Samouczek: implementowanie usługi Azure Databricks przy użyciu punktu końcowego usługi Azure Cosmos DB
W tym samouczku opisano sposób implementowania środowiska usługi Databricks ze wstrzykniętą siecią wirtualną z włączonym punktem końcowym usługi dla usługi Azure Cosmos DB.
Z tego samouczka dowiesz się, jak wykonywać następujące działania:
- Tworzenie obszaru roboczego usługi Azure Databricks w sieci wirtualnej
- Tworzenie punktu końcowego usługi Azure Cosmos DB
- Tworzenie konta usługi Azure Cosmos DB i importowanie danych
- Tworzenie klastra usługi Azure Databricks
- Wykonywanie zapytań względem usługi Azure Cosmos DB z notesu usługi Azure Databricks
Wymagania wstępne
Przed rozpoczęciem wykonaj następujące czynności:
Utwórz obszar roboczy usługi Azure Databricks w sieci wirtualnej.
Pobierz łącznik Spark.
Pobierz przykładowe dane z krajowych centrów NOAA for Environmental Information. Wybierz stan lub obszar i wybierz pozycję Wyszukaj. Na następnej stronie zaakceptuj wartości domyślne i wybierz pozycję Wyszukaj. Następnie wybierz pozycję Pobierz PLIK CSV po lewej stronie, aby pobrać wyniki.
Pobierz wstępnie skompilowany plik binarny narzędzia do migracji danych usługi Azure Cosmos DB.
Tworzenie punktu końcowego usługi Azure Cosmos DB
Po wdrożeniu obszaru roboczego usługi Azure Databricks w sieci wirtualnej przejdź do sieci wirtualnej w Azure Portal. Zwróć uwagę na podsieci publiczne i prywatne utworzone we wdrożeniu usługi Databricks.
Wybierz podsieć publiczną i utwórz punkt końcowy usługi Azure Cosmos DB. Następnie zapisz.
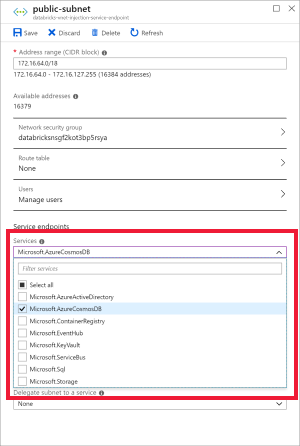
Tworzenie konta usługi Azure Cosmos DB
Otwórz Azure Portal. W lewym górnym rogu ekranu wybierz pozycję Utwórz zasób > Bazy danych > Azure Cosmos DB.
Wypełnij szczegóły wystąpienia na karcie Podstawy przy użyciu następujących ustawień:
Ustawienie Wartość Subskrypcji Twoja subskrypcja Grupa zasobów grupa zasobów Nazwa konta db-vnet-service-endpoint API Core (SQL) Lokalizacji Zachodnie stany USA Geo-Redundancy Wyłączyć Zapisy w wielu regionach Włączyć 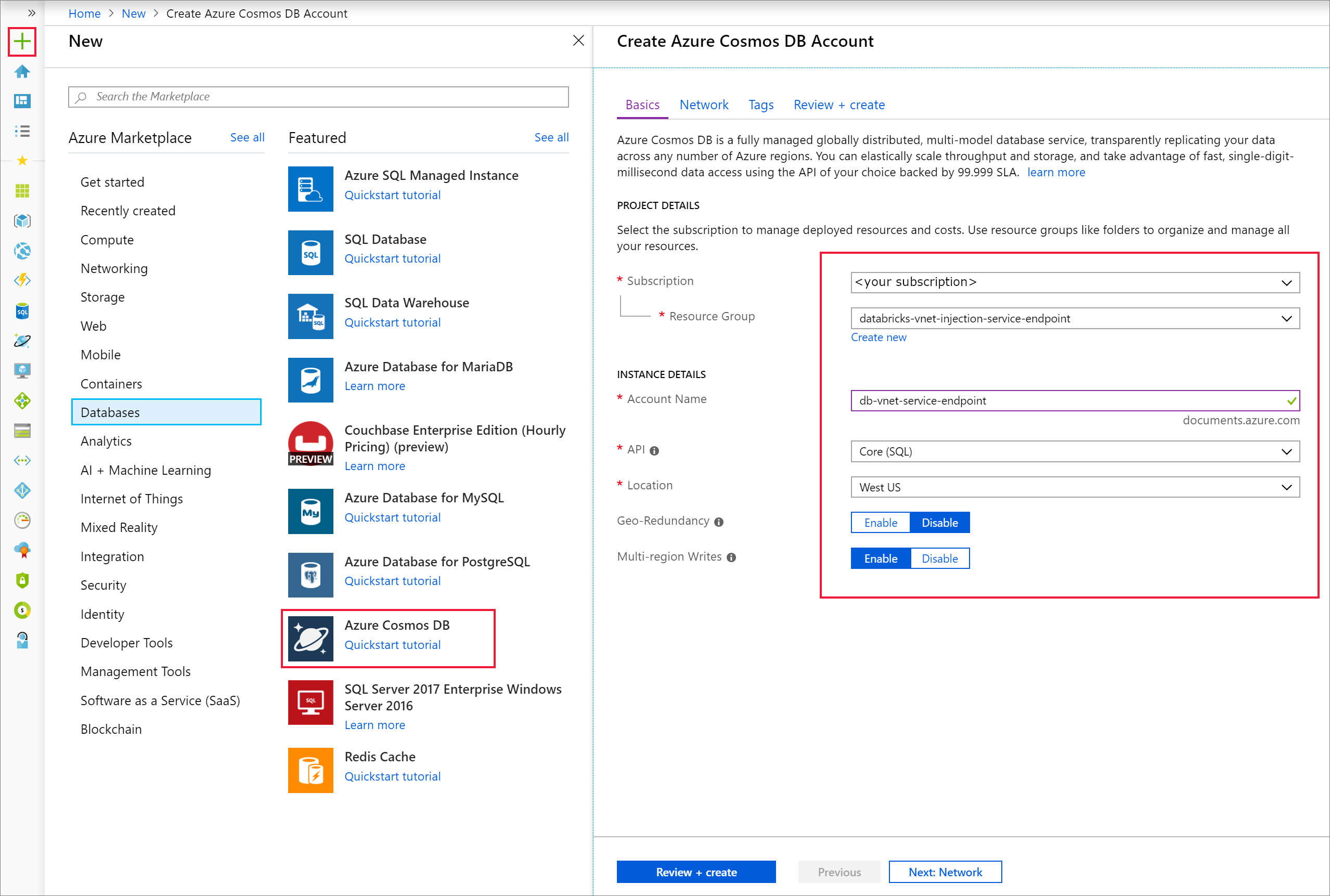
Wybierz kartę Sieć i skonfiguruj sieć wirtualną.
