Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Na tej stronie opisano sposób używania tabel Delta jako źródeł i celów dla Spark Structured Streaming za pomocą readStream i writeStream. Usługa Delta Lake rozwiązuje typowe problemy z wydajnością i niezawodnością systemów przesyłania strumieniowego i plików. Najważniejsze korzyści to:
- Łączenie małych plików generowanych przez przetwarzanie danych o niskich opóźnieniach w celu zwiększenia wydajności.
- Obsługa przetwarzania "dokładnie raz" przy użyciu więcej niż jednego strumienia (lub współbieżnych zadań wsadowych).
- Efektywne wykrywanie nowych plików podczas korzystania z plików jako źródła strumieniowego.
Aby dowiedzieć się, jak ładować dane przy użyciu tabel przesyłania strumieniowego w usłudze Databricks SQL, zobacz Używanie tabel przesyłania strumieniowego w usłudze Databricks SQL.
Aby uzyskać informacje o sprzężeniach strumieniowo-statycznych za pomocą usługi Delta Lake, zobacz Stream-static joins (Sprzężenia strumieniowo-statyczne).
Używanie tabel delty jako ujścia
Dane można zapisywać w tabeli Delta przy użyciu Structured Streaming. Dziennik transakcji usługi Delta Lake gwarantuje dokładne jednokrotne przetwarzanie, nawet gdy istnieją inne strumienie lub zapytania wsadowe uruchomione współbieżnie z tabelą.
Podczas zapisywania do tabeli Delta przy użyciu ujścia strukturalnego przesyłania strumieniowego, mogą być widoczne puste zatwierdzenia z epochId = -1. Są one oczekiwane i zwykle występują:
- W pierwszej partii każdego uruchomienia zapytania przesyłania strumieniowego (dzieje się to w każdej partii dla elementu
Trigger.AvailableNow). - Gdy schemat zostanie zmieniony (na przykład dodanie kolumny).
Te puste zatwierdzenia są zamierzone i nie wskazują błędu. Nie wpływają one na poprawność ani wydajność zapytania w żaden znaczący sposób.
Note
Funkcja Delta Lake VACUUM usuwa wszystkie pliki, które nie są zarządzane przez usługę Delta Lake, ale pomija wszystkie katalogi rozpoczynające się od _. Punkty kontrolne można bezpiecznie przechowywać wraz z innymi danymi i metadanymi dla tabeli delty przy użyciu struktury katalogów, takiej jak <table-name>/_checkpoints.
Monitorowanie listy prac za pomocą metryk
Użyj następujących metryk, aby monitorować zaległości procesu zapytań strumieniowych:
-
numBytesOutstanding: liczba bajtów do przetworzenia na liście prac. -
numFilesOutstanding: liczba plików do przetworzenia na liście prac. -
numNewListedFiles: Liczba plików Delta Lake wymienionych do obliczenia zaległości dla tej partii. -
backlogEndOffset: wersja tabeli delty używana do obliczania listy prac.
W notesie wyświetl te metryki na karcie Surowe dane na pulpicie nawigacyjnym postępu zapytania strumieniowego:
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Tryb dołączania
Domyślnie strumienie działają w trybie dołączania i dodają tylko nowe rekordy do tabeli.
Użyj metody toTable podczas przesyłania strumieniowego do tabel.
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Tryb pełny
Użyj Structured Streaming w trybie pełnym, aby zastąpić całą tabelę po każdym przetworzeniu. Można na przykład stale aktualizować zagregowaną tabelę podsumowania zdarzeń według klienta:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
W przypadku aplikacji bez rygorystycznych wymagań dotyczących opóźnień można zaoszczędzić zasoby obliczeniowe i koszty za pomocą wyzwalaczy jednorazowych, takich jak AvailableNow. Na przykład użyj tego wyzwalacza, aby zaktualizować tabele z podsumowaniem agregacji zgodnie z określonym harmonogramem, przetwarzając tylko nowe dane, które dotarły do czasu ostatniej aktualizacji. Zobacz AvailableNow: Przyrostowe przetwarzanie wsadowe.
