Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Na tej stronie opisano, jak dostosować automatyczne rejestrowanie w usłudze Databricks, które automatycznie przechwytuje parametry modelu, metryki, pliki oraz informacje o pochodzeniu podczas trenowania modeli z różnych popularnych bibliotek uczenia maszynowego. Sesje szkoleniowe są rejestrowane jako przebiegi śledzenia MLflow. Pliki modelu są również śledzone, dzięki czemu można je łatwo rejestrować w rejestrze modeli MLflow.
Uwaga
Aby włączyć rejestrowanie śledzenia dla obciążeń generatywnej sztucznej inteligencji, MLflow obsługuje OpenAI autologging.
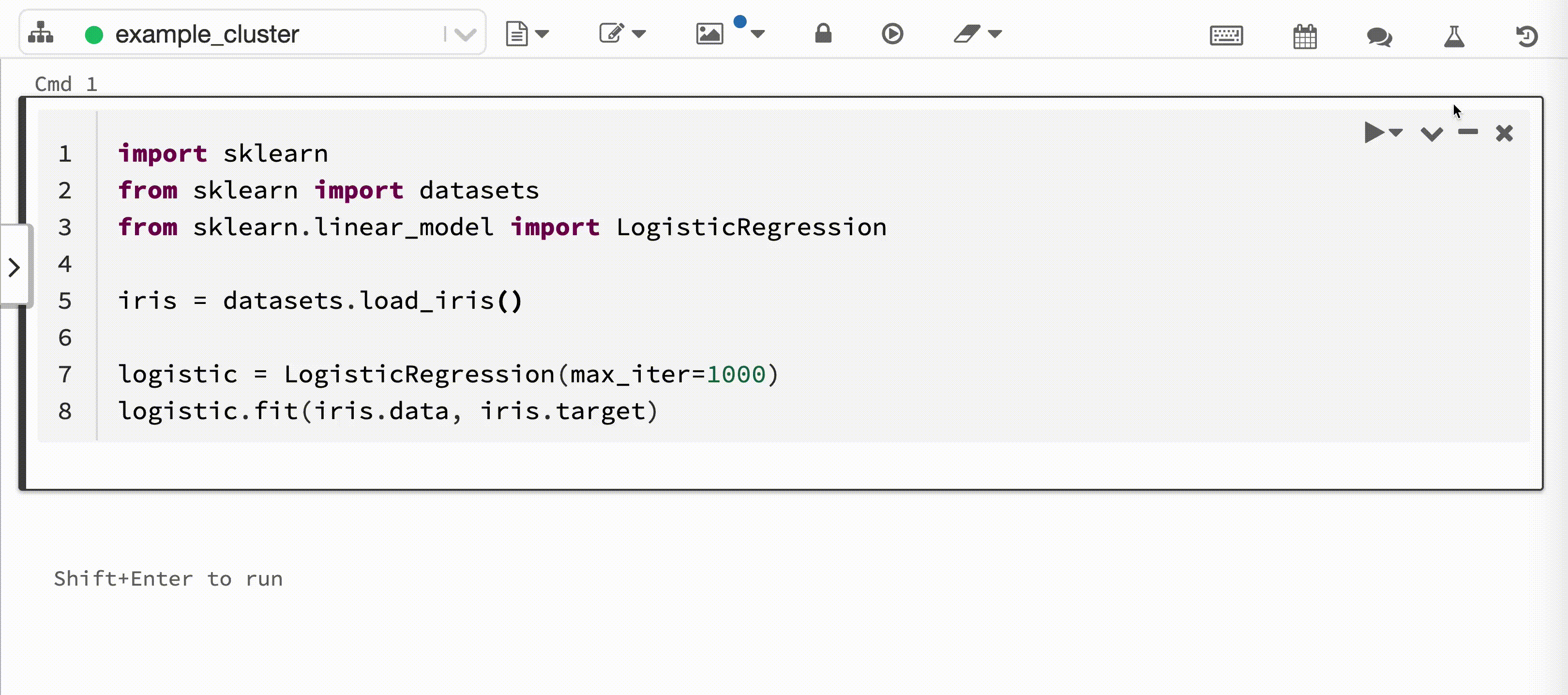