Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Generowanie sztucznej inteligencji, włączone przez duże modele językowe (LLMs), otwiera ekscytujące nowe możliwości dla deweloperów oprogramowania i organizacji. Usługi, takie jak Azure OpenAI w modelach foundry, ułatwiają tworzenie sztucznej inteligencji za pomocą łatwych w użyciu interfejsów API. Deweloperzy na wszystkich poziomach umiejętności mogą integrować zaawansowane funkcje sztucznej inteligencji z aplikacjami bez specjalistycznej wiedzy ani inwestycji w sprzęt.
Jako deweloper aplikacji możesz chcieć zrozumieć, jaką rolę możesz odgrywać i gdzie się zmieścisz. Na przykład, możesz się zastanawiać, na jakim poziomie w "stosie sztucznej inteligencji" się skupić w nauce. Możesz też zastanawiać się, co jesteś w stanie tworzyć, biorąc pod uwagę istniejące technologie.
Aby odpowiedzieć na te pytania, ważne jest, aby najpierw opracować model mentalny, który mapuje, jak nowa terminologia i technologie pasują do tego, co już rozumiesz. Opracowanie modelu psychicznego ułatwia projektowanie i tworzenie funkcji generowania sztucznej inteligencji w aplikacjach.
W serii artykułów pokazano, w jaki sposób bieżące środowisko tworzenia oprogramowania ma zastosowanie do generowania sztucznej inteligencji. Artykuły tworzą również podstawy słów kluczowych i pojęć, które można wykorzystać do rozwijania swoich pierwszych rozwiązań opartych na generatywnej sztucznej inteligencji.
Jak firmy korzystają z generatywnej sztucznej inteligencji
Aby zrozumieć, w jaki sposób bieżące środowisko tworzenia oprogramowania ma zastosowanie do generowania sztucznej inteligencji, ważne jest, aby zrozumieć, w jaki sposób firmy zamierzają korzystać z generowania sztucznej inteligencji.
Firmy postrzegają generowanie sztucznej inteligencji jako środek zwiększający zaangażowanie klientów, zwiększając wydajność operacyjną i zwiększając rozwiązywanie problemów i kreatywność. Zintegrowanie generowania sztucznej inteligencji z istniejącymi systemami otwiera możliwości dla firm w celu ulepszenia ekosystemów oprogramowania. Może ona uzupełniać tradycyjne funkcje oprogramowania zaawansowanymi funkcjami sztucznej inteligencji, takimi jak spersonalizowane zalecenia dla użytkowników lub inteligentny agent, który może odpowiedzieć na konkretne pytania dotyczące organizacji lub jej produktów lub usług.
Oto kilka typowych scenariuszy, w których generowanie sztucznej inteligencji może pomóc firmom:
generowanie zawartości:
- Generuj tekst, kod, obrazy i dźwięk. Ten scenariusz może być przydatny w przypadku marketingu, sprzedaży, IT, komunikacji wewnętrznej i nie tylko.
przetwarzanie języka naturalnego:
- Redaguj lub ulepszaj komunikację biznesową za pośrednictwem sugestii lub kompletnego generowania komunikatów.
- Użyj "czatu z danymi". Oznacza to, że umożliwia użytkownikowi zadawanie pytań w środowisku czatu przy użyciu danych przechowywanych w bazach danych lub dokumentach organizacji jako podstawy odpowiedzi.
- Podsumowanie, organizacja i uproszczenie dużych treści zawartości w celu zwiększenia dostępności zawartości.
- Użyj wyszukiwania semantycznego. Oznacza to, że umożliwia użytkownikom wyszukiwanie dokumentów i danych bez używania dokładnych dopasowań słów kluczowych.
- Tłumaczenie języka w celu zwiększenia zasięgu i dostępności zawartości.
analiza danych:
- Analizowanie rynków i identyfikowanie trendów w danych.
- Modelowanie scenariuszy "co by było, gdyby" pomaga firmom w planowaniu możliwych zmian lub wyzwań w różnych obszarach działalności.
- Analizowanie kodu w celu sugerowania ulepszeń, naprawiania usterek i generowania dokumentacji.