Obsługa zmian w źródłowych tabelach delty
Przesyłanie strumieniowe Structured Streaming przyrostowo odczytuje tabele Delta. Gdy zapytanie przesyłane strumieniowo odczytuje z tabeli Delta, nowe rekordy są przetwarzane idempotentnie, gdy nowe wersje tabeli są zatwierdzane w tabeli źródłowej. Strukturalne przesyłanie strumieniowe akceptuje tylko dodawanie danych wejściowych i zgłasza wyjątek, jeśli w źródłowej tabeli Delta wystąpią jakiekolwiek modyfikacje. Jeśli na przykład operacja UPDATE, DELETE, MERGE INTOlub OVERWRITE modyfikuje źródłową tabelę delty odczytywaną przez zapytanie przesyłane strumieniowo, strumień kończy się niepowodzeniem z powodu błędu.
Istnieją cztery typowe podejścia do obsługi nadrzędnych zmian w źródłowych tabelach delty, w zależności od przypadku użycia. Poniżej przedstawiono tabelę referencyjną i szczegółowe informacje na temat każdego z nich:
| Metoda | Zalety | Cons |
|---|---|---|
skipChangeCommits |
Proste, nie wymaga pisania złożonej logiki. Przydatne w przypadku przetwarzania tylko do dołączania, w którym zmiany nadrzędne są obsługiwane oddzielnie lub do tymczasowej obsługi nieprawidłowego rekordu. | Nie propaguje zmian i obsługuje tylko dołączenia. |
| Pełne odświeżanie | Ponadto proste, nie wymaga pisania złożonej logiki. Przydatne w przypadku małych zestawów danych z rzadkimi zmianami nadrzędnymi. | Drogie w przypadku dużych zestawów danych. Wymaga ponownego przetwarzania wszystkich tabel podrzędnych. |
| Zmienianie źródła danych | Przetwarzanie wszystkich typów zmian (wstawiania, aktualizacji i usuwania). Usługa Databricks zaleca przesyłanie strumieniowe ze źródła danych CDC tabeli delta, a nie bezpośrednio z tabeli, gdy jest to możliwe. | Wymaga pisania bardziej złożonej logiki do obsługi każdego typu zmiany. |
| Zmaterializowane widoki | Prosta alternatywa dla Structured Streaming, posiadająca automatyczną propagację zmian. | Większe opóźnienie. Dostępne tylko w potokach deklaratywnych platformy Spark w usłudze Lakeflow i usłudze Databricks SQL. |
Pomiń zatwierdzenia zmian nadrzędnych za pomocą polecenia skipChangeCommits
Ustaw skipChangeCommits na ignorowanie transakcji, które usuwają lub modyfikują istniejące rekordy, oraz na przetwarzanie tylko operacji dodawania. Jest to przydatne, gdy zmiany istniejących danych nie muszą być propagowane za pośrednictwem strumienia lub gdy wolisz oddzielną logikę do obsługi tych zmian. Możesz włączyć i wyłączyć skipChangeCommits , jeśli konieczne jest tymczasowe ignorowanie jednorazowych zmian.
Usługa Databricks zaleca korzystanie z skipChangeCommits większości obciążeń, które nie używają źródeł danych zmian.
Python
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
Scala
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Important
Jeśli zmieni się schemat tabeli Delta po rozpoczęciu odczytu strumieniowego z tabeli, zapytanie zakończy się niepowodzeniem. W przypadku większości zmian schematu można ponownie uruchomić strumień, aby rozwiązać niezgodność schematu i kontynuować przetwarzanie.
W środowisku Databricks Runtime 12.2 LTS i poniżej nie można przesyłać strumieniowo z tabeli Delta z włączonym mapowaniem kolumn, które przeszły ewolucję schematu, która nie jest dodatnia, na przykład zmianę nazwy lub usuwanie kolumn. Aby uzyskać szczegółowe informacje, zobacz Mapowanie kolumn i przesyłanie strumieniowe.
Note
W środowisku Databricks Runtime 12.2 LTS lub nowszym, skipChangeCommits zastępuje ignoreChanges. W środowisku Databricks Runtime 11.3 LTS i niższym jest ignoreChanges jedyną obsługiwaną opcją. Zobacz Starsza opcja: ignoreChanges w celu uzyskania szczegółowych informacji.
Starsza opcja: ignoreDeletes
ignoreDeletes jest opcją przestarzałą, która obsługuje tylko transakcje usuwające dane na granicach partycji (czyli pełne usunięcie partycji). Jeśli musisz obsługiwać operacje usuwania, aktualizacji lub innych modyfikacji nienależących do partycji, użyj skipChangeCommits zamiast tego.