A. Wybierz sieć wirtualną utworzoną jako wymaganie wstępne, a następnie wybierz pozycję public-subnet. Zwróć uwagę, że w podsieci prywatnejbrakuje uwagi "Brak punktu końcowego bazy danych Microsoft AzureCosmosDB". Dzieje się tak, ponieważ włączono tylko punkt końcowy usługi Azure Cosmos DB w podsieci publicznej.
B. Upewnij się, że masz włączoną opcję Zezwalaj na dostęp z Azure Portal. To ustawienie umożliwia dostęp do konta usługi Azure Cosmos DB z Azure Portal. Jeśli ta opcja jest ustawiona na Odmów, podczas próby uzyskania dostępu do konta zostaną wyświetlone błędy.
Uwaga
Nie jest to konieczne w tym samouczku, ale możesz również włączyć opcję Zezwalaj na dostęp z mojego adresu IP , jeśli chcesz mieć dostęp do konta usługi Azure Cosmos DB z komputera lokalnego. Jeśli na przykład nawiązujesz połączenie z kontem przy użyciu zestawu SDK usługi Azure Cosmos DB, musisz włączyć to ustawienie. Jeśli jest wyłączona, wystąpią błędy "Odmowa dostępu".
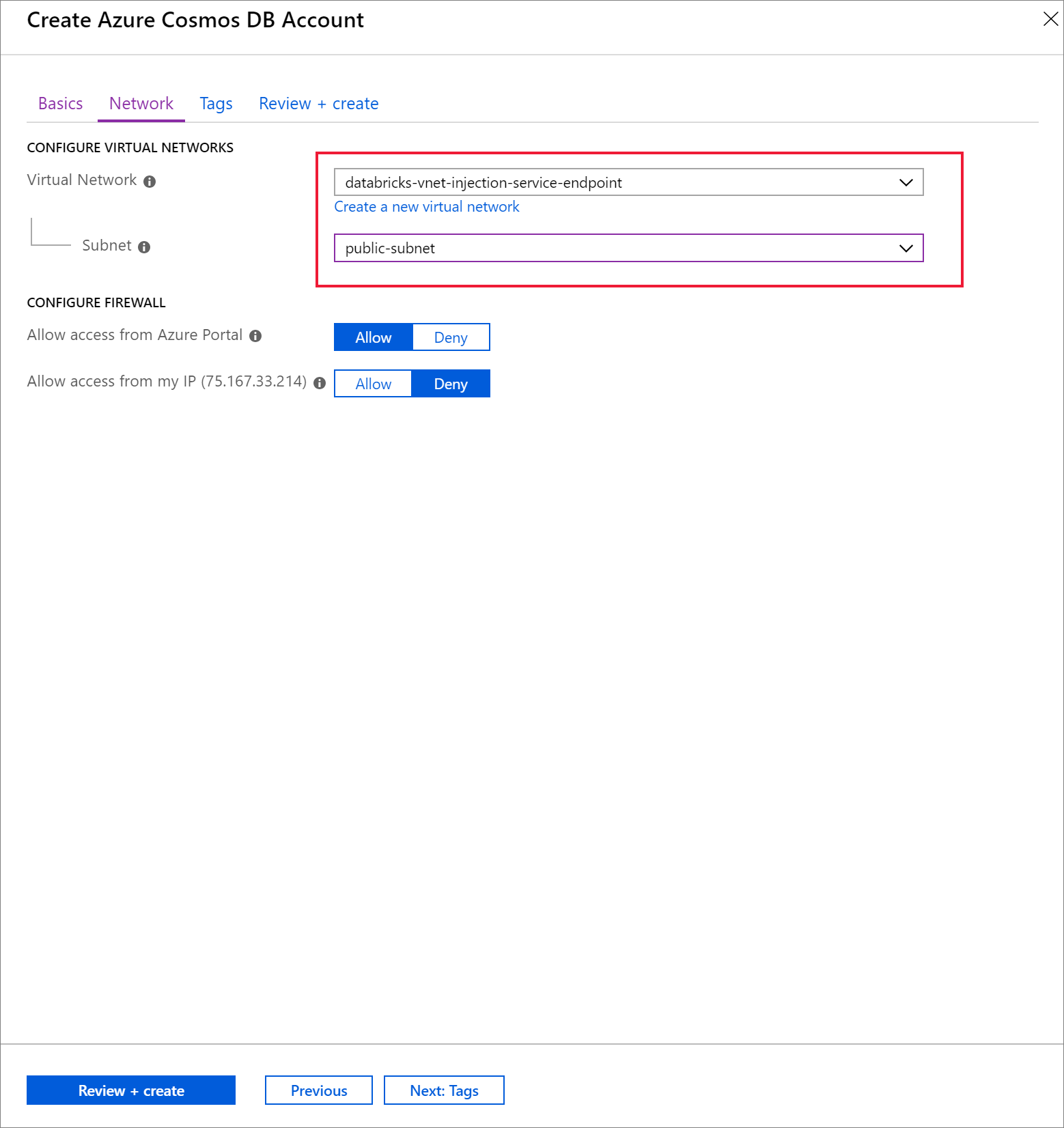
Wybierz pozycję Przejrzyj i utwórz, a następnie pozycję Utwórz , aby utworzyć konto usługi Azure Cosmos DB w sieci wirtualnej.
