Powolny etap platformy Spark z małą ilością operacji we/wy
Jeśli masz powolny etap z nie dużą wielką ilością operacji we/wy, może to być spowodowane przez:
- Odczytywanie wielu małych plików
- Pisanie wielu małych plików
- Powolne funkcje zdefiniowane przez użytkownika
- Dołącz do Kartezjańskiego
- Przyłączanie eksplodujące
Prawie wszystkie te problemy można zidentyfikować przy użyciu grupy DAG SQL.
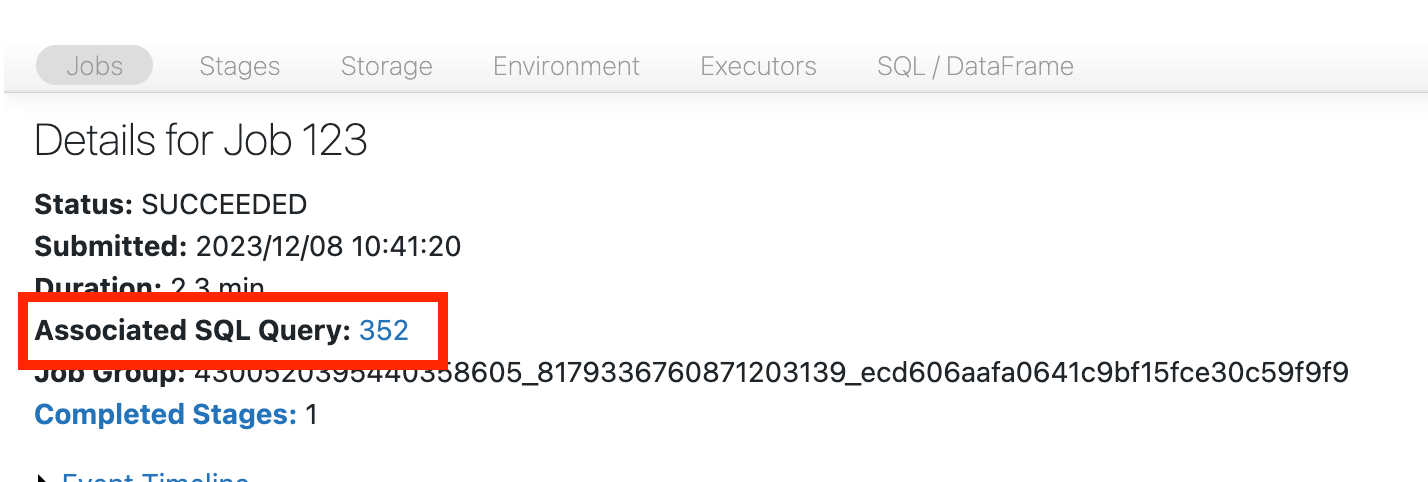