Python
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
Scala
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Starsza opcja: ignoreChanges
ignoreChanges jest dostępny w środowisku Databricks Runtime 11.3 LTS i niższym. W środowisku Databricks Runtime 12.2 LTS i nowszym jest on zastępowany przez skipChangeCommits.
Z włączonym ignoreChanges, przepisywane pliki danych w tabeli źródłowej są ponownie wypuszczane po modyfikacji danych, takiej jak UPDATE, MERGE INTO, DELETE (w obrębie partycji) lub OVERWRITE. Niezmienione wiersze są często emitowane obok nowych wierszy, więc odbiorcy podrzędni muszą mieć możliwość obsługi duplikatów. Usunięcia nie są propagowane w dół.
ignoreChanges ma pierwszeństwo przed ignoreDeletes.
Z kolei skipChangeCommits całkowicie pomija operacje zmieniania plików. Przepisane pliki danych w tabeli źródłowej z powodu operacji modyfikacji danych, takich jak UPDATE, MERGE INTO, DELETEi OVERWRITE , są całkowicie ignorowane. Aby odzwierciedlić zmiany w tabelach źródłowych strumienia, należy zaimplementować oddzielną logikę, aby propagować te zmiany.
Databricks zaleca używanie skipChangeCommits dla wszystkich nowych obciążeń. Aby przeprowadzić migrację obciążenia z ignoreChanges do skipChangeCommits, przekształć logikę przesyłania strumieniowego.
Pełne odświeżanie tabel podrzędnych
Jeśli zmiany nadrzędne są rzadkie, a dane są wystarczająco małe, aby ponownie przetworzyć, możesz usunąć punkt kontrolny przesyłania strumieniowego i tabelę danych wyjściowych, a następnie ponownie uruchomić strumień od początku. Powoduje to ponowne przetwarzanie wszystkich danych z tabeli źródłowej przez strumień. Należy pamiętać, że takie podejście wymaga również ponownego przetwarzania wszystkich tabel podrzędnych, które zależą od danych wyjściowych tego strumienia.
Takie podejście najlepiej nadaje się w przypadku mniejszych zestawów danych lub obciążeń, w których zmiany nadrzędne są rzadko wykonywane, a koszt pełnego odświeżania jest akceptowalny.
Używanie zestawienia danych zmian
W przypadku obciążeń, które przetwarzają wszystkie typy operacji (wstawienia, aktualizacje i usuwania), użyj kanału danych zmian Delta Lake. Zapis zmian danych rejestruje zmiany na poziomie wiersza w tabeli Delta, co umożliwia transmitowanie tych zmian i zapisywanie logiki do obsługi każdego rodzaju zmiany w tabelach podrzędnych. Jest to najbardziej niezawodne podejście, ponieważ kod jawnie obsługuje każdy typ zdarzenia zmiany. Zobacz Zastosowanie strumienia zmian danych w Delta Lake na Azure Databricks.
Jeśli używasz deklaratywnych potoków Spark platformy Lakeflow, sprawdź AUTO CDC APIs: Upraszczanie przechwytywania zmian danych za pomocą potoków.
Important
W środowisku Databricks Runtime 12.2 LTS i poniżej nie można przesyłać strumieniowo ze źródła danych zmian dla tabeli delty z włączonym mapowaniem kolumn, które przeszły ewolucję schematu nie addytywnego, na przykład zmiany nazw lub upuszczania kolumn. Zobacz Mapowanie kolumn i przesyłanie strumieniowe.
Użyj widoków zmaterializowanych
Zmaterializowane widoki automatycznie obsługują zmiany nadrzędne przez ponowne obliczanie wyników po zmianie danych źródłowych. Jeśli nie potrzebujesz najmniejszego możliwego opóźnienia i chcesz uniknąć zarządzania złożonością przesyłania strumieniowego, zmaterializowany widok może uprościć architekturę. Zmaterializowane widoki są dostępne w potokach deklaratywnych spark lakeflow i w usłudze Databricks SQL. Zobacz zmaterializowane widoki.
Example
Załóżmy na przykład, że masz tabelę user_events z kolumnami date, user_emaili action, które są partycjonowane przez date. Przesyłasz dane z tabeli user_events i musisz usunąć z niej dane ze względu na RODO.
skipChangeCommits umożliwia usuwanie danych w wielu partycjach (w tym przykładzie filtrowanie przy użyciu metody user_email). Użyj następującej składni:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
Jeśli zaktualizujesz user_email za pomocą instrukcji UPDATE, plik zawierający dany user_email zostanie przepisany. Użyj polecenia skipChangeCommits , aby zignorować zmienione pliki danych.