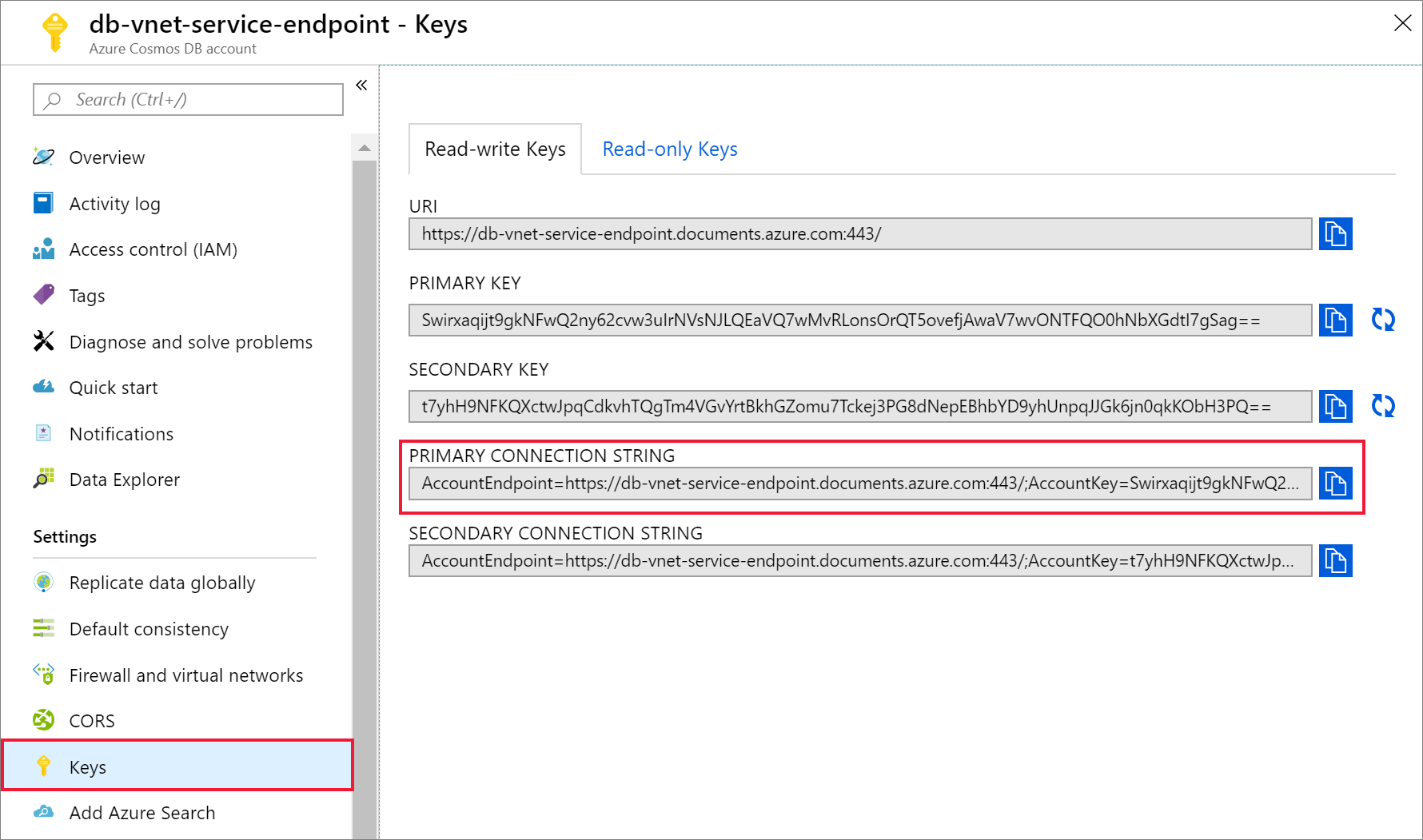
Po utworzeniu konta usługi Azure Cosmos DB przejdź do pozycji Klucze w obszarze Ustawienia. Skopiuj podstawowe parametry połączenia i zapisz je w edytorze tekstów do późniejszego użycia.
Wybierz pozycję Data Explorer i Nowy kontener, aby dodać nową bazę danych i kontener do konta usługi Azure Cosmos DB.