Otwórz grupę DAG SQL
Aby otworzyć grupę DAG SQL, przewiń w górę do góry strony zadania i kliknij pozycję Skojarzone zapytanie SQL:
Powinna zostać wyświetlona grupa DAG. Jeśli nie, przewiń nieco i powinien zostać wyświetlony:
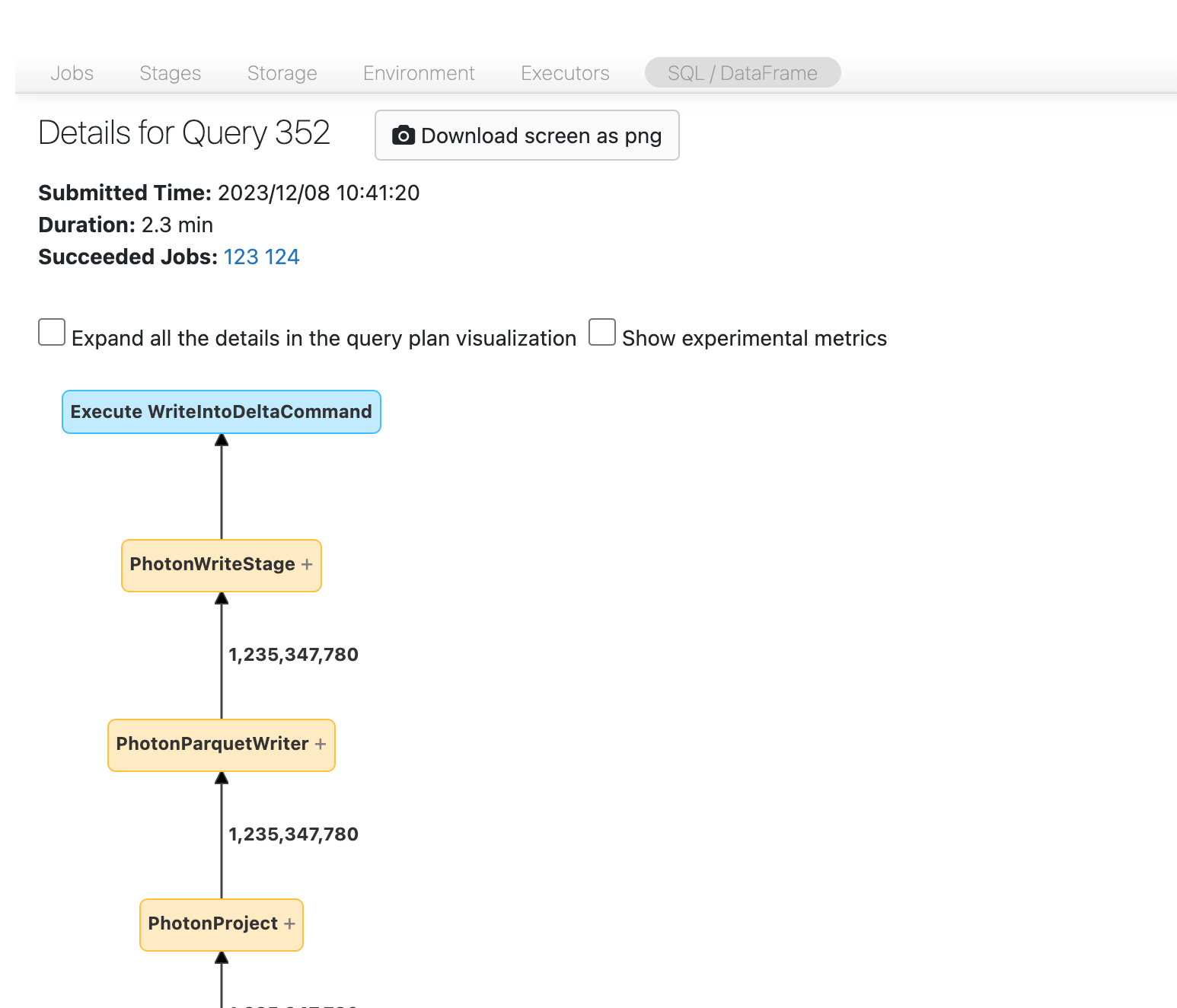
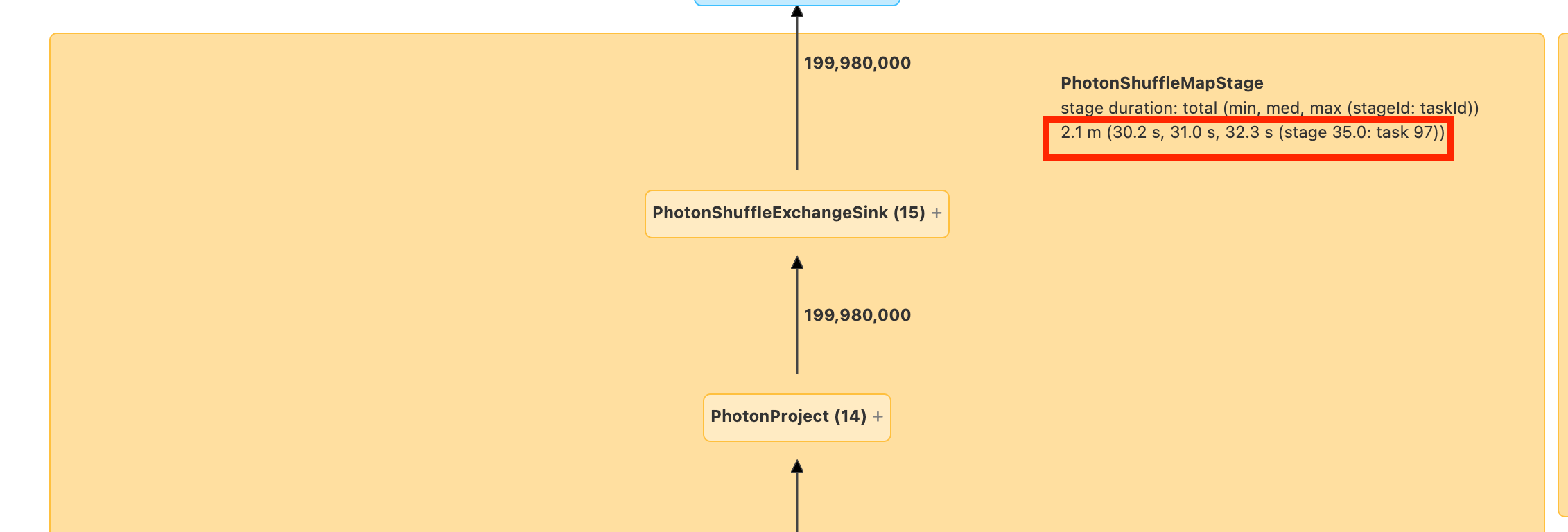
Zanim przejdziesz dalej, zapoznaj się z grupą DAG i miejscem, w którym spędzasz czas. Niektóre węzły w grupie DAG mają przydatne informacje o czasie, a