Usługa Databricks zaleca użycie skipChangeCommits zamiast ignoreDeletes, chyba że masz pewność, że usunięcia są zawsze pełne usunięcia partycji.
Użyj foreachBatch do idempotentnych zapisów w tabeli
Note
Usługa Databricks zaleca skonfigurowanie oddzielnego zapisu strumieniowego dla każdego ujścia, które chcesz zaktualizować, zamiast używania foreachBatch. Zapisy do wielu miejsc docelowych zmniejszają stopień foreachBatch równoległości i zwiększają ogólne opóźnienie, ponieważ przy zapisie do wielu tabel następuje serializacja w programie foreachBatch.
Tabele różnicowe obsługują następujące opcje DataFrameWriter, aby uczynić zapisy do wielu tabel w foreachBatch idempotentnymi:
-
txnAppId: unikatowy ciąg, który można zastosować przy każdym zapisie DataFrame. Na przykład możesz użyć identyfikatora StreamingQuery jakotxnAppId.txnAppIdmoże być dowolnym unikatowym ciągiem generowanym przez użytkownika i nie musi być powiązany z identyfikatorem strumienia. -
txnVersion: monotonicznie rosnąca liczba, która działa jako wersja transakcji.
Usługa Delta Lake używa funkcji txnAppId i txnVersion do identyfikowania i ignorowania zduplikowanych zapisów. Na przykład po przerwaniu zapisu wsadowego z powodu awarii można ponownie uruchomić proces wsadowy z tą samą wartością txnAppId i txnVersion, aby prawidłowo zidentyfikować i zignorować duplikaty. Zobacz Używanie polecenia foreachBatch do zapisu w dowolnych odbiornikach danych.
Warning
Jeśli usuniesz punkt kontrolny przesyłania strumieniowego i ponownie uruchomisz zapytanie przy użyciu nowego punktu kontrolnego, musisz podać inny txnAppId. Nowe punkty kontrolne zaczynają się od identyfikatora partii 0. Usługa Delta Lake używa identyfikatora partii i txnAppId jako unikatowego klucza i pomija partie z już widocznymi wartościami.
W poniższym przykładzie kodu pokazano ten wzorzec:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
Upsert z zapytań przesyłanych strumieniowo przy użyciu polecenia foreachBatch
Można użyć funkcji merge i foreachBatch do zapisania złożonych operacji upsert z kwerendy przesyłania strumieniowego do tabeli Delta. Zobacz Używanie polecenia foreachBatch do zapisu w dowolnych odbiornikach danych.
Takie podejście ma wiele aplikacji:
- Zwiększ wydajność zapisu w
updatetrybie wyjściowym, natomiastcompletetryb wyjściowy wymaga ponownego zapisania całej tabeli wyników dla każdej mikropartii. - Ciągłe stosowanie strumienia zmian do tabeli delty przy użyciu zapytania scalania w celu zapisania danych zmian w pliku
foreachBatch. Zobacz Powolne zmienianie danych (SCD) i przechwytywanie danych zmian (CDC) za pomocą usługi Delta Lake. - Obsługa deduplikacji podczas przetwarzania strumienia. Możesz użyć
foreachBatchzapytania scalania tylko do wstawiania, aby stale zapisywać dane w Tabeli Delta z automatyczną deduplikacją. Zobacz Deduplikacja danych podczas zapisywania w tabelach Delta.
Note
Sprawdź, czy instrukcja
mergewewnątrzforeachBatchjest idempotentna. W przeciwnym razie ponowne uruchomienia zapytania przesyłania strumieniowego mogą wielokrotnie stosować operację na tej samej partii danych. Zobacz Use for idempotent table writes (UżywanieforeachBatchdla operacji zapisu w tabeli idempotentnych).W przypadku użycia
mergewforeachBatch, metryka szybkości danych wejściowych może zwracać wielokrotność rzeczywistej szybkości generowania danych w źródle.mergeodczytuje dane wejściowe wiele razy, co mnoży metryki. Aby zapobiec mnożeniu metryk, należy buforować wsadowe ramki danych przedmerge, a następnie odbuforować je pomerge.Szybkość danych wejściowych jest dostępna poprzez
StreamingQueryProgressoraz na wykresie szybkości strumieniowej w notebooku. Zobacz Monitorowanie zapytań przesyłania strumieniowego ze strukturą w Azure Databricks.
