Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
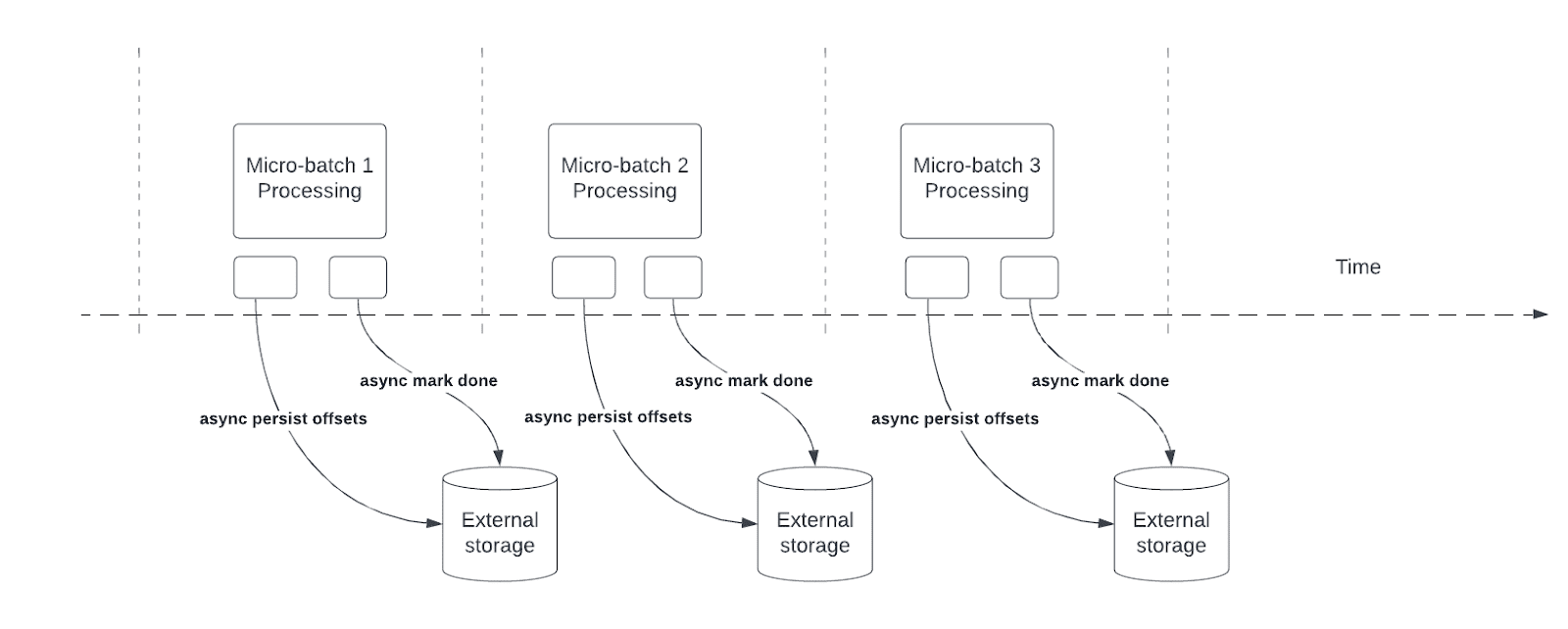
Śledzenie postępu asynchronicznego zmniejsza opóźnienia w potokach Structured Streaming, umożliwiając zapytaniom asynchronicznie aktualizować postęp punktów kontrolnych i przetwarzać dane w każdej mikropartii.
Podczas przetwarzania zapytań Strukturowane Przesyłanie Strumieniowe przechowuje i zarządza przesunięciami w celu mierzenia postępu zapytań w offsetLog i commitLog w każdej mikropartii. Bez śledzenia postępu asynchronicznego operacje zarządzania przesunięciami mają bezpośredni wpływ na opóźnienie przetwarzania, ponieważ przetwarzanie danych nie może być kontynuowane do momentu ich ukończenia.
Notatka
Śledzenie postępu asynchronicznego nie jest zgodne z wyzwalaczami Trigger.once lub Trigger.availableNow . Jeśli ta opcja jest włączona, zapytania strumieniowego przesyłania danych z użyciem Trigger.once lub Trigger.availableNow kończą się niepowodzeniem.