inne nie. Na przykład ten blok trwał 2,1 minuty, a nawet udostępnia identyfikator etapu:
Ten węzeł wymaga otwarcia go, aby zobaczyć, że zajęło to 1,4 minuty:
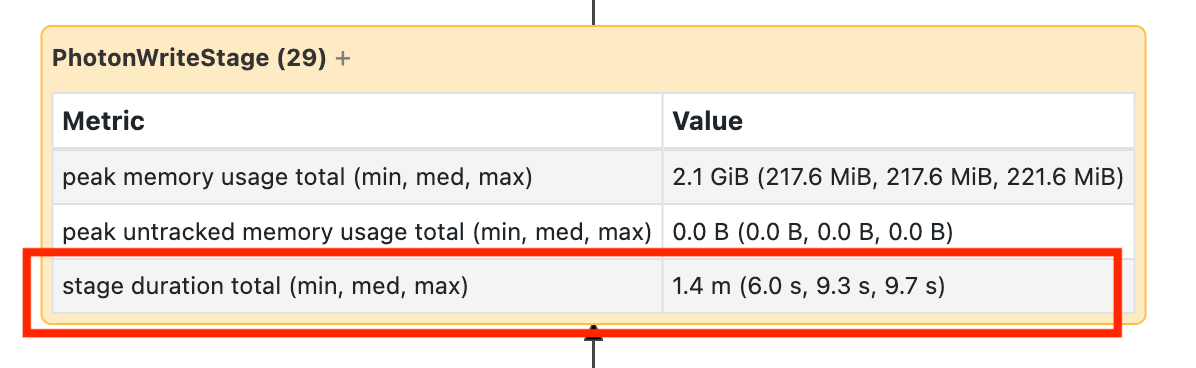
Te czasy są skumulowane, więc jest to łączny czas spędzony na wszystkich zadaniach, a nie czas zegara. Ale nadal jest to bardzo przydatne, ponieważ są one skorelowane z zegarem i kosztami.
Warto zapoznać się z tym, gdzie w DAG jest poświęcany czas.
