Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Model MLflow to standardowy format pakowania modeli uczenia maszynowego, które mogą być używane w różnych narzędziach końcowych — na przykład wnioskowanie wsadowe na platformie Apache Spark lub obsługa w czasie rzeczywistym za pośrednictwem interfejsu API REST. Format definiuje konwencję umożliwiającą zapisywanie modelu w różnych wersjach (python-function, pytorch, sklearn itd.), które są zrozumiałe dla różnych platform obsługujących i inferencji modelu.
Aby dowiedzieć się, jak rejestrować i oceniać model przesyłania strumieniowego, zobacz Jak zapisać i załadować model przesyłania strumieniowego.
MLflow 3 wprowadza znaczące ulepszenia modeli MLflow, wprowadzając nowy, dedykowany LoggedModel obiekt z własnymi metadanymi, takimi jak metryki i parametry. Aby uzyskać więcej informacji, zobacz Śledzenie i porównywanie modeli przy użyciu modeli zarejestrowanych przez platformę MLflow.
Modele rejestrowania i ładowania
Podczas rejestrowania modelu narzędzie MLflow automatycznie rejestruje requirements.txt i conda.yaml pliki. Tych plików można użyć do odtworzenia środowiska deweloperskiego modelu i reinstalacji zależności przy użyciu virtualenv (zalecane) lub conda.
Ważne
Anaconda Inc. zaktualizowała swoje warunki świadczenia usług dla kanałów anaconda.org. Na podstawie nowych warunków świadczenia usług może być konieczne uzyskanie licencji komercyjnej, jeśli polegasz na pakietowaniu i dystrybucji Anaconda. Aby uzyskać więcej informacji, zobacz Często zadawane pytania dotyczące wersji komercyjnej Anaconda. Korzystanie z jakichkolwiek kanałów Anaconda podlega warunkom świadczenia usług.
Modele MLflow zarejestrowane przed wersją 1.18 (Databricks Runtime 8.3 ML lub starsze) były domyślnie rejestrowane przy użyciu kanału Conda defaults (https://repo.anaconda.com/pkgs/) jako zależności. Ze względu na tę zmianę licencji usługa Databricks zatrzymała korzystanie z kanału defaults dla modeli zarejestrowanych przy użyciu platformy MLflow w wersji 1.18 lub nowszej. Zarejestrowany kanał domyślny to teraz conda-forge, co wskazuje na https://conda-forge.org/ zarządzaną przez społeczność.
Jeśli model został zarejestrowany przed MLflow w wersji 1.18, bez wykluczania kanału defaults ze środowiska conda dla modelu, może mieć zależność od kanału defaults, której prawdopodobnie nie zamierzałeś/aś.
Aby ręcznie potwierdzić, czy model ma tę zależność, możesz sprawdzić channel wartość pliku conda.yaml spakowanego razem z zarejestrowanym modelem. Na przykład model conda.yaml z zależnością kanału defaults może wyglądać następująco:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Ponieważ usługa Databricks nie może określić, czy korzystanie z repozytorium Anaconda do interakcji z modelami jest dozwolone w ramach relacji z platformą Anaconda, usługa Databricks nie zmusza swoich klientów do wprowadzania żadnych zmian. Jeśli korzystanie z repozytorium Anaconda.com za pośrednictwem korzystania z usługi Databricks jest dozwolone zgodnie z warunkami platformy Anaconda, nie musisz podejmować żadnych działań.
Jeśli chcesz zmienić kanał używany w środowisku modelu, możesz ponownie zarejestrować model w rejestrze modeli przy użyciu nowego conda.yamlelementu . Można to zrobić, określając kanał w parametrze conda_envlog_model().
Aby uzyskać więcej informacji na temat interfejsu log_model() API, zobacz dokumentację platformy MLflow dotyczącą odmiany modelu, z którą pracujesz, na przykład log_model dla biblioteki scikit-learn.
Aby uzyskać więcej informacji na conda.yaml temat plików, zobacz dokumentację platformy MLflow.
Polecenia interfejsu API
Aby zarejestrować model na serwerze śledzenia MLflow
Aby załadować wcześniej zarejestrowany model do wnioskowania lub dalszego programowania, użyj mlflow.<model-type>.load_model(modelpath), gdzie modelpath jest jednym z następujących elementów:
- ścieżka modelu (na przykład
models:/{model_id}) (tylko MLflow 3 ) - ścieżka względna przebiegu (na przykład
runs:/{run_id}/{model-path}) - ścieżka woluminów Unity Catalog (na przykład
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - ścieżka magazynu artefaktów zarządzanych przez platformę MLflow rozpoczynająca się od
dbfs:/databricks/mlflow-tracking/ - Ścieżka zarejestrowanego modelu (na przykład
models:/{model_name}/{model_stage}).