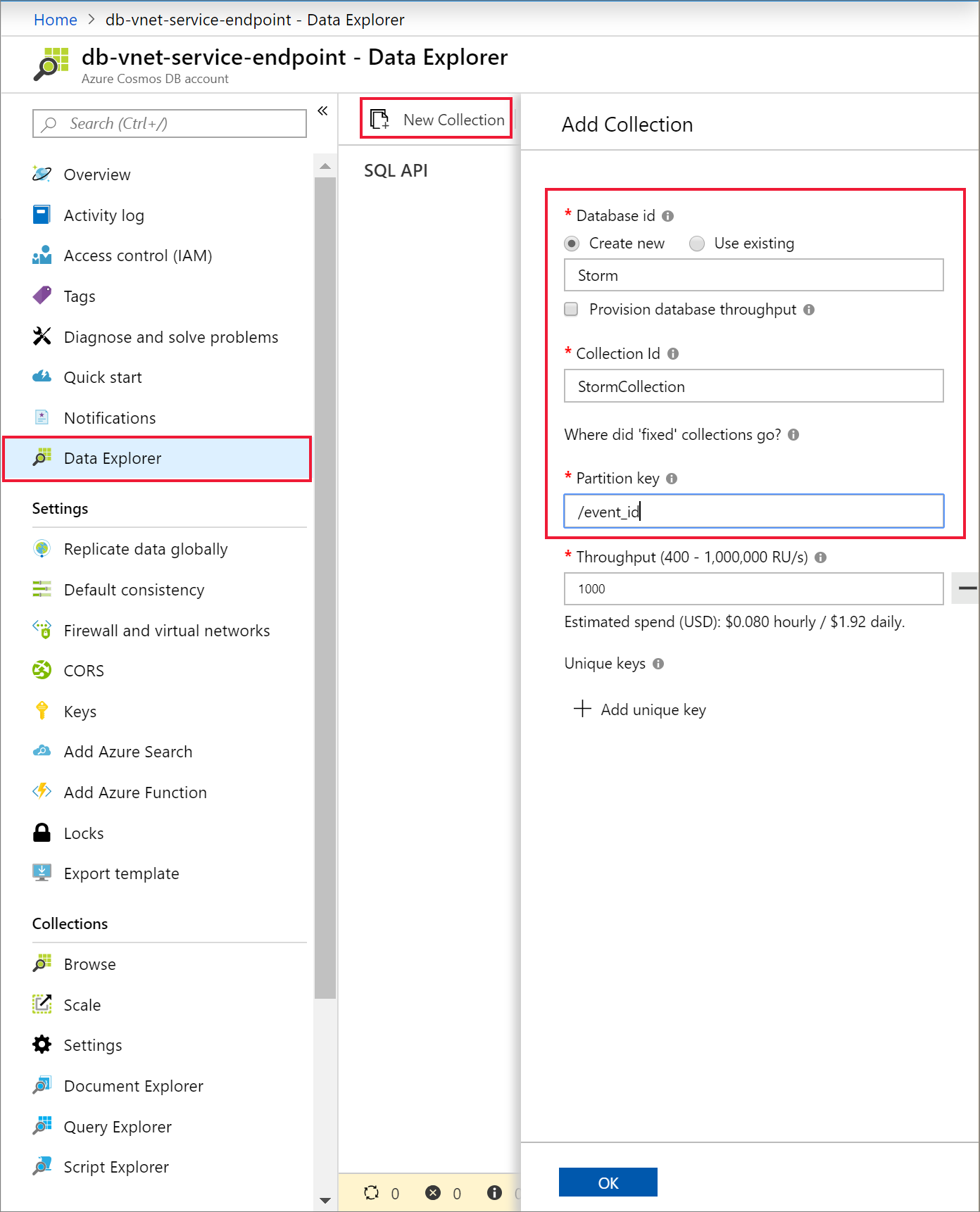
Przekazywanie danych do usługi Azure Cosmos DB
Otwórz wersję interfejsu graficznego narzędzia do migracji danych dla usługi Azure Cosmos DB,Dtui.exe.
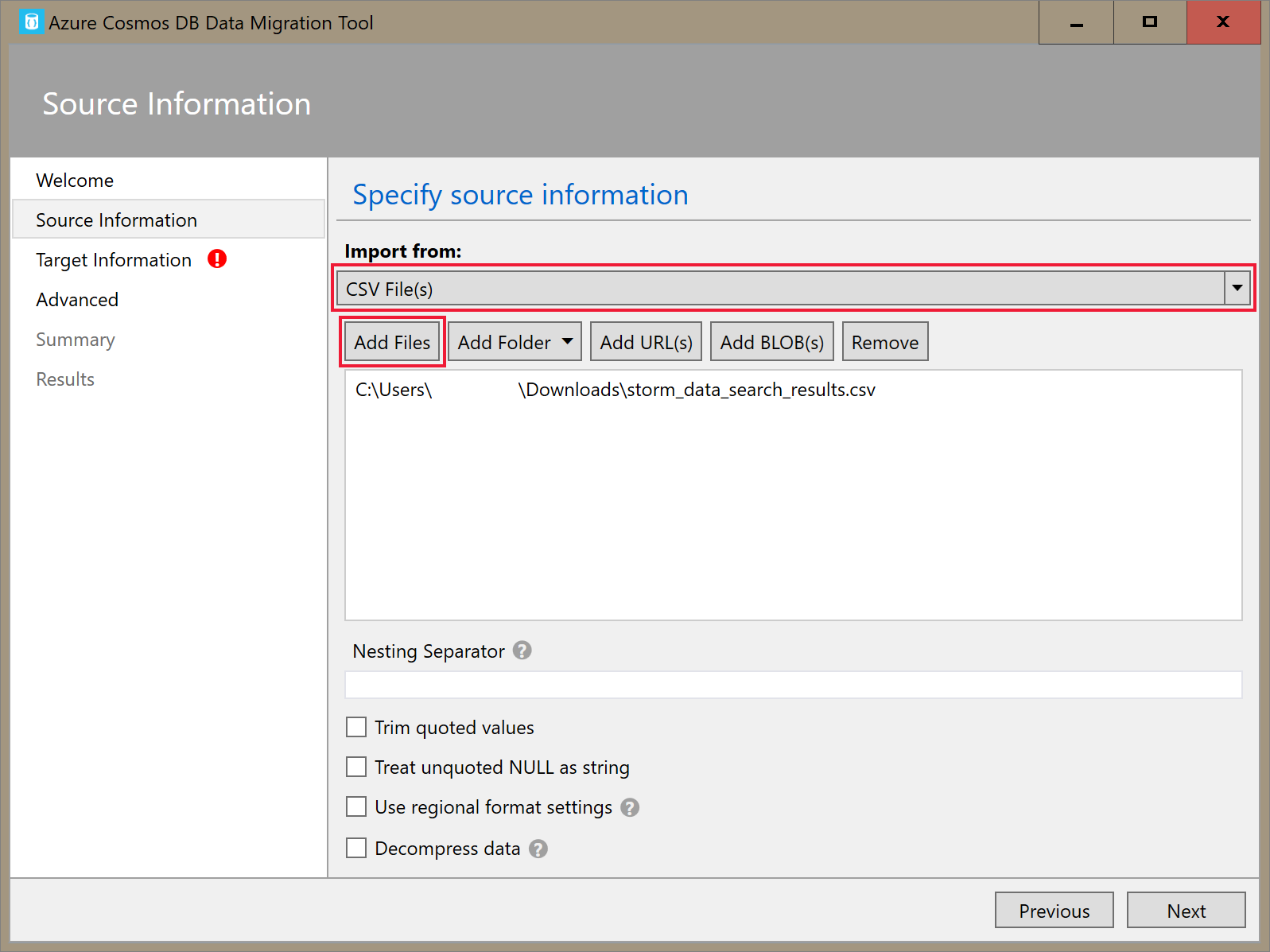
Na karcie Informacje o źródle wybierz pozycję Pliki CSV na liście rozwijanej Importuj z . Następnie wybierz pozycję Dodaj pliki i dodaj pobrany plik CSV danych storm jako wymaganie wstępne.