Deweloper oprogramowania może znacznie zwiększyć swój wpływ, integrując generowanie aplikacji i funkcji sztucznej inteligencji z oprogramowaniem, na których opiera się organizacja.
Jak tworzyć aplikacje generujące sztuczną inteligencję
Mimo że LLM wykonuje trudniejszą część pracy, ty tworzysz systemy integrujące, orkiestrujące i monitorujące wyniki. Istnieje wiele do nauki, ale możesz zastosować już posiadane umiejętności, w tym instrukcje:
- Wywoływanie interfejsów API przy użyciu zestawów REST, JSON lub zestawów SDK specyficznych dla języka
- Organizowanie wywołań interfejsów API i wykonywanie logiki biznesowej
- Przechowywanie i pobieranie z magazynów danych
- Integrowanie danych wejściowych i wyników ze środowiskiem użytkownika
- Tworzenie interfejsów API, które mogą być wywoływane z poziomu usługi LLMs
Opracowywanie generacyjnych rozwiązań sztucznej inteligencji opiera się na istniejących umiejętnościach.
Narzędzia i usługi dla deweloperów
Firma Microsoft inwestuje w opracowywanie narzędzi, usług, interfejsów API, przykładów i zasobów szkoleniowych, które ułatwiają rozpoczęcie opracowywania generacyjnych rozwiązań sztucznej inteligencji. Każdy z nich wyróżnia główne kwestie lub odpowiedzialność, która jest wymagana do utworzenia generującego rozwiązania sztucznej inteligencji. Aby efektywnie korzystać z danej usługi, interfejsu API lub zasobu, wyzwaniem jest upewnienie się, że:
- Poznaj typowe funkcje, role i obowiązki w danym typie funkcji generowania sztucznej inteligencji. Na przykład, jak szczegółowo omawiamy w artykułach koncepcyjnych opisujących systemy czatowe oparte na generacji wspomaganej przez wyszukiwanie (RAG), istnieje wiele odpowiedzialności architektonicznych w systemie. Ważne jest, aby dokładnie zrozumieć domenę problemu i ograniczenia przed zaprojektowaniem systemu, który rozwiązuje ten problem.
- Poznaj interfejsy API, usługi i narzędzia, które istnieją dla danej funkcji, roli lub odpowiedzialności. Teraz, gdy rozumiesz domenę problemu i ograniczenia, możesz utworzyć ten aspekt systemu samodzielnie przy użyciu kodu niestandardowego lub istniejących narzędzi niskiego kodu/bez kodu lub wywołać interfejsy API dla istniejących usług.
- Zapoznaj się z opcjami, w tym rozwiązaniami skoncentrowanymi na kodzie oraz rozwiązaniami bez kodu i z niskim użyciem kodu. Możesz zbudować wszystko samodzielnie, ale czy jest to efektywne wykorzystanie swojego czasu i umiejętności? W zależności od wymagań zwykle można połączyć kombinację technologii i podejść (kod, bez kodu, niski kod, narzędzia).
Nie ma jednego właściwego sposobu tworzenia funkcji generacyjnych sztucznej inteligencji w aplikacjach. Możesz wybrać spośród wielu narzędzi i podejść. Ważne jest, aby ocenić zalety i wady każdego z nich.
Rozpoczynanie pracy z warstwą aplikacji
Nie musisz rozumieć wszystkiego, jak działa generowanie sztucznej inteligencji, aby rozpocząć pracę i zapewnić produktywność. Jak wspomniano wcześniej, prawdopodobnie już wiesz wystarczająco dużo. Aby rozpocząć pracę, możesz użyć interfejsów API i zastosować istniejące umiejętności.
Na przykład nie musisz trenować własnego modułu LLM od podstaw. Trenowanie modelu LLM wymaga czasu i zasobów, które większość firm nie jest skłonna zaangażować. Zamiast tego należy opierać się na istniejących wstępnie wytrenowanych modelach podstawowych, takich jak GPT-4, wykonując wywołania interfejsu API do istniejących usług hostowanych, takich jak interfejs API Azure OpenAI. Dodawanie funkcji generowania sztucznej inteligencji do istniejącej aplikacji nie różni się od dodawania innych funkcji na podstawie wywołania interfejsu API.