Na przykład można użyć MERGE instrukcji SQL w pliku foreachBatch:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Interfejsy API usługi Delta Lake można również używać do przesyłania strumieniowego upserts:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Ustaw początkową wersję tabeli w celu przetworzenia zmian
Domyślnie strumienie zaczynają się od najnowszej dostępnej wersji tabeli delty. Obejmuje to pełną migawkę tabeli w danym momencie oraz wszystkie przyszłe zmiany. Usługa Databricks zaleca używanie domyślnej początkowej wersji tabeli dla większości obciążeń.
Opcjonalnie możesz użyć następujących opcji, aby określić punkt początkowy źródła przesyłania strumieniowego usługi Delta Lake bez przetwarzania całej tabeli.
startingVersion: wersja tabeli delty do rozpoczęcia odczytywania. Wszystkie zmiany tabeli zatwierdzone w lub po określonej wersji są odczytywane przez strumień. Jeśli określona wersja jest niedostępna, uruchomienie strumienia nie powiedzie się.Aby znaleźć dostępne wersje zatwierdzeń, uruchom
DESCRIBE HISTORYi sprawdźversion. Aby zwrócić tylko najnowsze zmiany, określ wartośćlatest. Aby uzyskać informacje na temat wersji tabeli delty, zobacz Praca z historią tabel.startingTimestamp: sygnatura czasowa, od której rozpocznie się odczytywanie. Wszystkie zmiany tabeli zatwierdzone w godzinie lub po określonym znaczniku czasu są odczytywane przez strumień. Jeśli podany znacznik czasu poprzedza wszystkie zatwierdzenia w tabeli, odczyt przesyłania strumieniowego rozpoczyna się od najwcześniejszego dostępnego znacznika czasu. Ustaw jedną z następujących opcji:- Łańcuch znacznika czasu. Na przykład
"2019-01-01T00:00:00.000Z". - Ciąg daty. Na przykład
"2019-01-01".
- Łańcuch znacznika czasu. Na przykład
Nie można ustawić zarówno startingVersion, jak i startingTimestamp jednocześnie. Te ustawienia dotyczą tylko nowych zapytań przesyłanych strumieniowo. Jeśli zapytanie przesyłania strumieniowego zostało uruchomione i postęp został zarejestrowany w punkcie kontrolnym, te ustawienia są ignorowane.
Important
Chociaż źródło przesyłania strumieniowego można uruchomić z określonej wersji lub znacznika czasu, schemat źródła przesyłania strumieniowego jest zawsze najnowszym schematem tabeli Delta. Musisz upewnić się, że w tabeli Delta nie zaszła niezgodna zmiana schematu po określonej wersji lub znaczniku czasu. W przeciwnym razie źródło przesyłania strumieniowego może zwracać nieprawidłowe wyniki podczas odczytywania danych z nieprawidłowym schematem.
Example
Załóżmy na przykład, że masz tabelę user_events. Jeśli chcesz odczytać zmiany od wersji 5, użyj:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Jeśli chcesz odczytać zmiany od 2018-10-18, użyj:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Przetwarzanie początkowej migawki bez usuwania danych
Ta funkcja jest dostępna w środowisku Databricks Runtime 11.3 LTS lub nowszym.
W stanowym zapytaniu strumieniowym ze zdefiniowanym znakiem wodnym przetwarzanie plików według czasu modyfikacji może prowadzić do przetwarzania rekordów w niewłaściwej kolejności. Może to spowodować nieprawidłowe oznaczenie rekordów jako zdarzeń zaległych i ich porzucenie. Taka sytuacja może wystąpić tylko wtedy, gdy początkowa migawka Delta jest przetwarzana w domyślnej kolejności.
W przypadku strumieni z tabelą źródłową Delta, zapytanie najpierw przetwarza wszystkie dane, które są obecne w tabeli i tworzy wersję nazywaną początkową migawką. Domyślnie pliki danych tabeli delty są przetwarzane na podstawie tego, który plik został ostatnio zmodyfikowany. Jednak czas ostatniej modyfikacji nie musi reprezentować kolejności czasu zdarzenia rekordu.