Na karcie Informacje o obiekcie docelowym wprowadź parametry połączenia. Format parametrów połączenia to
AccountEndpoint=<URL>;AccountKey=<key>;Database=<database>. Parametry połączenia AccountEndpoint i AccountKey są uwzględniane w podstawowych parametrach połączenia zapisanych w poprzedniej sekcji. DołączDatabase=<your database name>ciąg na końcu parametrów połączenia, a następnie wybierz pozycję Weryfikuj. Następnie dodaj nazwę kontenera i klucz partycji.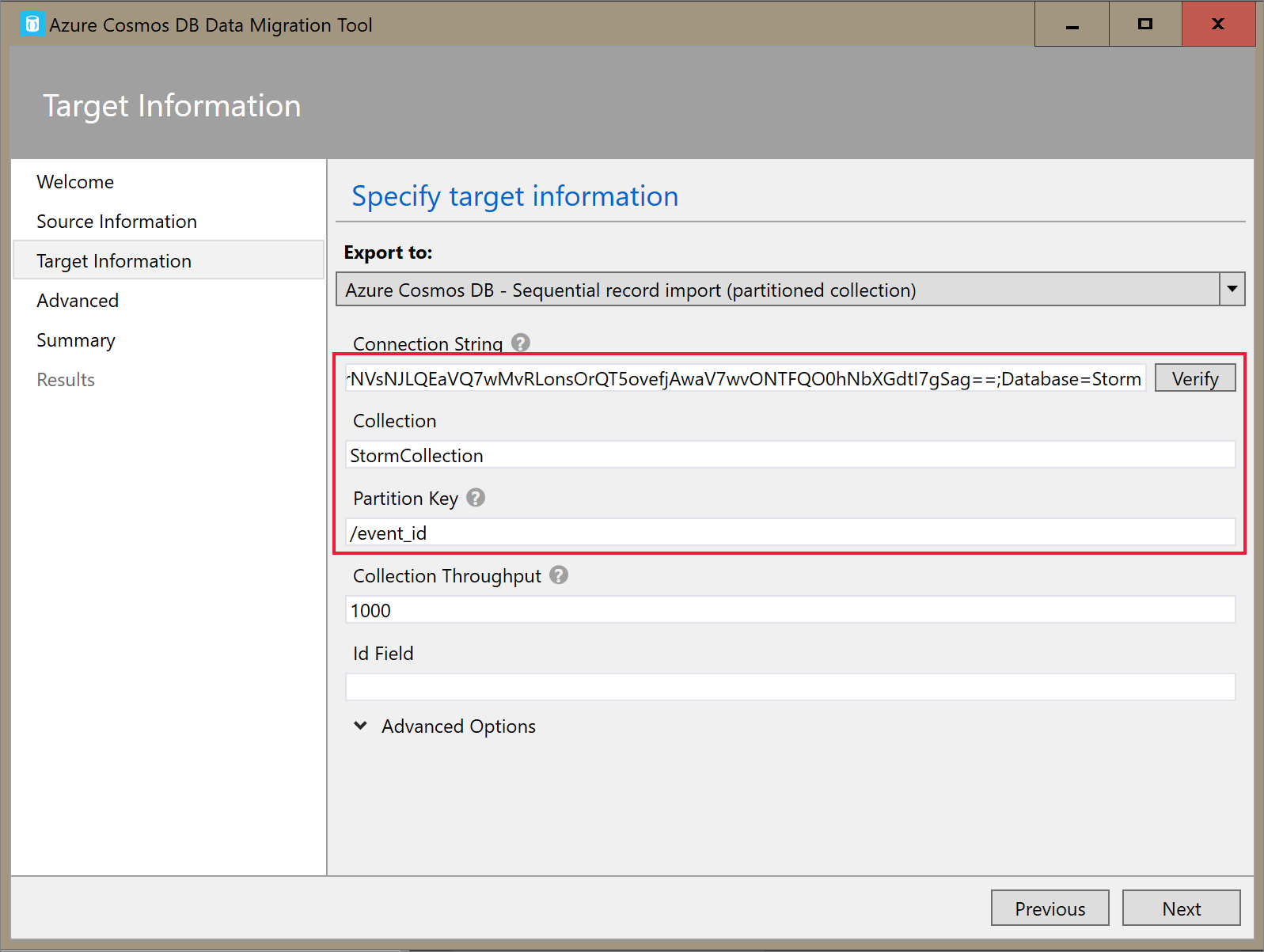
Wybierz przycisk Dalej , dopóki nie zostanie wyświetlona strona Podsumowanie. Następnie wybierz pozycję Importuj.
Tworzenie klastra i dodawanie biblioteki
Przejdź do usługi Azure Databricks w Azure Portal i wybierz pozycję Uruchom obszar roboczy.
Utwórz nowy klaster. Wybierz nazwę klastra i zaakceptuj pozostałe ustawienia domyślne.