Badanie sposobu trenowania modeli językowych lub ich działania może zaspokoić twoją ciekawość intelektualną, ale pełne zrozumienie tego, jak działa LLM, wymaga głębokiego zrozumienia nauki o danych oraz podstaw matematycznych, które je wspierają. Uzyskanie tego zrozumienia może obejmować kursy na poziomie absolwentów dotyczące statystyk, prawdopodobieństwa i teorii informacji.
Jeśli masz doświadczenie w dziedzinie informatyki, możesz docenić, że większość programowania aplikacji odbywa się w wyższej warstwie w "stosie" badań i technologii. Możesz mieć pewne informacje na temat każdej warstwy, ale prawdopodobnie specjalizujesz się w warstwie tworzenia aplikacji, koncentrując się na określonym języku programowania i platformie, takich jak dostępne interfejsy API, narzędzia i wzorce.
To samo dotyczy pola sztucznej inteligencji. Możesz zrozumieć i docenić teorię, która leży u podstaw budowania na bazie LLMs, ale prawdopodobnie skupisz swoją uwagę na warstwie aplikacyjnej lub pomożesz wdrażać wzorce i procesy wspierające wysiłki związane z generatywną AI w firmie.
Oto nadmierna uproszczona reprezentacja warstw wiedzy, które są wymagane do zaimplementowania funkcji generacyjnych sztucznej inteligencji w nowej lub istniejącej aplikacji:
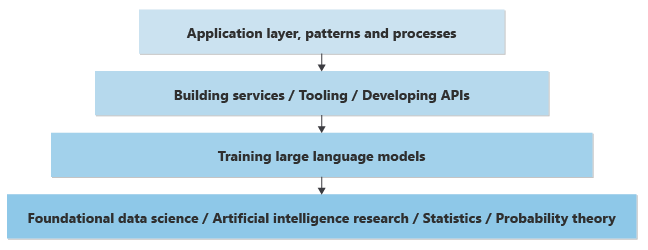
Na najniższym poziomie analitycy danych wykonują badania nad nauką o danych w celu rozwiązywania lub ulepszania sztucznej inteligencji na podstawie głębokiego matematycznego zrozumienia statystyk, teorii prawdopodobieństwa itd.
O jeden poziom wyżej, w oparciu o najniższą warstwę podstawową, inżynierowie danych implementują koncepcje teoretyczne w LLM, tworząc sieci neuronowe i ucząc wagi i odchylenia, aby zapewnić praktyczne oprogramowanie, które mogą przyjmować dane wejściowe (monity) i generować wyniki (ukończenia). Proces obliczeniowy komponowania uzupełnień na podstawie podpowiedzi jest nazywany wnioskowaniem. Analitycy danych określają , w jaki sposób neurony sieci neuronowej przewidują wygenerowanie następnego słowa lub piksela.
Biorąc pod uwagę ilość mocy obliczeniowej wymaganej do trenowania modeli i generowania wyników na podstawie danych wejściowych, modele często są trenowane i hostowane w dużych centrach danych. Istnieje możliwość trenowania lub hostowania modelu na komputerze lokalnym, ale wyniki są często powolne. Karty wideo GPU zapewniają szybkość i wydajność, pomagając w obsłudze obliczeń niezbędnych do generowania wyników.
W przypadku hostowania w dużych centrach danych dostęp programowy do tych modeli jest zapewniany za pośrednictwem interfejsów API REST. Interfejsy API są czasami "opakowane" przez zestawy SDK i są dostępne dla deweloperów aplikacji w celu ułatwienia ich użycia. Inne narzędzia mogą pomóc ulepszyć środowisko deweloperskie, zapewniając możliwość obserwowania lub inne narzędzia.
Deweloperzy aplikacji mogą wykonywać wywołania tych interfejsów API w celu zaimplementowania funkcji biznesowych.
Poza wywoływaniem modeli programowo pojawiają się wzorce i procesy ułatwiające organizacjom tworzenie niezawodnych funkcji biznesowych na podstawie generatywnej sztucznej inteligencji. Na przykład pojawiają się wzorce, które pomagają firmom zapewnić, że wygenerowany tekst, kod, obrazy i dźwięk są zgodne ze standardami etycznymi i bezpieczeństwa oraz z zobowiązaniami dotyczącymi prywatności danych klientów.