Odczytywanie wielu małych plików
Jeśli widzisz, że jeden z operatorów skanowania zajmuje dużo czasu, otwórz go i poszukaj liczby odczytanych plików:
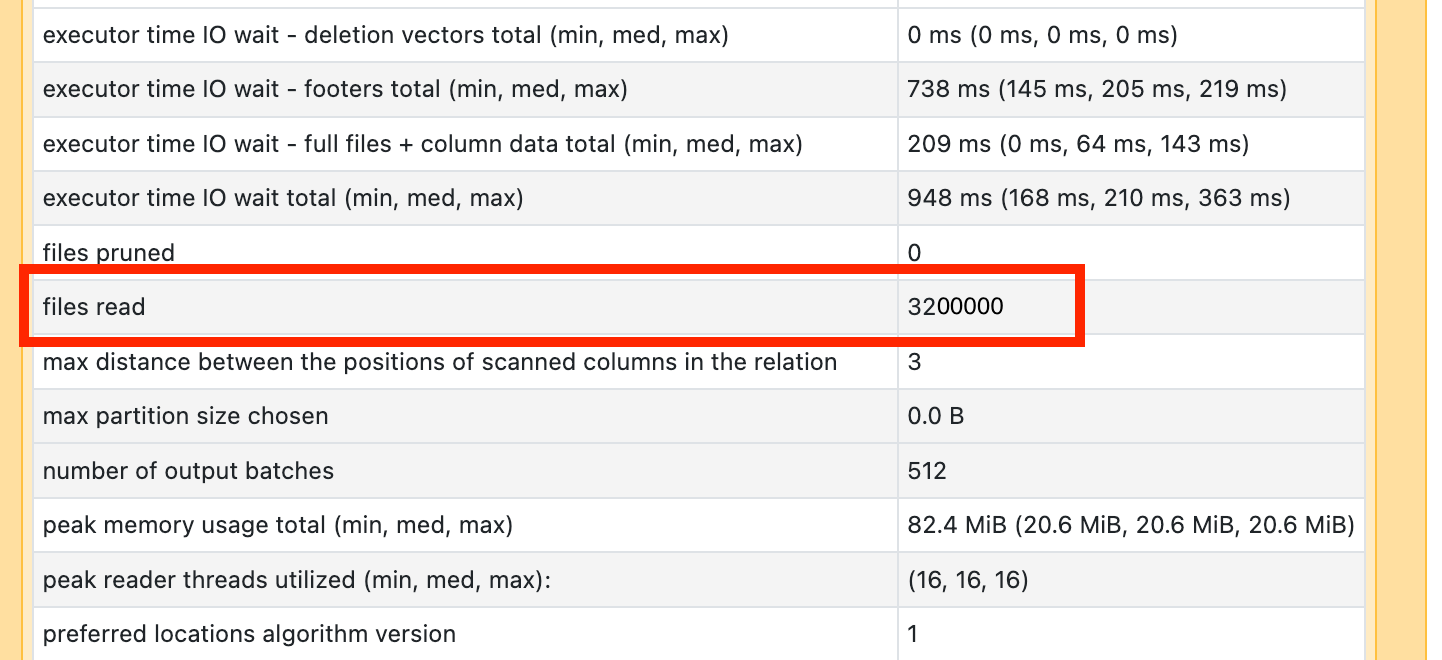
Jeśli czytasz dziesiątki tysięcy plików lub więcej, być może masz mały problem z plikiem. Pliki nie powinny być mniejsze niż 8 MB. Problem z małym plikiem jest najczęściej spowodowany partycjonowaniem zbyt wielu kolumn lub kolumną o wysokiej kardynalności.
Jeśli masz szczęście, może być konieczne uruchomienie polecenia OPTIMIZE. Niezależnie od tego, należy ponownie rozważyć układ pliku.