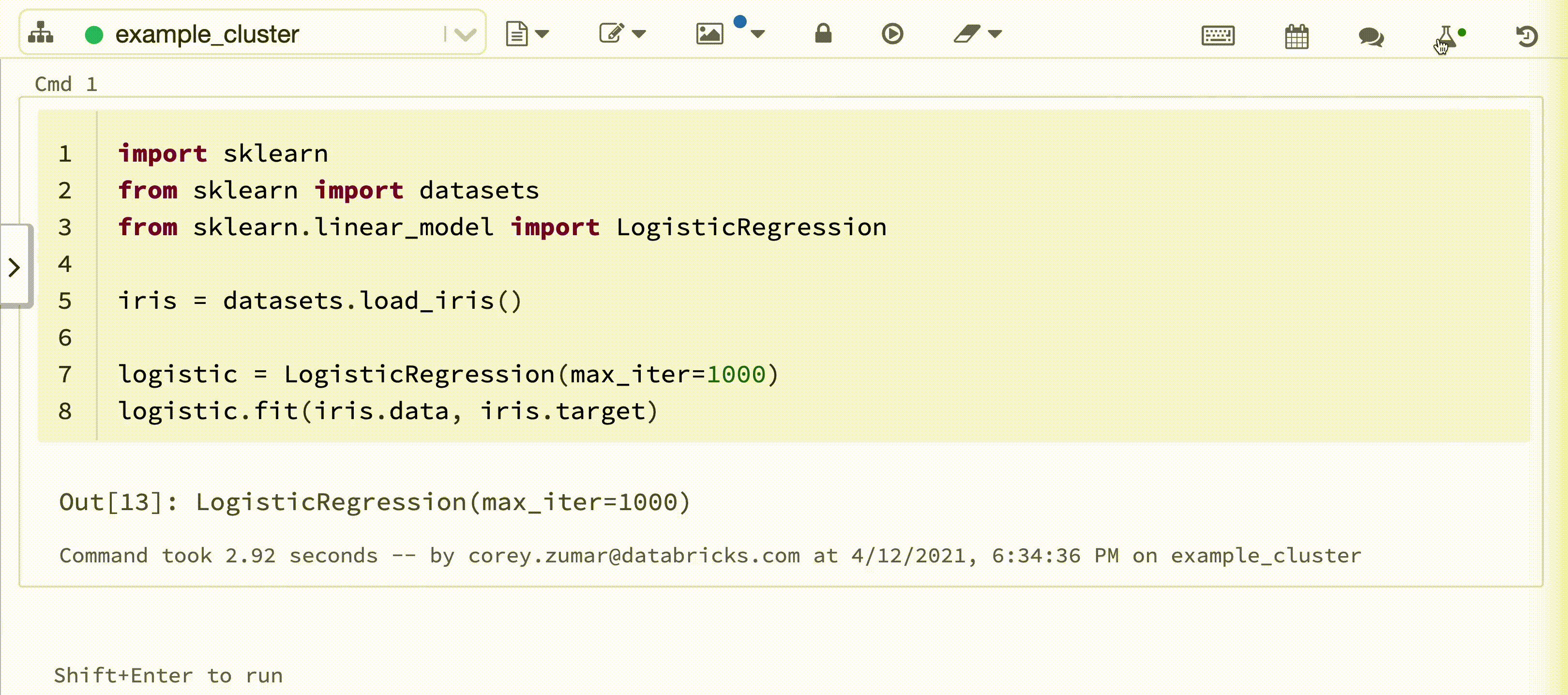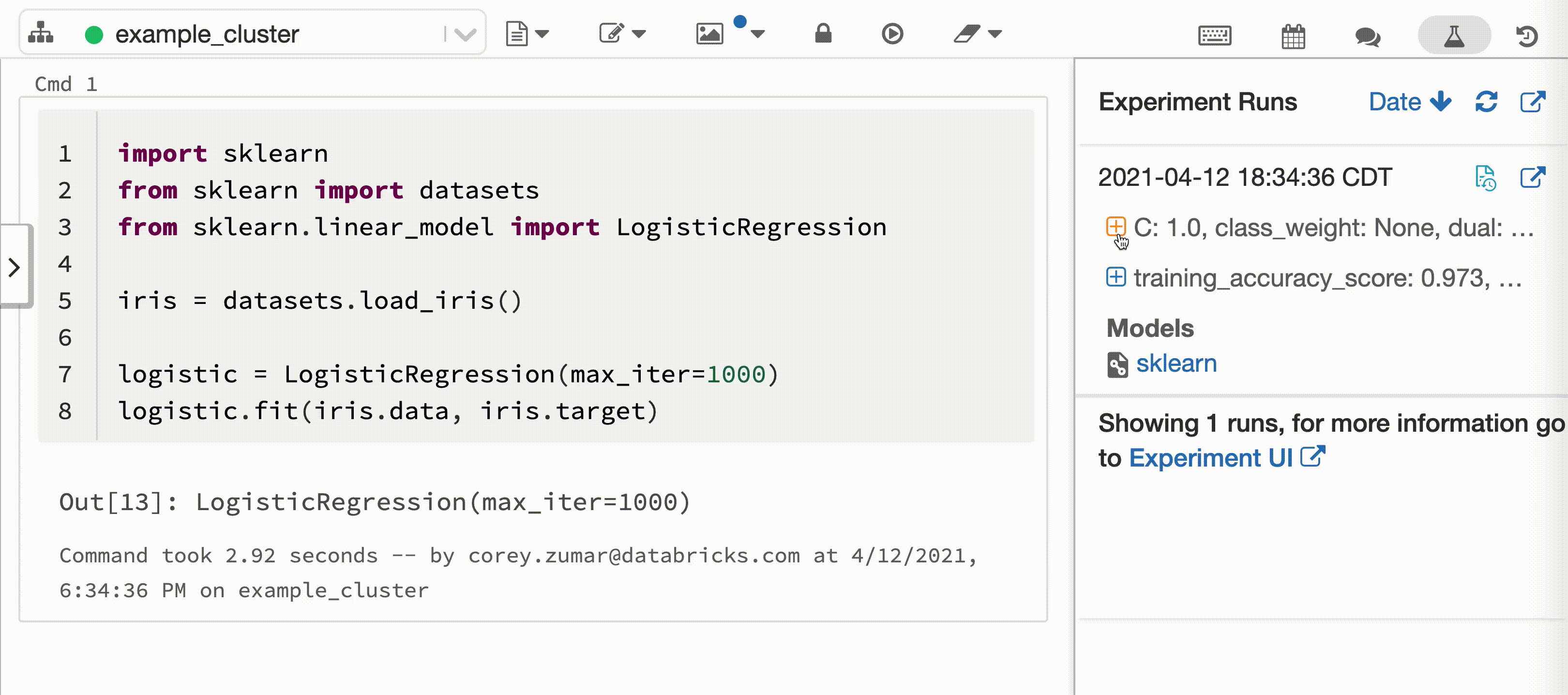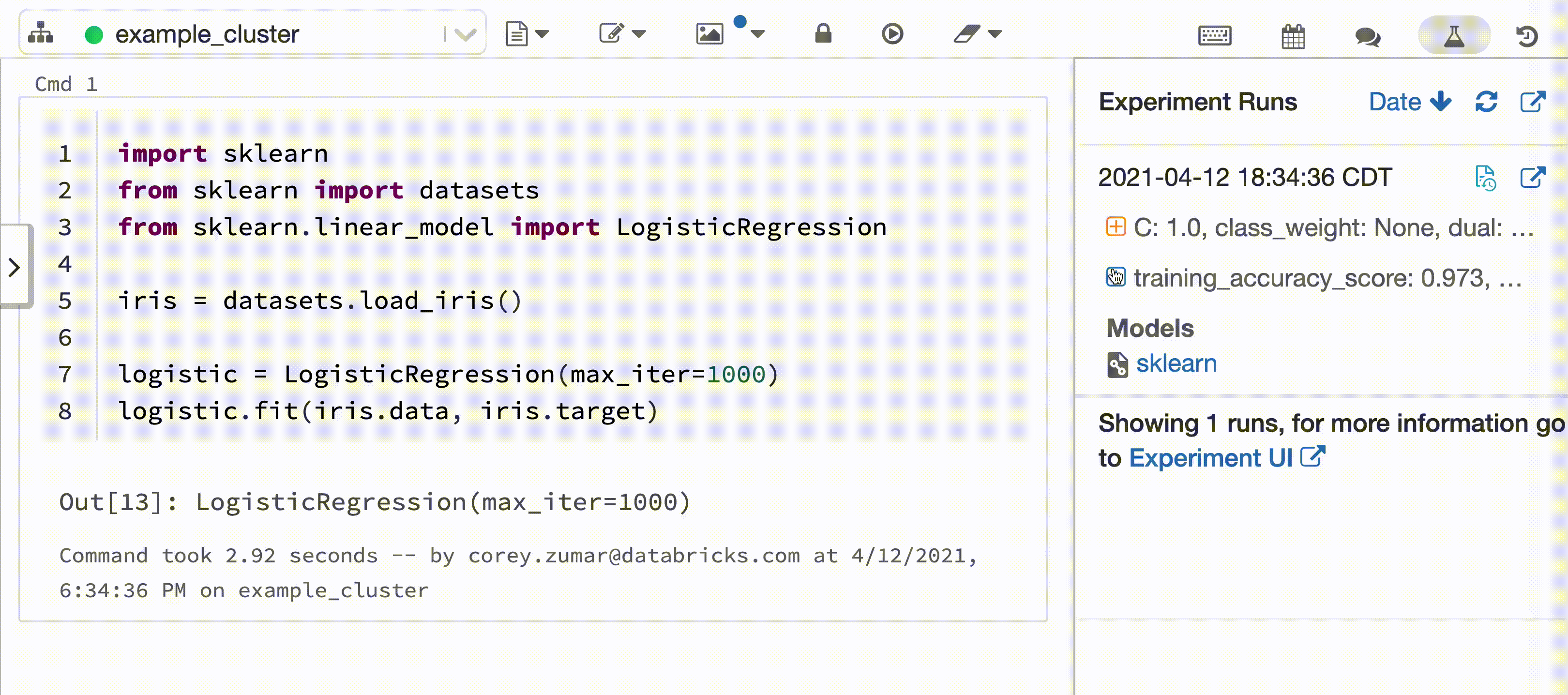
Na poniższym filmie pokazano Databricks Autologging podczas sesji trenowania modelu scikit-learn w interaktywnym notesie Python. Informacje śledzenia są automatycznie przechwytywane i wyświetlane w bocznym panelu 'Przebiegi eksperymentów' oraz w interfejsie użytkownika MLflow.
Wymagania
- Autologowanie Databricks jest dostępne w wersji ogólnej we wszystkich regionach w środowisku Databricks Runtime 10.4 LTS ML lub nowszym.
- Databricks Autologging jest dostępne w wybranych regionach w wersji zapoznawczej z Databricks Runtime 9.1 LTS ML lub nowszym.