W tym stosie zagadnień lub warstw, jeśli jesteś deweloperem aplikacji odpowiedzialnym za tworzenie funkcji biznesowych, możesz przekroczyć warstwę aplikacji, aby opracowywać i trenować własny LLM. Jednak ten poziom zrozumienia wymaga nowego zestawu umiejętności, które często są opracowywane tylko za pośrednictwem edukacji zaawansowanej.
Jeśli nie możesz zobowiązać się do rozwijania kompetencji w dziedzinie nauki o danych na poziomie akademickim, aby pomóc w tworzeniu kolejnej warstwy w stosie, możesz skupić się na pogłębianiu wiedzy na temat warstwy aplikacji.
- Interfejsy API i zestawy SDK: co jest dostępne i co generują różne punkty dostępu.
- Powiązane narzędzia i usługi ułatwiające tworzenie wszystkich funkcji wymaganych przez rozwiązanie do generowania sztucznej inteligencji gotowe do produkcji.
- Inżynieria zapytań: Jak osiągnąć najlepsze wyniki, zadając lub przekształcając pytania.
- Gdzie pojawiają się wąskie gardła i jak wprowadzać skalowalne rozwiązania. Ten obszar obejmuje zrozumienie, co jest związane z rejestrowaniem lub uzyskiwaniem danych telemetrycznych bez naruszania kwestii dotyczących prywatności klientów.
- Cechy różnych maszyn LLM: ich mocne strony, przypadki użycia, testy porównawcze i miary oraz kluczowe różnice między dostawcami i modelami produkowanymi przez każdego dostawcę. Te informacje ułatwiają wybór odpowiedniego modelu dla potrzeb organizacji.
- Najnowsze wzorce, przepływy pracy i procesy, których można użyć do tworzenia efektywnych i odpornych funkcji sztucznej inteligencji w aplikacjach.
Narzędzia i usługi firmy Microsoft
Aby ułatwić tworzenie niektórych lub wszystkich rozwiązań, możesz użyć narzędzi i usług generacyjnych sztucznej inteligencji z małą ilością kodu i bez kodu od firmy Microsoft. Różne usługi platformy Azure mogą odgrywać kluczowe role. Każdy z nich przyczynia się do wydajności, skalowalności i niezawodności rozwiązania.
Interfejsy API i zestawy SDK dla podejścia skoncentrowanego na kodzie
Sercem każdego generowanego rozwiązania sztucznej inteligencji jest model LLM. Usługa Azure OpenAI zapewnia dostęp do wszystkich funkcji dostępnych w modelach, takich jak GPT-4.
| Produkt | opis |
|---|---|
| Azure OpenAI | Hostowana usługa, która zapewnia dostęp do zaawansowanych modeli językowych, takich jak GPT-4. Możesz użyć kilku interfejsów API do wykonywania wszystkich typowych funkcji LLM, w tym tworzenia osadzeń danych i tworzenia doświadczenia czatu. Masz pełny dostęp do ustawień i dostosowań, aby uzyskać żądane wyniki. |
Środowiska wykonywania
Ponieważ tworzysz logikę biznesową, logikę prezentacji lub interfejsy API, aby zintegrować generowanie sztucznej inteligencji z aplikacjami organizacji, potrzebujesz usługi do hostowania i wykonywania tej logiki.
| Produkt | opis |
|---|---|
| Usługa Aplikacji Azure (lub jedna z kilku usług chmurowych opartych na kontenerach) | Ta platforma może hostować interfejsy internetowe lub interfejsy API, za pośrednictwem których użytkownicy wchodzą w interakcje z systemem czatów RAG. Obsługuje szybkie opracowywanie, wdrażanie i skalowanie aplikacji internetowych, dzięki czemu łatwiej jest zarządzać składnikami frontonu systemu. |
| Azure Functions | Używaj przetwarzania bezserwerowego do obsługi zadań opartych na zdarzeniach w systemie czatu RAG. Na przykład służy do wyzwalania procesów pobierania danych, przetwarzania zapytań użytkowników lub obsługi zadań w tle, takich jak synchronizacja danych i oczyszczanie. Umożliwia to bardziej modułowe, skalowalne podejście do tworzenia zaplecza systemu. |
Rozwiązania z małą ilością kodu i bez kodu
Niektóre logiki potrzebne do zaimplementowania generowania obrazów sztucznej inteligencji można szybko skompilować i niezawodnie hostować przy użyciu rozwiązania z małą ilością kodu lub bez kodu.
