanie modelu na danych produkcyjnych w środowisku produkcyjnym.
- Ponowne trenowanie modelu zautomatyzowanego jest bezpieczniejsze, ponieważ kod trenowania jest przeglądany, testowany i zatwierdzony do produkcji.
- Kod pomocniczy jest zgodny z tym samym wzorcem co kod trenowania modelu. Obydwa testy integracyjne są przeprowadzane w środowisku testowym.
Wady:
- Krzywa szkoleniowa dla analityków danych do przekazania kodu współpracownikom może być stroma. Przydatne są wstępnie zdefiniowane szablony projektów i przepływy pracy.
Ponadto w tym schemacie naukowcy danych muszą mieć możliwość przeglądania wyników trenowania ze środowiska produkcyjnego, ponieważ mają wiedzę na temat identyfikowania i rozwiązywania problemów specyficznych dla uczenia maszynowego.
Jeśli sytuacja wymaga wytrenowania modelu w środowisku przejściowym w pełnym zestawie danych produkcyjnych, możesz użyć podejścia hybrydowego, wdrażając kod w środowisku przejściowym, trenowanie modelu, a następnie wdrażanie modelu w środowisku produkcyjnym. Takie podejście zmniejsza koszty szkolenia w środowisku produkcyjnym, ale wiąże się z dodatkowymi kosztami operacyjnymi w środowisku przejściowym.
Wdrażanie modeli
W tym wzorcu artefakt modelu jest generowany przez kod treningowy w środowisku programistycznym. Artefakt jest następnie testowany w środowisku przejściowym przed wdrożeniem w środowisku produkcyjnym.
Rozważ tę opcję, jeśli zastosuje się co najmniej jedną z następujących opcji:
- Trenowanie modelu jest bardzo kosztowne lub trudne do odtworzenia.
- Wszystkie prace są wykonywane w jednym obszarze roboczym usługi Azure Databricks.
- Nie współpracujesz z zewnętrznymi repozytoriami ani z procesem ciągłej integracji i wdrażania (CI/CD).
Zalety:
- Prostsze przekazywanie obowiązków dla naukowców danych
- W przypadkach, gdy trenowanie modelu jest kosztowne, wymaga się tylko jednokrotnego treningu modelu.
Wady:
- Jeśli dane produkcyjne nie są dostępne ze środowiska programistycznego (co może być prawdziwe ze względów bezpieczeństwa), ta architektura może nie być opłacalna.
- Ponowne trenowanie modelu zautomatyzowanego jest trudne w tym wzorcu. Możesz zautomatyzować ponowne trenowanie w środowisku deweloperskim, ale zespół odpowiedzialny za wdrożenie modelu w środowisku produkcyjnym może nie zaakceptować wynikowego modelu jako gotowego do produkcji.
- Kod pomocniczy, taki jak potoki używane do inżynierii cech, wnioskowania i monitorowania, należy wdrożyć do środowiska produkcyjnego oddzielnie.
Typowo środowisko (deweloperskie, stagingowe lub produkcyjne) odpowiada katalogowi w Unity Catalog. Aby uzyskać szczegółowe informacje na temat implementowania tego wzorca, zobacz przewodnik uaktualniania.
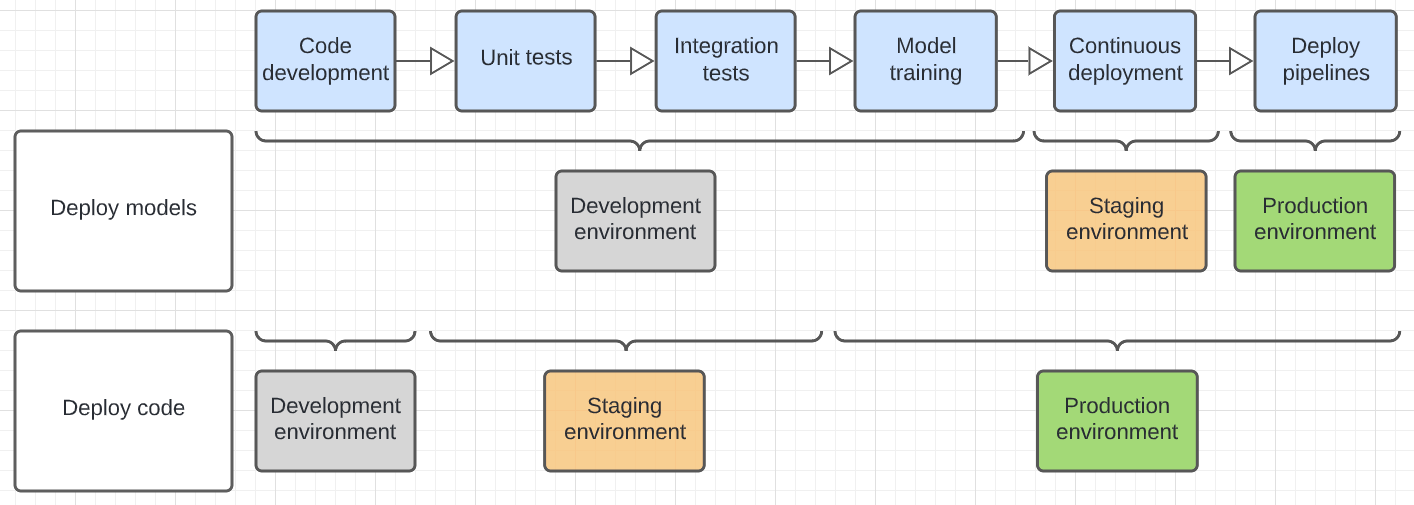
Na poniższym diagramie kontrastuje cykl życia kodu dla powyższych wzorców wdrażania w różnych środowiskach wykonywania.
Środowisko pokazane na diagramie jest ostatnim środowiskiem, w którym jest uruchamiany krok. Na przykład w schemacie wdrażania modeli ostateczne testy jednostkowe i integracyjne są wykonywane w środowisku deweloperskim. We wzorcu wdrażania kodu testy jednostkowe i testy integracji są uruchamiane w środowiskach deweloperskich, a ostateczna jednostka i testowanie integracji są wykonywane w środowisku przejściowym.