Pisanie wielu małych plików
Jeśli widzisz, że zapis trwa długo, otwórz go i poszukaj liczby plików oraz ilości zapisanych danych:
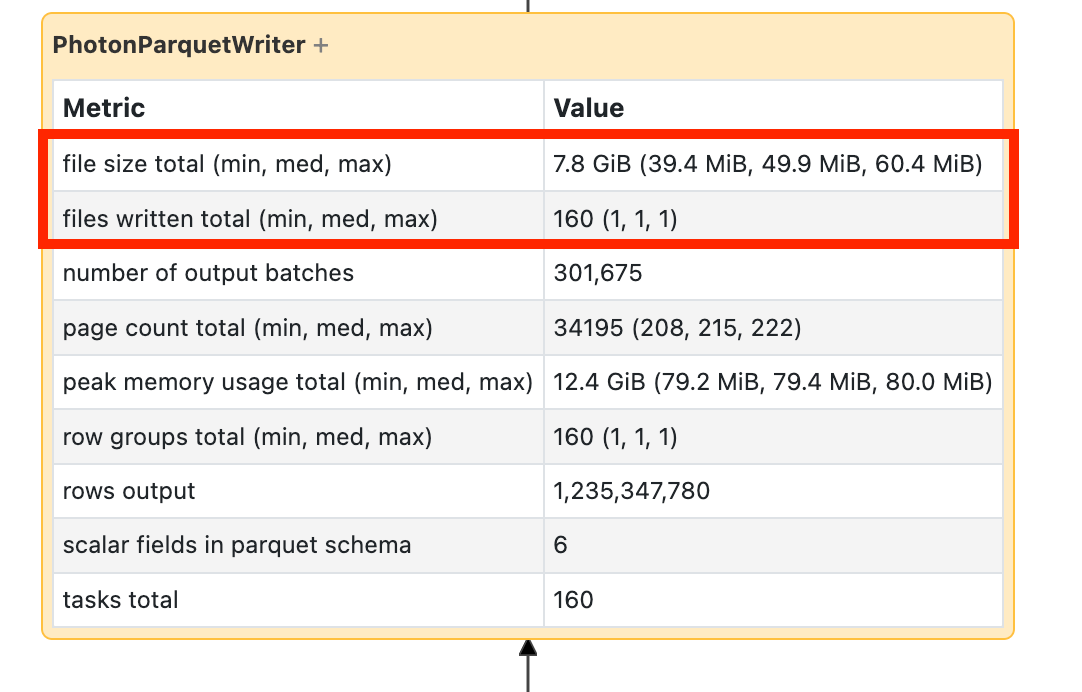
Jeśli piszesz dziesiątki tysięcy plików lub więcej, być może masz mały problem z plikiem. Pliki nie powinny być mniejsze niż 8 MB. Problem z małym plikiem jest najczęściej spowodowany partycjonowaniem zbyt wielu kolumn lub kolumną o wysokiej kardynalności. Należy ponownie rozważyć układ pliku lub włączyć zoptymalizowane zapisy.
Powolne funkcje zdefiniowane przez użytkownika
Jeśli wiesz, że masz funkcje zdefiniowane przez użytkownika lub widzisz coś takiego w grupie DAG, możesz cierpieć na powolne funkcje zdefiniowane przez użytkownika:
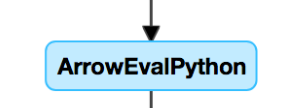
Jeśli uważasz, że cierpisz na ten problem, spróbuj dodać komentarz do funkcji zdefiniowanej przez użytkownika, aby zobaczyć, jak ma to wpływ na szybkość potoku. Jeśli funkcja UDF jest rzeczywiście miejscem, w którym jest poświęcany czas, najlepszym rozwiązaniem jest ponowne zapisywanie funkcji zdefiniowanej przez użytkownika przy użyciu funkcji natywnych. Jeśli nie jest to możliwe, rozważ liczbę zadań na etapie wykonywania funkcji zdefiniowanej przez użytkownika. Jeśli liczba rdzeni w klastrze jest mniejsza niż liczba rdzeni, repartition() ramka danych przed użyciem funkcji zdefiniowanej przez użytkownika:
(df
.repartition(num_cores)
.withColumn('new_col', udf(...))
)
Funkcje zdefiniowane przez użytkownika mogą również mieć problemy z pamięcią. Należy wziąć pod uwagę, że każde zadanie może wymagać załadowania wszystkich danych w partycji do pamięci. Jeśli te dane są zbyt duże, rzeczy mogą być bardzo powolne lub niestabilne. Ponowne dzielenie może również rozwiązać ten problem, co zmniejsza każde zadanie.
Dołącz do Kartezjańskiego
Jeśli widzisz sprzężenia kartezjańskiego lub zagnieżdżonego sprzężenia pętli w grupie DAG, musisz wiedzieć, że te sprzężenia są bardzo kosztowne. Upewnij się, że to, co zamierzasz i sprawdź, czy istnieje inny sposób.
Eksplodowanie sprzężenia lub eksplodowanie
Jeśli zobaczysz kilka wierszy przechodzących do węzła i większej liczby wielkości wychodzących, możesz cierpieć na eksplodujące sprzężenie lub eksplodowanie():

Przeczytaj więcej na temat eksplodów w przewodniku dotyczącym optymalizacji usługi Databricks.