| Produkt | opis |
|---|---|
| Azure AI Foundry | Do trenowania, testowania i wdrażania niestandardowych modeli uczenia maszynowego można użyć azure AI Foundry, aby ulepszyć system czatów RAG. Na przykład użyj usługi Azure AI Foundry, aby dostosować generowanie odpowiedzi lub poprawić istotność pobranych informacji. |
Wektorowa baza danych
Niektóre rozwiązania generujące sztuczną inteligencję mogą wymagać przechowywania i pobierania danych używanych do generowania rozszerzonego. Przykładem jest system czatów oparty na usłudze RAG, który umożliwia użytkownikom rozmowę z danymi organizacji. W tym przypadku użycia potrzebny jest wektorowy magazyn danych.
| Produkt | opis |
|---|---|
| Azure AI Search | Za pomocą tej usługi można efektywnie wyszukiwać duże zestawy danych w celu znalezienia odpowiednich informacji, które informują o odpowiedziach generowanych przez model językowy. Jest to przydatne dla komponentu wyszukiwania w systemie RAG, aby generowane odpowiedzi były jak najbardziej informacyjne i adekwatne kontekstowo. |
| Azure Cosmos DB | Ta rozproszona globalnie wielomodelowa usługa bazy danych może przechowywać ogromne ilości ustrukturyzowanych i nieustrukturyzowanych danych, do których musi uzyskać dostęp system czatów RAG. Jego szybkie możliwości odczytu i zapisu sprawiają, że idealnie nadaje się do obsługi danych w czasie rzeczywistym w modelu językowym i przechowywania interakcji użytkownika w celu dalszej analizy. |
| Azure Cache for Redis | Ten w pełni zarządzany magazyn danych w pamięci może służyć do buforowania często używanych informacji, zmniejszając opóźnienia i poprawiając wydajność systemu czatów RAG. Szczególnie przydatne jest przechowywanie danych sesji, preferencji użytkownika i typowych zapytań. |
| Azure Database for PostgreSQL — serwer elastyczny | Ta zarządzana usługa bazy danych może przechowywać dane aplikacji, w tym dzienniki, profile użytkowników i historyczne dane czatu. Jego elastyczność i skalowalność obsługują dynamiczne potrzeby systemu czatów RAG, dzięki czemu dane są stale dostępne i bezpieczne. |
Każda z tych usług platformy Azure przyczynia się do tworzenia kompleksowej, skalowalnej i wydajnej architektury dla generującego rozwiązania sztucznej inteligencji. Pomagają deweloperom uzyskiwać dostęp do najlepszych możliwości chmury platformy Azure i technologii sztucznej inteligencji oraz korzystać z nich.
Rozwój sztucznej inteligencji generatywnej skoncentrowany na kodzie przy użyciu interfejsu API usługi Azure OpenAI
W tej sekcji skoncentrujemy się na interfejsie API usługi Azure OpenAI. Jak wspomniano wcześniej, dostęp do funkcji LLM uzyskuje się programowo za pośrednictwem internetowego interfejsu API RESTful. Do wywołania tych interfejsów API można użyć dosłownie dowolnego nowoczesnego języka programowania. W wielu przypadkach zestawy SDK specyficzne dla języka lub platformy działają jako opakowania wokół wywołań interfejsu API REST, aby środowisko było bardziej naturalne.
Oto lista wrapperów dla Azure OpenAI REST API:
- Biblioteka klienta platformy Azure OpenAI dla platformy .NET
- Biblioteka klienta platformy Azure OpenAI dla języka Java
- Biblioteka klienta usługi Azure OpenAI dla języka JavaScript
- Moduł klienta usługi Azure OpenAI dla języka Go
- Użyj pakietu OpenAI języka Python i zmień kilka opcji. Język Python nie oferuje biblioteki klienta specyficznej dla platformy Azure.