Aby uniknąć spadku danych podczas początkowego przetwarzania migawek, włącz withEventTimeOrder tę opcję.
withEventTimeOrder dzieli zakres czasu początkowych danych migawki na przedziały czasu zdarzenia. Każda mikroseria przetwarza wiadro, filtrując dane w określonym przedziale czasowym. Opcje maxFilesPerTrigger i maxBytesPerTrigger nadal mają zastosowanie do kontrolowania rozmiaru mikropartii, ale tylko w przybliżeniu z powodu zastosowanego podejścia do przetwarzania.
Na poniższym diagramie przedstawiono ten proces:
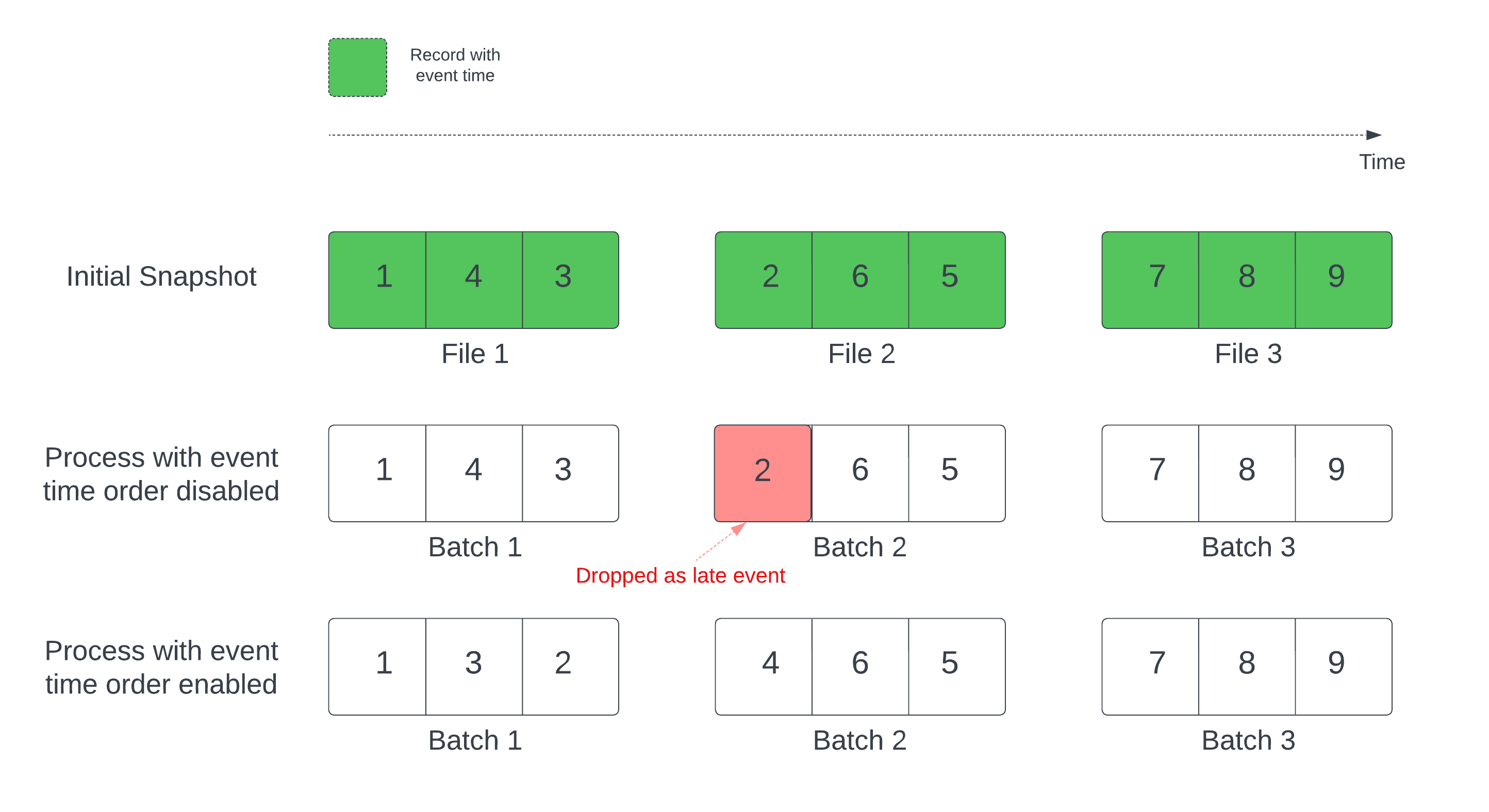
Ograniczenia
- Nie można zmienić
withEventTimeOrder, jeśli rozpoczęto zapytanie strumieniowe, a początkowy zrzut danych jest aktywnie przetwarzany. Aby resetować zwithEventTimeOrderzmienionym, należy usunąć punkt kontrolny. - Jeśli
withEventTimeOrderjest włączona, nie można obniżyć wersji strumienia do wersji środowiska Databricks Runtime, która nie obsługuje tej funkcji, dopóki początkowe przetwarzanie migawek nie zostanie zakończone. Aby przejść do niższej wersji, poczekaj na zakończenie początkowej migawki lub usuń punkt kontrolny i uruchom ponownie zapytanie. - Ta funkcja nie jest obsługiwana w następujących scenariuszach:
- Kolumna czasu zdarzenia jest kolumną generowaną, a między źródłem Delta a znakiem wodnym istnieją przekształcenia niezwiązane z projekcją.