Aby uzyskać pełną listę opcji ładowania modeli MLflow, zobacz Odwoływanie się do artefaktów w dokumentacji platformy MLflow.
W przypadku modeli MLflow w języku Python, dodatkową opcją jest załadowanie modelu jako ogólnej funkcji Pythona przy użyciu mlflow.pyfunc.load_model().
Poniższy fragment kodu służy do ładowania modelu i oceniania punktów danych.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
Alternatywnie możesz wyeksportować model jako funkcję UDF Apache Spark do użycia do oceniania wyników w klastrze Spark jako zadania wsadowego lub zadań strumieniowych Spark w czasie rzeczywistym.
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
Zależności modelu dzienników systemu logowania
Aby dokładnie załadować model, upewnij się, że zależności modelu są ładowane z odpowiednimi wersjami do środowiska notebooka. W środowisku Databricks Runtime 10.5 ML i nowszym platforma MLflow ostrzega, jeśli między bieżącym środowiskiem a zależnościami modelu zostanie wykryta niezgodność.
Dodatkowe funkcje upraszczające przywracanie zależności modelu są uwzględniane w środowisku Databricks Runtime 11.0 ML i nowszym. W środowisku Databricks Runtime 11.0 ML i nowszym dla pyfunc modeli typu "flavor" można wywołać metodę mlflow.pyfunc.get_model_dependencies, aby uzyskać i pobrać zależności modelu. Ta funkcja zwraca ścieżkę do pliku zależności, który można następnie zainstalować przy użyciu polecenia %pip install <file-path>. Podczas ładowania modelu jako UDF PySpark należy określić env_manager="virtualenv" w wywołaniu mlflow.pyfunc.spark_udf. To przywraca zależności modelu w kontekście PySpark UDF i nie wpływa na środowisko zewnętrzne.
Możesz również użyć tej funkcji w środowisku Databricks Runtime 10.5 lub nowszym, ręcznie instalując bibliotekę MLflow w wersji 1.25.0 lub nowszej:
%pip install "mlflow>=1.25.0"
Aby uzyskać dodatkowe informacje na temat rejestrowania zależności modelu (Python i nienależących do Python) oraz artefaktów, zobacz Log model dependencies.
Dowiedz się, jak rejestrować zależności modelu i niestandardowe artefakty na potrzeby obsługi modelu:
- Wdrażanie modeli z zależnościami
- Używanie niestandardowych bibliotek języka Python z obsługą modelu
- Tworzenie pakietów artefaktów niestandardowych na potrzeby obsługi modelu
Automatycznie wygenerowane fragmenty kodu w interfejsie użytkownika platformy MLflow
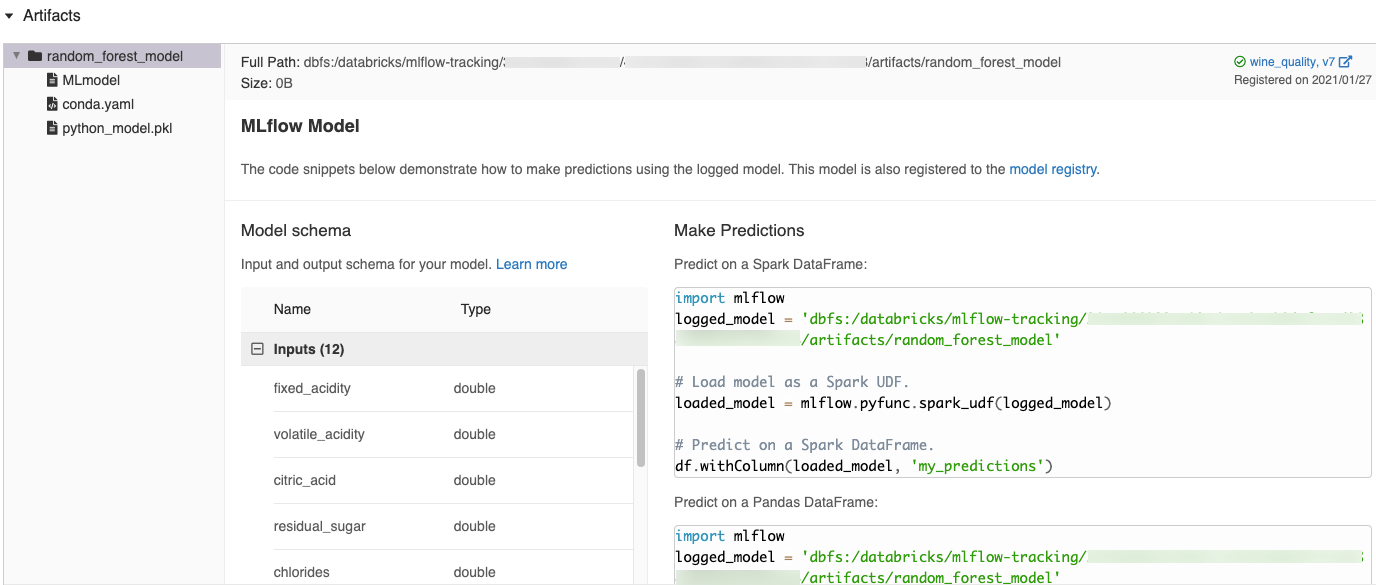
Podczas rejestrowania modelu w notesie usługi Azure Databricks usługa Azure Databricks automatycznie generuje fragmenty kodu, które można skopiować i użyć do załadowania i uruchomienia modelu. Aby wyświetlić te fragmenty kodu:
- Przejdź do ekranu Przebiegi dla przebiegu, który wygenerował model. (Zobacz Wyświetl eksperyment notesu, aby zobaczyć ekran uruchomień).