Jeśli zestaw SDK języka lub platformy jest niedostępny, najgorszym scenariuszem jest wykonanie wywołań REST bezpośrednio do internetowych interfejsów API:
Większość deweloperów zna sposób wywoływania internetowych interfejsów API.
Usługa Azure OpenAI oferuje szereg interfejsów API zaprojektowanych w celu ułatwienia różnych typów zadań opartych na sztucznej inteligencji, dzięki czemu deweloperzy mogą integrować zaawansowane funkcje sztucznej inteligencji z aplikacjami. Oto omówienie kluczowych interfejsów API dostępnych w usłudze OpenAI:
- API do uzupełniania rozmów: API to skupia się na scenariuszach generowania tekstu, oferując funkcje konwersacyjne wspierające tworzenie czatbotów i wirtualnych asystentów, które mogą prowadzić naturalny dialog. Jest zoptymalizowany pod kątem interaktywnych przypadków użycia, w tym obsługi klienta, asystentów osobistych i interaktywnych środowisk szkoleniowych. Jest ona jednak używana dla wszystkich scenariuszy generowania tekstu, w tym podsumowania, autouzupełniania, pisania dokumentów, analizowania tekstu i tłumaczenia. Jest to punkt wejścia do funkcji widzenia, które są obecnie dostępne w wersji zapoznawczej (czyli aby przesłać obraz i zadawać pytania dotyczące tego obrazu).
- Moderacja API: To API jest zaprojektowane, aby pomóc programistom w identyfikacji i filtrowaniu potencjalnie szkodliwych treści w tekście. Jest to narzędzie, które pomaga zapewnić bezpieczniejsze interakcje użytkowników dzięki automatycznej wykrywaniu obraźliwych, niebezpiecznych lub w inny sposób nieodpowiednich materiałów.
- API do tworzenia osadzonych reprezentacji: API do tworzenia osadzonych reprezentacji generuje wektorowe reprezentacje danych wejściowych tekstu. Konwertuje wyrazy, zdania lub akapity na wektory o wysokim wymiarach. Te osadzania mogą służyć do wyszukiwania semantycznego, klastrowania, analizy podobieństwa zawartości i nie tylko. Przechwytuje podstawowe znaczenie i semantyczne relacje w tekście.
- API generowania obrazów: użyj tego API do generowania oryginalnych, wysokiej jakości obrazów na podstawie opisów tekstowych. Jest oparty na modelu DALL·E stworzonego przez OpenAI, który potrafi tworzyć obrazy pasujące do szerokiej gamy stylów i tematów na podstawie otrzymywanych podpowiedzi.
- Interfejs API Audio: To API zapewnia dostęp do modelu audio OpenAI i jest przeznaczone do automatycznego rozpoznawania mowy. Może ona transkrybować język mówiony w tekście lub tekst w mowę, obsługując różne języki i dialekty. Jest to przydatne w przypadku aplikacji wymagających poleceń głosowych, transkrypcji zawartości audio i nie tylko.
Chociaż w pozostałej części tego artykułu można używać generowania sztucznej inteligencji do pracy z wieloma różnymi modami medialnymi, koncentrujemy się na rozwiązaniach generowania sztucznej inteligencji opartych na tekście. Te rozwiązania obejmują scenariusze, takie jak czat i podsumowanie.
Rozpocznij programowanie z wykorzystaniem generatywnej sztucznej inteligencji
Deweloperzy oprogramowania, którzy są nowi w nieznanym języku, technologii lub interfejsie API, zwykle zaczynają się go uczyć, korzystając z samouczków lub modułów szkoleniowych, które pokazują, jak tworzyć małe aplikacje. Niektórzy deweloperzy oprogramowania wolą stosować podejście samodzielne i tworzyć małe aplikacje eksperymentalne. Oba podejścia są prawidłowe i przydatne.