Opcje konfiguracji
| Opcja | Domyślny | Opis |
|---|---|---|
asyncProgressTrackingEnabled |
false |
Czy włączyć śledzenie postępu asynchronicznego. |
asyncProgressTrackingCheckpointIntervalMs |
1000 |
Interwał w milisekundach między zapisami dla przesunięć i zatwierdzeń ukończenia. |
Włączanie śledzenia postępu asynchronicznego
Aby włączyć śledzenie postępu asynchronicznego, ustaw wartość asyncProgressTrackingEnabledtrue:
Python
stream = (spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
)
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
)
Scala
val stream = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "in")
.load()
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.start()
Zwiększanie przepływności za pomocą częstotliwości punktów kontrolnych
Domyślna częstotliwość punktów kontrolnych w milisekundach 1000 ma dobrą przepływność dla większości zapytań. Gdy operacje zarządzania przesunięciami są wykonywane szybciej, niż śledzenie postępów asynchronicznych jest w stanie je przetworzyć, powstaje zaległość operacji zarządzania przesunięciami. Aby zapobiec dalszemu zwiększaniu listy prac, śledzenie postępu asynchronicznego może blokować lub spowalniać przetwarzanie danych, co potencjalnie zmniejsza oczekiwane korzyści z opóźnienia.
W tym scenariuszu usługa Databricks zaleca zwiększenie interwału punktu kontrolnego:
Python
query = (stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
)
Scala
val query = stream.writeStream
.format("kafka")
.option("topic", "out")
.option("checkpointLocation", "/tmp/checkpoint")
.option("asyncProgressTrackingEnabled", "true")
.option("asyncProgressTrackingCheckpointIntervalMs", "5000")
.start()
Notatka
Czas odzyskiwania po awarii zwiększa się wraz z długością interwału punktów kontrolnych. W przypadku awarii potok musi ponownie przetworzyć wszystkie dane od poprzedniego pomyślnego punktu kontrolnego. Przed wprowadzeniem tej zmiany w środowisku produkcyjnym należy rozważyć kompromis między mniejszym opóźnieniem podczas regularnego przetwarzania w porównaniu z czasem odzyskiwania w przypadku awarii.
Wyłączanie śledzenia postępu asynchronicznego
Po włączeniu śledzenia postępu asynchronicznego strumień nie gwarantuje postępu w punktach kontrolnych dla każdej paczki danych. Zanim będziesz mógł wyłączyć tę funkcję, musisz zapisać postępy.
Aby wyłączyć, wykonaj następujące kroki:
Przetwórz co najmniej dwie mikropartie z
asyncProgressTrackingEnabledustawionym natrueoraz zasyncProgressTrackingCheckpointIntervalMsustawionym na0:Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "true") .option("asyncProgressTrackingCheckpointIntervalMs", "0") .start()Zatrzymaj zapytanie:
Python
query.stop()Scala
query.stop()Wyłącz śledzenie postępu asynchronicznego i uruchom ponownie zapytanie:
Python
query = (stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start() )Scala
val query = stream.writeStream .format("kafka") .option("topic", "out") .option("checkpointLocation", "/tmp/checkpoint") .option("asyncProgressTrackingEnabled", "false") .start()
Jeśli wyłączysz śledzenie postępu asynchronicznego bez wykonywania powyższych kroków, może wystąpić następujący błąd:
java.lang.IllegalStateException: batch x doesn't exist
W dziennikach sterowników może zostać wyświetlony następujący błąd:
The offset log for batch x doesn't exist, which is required to restart the query from the latest batch x from the offset log. Please ensure there are two subsequent offset logs available for the latest batch via manually deleting the offset file(s). Please also ensure the latest batch for commit log is equal or one batch earlier than the latest batch for offset log.
Ograniczenia
- W przypadku ujść Kafka śledzenie asynchroniczne postępu obsługiwane jest tylko w potokach bezstanowych.
- Śledzenie postępu asynchronicznego nie gwarantuje dokładnego, jednokrotnego przetwarzania od początku do końca, ponieważ zakresy przesunięcia dla partii mogą ulec zmianie po awarii. Niektóre ujścia, takie jak Kafka, nigdy nie zapewniają gwarancji typu exactly-once.