- Istnieje znak wodny, który ma więcej niż jedno źródło Delta w zapytaniu strumieniowym.
Wydajność
Jeśli withEventTimeOrder ta opcja jest włączona, wydajność początkowego przetwarzania migawek może być niższa. Każda mikropartia skanuje początkową migawkę, aby filtrować dane w odpowiednim zakresie czasu zdarzenia. Aby zwiększyć wydajność filtrowania:
- Użyj kolumny źródłowej Delta jako czasu zdarzenia, aby umożliwić pomijanie danych. Zobacz Pomijanie danych.
- Podziel tabelę na partycje wzdłuż kolumny czasu zdarzenia.
Użyj interfejsu użytkownika Spark, aby zobaczyć, ile plików Delta jest skanowanych dla określonego mikroelementu.
Example
Załóżmy, że masz tabelę user_events z kolumną event_time. Zapytanie przesyłane strumieniowo jest zapytaniem agregacji. Jeśli chcesz mieć pewność, że podczas początkowego przetwarzania migawek nie ma żadnych danych, możesz użyć następujących funkcji:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
Możesz ustawić withEventTimeOrder konfigurację platformy Spark w klastrze, aby zastosować ją do wszystkich zapytań przesyłania strumieniowego: spark.databricks.delta.withEventTimeOrder.enabled true.
Ograniczanie szybkości wprowadzania w celu zwiększenia wydajności przetwarzania
Domyślnie Structured Streaming przetwarza jak najwięcej plików w każdej mikropartii. Aby ograniczyć ilość przetwarzanych danych na partię i zarządzać użyciem pamięci, ustabilizować opóźnienie lub zmniejszyć koszty magazynowania w chmurze, użyj następujących opcji:
-
maxFilesPerTrigger: Liczba nowych plików, które należy rozważyć w każdej mikroserii. Wartość domyślna to 1000. -
maxBytesPerTrigger: Ilość danych, które są przetwarzane w każdej mikroserii. Ta opcja ustawia "miękki limit", co oznacza, że partia przetwarza około tej ilości danych i może przetwarzać więcej niż limit, aby zapytanie strumieniowe mogło się posuwać naprzód w przypadkach, gdy najmniejsza jednostka wejściowa jest większa niż ten limit. Ta opcja nie jest domyślnie ustawiona.
Jeśli używasz zarówno maxBytesPerTrigger jak i maxFilesPerTrigger, mikrosadowy proces przetwarza dane do momentu osiągnięcia ograniczenia maxFilesPerTrigger lub maxBytesPerTrigger.
Note
Jeśli domyślnie logRetentionDuration czyści transakcje w tabeli źródłowej, a zapytanie przesyłane strumieniowo próbuje przetworzyć te wersje, zapytanie nie może zapobiec utracie danych. Możesz ustawić opcję z failOnDataLoss na false, aby ignorować utracone dane i kontynuować przetwarzanie. Zobacz Konfigurowanie przechowywania danych dla zapytań dotyczących podróży w czasie.
Kontrolowanie kosztów magazynu w chmurze
Zapytania przesyłane strumieniowo mają dostępne kilka trybów wyzwalacza, które umożliwiają równoważenie kosztów i opóźnień, w tym processingTime, availableNowi realTime. Zobacz Kontrolowanie kosztów magazynowania w chmurze.