Gdy zaczniesz, najlepiej zacząć od małych, obiecywać niewiele, iterować i rozwijać swoje zrozumienie i umiejętności. Tworzenie aplikacji przy użyciu generowania sztucznej inteligencji ma unikatowe wyzwania. Na przykład w tradycyjnym tworzeniu oprogramowania można polegać na danych wyjściowych deterministycznych. Oznacza to, że w przypadku dowolnego zestawu danych wejściowych można oczekiwać dokładnie tych samych danych wyjściowych za każdym razem. Jednak generowanie sztucznej inteligencji nie jest nieokreślone. Nigdy nie otrzymasz dokładnie tej samej odpowiedzi dwa razy dla danego monitu, co jest źródłem wielu nowych wyzwań.
Podczas rozpoczynania pracy należy wziąć pod uwagę te porady.
Porada 1: Jasne, co chcesz osiągnąć
- Bądź specyficzny dla problemu, który próbujesz rozwiązać: Generowanie sztucznej inteligencji może rozwiązać szeroką gamę problemów, ale sukces wynika z jasnego zdefiniowania konkretnego problemu, który chcesz rozwiązać. Czy próbujesz wygenerować tekst, obrazy, kod lub coś innego? Tym bardziej szczegółowe jest, tym lepiej możesz dostosować sztuczną inteligencję do własnych potrzeb.
- Zrozumienie odbiorców: Znajomość odbiorców pomaga dostosować dane wyjściowe sztucznej inteligencji do swoich oczekiwań, niezależnie od tego, czy jest to przypadkowi użytkownicy, czy eksperci w danym obszarze.
Porada 2: Używanie mocnych stron LLMs
- Zapoznaj się z ograniczeniami i uprzedzeniami LLM-ów: Chociaż LLM-y są zaawansowane, mają ograniczenia oraz wrodzone uprzedzenia. Znajomość ograniczeń i uprzedzeń może pomóc w projektowaniu, uwzględniając je, lub wdrożeniu środków zaradczych.
- Dowiedz się, w czym LLM-y się wyróżniają: LLM-y doskonale sprawdzają się w zadaniach, takich jak tworzenie treści, podsumowywanie i tłumaczenie. Chociaż ich możliwości podejmowania decyzji i możliwości dyskryminacyjne są coraz silniejsze w każdej nowej wersji, mogą istnieć inne typy sztucznej inteligencji, które są bardziej odpowiednie dla danego scenariusza lub przypadku użycia. Wybierz odpowiednie narzędzie dla zadania.
Porada 3: Aby uzyskać dobre wyniki, użyj dobrych monitów
- Poznaj najlepsze praktyki tworzenia podpowiedzi: Tworzenie skutecznych podpowiedzi jest sztuką. Poeksperymentuj z różnymi monitami, aby zobaczyć, jak wpływają one na dane wyjściowe. Bądź zwięzły, ale opisowy.
- Zobowiąż się do iteracyjnego doskonalenia: często pierwsze polecenie może nie przynosić żądanego wyniku. Jest to proces prób i błędów. Użyj danych wyjściowych, aby lepiej ulepszyć swoje polecenia.
Tworzenie pierwszego rozwiązania do generowania sztucznej inteligencji
Jeśli chcesz od razu rozpocząć eksperymentowanie z tworzeniem generującego rozwiązania sztucznej inteligencji, zalecamy zapoznanie się z Rozpoczynanie pracy z czatem przy użyciu własnego przykładu danych dla języka Python. Samouczek jest również dostępny dla .NET, Javai JavaScript.
Końcowe zagadnienia dotyczące projektowania aplikacji
Poniżej przedstawiono krótką listę kwestii, które należy wziąć pod uwagę i inne wnioski z tego artykułu, które mogą mieć wpływ na decyzje projektowe aplikacji:
- Jasno zdefiniuj przestrzeń problemu i odbiorców, aby dopasować możliwości sztucznej inteligencji do oczekiwań użytkowników. Zoptymalizuj skuteczność rozwiązania pod kątem zamierzonego przypadku użycia.
- Używaj platform o niskim kodzie/braku kodu do szybkiego tworzenia prototypów i programowania, jeśli spełniają one wymagania projektu. Oceń kompromis między szybkością programowania i możliwościami dostosowywania. Poznaj możliwości rozwiązań z małą ilością kodu i bez kodu dla części aplikacji, aby przyspieszyć programowanie i umożliwić członkom zespołu nietechnicznego współtworzenie projektu.