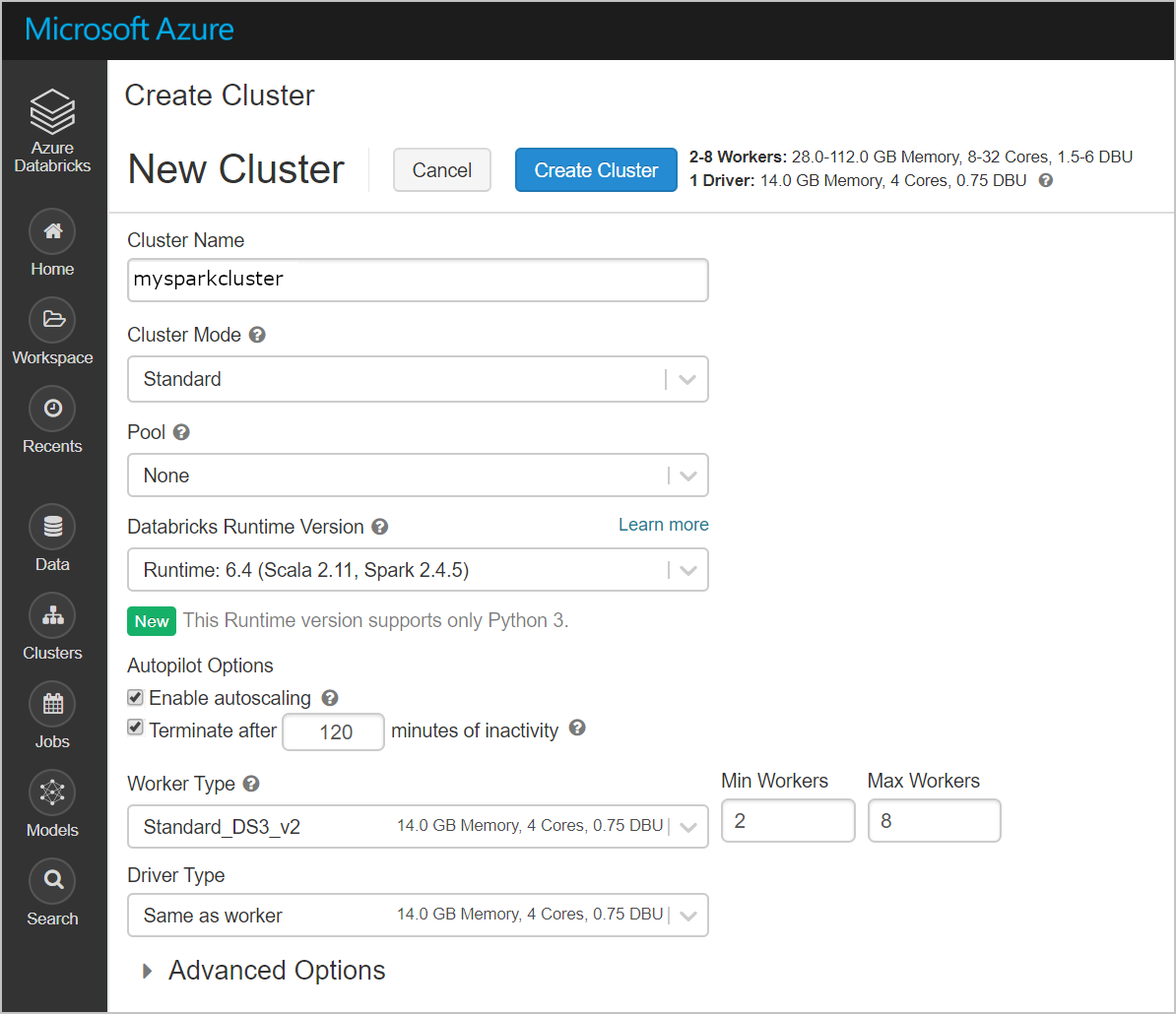
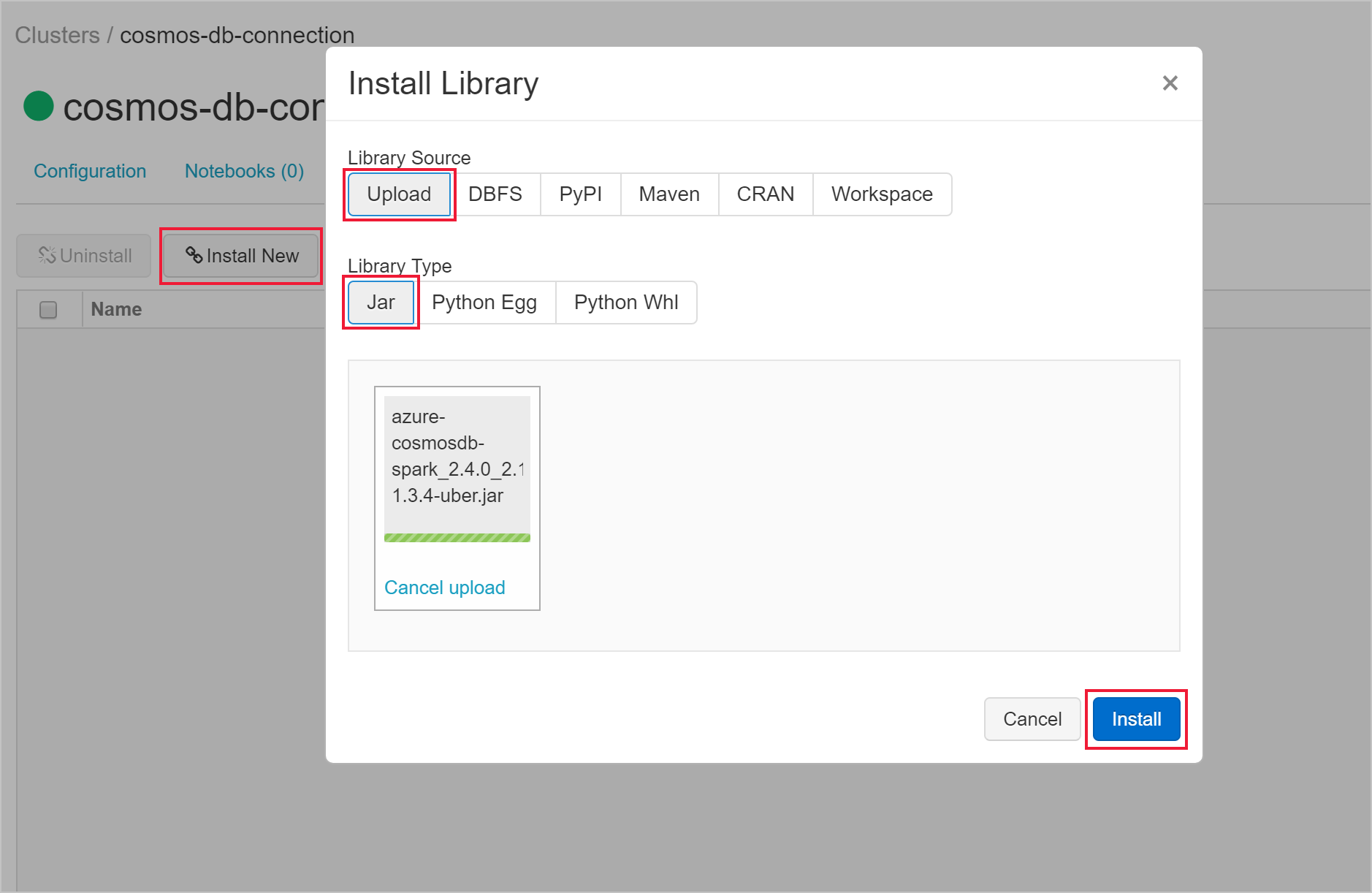
Po utworzeniu klastra przejdź do strony klastra i wybierz kartę Biblioteki . Wybierz pozycję Zainstaluj nowy i przekaż plik jar łącznika Spark, aby zainstalować bibliotekę.