Jak to działa
Po dołączeniu interaktywnego notatnika Pythona do klastra usługi Azure Databricks, funkcja Autologging w Databricks wywołuje mlflow.autolog() w celu skonfigurowania śledzenia sesji trenowania modelu. Podczas trenowania modeli w notebooku, informacje o trenowaniu modelu są automatycznie śledzone za pomocą MLflow Tracking. Aby uzyskać informacje o sposobie zabezpieczania i zarządzania informacjami dotyczącymi trenowania modelu, zobacz Zabezpieczenia i zarządzanie danymi.
Uwaga
Automatyczne rejestrowanie nie jest automatycznie włączone w obliczeniach bezserwerowych. W przypadku bezserwerowych klastrów obliczeniowych należy jawnie wywołać mlflow.autolog() funkcję włączania automatycznego rejestrowania.
Domyślna konfiguracja wywołania mlflow.autolog() to:
mlflow.autolog(
log_input_examples=False,
log_model_signatures=True,
log_models=True,
disable=False,
exclusive=False,
disable_for_unsupported_versions=True,
silent=False
)
Konfigurację automatycznego rejestrowania można dostosować.
Użycie
Aby użyć automatycznego rejestrowania usługi Databricks, wytrenuj model uczenia maszynowego w obsługiwanej strukturze przy użyciu interaktywnego notesu języka Python usługi Azure Databricks. Automatyczne rejestrowanie w Databricks automatycznie zapisuje informacje o pochodzeniu modelu, parametry i metryki do śledzenia w MLflow. Możesz również dostosować zachowanie funkcji automatycznego rejestrowania w Databricks.
Uwaga
Automatyczne rejestrowanie usługi Databricks nie jest stosowane do przebiegów utworzonych przy użyciu płynnego interfejsu API MLflow z usługą mlflow.start_run(). W takich przypadkach należy wywołać metodę mlflow.autolog(), aby zapisać autonomicznie zalogowaną zawartość do wykonywanej sesji MLflow. Zobacz Śledzenie dodatkowej zawartości.
Dostosowywanie zachowania rejestrowania
Aby dostosować rejestrowanie, użyj metody mlflow.autolog().
Ta funkcja udostępnia parametry konfiguracji umożliwiające logowanie modeli (log_models), rejestrowanie zestawów danych (log_datasets), zbieranie przykładów danych wejściowych (log_input_examples), rejestrowanie podpisów modeli (log_model_signatures), konfigurowanie ostrzeżeń (silent) i wiele więcej.
Śledzenie dodatkowej zawartości
Aby śledzić dodatkowe metryki, parametry, pliki i metadane przy użyciu przebiegów MLflow utworzonych przez funkcję automatycznego rejestrowania usługi Databricks, wykonaj następujące kroki w interaktywnym notesie języka Python usługi Azure Databricks:
- Wywołaj metodę mlflow.autolog() za pomocą polecenia
exclusive=False. - Uruchom przebieg MLflow przy użyciu mlflow.start_run().
To wywołanie można opakowować w pliku
with mlflow.start_run(). Po wykonaniu tego zadania przebieg zostanie automatycznie zakończony. - Użyj metod śledzenia MLflow, takich jak mlflow.log_param(), aby śledzić zawartość przed trenowania.
- Trenowanie co najmniej jednego modelu uczenia maszynowego w strukturze obsługiwanej przez funkcję automatycznego rejestrowania w usłudze Databricks.
- Użyj metod śledzenia MLflow, takich jak mlflow.log_metric(), aby śledzić zawartość po szkoleniu.
- Jeśli nie użyto
with mlflow.start_run()w kroku 2, zakończ przebieg MLflow przy użyciu mlflow.end_run().