- Przewiń do sekcji Artifacts.
- Kliknij nazwę zarejestrowanego modelu. Po prawej stronie zostanie otwarty panel przedstawiający kod, którego można użyć do załadowania zarejestrowanego modelu i przewidywania na ramkach danych platformy Spark lub biblioteki pandas.
Przykłady
Przykłady modeli rejestrowania można znaleźć w przykładach śledzenia przebiegów treningowych uczenia maszynowego.
Rejestrowanie modeli w rejestrze modeli
Modele można zarejestrować w rejestrze modeli MLflow, scentralizowanym magazynie modeli, który udostępnia interfejs użytkownika i zestaw interfejsów API do zarządzania pełnym cyklem życia modeli MLflow. Aby uzyskać instrukcje dotyczące korzystania z Model Registry do zarządzania modelami w Unity Catalog Databricks, zobacz Zarządzanie cyklem życia modelu w Unity Catalog. Aby użyć rejestru modeli obszaru roboczego, zobacz Zarządzanie cyklem życia modelu przy użyciu rejestru modeli obszaru roboczego (starsza wersja).
Gdy modele utworzone za pomocą MLflow 3 są rejestrowane w rejestrze modeli katalogu Unity, można wyświetlać dane, takie jak parametry i metryki, w jednej centralnej lokalizacji, we wszystkich eksperymentach i przestrzeniach roboczych. Aby uzyskać więcej informacji, zobacz Ulepszenia rejestru modeli za pomocą biblioteki MLflow 3.
Aby zarejestrować model przy użyciu interfejsu API, użyj następującego polecenia:
MLflow 3
mlflow.register_model("models:/{model_id}", "{registered_model_name}")
MLflow 2.x
mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}")
Zapisz modele w woluminach Unity Catalog
Aby zapisać model lokalnie, użyj polecenia mlflow.<model-type>.save_model(model, modelpath).
modelpath musi być ścieżką woluminów Unity Catalog . Jeśli na przykład używasz lokalizacji woluminów w katalogu Unity dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models do przechowywania swojej pracy nad projektem, musisz użyć ścieżki modelu /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models:
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
W przypadku modeli MLlib użyj potoków uczenia maszynowego.
Pobieranie artefaktów modelu
Zarejestrowane artefakty modelu (takie jak pliki modelu, wykresy i metryki) można pobrać dla zarejestrowanego modelu z różnymi interfejsami API.
Przykład interfejsu API języka Python:
mlflow.set_registry_uri("databricks-uc")
mlflow.artifacts.download_artifacts(f"models:/{model_name}/{model_version}")
Przykład interfejsu API języka Java:
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
Wdrażanie modeli na potrzeby obsługi online
Notatka
Przed wdrożeniem modelu warto sprawdzić, czy model jest w stanie być serwowany. Zapoznaj się z dokumentacją platformy MLflow, aby dowiedzieć się, jak można użyć mlflow.models.predict do weryfikacji modeli przed wdrożeniem.
Użyj modelu mozaiki AI obsługiwanego przez do hostowania modeli uczenia maszynowego zarejestrowanych w rejestrze modeli w katalogu Unity jako punkty końcowe REST. Te punkty końcowe są aktualizowane automatycznie na podstawie dostępności wersji modelu.