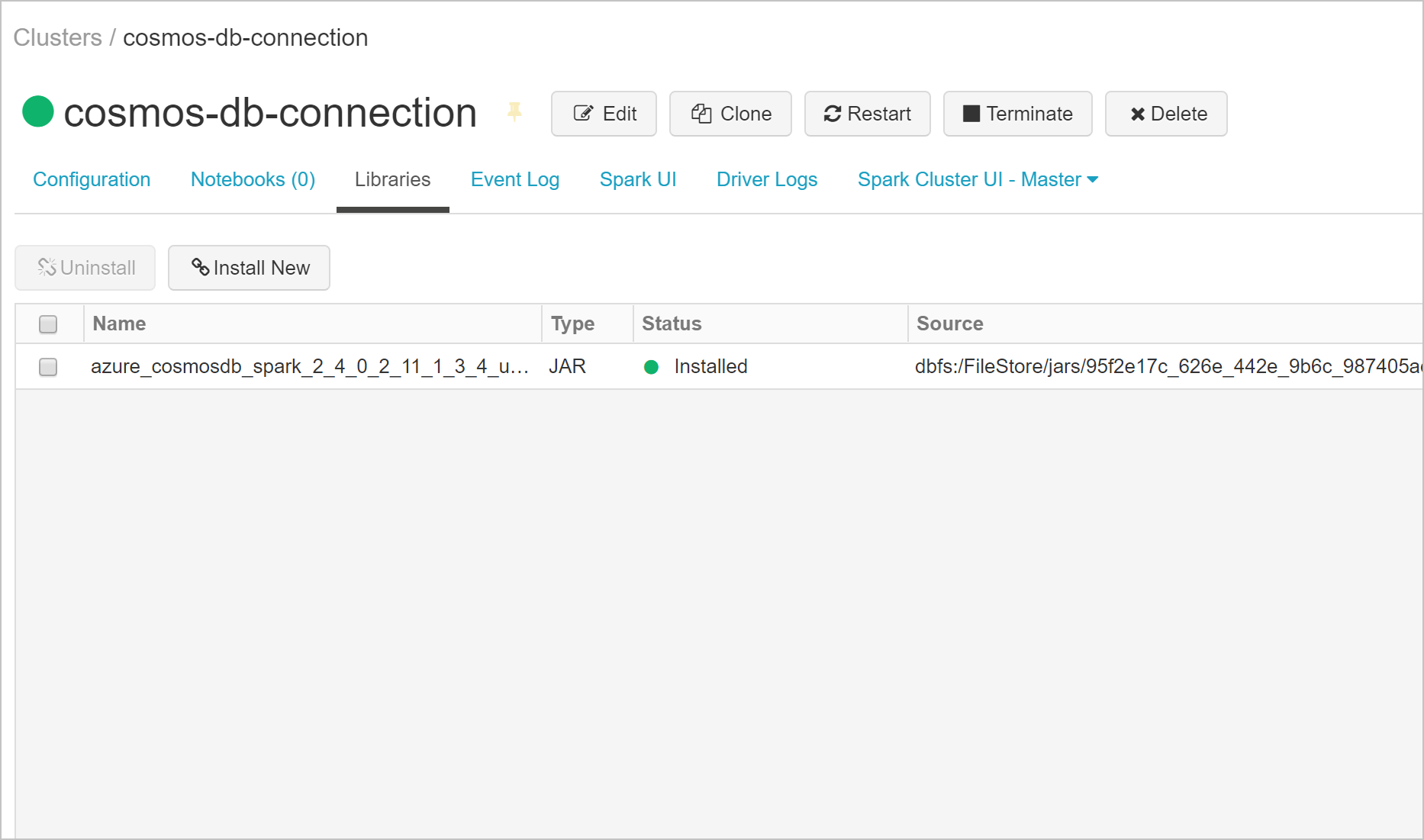
Możesz sprawdzić, czy biblioteka została zainstalowana na karcie Biblioteki .