Na przykład:
import mlflow
mlflow.autolog(exclusive=False)
with mlflow.start_run():
mlflow.log_param("example_param", "example_value")
# <your model training code here>
mlflow.log_metric("example_metric", 5)
Wyłącz automatyczne rejestrowanie usługi Databricks
Aby wyłączyć automatyczne rejestrowanie usługi Databricks w interaktywnym notesie języka Python usługi Azure Databricks, wywołaj metodę mlflow.autolog() za pomocą polecenia :disable=True
import mlflow
mlflow.autolog(disable=True)
Administratorzy mogą również wyłączyć automatyczne rejestrowanie usługi Databricks dla wszystkich klastrów w obszarze roboczym na karcie Zaawansowane na stronie ustawień administratora. Aby ta zmiana weszła w życie, należy ponownie uruchomić klastry.
Obsługiwane środowiska i struktury
Automatyczne rejestrowanie usługi Databricks jest wspierane w interaktywnych notesach języka Python i jest dostępne dla następujących frameworków uczenia maszynowego:
- scikit-learn
- Apache Spark MLlib
- TensorFlow
- Keras
- Piorun PyTorch
- XGBoost
- LightGBM
- Gluon
- Fast.ai
- statsmodels - biblioteka do modelowania statystycznego
- PaddlePaddle
- Otwarta sztuczna inteligencja
- LangChain
Aby uzyskać więcej informacji na temat każdego z obsługiwanych frameworków, zapoznaj się z sekcją MLflow Automatyczne rejestrowanie.
Włączanie funkcji śledzenia MLflow
Śledzenie MLflow korzysta z funkcji autolog w ramach odpowiednich integracji modelu, aby kontrolować włączanie lub wyłączanie obsługi śledzenia dla integracji, które obsługują śledzenie.
Aby na przykład włączyć śledzenie przy użyciu modelu LlamaIndex, użyj mlflow.llama_index.autolog() z log_traces=True:
import mlflow
mlflow.llama_index.autolog(log_traces=True)
Uwaga
W przypadku bezserwerowych klastrów obliczeniowych automatyczne rejestrowanie śledzenia nie jest automatycznie włączone. Należy jawnie włączyć automatyczne rejestrowanie dla określonych integracji platformy, które mają być śledzone (na przykład mlflow.openai.autolog() lub mlflow.langchain.autolog()).
Obsługiwane integracje z włączoną obsługą śledzenia w ramach implementacji autologu to:
Zarządzanie zabezpieczeniami i danymi
Wszystkie informacje o treningu modelu śledzone za pomocą autologowania Databricks są przechowywane w systemie śledzenia MLflow i są chronione przez uprawnienia do eksperymentów MLflow. Informacje o trenowaniu modelu można udostępniać, modyfikować lub usuwać za pomocą interfejsu API śledzenia MLflow lub interfejsu użytkownika.
Administracja
Administratorzy mogą włączać lub wyłączać automatyczne rejestrowanie Databricks dla wszystkich interaktywnych sesji notatnika w całym obszarze roboczym na karcie Zaawansowane na stronie ustawień administratora. Zmiany nie zostaną zastosowane do momentu ponownego uruchomienia klastra.
Ograniczenia
- Automatyczne rejestrowanie Databricks jest włączone tylko na nodzie sterowniczym klastra usługi Azure Databricks. Aby użyć automatycznego rejestrowania z węzłów procesu roboczego, należy jawnie wywołać metodę mlflow.autolog() z poziomu kodu wykonywanego przez każdy proces roboczy.
- Integracja scikit-learn z XGBoost nie jest obsługiwana.
Apache Spark MLlib, Hyperopt i zautomatyzowane śledzenie za pomocą MLflow
Automatyczne rejestrowanie usługi Databricks nie zmienia zachowania istniejących automatycznych integracji śledzenia MLflow dla Apache Spark MLlib i Hyperopt.
Uwaga
W środowisku Databricks Runtime 10.1 ML wyłączenie automatycznej integracji śledzenia MLflow dla Apache Spark MLlib CrossValidator i TrainValidationSplit modeli powoduje także wyłączenie funkcji automatycznego śledzenia usługi Databricks dla wszystkich modeli Apache Spark MLlib.