Wykonywanie zapytań względem usługi Azure Cosmos DB z notesu usługi Databricks
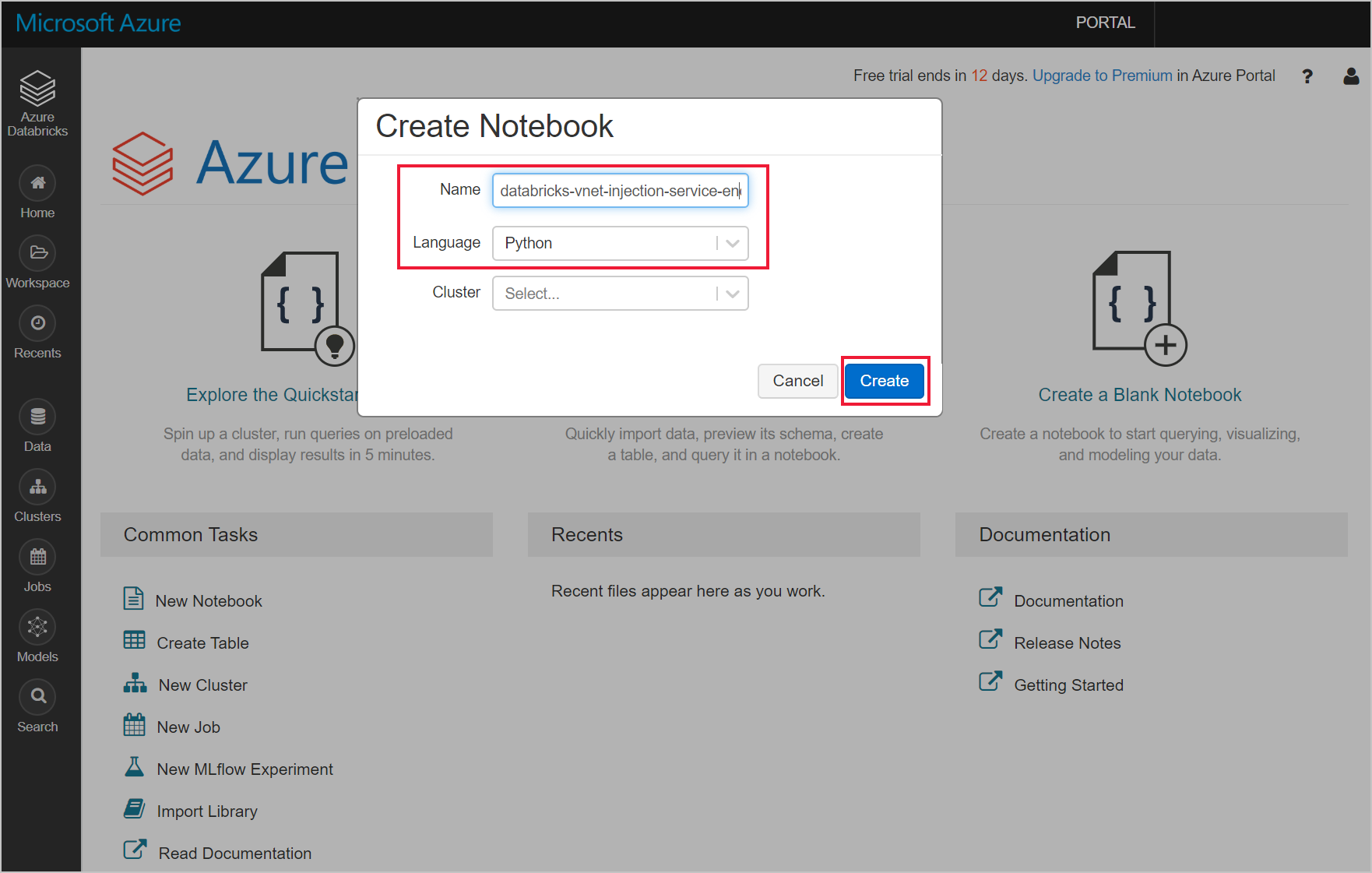
Przejdź do obszaru roboczego usługi Azure Databricks i utwórz nowy notes języka Python.
Uruchom następujący kod w języku Python, aby ustawić konfigurację połączenia usługi Azure Cosmos DB. Odpowiednio zmień punkt końcowy, klucz master,bazę danych i kontener .
connectionConfig = { "Endpoint" : "https://<your Azure Cosmos DB account name.documents.azure.com:443/", "Masterkey" : "<your Azure Cosmos DB primary key>", "Database" : "<your database name>", "preferredRegions" : "West US 2", "Container": "<your container name>", "schema_samplesize" : "1000", "query_pagesize" : "200000", "query_custom" : "SELECT * FROM c" }Użyj następującego kodu w języku Python, aby załadować dane i utworzyć widok tymczasowy.
users = spark.read.format("com.microsoft.azure.cosmosdb.spark").options(**connectionConfig).load() users.createOrReplaceTempView("storm")Użyj następującego polecenia magic, aby wykonać instrukcję SQL zwracającą dane.
%sql select * from stormPomyślnie połączono obszar roboczy usługi Databricks z wprowadzonym siecią wirtualną do zasobu usługi Azure Cosmos DB z włączonym punktem końcowym usługi. Aby dowiedzieć się więcej na temat nawiązywania połączenia z usługą Azure Cosmos DB, zobacz Łącznik usługi Azure Cosmos DB dla platformy Apache Spark.
Czyszczenie zasobów
Gdy grupa zasobów, obszar roboczy usługi Azure Databricks i wszystkie pokrewne zasoby nie będą już potrzebne, usuń je. Usunięcie zadania pozwala uniknąć niepotrzebnych rozliczeń. Jeśli planujesz korzystanie z obszaru roboczego usługi Azure Databricks w przyszłości, możesz zatrzymać klaster i uruchomić go ponownie później. Jeśli nie zamierzasz nadal korzystać z tego obszaru roboczego usługi Azure Databricks, usuń wszystkie zasoby utworzone w tym samouczku, wykonując następujące czynności:
W menu po lewej stronie w Azure Portal kliknij pozycję Grupy zasobów, a następnie kliknij nazwę utworzonej grupy zasobów.
Na stronie grupy zasobów wybierz pozycję Usuń, wpisz nazwę zasobu do usunięcia w polu tekstowym, a następnie ponownie wybierz pozycję Usuń .
Następne kroki
W tym samouczku wdrożono obszar roboczy usługi Azure Databricks w sieci wirtualnej i użyto łącznika Spark usługi Azure Cosmos DB do wykonywania zapytań dotyczących danych usługi Azure Cosmos DB z usługi Databricks. Aby dowiedzieć się więcej na temat pracy z usługą Azure Databricks w sieci wirtualnej, przejdź do samouczka dotyczącego używania SQL Server z usługą Azure Databricks.